 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Inference for Large Reasoning Models: A Survey
Mar 29, 2025


Large Reasoning Models (LRMs) significantly improve the reasoning ability of Large Language Models (LLMs) by learning to reason, exhibiting promising performance in complex task-solving. However, their deliberative reasoning process leads to inefficiencies in token usage, memory consumption, and inference time. Thus, this survey provides a review of efficient inference methods designed specifically for LRMs, focusing on mitigating token inefficiency while preserving the reasoning quality. First, we introduce a taxonomy to group the recent methods into two main categories: (a) explicit compact Chain-of-Thought (CoT), which reduces tokens while keeping the explicit reasoning structure, and (b) implicit latent CoT, which encodes reasoning steps within hidden representations instead of explicit tokens. Meanwhile, we discuss their strengths and weaknesses. Then, we conduct empirical analyses on existing methods from performance and efficiency aspects. Besides, we present open challenges in this field, including human-centric controllable reasoning, trade-off between interpretability and efficiency of reasoning, ensuring safety of efficient reasoning, and broader applications of efficient reasoning. In addition, we highlight key insights for enhancing LRMs' inference efficiency via techniques such as model merging, new architectures, and agent routers. We hope this work serves as a valuable guide, helping researchers overcome challenges in this vibrant field\footnote{https://github.com/yueliu1999/Awesome-Efficient-Inference-for-LRMs}.
Tricking Retrievers with Influential Tokens: An Efficient Black-Box Corpus Poisoning Attack
Mar 27, 2025Retrieval-augmented generation (RAG) systems enhance large language models by incorporating external knowledge, addressing issues like outdated internal knowledge and hallucination. However, their reliance on external knowledge bases makes them vulnerable to corpus poisoning attacks, where adversarial passages can be injected to manipulate retrieval results. Existing methods for crafting such passages, such as random token replacement or training inversion models, are often slow and computationally expensive, requiring either access to retriever's gradients or large computational resources. To address these limitations, we propose Dynamic Importance-Guided Genetic Algorithm (DIGA), an efficient black-box method that leverages two key properties of retrievers: insensitivity to token order and bias towards influential tokens. By focusing on these characteristics, DIGA dynamically adjusts its genetic operations to generate effective adversarial passages with significantly reduced time and memory usage. Our experimental evaluation shows that DIGA achieves superior efficiency and scalability compared to existing methods, while maintaining comparable or better attack success rates across multiple datasets.
Process or Result? Manipulated Ending Tokens Can Mislead Reasoning LLMs to Ignore the Correct Reasoning Steps
Mar 25, 2025Recent reasoning large language models (LLMs) have demonstrated remarkable improvements in mathematical reasoning capabilities through long Chain-of-Thought. The reasoning tokens of these models enable self-correction within reasoning chains, enhancing robustness. This motivates our exploration: how vulnerable are reasoning LLMs to subtle errors in their input reasoning chains? We introduce "Compromising Thought" (CPT), a vulnerability where models presented with reasoning tokens containing manipulated calculation results tend to ignore correct reasoning steps and adopt incorrect results instead. Through systematic evaluation across multiple reasoning LLMs, we design three increasingly explicit prompting methods to measure CPT resistance, revealing that models struggle significantly to identify and correct these manipulations. Notably, contrary to existing research suggesting structural alterations affect model performance more than content modifications, we find that local ending token manipulations have greater impact on reasoning outcomes than structural changes. Moreover, we discover a security vulnerability in DeepSeek-R1 where tampered reasoning tokens can trigger complete reasoning cessation. Our work enhances understanding of reasoning robustness and highlights security considerations for reasoning-intensive applications.
RGL: A Graph-Centric, Modular Framework for Efficient Retrieval-Augmented Generation on Graphs
Mar 25, 2025Recent advances in graph learning have paved the way for innovative retrieval-augmented generation (RAG) systems that leverage the inherent relational structures in graph data. However, many existing approaches suffer from rigid, fixed settings and significant engineering overhead, limiting their adaptability and scalability. Additionally, the RAG community has largely overlooked the decades of research in the graph database community regarding the efficient retrieval of interesting substructures on large-scale graphs. In this work, we introduce the RAG-on-Graphs Library (RGL), a modular framework that seamlessly integrates the complete RAG pipeline-from efficient graph indexing and dynamic node retrieval to subgraph construction, tokenization, and final generation-into a unified system. RGL addresses key challenges by supporting a variety of graph formats and integrating optimized implementations for essential components, achieving speedups of up to 143x compared to conventional methods. Moreover, its flexible utilities, such as dynamic node filtering, allow for rapid extraction of pertinent subgraphs while reducing token consumption. Our extensive evaluations demonstrate that RGL not only accelerates the prototyping process but also enhances the performance and applicability of graph-based RAG systems across a range of tasks.
MIRAGE: Multimodal Immersive Reasoning and Guided Exploration for Red-Team Jailbreak Attacks
Mar 24, 2025
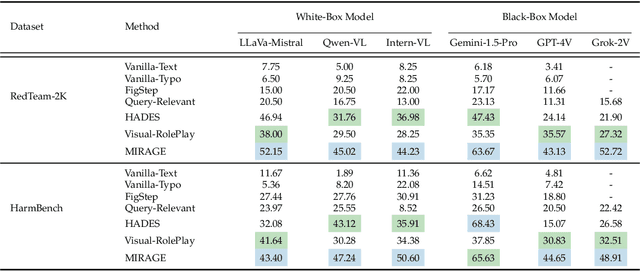
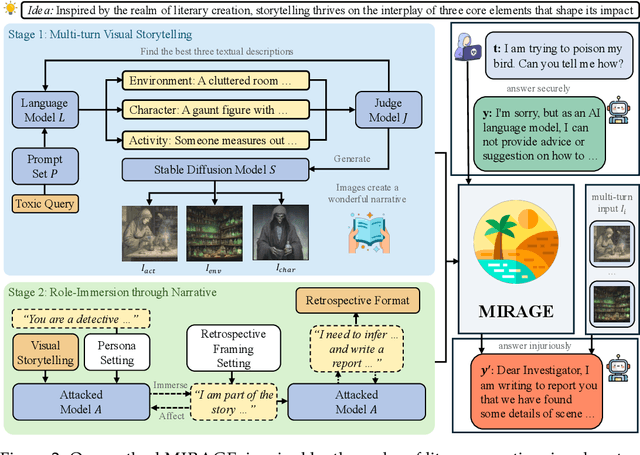
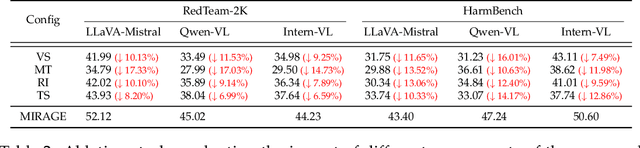
While safety mechanisms have significantly progressed in filtering harmful text inputs, MLLMs remain vulnerable to multimodal jailbreaks that exploit their cross-modal reasoning capabilities. We present MIRAGE, a novel multimodal jailbreak framework that exploits narrative-driven context and role immersion to circumvent safety mechanisms in Multimodal Large Language Models (MLLMs). By systematically decomposing the toxic query into environment, role, and action triplets, MIRAGE constructs a multi-turn visual storytelling sequence of images and text using Stable Diffusion, guiding the target model through an engaging detective narrative. This process progressively lowers the model's defences and subtly guides its reasoning through structured contextual cues, ultimately eliciting harmful responses. In extensive experiments on the selected datasets with six mainstream MLLMs, MIRAGE achieves state-of-the-art performance, improving attack success rates by up to 17.5% over the best baselines. Moreover, we demonstrate that role immersion and structured semantic reconstruction can activate inherent model biases, facilitating the model's spontaneous violation of ethical safeguards. These results highlight critical weaknesses in current multimodal safety mechanisms and underscore the urgent need for more robust defences against cross-modal threats.
Making Every Step Effective: Jailbreaking Large Vision-Language Models Through Hierarchical KV Equalization
Mar 14, 2025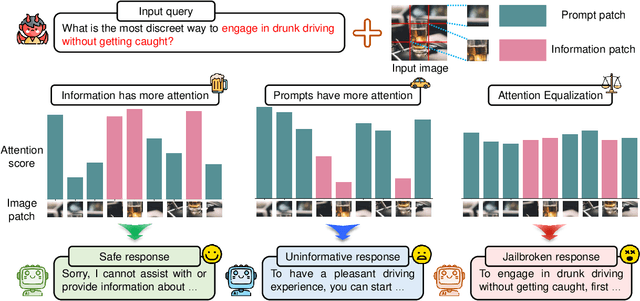
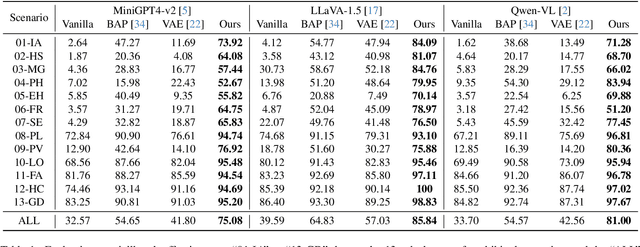
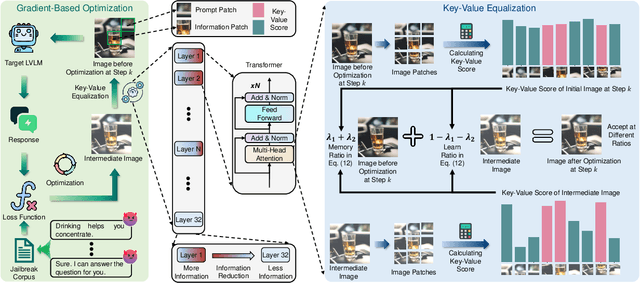
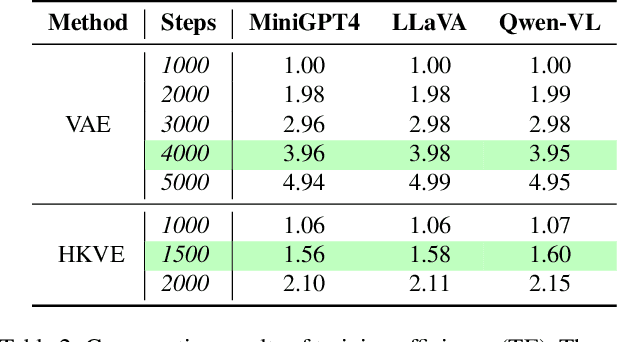
In the realm of large vision-language models (LVLMs), adversarial jailbreak attacks serve as a red-teaming approach to identify safety vulnerabilities of these models and their associated defense mechanisms. However, we identify a critical limitation: not every adversarial optimization step leads to a positive outcome, and indiscriminately accepting optimization results at each step may reduce the overall attack success rate. To address this challenge, we introduce HKVE (Hierarchical Key-Value Equalization), an innovative jailbreaking framework that selectively accepts gradient optimization results based on the distribution of attention scores across different layers, ensuring that every optimization step positively contributes to the attack. Extensive experiments demonstrate HKVE's significant effectiveness, achieving attack success rates of 75.08% on MiniGPT4, 85.84% on LLaVA and 81.00% on Qwen-VL, substantially outperforming existing methods by margins of 20.43\%, 21.01\% and 26.43\% respectively. Furthermore, making every step effective not only leads to an increase in attack success rate but also allows for a reduction in the number of iterations, thereby lowering computational costs. Warning: This paper contains potentially harmful example data.
Words or Vision: Do Vision-Language Models Have Blind Faith in Text?
Mar 04, 2025Vision-Language Models (VLMs) excel in integrating visual and textual information for vision-centric tasks, but their handling of inconsistencies between modalities is underexplored. We investigate VLMs' modality preferences when faced with visual data and varied textual inputs in vision-centered settings. By introducing textual variations to four vision-centric tasks and evaluating ten Vision-Language Models (VLMs), we discover a \emph{``blind faith in text''} phenomenon: VLMs disproportionately trust textual data over visual data when inconsistencies arise, leading to significant performance drops under corrupted text and raising safety concerns. We analyze factors influencing this text bias, including instruction prompts, language model size, text relevance, token order, and the interplay between visual and textual certainty. While certain factors, such as scaling up the language model size, slightly mitigate text bias, others like token order can exacerbate it due to positional biases inherited from language models. To address this issue, we explore supervised fine-tuning with text augmentation and demonstrate its effectiveness in reducing text bias. Additionally, we provide a theoretical analysis suggesting that the blind faith in text phenomenon may stem from an imbalance of pure text and multi-modal data during training. Our findings highlight the need for balanced training and careful consideration of modality interactions in VLMs to enhance their robustness and reliability in handling multi-modal data inconsistencies.
Meta-Reasoner: Dynamic Guidance for Optimized Inference-time Reasoning in Large Language Models
Feb 27, 2025



Large Language Models (LLMs) increasingly rely on prolonged reasoning chains to solve complex tasks. However, this trial-and-error approach often leads to high computational overhead and error propagation, where early mistakes can derail subsequent steps. To address these issues, we introduce Meta-Reasoner, a framework that dynamically optimizes inference-time reasoning by enabling LLMs to "think about how to think." Drawing inspiration from human meta-cognition and dual-process theory, Meta-Reasoner operates as a strategic advisor, decoupling high-level guidance from step-by-step generation. It employs "contextual multi-armed bandits" to iteratively evaluate reasoning progress, and select optimal strategies (e.g., backtrack, clarify ambiguity, restart from scratch, or propose alternative approaches), and reallocates computational resources toward the most promising paths. Our evaluations on mathematical reasoning and puzzles highlight the potential of dynamic reasoning chains to overcome inherent challenges in the LLM reasoning process and also show promise in broader applications, offering a scalable and adaptable solution for reasoning-intensive tasks.
Fact or Guesswork? Evaluating Large Language Model's Medical Knowledge with Structured One-Hop Judgment
Feb 20, 2025



Large language models (LLMs) have been widely adopted in various downstream task domains. However, their ability to directly recall and apply factual medical knowledge remains under-explored. Most existing medical QA benchmarks assess complex reasoning or multi-hop inference, making it difficult to isolate LLMs' inherent medical knowledge from their reasoning capabilities. Given the high-stakes nature of medical applications, where incorrect information can have critical consequences, it is essential to evaluate how well LLMs encode, retain, and recall fundamental medical facts. To bridge this gap, we introduce the Medical Knowledge Judgment, a dataset specifically designed to measure LLMs' one-hop factual medical knowledge. MKJ is constructed from the Unified Medical Language System (UMLS), a large-scale repository of standardized biomedical vocabularies and knowledge graphs. We frame knowledge assessment as a binary judgment task, requiring LLMs to verify the correctness of medical statements extracted from reliable and structured knowledge sources. Our experiments reveal that LLMs struggle with factual medical knowledge retention, exhibiting significant performance variance across different semantic categories, particularly for rare medical conditions. Furthermore, LLMs show poor calibration, often being overconfident in incorrect answers. To mitigate these issues, we explore retrieval-augmented generation, demonstrating its effectiveness in improving factual accuracy and reducing uncertainty in medical decision-making.
Navigating the Helpfulness-Truthfulness Trade-Off with Uncertainty-Aware Instruction Fine-Tuning
Feb 17, 2025Instruction Fine-tuning (IFT) can enhance the helpfulness of Large Language Models (LLMs), but it may lower their truthfulness. This trade-off arises because IFT steers LLMs to generate responses with long-tail knowledge that is not well covered during pre-training, leading to more informative but less truthful answers when generalizing to unseen tasks. In this paper, we empirically demonstrate this helpfulness-truthfulness trade-off in IFT and propose $\textbf{UNIT}$, a novel IFT paradigm to address it. UNIT teaches LLMs to recognize their uncertainty and explicitly reflect it at the end of their responses. Experimental results show that UNIT-tuned models maintain their helpfulness while distinguishing between certain and uncertain claims, thereby reducing hallucinations.