 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRNA-FrameFlow: Flow Matching for de novo 3D RNA Backbone Design
Jun 19, 2024We introduce RNA-FrameFlow, the first generative model for 3D RNA backbone design. We build upon SE(3) flow matching for protein backbone generation and establish protocols for data preparation and evaluation to address unique challenges posed by RNA modeling. We formulate RNA structures as a set of rigid-body frames and associated loss functions which account for larger, more conformationally flexible RNA backbones (13 atoms per nucleotide) vs. proteins (4 atoms per residue). Toward tackling the lack of diversity in 3D RNA datasets, we explore training with structural clustering and cropping augmentations. Additionally, we define a suite of evaluation metrics to measure whether the generated RNA structures are globally self-consistent (via inverse folding followed by forward folding) and locally recover RNA-specific structural descriptors. The most performant version of RNA-FrameFlow generates locally realistic RNA backbones of 40-150 nucleotides, over 40% of which pass our validity criteria as measured by a self-consistency TM-score >= 0.45, at which two RNAs have the same global fold. Open-source code: https://github.com/rish-16/rna-backbone-design
Evaluating representation learning on the protein structure universe
Jun 19, 2024We introduce ProteinWorkshop, a comprehensive benchmark suite for representation learning on protein structures with Geometric Graph Neural Networks. We consider large-scale pre-training and downstream tasks on both experimental and predicted structures to enable the systematic evaluation of the quality of the learned structural representation and their usefulness in capturing functional relationships for downstream tasks. We find that: (1) large-scale pretraining on AlphaFold structures and auxiliary tasks consistently improve the performance of both rotation-invariant and equivariant GNNs, and (2) more expressive equivariant GNNs benefit from pretraining to a greater extent compared to invariant models. We aim to establish a common ground for the machine learning and computational biology communities to rigorously compare and advance protein structure representation learning. Our open-source codebase reduces the barrier to entry for working with large protein structure datasets by providing: (1) storage-efficient dataloaders for large-scale structural databases including AlphaFoldDB and ESM Atlas, as well as (2) utilities for constructing new tasks from the entire PDB. ProteinWorkshop is available at: github.com/a-r-j/ProteinWorkshop.
Multi-State RNA Design with Geometric Multi-Graph Neural Networks
May 25, 2023Computational RNA design has broad applications across synthetic biology and therapeutic development. Fundamental to the diverse biological functions of RNA is its conformational flexibility, enabling single sequences to adopt a variety of distinct 3D states. Currently, computational biomolecule design tasks are often posed as inverse problems, where sequences are designed based on adopting a single desired structural conformation. In this work, we propose gRNAde, a geometric RNA design pipeline that operates on sets of 3D RNA backbone structures to explicitly account for and reflect RNA conformational diversity in its designs. We demonstrate the utility of gRNAde for improving native sequence recovery over single-state approaches on a new large-scale 3D RNA design dataset, especially for multi-state and structurally diverse RNAs. Our code is available at https://github.com/chaitjo/geometric-rna-design
Utilising Graph Machine Learning within Drug Discovery and Development
Dec 09, 2020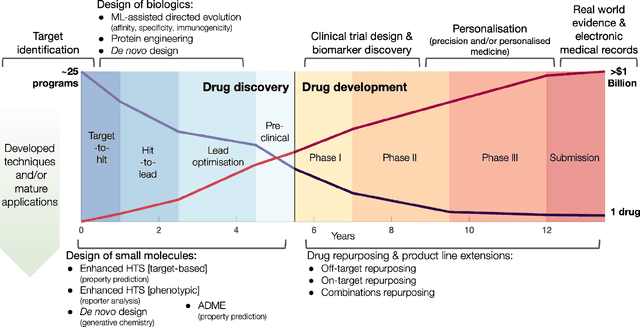
Graph Machine Learning (GML) is receiving growing interest within the pharmaceutical and biotechnology industries for its ability to model biomolecular structures, the functional relationships between them, and integrate multi-omic datasets - amongst other data types. Herein, we present a multidisciplinary academic-industrial review of the topic within the context of drug discovery and development. After introducing key terms and modelling approaches, we move chronologically through the drug development pipeline to identify and summarise work incorporating: target identification, design of small molecules and biologics, and drug repurposing. Whilst the field is still emerging, key milestones including repurposed drugs entering in vivo studies, suggest graph machine learning will become a modelling framework of choice within biomedical machine learning.
Message Passing Neural Processes
Sep 29, 2020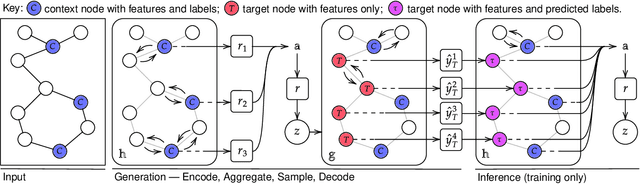
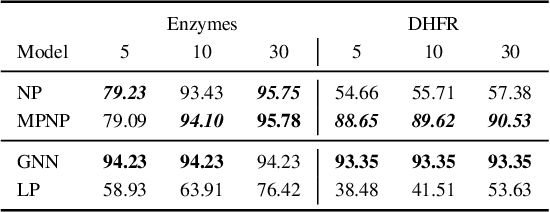
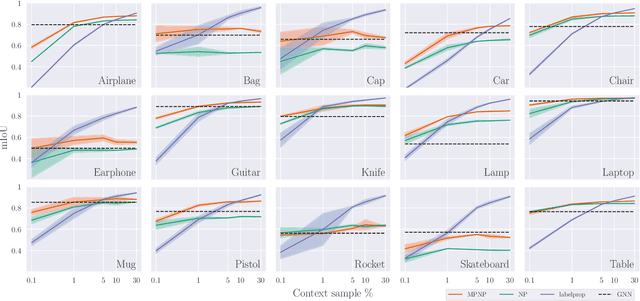
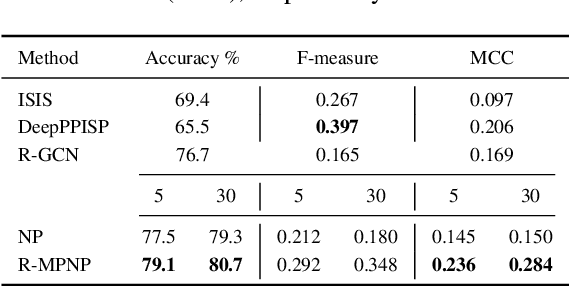
Neural Processes (NPs) are powerful and flexible models able to incorporate uncertainty when representing stochastic processes, while maintaining a linear time complexity. However, NPs produce a latent description by aggregating independent representations of context points and lack the ability to exploit relational information present in many datasets. This renders NPs ineffective in settings where the stochastic process is primarily governed by neighbourhood rules, such as cellular automata (CA), and limits performance for any task where relational information remains unused. We address this shortcoming by introducing Message Passing Neural Processes (MPNPs), the first class of NPs that explicitly makes use of relational structure within the model. Our evaluation shows that MPNPs thrive at lower sampling rates, on existing benchmarks and newly-proposed CA and Cora-Branched tasks. We further report strong generalisation over density-based CA rule-sets and significant gains in challenging arbitrary-labelling and few-shot learning setups.