 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Cross-lingual Alignment: Balancing Transfer and Cultural Erasure in Multilingual LLMs
Oct 29, 2025



Cross-lingual alignment (CLA) aims to align multilingual representations, enabling Large Language Models (LLMs) to seamlessly transfer knowledge across languages. While intuitive, we hypothesize, this pursuit of representational convergence can inadvertently cause "cultural erasure", the functional loss of providing culturally-situated responses that should diverge based on the query language. In this work, we systematically analyze this trade-off by introducing a holistic evaluation framework, the transfer-localization plane, which quantifies both desirable knowledge transfer and undesirable cultural erasure. Using this framework, we re-evaluate recent CLA approaches and find that they consistently improve factual transfer at the direct cost of cultural localization across all six languages studied. Our investigation into the internal representations of these models reveals a key insight: universal factual transfer and culturally-specific knowledge are optimally steerable at different model layers. Based on this finding, we propose Surgical Steering, a novel inference-time method that disentangles these two objectives. By applying targeted activation steering to distinct layers, our approach achieves a better balance between the two competing dimensions, effectively overcoming the limitations of current alignment techniques.
SpeechQE: Estimating the Quality of Direct Speech Translation
Oct 28, 2024



Recent advances in automatic quality estimation for machine translation have exclusively focused on written language, leaving the speech modality underexplored. In this work, we formulate the task of quality estimation for speech translation (SpeechQE), construct a benchmark, and evaluate a family of systems based on cascaded and end-to-end architectures. In this process, we introduce a novel end-to-end system leveraging pre-trained text LLM. Results suggest that end-to-end approaches are better suited to estimating the quality of direct speech translation than using quality estimation systems designed for text in cascaded systems. More broadly, we argue that quality estimation of speech translation needs to be studied as a separate problem from that of text, and release our data and models to guide further research in this space.
Adapters for Altering LLM Vocabularies: What Languages Benefit the Most?
Oct 12, 2024



Vocabulary adaptation, which integrates new vocabulary into pre-trained language models (LMs), enables expansion to new languages and mitigates token over-fragmentation. However, existing approaches are limited by their reliance on heuristic or external embeddings. We propose VocADT, a novel method for vocabulary adaptation using adapter modules that are trained to learn the optimal linear combination of existing embeddings while keeping the model's weights fixed. VocADT offers a flexible and scalable solution without requiring external resources or language constraints. Across 11 languages-with various scripts, resource availability, and fragmentation-we demonstrate that VocADT outperforms the original Mistral model and other baselines across various multilingual tasks. We find that Latin-script languages and highly fragmented languages benefit the most from vocabulary adaptation. We further fine-tune the adapted model on the generative task of machine translation and find that vocabulary adaptation is still beneficial after fine-tuning and that VocADT is the most effective method.
The Prompt Report: A Systematic Survey of Prompting Techniques
Jun 06, 2024Generative Artificial Intelligence (GenAI) systems are being increasingly deployed across all parts of industry and research settings. Developers and end users interact with these systems through the use of prompting or prompt engineering. While prompting is a widespread and highly researched concept, there exists conflicting terminology and a poor ontological understanding of what constitutes a prompt due to the area's nascency. This paper establishes a structured understanding of prompts, by assembling a taxonomy of prompting techniques and analyzing their use. We present a comprehensive vocabulary of 33 vocabulary terms, a taxonomy of 58 text-only prompting techniques, and 40 techniques for other modalities. We further present a meta-analysis of the entire literature on natural language prefix-prompting.
XLAVS-R: Cross-Lingual Audio-Visual Speech Representation Learning for Noise-Robust Speech Perception
Mar 21, 2024



Speech recognition and translation systems perform poorly on noisy inputs, which are frequent in realistic environments. Augmenting these systems with visual signals has the potential to improve robustness to noise. However, audio-visual (AV) data is only available in limited amounts and for fewer languages than audio-only resources. To address this gap, we present XLAVS-R, a cross-lingual audio-visual speech representation model for noise-robust speech recognition and translation in over 100 languages. It is designed to maximize the benefits of limited multilingual AV pre-training data, by building on top of audio-only multilingual pre-training and simplifying existing pre-training schemes. Extensive evaluation on the MuAViC benchmark shows the strength of XLAVS-R on downstream audio-visual speech recognition and translation tasks, where it outperforms the previous state of the art by up to 18.5% WER and 4.7 BLEU given noisy AV inputs, and enables strong zero-shot audio-visual ability with audio-only fine-tuning.
Bridging Background Knowledge Gaps in Translation with Automatic Explicitation
Dec 03, 2023Translations help people understand content written in another language. However, even correct literal translations do not fulfill that goal when people lack the necessary background to understand them. Professional translators incorporate explicitations to explain the missing context by considering cultural differences between source and target audiences. Despite its potential to help users, NLP research on explicitation is limited because of the dearth of adequate evaluation methods. This work introduces techniques for automatically generating explicitations, motivated by WikiExpl: a dataset that we collect from Wikipedia and annotate with human translators. The resulting explicitations are useful as they help answer questions more accurately in a multilingual question answering framework.
Monotonic Simultaneous Translation with Chunk-wise Reordering and Refinement
Oct 18, 2021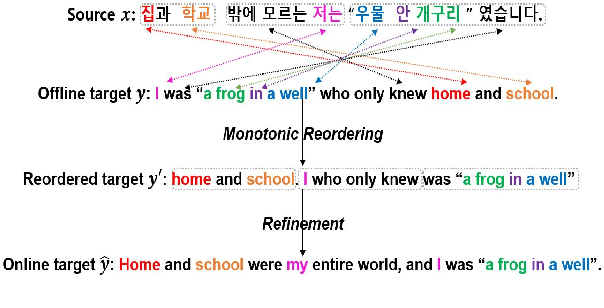
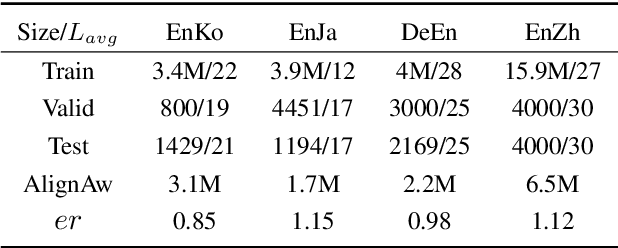
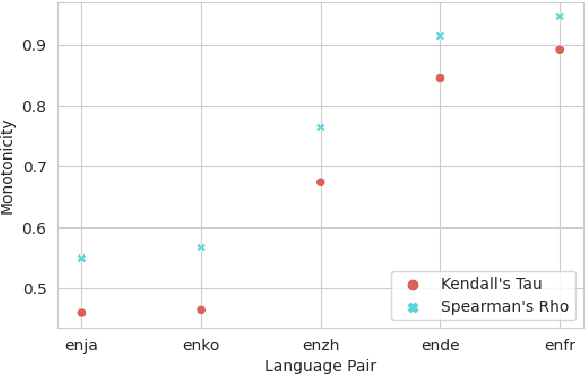
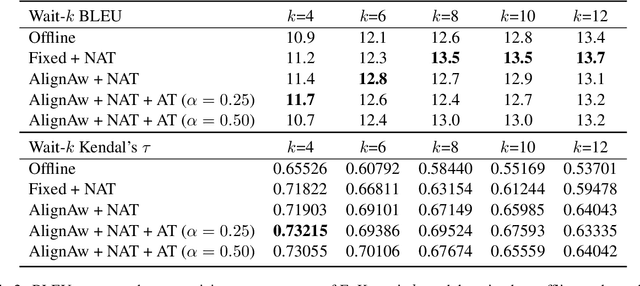
Recent work in simultaneous machine translation is often trained with conventional full sentence translation corpora, leading to either excessive latency or necessity to anticipate as-yet-unarrived words, when dealing with a language pair whose word orders significantly differ. This is unlike human simultaneous interpreters who produce largely monotonic translations at the expense of the grammaticality of a sentence being translated. In this paper, we thus propose an algorithm to reorder and refine the target side of a full sentence translation corpus, so that the words/phrases between the source and target sentences are aligned largely monotonically, using word alignment and non-autoregressive neural machine translation. We then train a widely used wait-k simultaneous translation model on this reordered-and-refined corpus. The proposed approach improves BLEU scores and resulting translations exhibit enhanced monotonicity with source sentences.