 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMovie Gen: A Cast of Media Foundation Models
Oct 17, 2024



We present Movie Gen, a cast of foundation models that generates high-quality, 1080p HD videos with different aspect ratios and synchronized audio. We also show additional capabilities such as precise instruction-based video editing and generation of personalized videos based on a user's image. Our models set a new state-of-the-art on multiple tasks: text-to-video synthesis, video personalization, video editing, video-to-audio generation, and text-to-audio generation. Our largest video generation model is a 30B parameter transformer trained with a maximum context length of 73K video tokens, corresponding to a generated video of 16 seconds at 16 frames-per-second. We show multiple technical innovations and simplifications on the architecture, latent spaces, training objectives and recipes, data curation, evaluation protocols, parallelization techniques, and inference optimizations that allow us to reap the benefits of scaling pre-training data, model size, and training compute for training large scale media generation models. We hope this paper helps the research community to accelerate progress and innovation in media generation models. All videos from this paper are available at https://go.fb.me/MovieGenResearchVideos.
NC-NCD: Novel Class Discovery for Node Classification
Jul 25, 2024



Novel Class Discovery (NCD) involves identifying new categories within unlabeled data by utilizing knowledge acquired from previously established categories. However, existing NCD methods often struggle to maintain a balance between the performance of old and new categories. Discovering unlabeled new categories in a class-incremental way is more practical but also more challenging, as it is frequently hindered by either catastrophic forgetting of old categories or an inability to learn new ones. Furthermore, the implementation of NCD on continuously scalable graph-structured data remains an under-explored area. In response to these challenges, we introduce for the first time a more practical NCD scenario for node classification (i.e., NC-NCD), and propose a novel self-training framework with prototype replay and distillation called SWORD, adopted to our NC-NCD setting. Our approach enables the model to cluster unlabeled new category nodes after learning labeled nodes while preserving performance on old categories without reliance on old category nodes. SWORD achieves this by employing a self-training strategy to learn new categories and preventing the forgetting of old categories through the joint use of feature prototypes and knowledge distillation. Extensive experiments on four common benchmarks demonstrate the superiority of SWORD over other state-of-the-art methods.
High Fidelity Text-Guided Music Generation and Editing via Single-Stage Flow Matching
Jul 04, 2024



We introduce a simple and efficient text-controllable high-fidelity music generation and editing model. It operates on sequences of continuous latent representations from a low frame rate 48 kHz stereo variational auto encoder codec that eliminates the information loss drawback of discrete representations. Based on a diffusion transformer architecture trained on a flow-matching objective the model can generate and edit diverse high quality stereo samples of variable duration, with simple text descriptions. We also explore a new regularized latent inversion method for zero-shot test-time text-guided editing and demonstrate its superior performance over naive denoising diffusion implicit model (DDIM) inversion for variety of music editing prompts. Evaluations are conducted on both objective and subjective metrics and demonstrate that the proposed model is not only competitive to the evaluated baselines on a standard text-to-music benchmark - quality and efficiency-wise - but also outperforms previous state of the art for music editing when combined with our proposed latent inversion. Samples are available at https://melodyflow.github.io.
Learning Fine-Grained Controllability on Speech Generation via Efficient Fine-Tuning
Jun 10, 2024



As the scale of generative models continues to grow, efficient reuse and adaptation of pre-trained models have become crucial considerations. In this work, we propose Voicebox Adapter, a novel approach that integrates fine-grained conditions into a pre-trained Voicebox speech generation model using a cross-attention module. To ensure a smooth integration of newly added modules with pre-trained ones, we explore various efficient fine-tuning approaches. Our experiment shows that the LoRA with bias-tuning configuration yields the best performance, enhancing controllability without compromising speech quality. Across three fine-grained conditional generation tasks, we demonstrate the effectiveness and resource efficiency of Voicebox Adapter. Follow-up experiments further highlight the robustness of Voicebox Adapter across diverse data setups.
XLAVS-R: Cross-Lingual Audio-Visual Speech Representation Learning for Noise-Robust Speech Perception
Mar 21, 2024



Speech recognition and translation systems perform poorly on noisy inputs, which are frequent in realistic environments. Augmenting these systems with visual signals has the potential to improve robustness to noise. However, audio-visual (AV) data is only available in limited amounts and for fewer languages than audio-only resources. To address this gap, we present XLAVS-R, a cross-lingual audio-visual speech representation model for noise-robust speech recognition and translation in over 100 languages. It is designed to maximize the benefits of limited multilingual AV pre-training data, by building on top of audio-only multilingual pre-training and simplifying existing pre-training schemes. Extensive evaluation on the MuAViC benchmark shows the strength of XLAVS-R on downstream audio-visual speech recognition and translation tasks, where it outperforms the previous state of the art by up to 18.5% WER and 4.7 BLEU given noisy AV inputs, and enables strong zero-shot audio-visual ability with audio-only fine-tuning.
Towards Privacy-Aware Sign Language Translation at Scale
Feb 14, 2024



A major impediment to the advancement of sign language translation (SLT) is data scarcity. Much of the sign language data currently available on the web cannot be used for training supervised models due to the lack of aligned captions. Furthermore, scaling SLT using large-scale web-scraped datasets bears privacy risks due to the presence of biometric information, which the responsible development of SLT technologies should account for. In this work, we propose a two-stage framework for privacy-aware SLT at scale that addresses both of these issues. We introduce SSVP-SLT, which leverages self-supervised video pretraining on anonymized and unannotated videos, followed by supervised SLT finetuning on a curated parallel dataset. SSVP-SLT achieves state-of-the-art finetuned and zero-shot gloss-free SLT performance on the How2Sign dataset, outperforming the strongest respective baselines by over 3 BLEU-4. Based on controlled experiments, we further discuss the advantages and limitations of self-supervised pretraining and anonymization via facial obfuscation for SLT.
UMG-CLIP: A Unified Multi-Granularity Vision Generalist for Open-World Understanding
Jan 18, 2024



Vision-language foundation models, represented by Contrastive language-image pre-training (CLIP), have gained increasing attention for jointly understanding both vision and textual tasks. However, existing approaches primarily focus on training models to match global image representations with textual descriptions, thereby overlooking the critical alignment between local regions and corresponding text tokens. This paper extends CLIP with multi-granularity alignment. Notably, we deliberately construct a new dataset comprising pseudo annotations at various levels of granularities, encompassing image-level, region-level, and pixel-level captions/tags. Accordingly, we develop a unified multi-granularity learning framework, named UMG-CLIP, that simultaneously empowers the model with versatile perception abilities across different levels of detail. Equipped with parameter efficient tuning, UMG-CLIP surpasses current widely used CLIP models and achieves state-of-the-art performance on diverse image understanding benchmarks, including open-world recognition, retrieval, semantic segmentation, and panoptic segmentation tasks. We hope UMG-CLIP can serve as a valuable option for advancing vision-language foundation models.
Audiobox: Unified Audio Generation with Natural Language Prompts
Dec 25, 2023



Audio is an essential part of our life, but creating it often requires expertise and is time-consuming. Research communities have made great progress over the past year advancing the performance of large scale audio generative models for a single modality (speech, sound, or music) through adopting more powerful generative models and scaling data. However, these models lack controllability in several aspects: speech generation models cannot synthesize novel styles based on text description and are limited on domain coverage such as outdoor environments; sound generation models only provide coarse-grained control based on descriptions like "a person speaking" and would only generate mumbling human voices. This paper presents Audiobox, a unified model based on flow-matching that is capable of generating various audio modalities. We design description-based and example-based prompting to enhance controllability and unify speech and sound generation paradigms. We allow transcript, vocal, and other audio styles to be controlled independently when generating speech. To improve model generalization with limited labels, we adapt a self-supervised infilling objective to pre-train on large quantities of unlabeled audio. Audiobox sets new benchmarks on speech and sound generation (0.745 similarity on Librispeech for zero-shot TTS; 0.77 FAD on AudioCaps for text-to-sound) and unlocks new methods for generating audio with novel vocal and acoustic styles. We further integrate Bespoke Solvers, which speeds up generation by over 25 times compared to the default ODE solver for flow-matching, without loss of performance on several tasks. Our demo is available at https://audiobox.metademolab.com/
AiluRus: A Scalable ViT Framework for Dense Prediction
Nov 02, 2023Vision transformers (ViTs) have emerged as a prevalent architecture for vision tasks owing to their impressive performance. However, when it comes to handling long token sequences, especially in dense prediction tasks that require high-resolution input, the complexity of ViTs increases significantly. Notably, dense prediction tasks, such as semantic segmentation or object detection, emphasize more on the contours or shapes of objects, while the texture inside objects is less informative. Motivated by this observation, we propose to apply adaptive resolution for different regions in the image according to their importance. Specifically, at the intermediate layer of the ViT, we utilize a spatial-aware density-based clustering algorithm to select representative tokens from the token sequence. Once the representative tokens are determined, we proceed to merge other tokens into their closest representative token. Consequently, semantic similar tokens are merged together to form low-resolution regions, while semantic irrelevant tokens are preserved independently as high-resolution regions. This strategy effectively reduces the number of tokens, allowing subsequent layers to handle a reduced token sequence and achieve acceleration. We evaluate our proposed method on three different datasets and observe promising performance. For example, the "Segmenter ViT-L" model can be accelerated by 48% FPS without fine-tuning, while maintaining the performance. Additionally, our method can be applied to accelerate fine-tuning as well. Experimental results demonstrate that we can save 52% training time while accelerating 2.46 times FPS with only a 0.09% performance drop. The code is available at https://github.com/caddyless/ailurus/tree/main.
Generative Pre-training for Speech with Flow Matching
Oct 25, 2023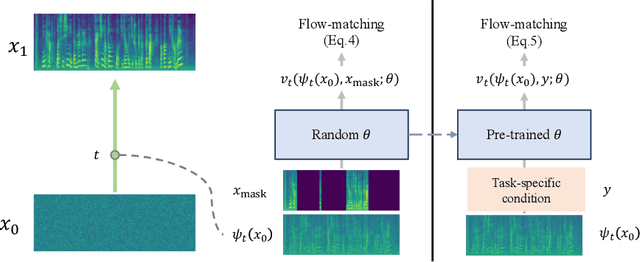
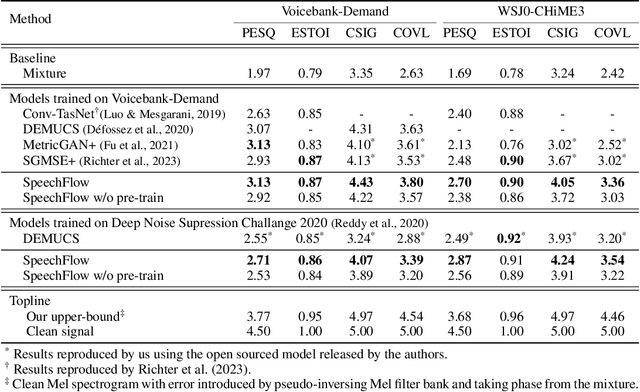
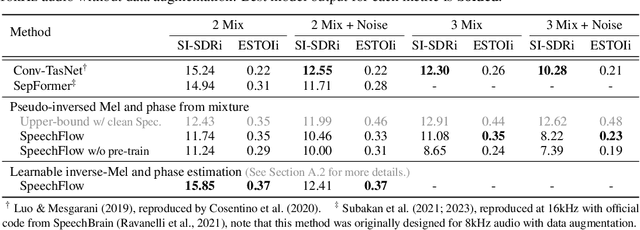
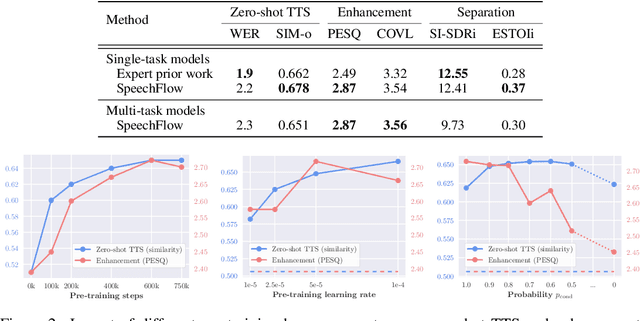
Generative models have gained more and more attention in recent years for their remarkable success in tasks that required estimating and sampling data distribution to generate high-fidelity synthetic data. In speech, text-to-speech synthesis and neural vocoder are good examples where generative models have shined. While generative models have been applied to different applications in speech, there exists no general-purpose generative model that models speech directly. In this work, we take a step toward this direction by showing a single pre-trained generative model can be adapted to different downstream tasks with strong performance. Specifically, we pre-trained a generative model, named SpeechFlow, on 60k hours of untranscribed speech with Flow Matching and masked conditions. Experiment results show the pre-trained generative model can be fine-tuned with task-specific data to match or surpass existing expert models on speech enhancement, separation, and synthesis. Our work suggested a foundational model for generation tasks in speech can be built with generative pre-training.