 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTieBot: Learning to Knot a Tie from Visual Demonstration through a Real-to-Sim-to-Real Approach
Jul 03, 2024



The tie-knotting task is highly challenging due to the tie's high deformation and long-horizon manipulation actions. This work presents TieBot, a Real-to-Sim-to-Real learning from visual demonstration system for the robots to learn to knot a tie. We introduce the Hierarchical Feature Matching approach to estimate a sequence of tie's meshes from the demonstration video. With these estimated meshes used as subgoals, we first learn a teacher policy using privileged information. Then, we learn a student policy with point cloud observation by imitating teacher policy. Lastly, our pipeline learns a residual policy when the learned policy is applied to real-world execution, mitigating the Sim2Real gap. We demonstrate the effectiveness of TieBot in simulation and the real world. In the real-world experiment, a dual-arm robot successfully knots a tie, achieving 50% success rate among 10 trials. Videos can be found on our $\href{https://tiebots.github.io/}{\text{website}}$.
Human-Agent Joint Learning for Efficient Robot Manipulation Skill Acquisition
Jul 02, 2024



Employing a teleoperation system for gathering demonstrations offers the potential for more efficient learning of robot manipulation. However, teleoperating a robot arm equipped with a dexterous hand or gripper, via a teleoperation system poses significant challenges due to its high dimensionality, complex motions, and differences in physiological structure. In this study, we introduce a novel system for joint learning between human operators and robots, that enables human operators to share control of a robot end-effector with a learned assistive agent, facilitating simultaneous human demonstration collection and robot manipulation teaching. In this setup, as data accumulates, the assistive agent gradually learns. Consequently, less human effort and attention are required, enhancing the efficiency of the data collection process. It also allows the human operator to adjust the control ratio to achieve a trade-off between manual and automated control. We conducted experiments in both simulated environments and physical real-world settings. Through user studies and quantitative evaluations, it is evident that the proposed system could enhance data collection efficiency and reduce the need for human adaptation while ensuring the collected data is of sufficient quality for downstream tasks. Videos are available at https://norweig1an.github.io/human-agent-joint-learning.github.io/.
HumanVLA: Towards Vision-Language Directed Object Rearrangement by Physical Humanoid
Jun 28, 2024Physical Human-Scene Interaction (HSI) plays a crucial role in numerous applications. However, existing HSI techniques are limited to specific object dynamics and privileged information, which prevents the development of more comprehensive applications. To address this limitation, we introduce HumanVLA for general object rearrangement directed by practical vision and language. A teacher-student framework is utilized to develop HumanVLA. A state-based teacher policy is trained first using goal-conditioned reinforcement learning and adversarial motion prior. Then, it is distilled into a vision-language-action model via behavior cloning. We propose several key insights to facilitate the large-scale learning process. To support general object rearrangement by physical humanoid, we introduce a novel Human-in-the-Room dataset encompassing various rearrangement tasks. Through extensive experiments and analysis, we demonstrate the effectiveness of the proposed approach.
Graspness Discovery in Clutters for Fast and Accurate Grasp Detection
Jun 17, 2024



Efficient and robust grasp pose detection is vital for robotic manipulation. For general 6 DoF grasping, conventional methods treat all points in a scene equally and usually adopt uniform sampling to select grasp candidates. However, we discover that ignoring where to grasp greatly harms the speed and accuracy of current grasp pose detection methods. In this paper, we propose "graspness", a quality based on geometry cues that distinguishes graspable areas in cluttered scenes. A look-ahead searching method is proposed for measuring the graspness and statistical results justify the rationality of our method. To quickly detect graspness in practice, we develop a neural network named cascaded graspness model to approximate the searching process. Extensive experiments verify the stability, generality and effectiveness of our graspness model, allowing it to be used as a plug-and-play module for different methods. A large improvement in accuracy is witnessed for various previous methods after equipping our graspness model. Moreover, we develop GSNet, an end-to-end network that incorporates our graspness model for early filtering of low-quality predictions. Experiments on a large-scale benchmark, GraspNet-1Billion, show that our method outperforms previous arts by a large margin (30+ AP) and achieves a high inference speed. The library of GSNet has been integrated into AnyGrasp, which is at https://github.com/graspnet/anygrasp_sdk.
Low-Rank Similarity Mining for Multimodal Dataset Distillation
Jun 06, 2024Though dataset distillation has witnessed rapid development in recent years, the distillation of multimodal data, e.g., image-text pairs, poses unique and under-explored challenges. Unlike unimodal data, image-text contrastive learning (ITC) data lack inherent categorization and should instead place greater emphasis on modality correspondence. In this work, we propose Low-Rank Similarity Mining (LoRS) for multimodal dataset distillation, that concurrently distills a ground truth similarity matrix with image-text pairs, and leverages low-rank factorization for efficiency and scalability. The proposed approach brings significant improvement to the existing algorithms, marking a significant contribution to the field of visual-language dataset distillation. We advocate adopting LoRS as a foundational synthetic data setup for image-text dataset distillation. Our code is available at https://github.com/silicx/LoRS_Distill.
The SkatingVerse Workshop & Challenge: Methods and Results
May 27, 2024

The SkatingVerse Workshop & Challenge aims to encourage research in developing novel and accurate methods for human action understanding. The SkatingVerse dataset used for the SkatingVerse Challenge has been publicly released. There are two subsets in the dataset, i.e., the training subset and testing subset. The training subsets consists of 19,993 RGB video sequences, and the testing subsets consists of 8,586 RGB video sequences. Around 10 participating teams from the globe competed in the SkatingVerse Challenge. In this paper, we provide a brief summary of the SkatingVerse Workshop & Challenge including brief introductions to the top three methods. The submission leaderboard will be reopened for researchers that are interested in the human action understanding challenge. The benchmark dataset and other information can be found at: https://skatingverse.github.io/.
DiffGen: Robot Demonstration Generation via Differentiable Physics Simulation, Differentiable Rendering, and Vision-Language Model
May 12, 2024
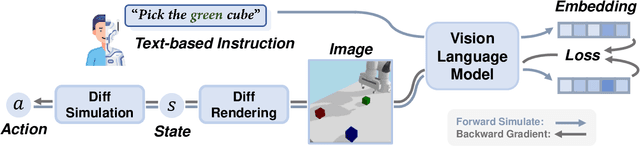
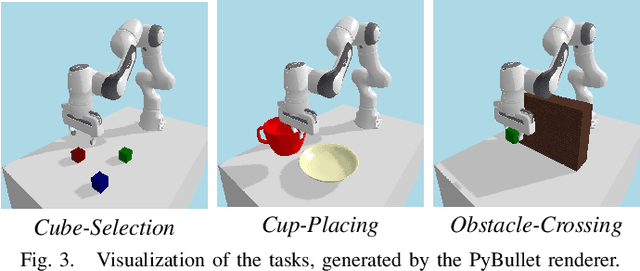
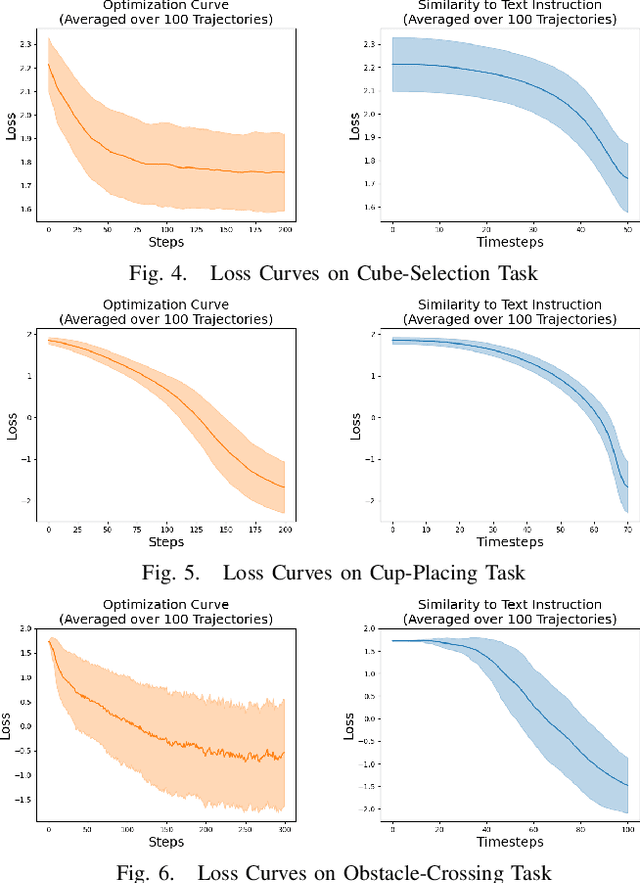
Generating robot demonstrations through simulation is widely recognized as an effective way to scale up robot data. Previous work often trained reinforcement learning agents to generate expert policies, but this approach lacks sample efficiency. Recently, a line of work has attempted to generate robot demonstrations via differentiable simulation, which is promising but heavily relies on reward design, a labor-intensive process. In this paper, we propose DiffGen, a novel framework that integrates differentiable physics simulation, differentiable rendering, and a vision-language model to enable automatic and efficient generation of robot demonstrations. Given a simulated robot manipulation scenario and a natural language instruction, DiffGen can generate realistic robot demonstrations by minimizing the distance between the embedding of the language instruction and the embedding of the simulated observation after manipulation. The embeddings are obtained from the vision-language model, and the optimization is achieved by calculating and descending gradients through the differentiable simulation, differentiable rendering, and vision-language model components, thereby accomplishing the specified task. Experiments demonstrate that with DiffGen, we could efficiently and effectively generate robot data with minimal human effort or training time.
RISE: 3D Perception Makes Real-World Robot Imitation Simple and Effective
Apr 18, 2024



Precise robot manipulations require rich spatial information in imitation learning. Image-based policies model object positions from fixed cameras, which are sensitive to camera view changes. Policies utilizing 3D point clouds usually predict keyframes rather than continuous actions, posing difficulty in dynamic and contact-rich scenarios. To utilize 3D perception efficiently, we present RISE, an end-to-end baseline for real-world imitation learning, which predicts continuous actions directly from single-view point clouds. It compresses the point cloud to tokens with a sparse 3D encoder. After adding sparse positional encoding, the tokens are featurized using a transformer. Finally, the features are decoded into robot actions by a diffusion head. Trained with 50 demonstrations for each real-world task, RISE surpasses currently representative 2D and 3D policies by a large margin, showcasing significant advantages in both accuracy and efficiency. Experiments also demonstrate that RISE is more general and robust to environmental change compared with previous baselines. Project website: rise-policy.github.io.
MS-MANO: Enabling Hand Pose Tracking with Biomechanical Constraints
Apr 16, 2024



This work proposes a novel learning framework for visual hand dynamics analysis that takes into account the physiological aspects of hand motion. The existing models, which are simplified joint-actuated systems, often produce unnatural motions. To address this, we integrate a musculoskeletal system with a learnable parametric hand model, MANO, to create a new model, MS-MANO. This model emulates the dynamics of muscles and tendons to drive the skeletal system, imposing physiologically realistic constraints on the resulting torque trajectories. We further propose a simulation-in-the-loop pose refinement framework, BioPR, that refines the initial estimated pose through a multi-layer perceptron (MLP) network. Our evaluation of the accuracy of MS-MANO and the efficacy of the BioPR is conducted in two separate parts. The accuracy of MS-MANO is compared with MyoSuite, while the efficacy of BioPR is benchmarked against two large-scale public datasets and two recent state-of-the-art methods. The results demonstrate that our approach consistently improves the baseline methods both quantitatively and qualitatively.
SemGrasp: Semantic Grasp Generation via Language Aligned Discretization
Apr 04, 2024



Generating natural human grasps necessitates consideration of not just object geometry but also semantic information. Solely depending on object shape for grasp generation confines the applications of prior methods in downstream tasks. This paper presents a novel semantic-based grasp generation method, termed SemGrasp, which generates a static human grasp pose by incorporating semantic information into the grasp representation. We introduce a discrete representation that aligns the grasp space with semantic space, enabling the generation of grasp postures in accordance with language instructions. A Multimodal Large Language Model (MLLM) is subsequently fine-tuned, integrating object, grasp, and language within a unified semantic space. To facilitate the training of SemGrasp, we have compiled a large-scale, grasp-text-aligned dataset named CapGrasp, featuring about 260k detailed captions and 50k diverse grasps. Experimental findings demonstrate that SemGrasp efficiently generates natural human grasps in alignment with linguistic intentions. Our code, models, and dataset are available publicly at: https://kailinli.github.io/SemGrasp.