 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Robust Cross-View Consistency in Self-Supervised Monocular Depth Estimation
Sep 19, 2022
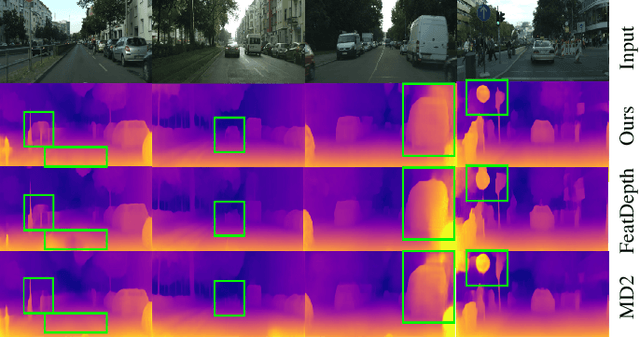
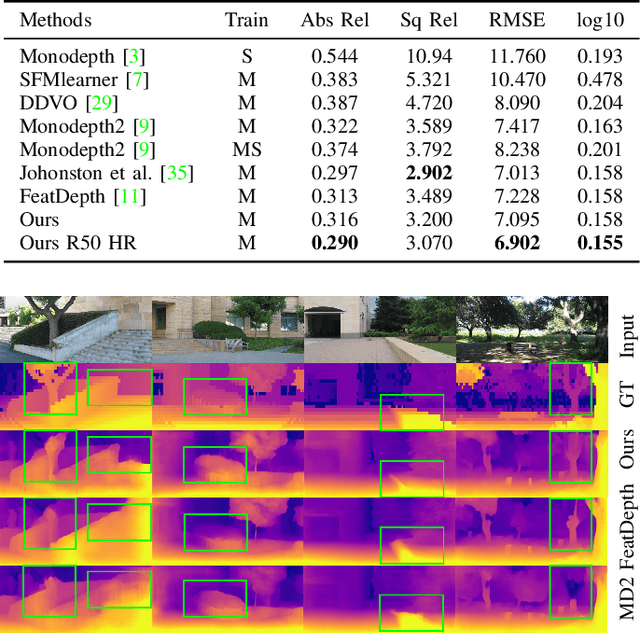
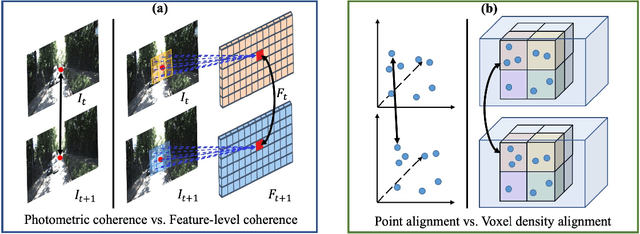
Remarkable progress has been made in self-supervised monocular depth estimation (SS-MDE) by exploring cross-view consistency, e.g., photometric consistency and 3D point cloud consistency. However, they are very vulnerable to illumination variance, occlusions, texture-less regions, as well as moving objects, making them not robust enough to deal with various scenes. To address this challenge, we study two kinds of robust cross-view consistency in this paper. Firstly, the spatial offset field between adjacent frames is obtained by reconstructing the reference frame from its neighbors via deformable alignment, which is used to align the temporal depth features via a Depth Feature Alignment (DFA) loss. Secondly, the 3D point clouds of each reference frame and its nearby frames are calculated and transformed into voxel space, where the point density in each voxel is calculated and aligned via a Voxel Density Alignment (VDA) loss. In this way, we exploit the temporal coherence in both depth feature space and 3D voxel space for SS-MDE, shifting the "point-to-point" alignment paradigm to the "region-to-region" one. Compared with the photometric consistency loss as well as the rigid point cloud alignment loss, the proposed DFA and VDA losses are more robust owing to the strong representation power of deep features as well as the high tolerance of voxel density to the aforementioned challenges. Experimental results on several outdoor benchmarks show that our method outperforms current state-of-the-art techniques. Extensive ablation study and analysis validate the effectiveness of the proposed losses, especially in challenging scenes. The code and models are available at https://github.com/sunnyHelen/RCVC-depth.
Robot Motion Planning as Video Prediction: A Spatio-Temporal Neural Network-based Motion Planner
Aug 24, 2022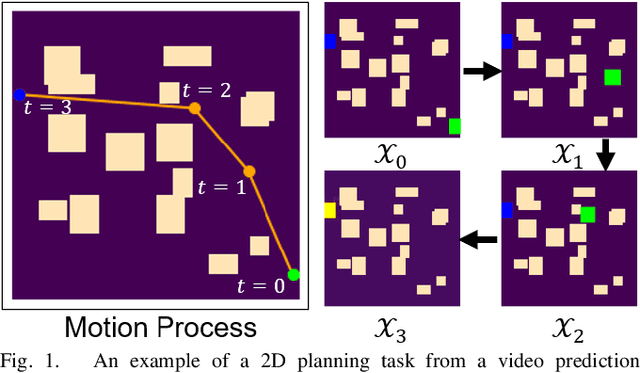
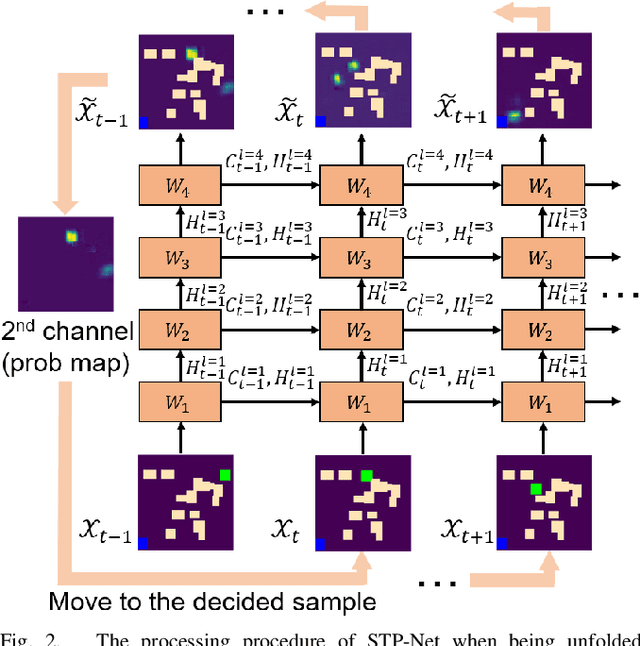
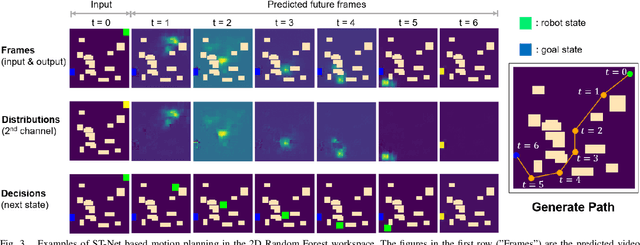
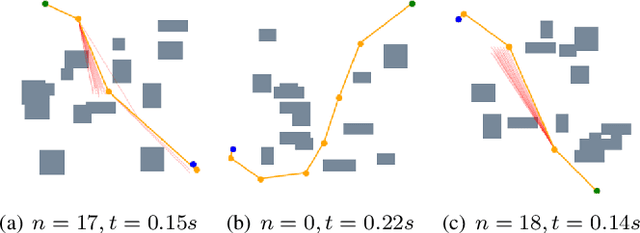
Neural network (NN)-based methods have emerged as an attractive approach for robot motion planning due to strong learning capabilities of NN models and their inherently high parallelism. Despite the current development in this direction, the efficient capture and processing of important sequential and spatial information, in a direct and simultaneous way, is still relatively under-explored. To overcome the challenge and unlock the potentials of neural networks for motion planning tasks, in this paper, we propose STP-Net, an end-to-end learning framework that can fully extract and leverage important spatio-temporal information to form an efficient neural motion planner. By interpreting the movement of the robot as a video clip, robot motion planning is transformed to a video prediction task that can be performed by STP-Net in both spatially and temporally efficient ways. Empirical evaluations across different seen and unseen environments show that, with nearly 100% accuracy (aka, success rate), STP-Net demonstrates very promising performance with respect to both planning speed and path cost. Compared with existing NN-based motion planners, STP-Net achieves at least 5x, 2.6x and 1.8x faster speed with lower path cost on 2D Random Forest, 2D Maze and 3D Random Forest environments, respectively. Furthermore, STP-Net can quickly and simultaneously compute multiple near-optimal paths in multi-robot motion planning tasks
RIBAC: Towards Robust and Imperceptible Backdoor Attack against Compact DNN
Aug 22, 2022
Recently backdoor attack has become an emerging threat to the security of deep neural network (DNN) models. To date, most of the existing studies focus on backdoor attack against the uncompressed model; while the vulnerability of compressed DNNs, which are widely used in the practical applications, is little exploited yet. In this paper, we propose to study and develop Robust and Imperceptible Backdoor Attack against Compact DNN models (RIBAC). By performing systematic analysis and exploration on the important design knobs, we propose a framework that can learn the proper trigger patterns, model parameters and pruning masks in an efficient way. Thereby achieving high trigger stealthiness, high attack success rate and high model efficiency simultaneously. Extensive evaluations across different datasets, including the test against the state-of-the-art defense mechanisms, demonstrate the high robustness, stealthiness and model efficiency of RIBAC. Code is available at https://github.com/huyvnphan/ECCV2022-RIBAC
* Code is available at https://github.com/huyvnphan/ECCV2022-RIBAC
The least-used key selection method for information retrieval in large-scale Cloud-based service repositories
Aug 16, 2022



As the number of devices connected to the Internet of Things (IoT) increases significantly, it leads to an exponential growth in the number of services that need to be processed and stored in the large-scale Cloud-based service repositories. An efficient service indexing model is critical for service retrieval and management of large-scale Cloud-based service repositories. The multilevel index model is the state-of-art service indexing model in recent years to improve service discovery and combination. This paper aims to optimize the model to consider the impact of unequal appearing probability of service retrieval request parameters and service input parameters on service retrieval and service addition operations. The least-used key selection method has been proposed to narrow the search scope of service retrieval and reduce its time. The experimental results show that the proposed least-used key selection method improves the service retrieval efficiency significantly compared with the designated key selection method in the case of the unequal appearing probability of parameters in service retrieval requests under three indexing models.
SafeRL-Kit: Evaluating Efficient Reinforcement Learning Methods for Safe Autonomous Driving
Jun 17, 2022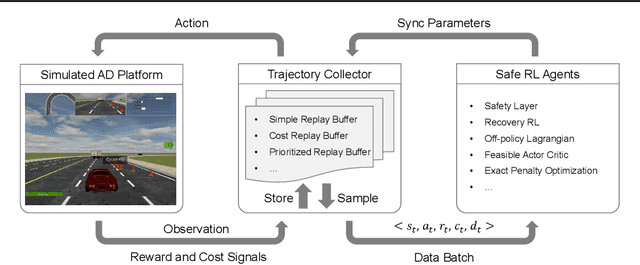
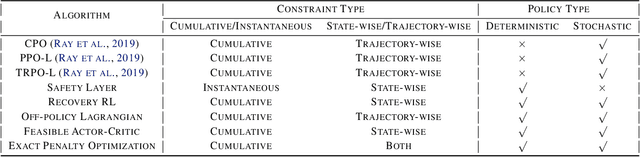
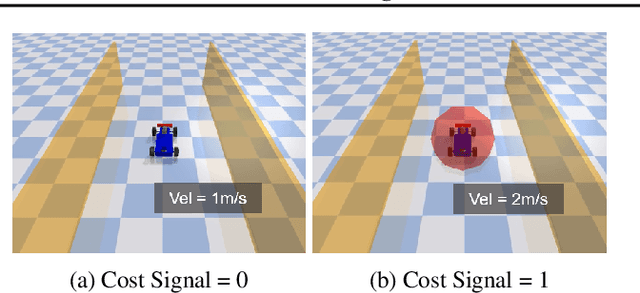
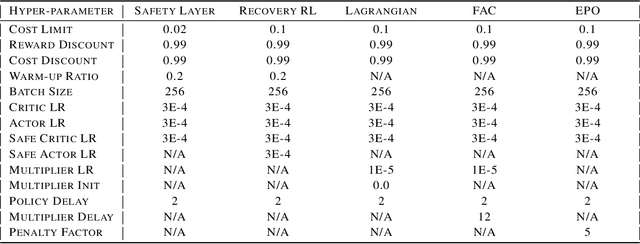
Safe reinforcement learning (RL) has achieved significant success on risk-sensitive tasks and shown promise in autonomous driving (AD) as well. Considering the distinctiveness of this community, efficient and reproducible baselines are still lacking for safe AD. In this paper, we release SafeRL-Kit to benchmark safe RL methods for AD-oriented tasks. Concretely, SafeRL-Kit contains several latest algorithms specific to zero-constraint-violation tasks, including Safety Layer, Recovery RL, off-policy Lagrangian method, and Feasible Actor-Critic. In addition to existing approaches, we propose a novel first-order method named Exact Penalty Optimization (EPO) and sufficiently demonstrate its capability in safe AD. All algorithms in SafeRL-Kit are implemented (i) under the off-policy setting, which improves sample efficiency and can better leverage past logs; (ii) with a unified learning framework, providing off-the-shelf interfaces for researchers to incorporate their domain-specific knowledge into fundamental safe RL methods. Conclusively, we conduct a comparative evaluation of the above algorithms in SafeRL-Kit and shed light on their efficacy for safe autonomous driving. The source code is available at \href{ https://github.com/zlr20/saferl_kit}{this https URL}.
Penalized Proximal Policy Optimization for Safe Reinforcement Learning
May 24, 2022
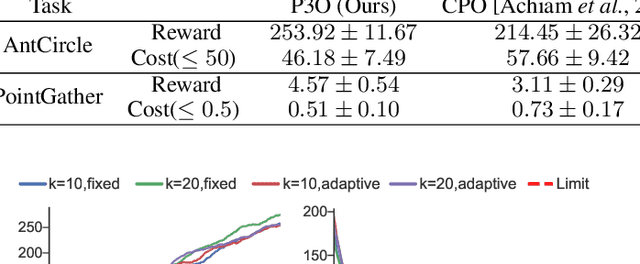
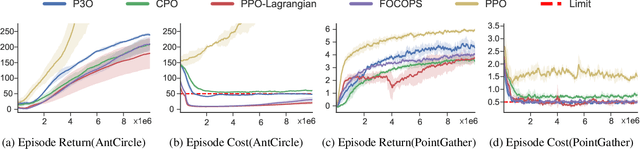
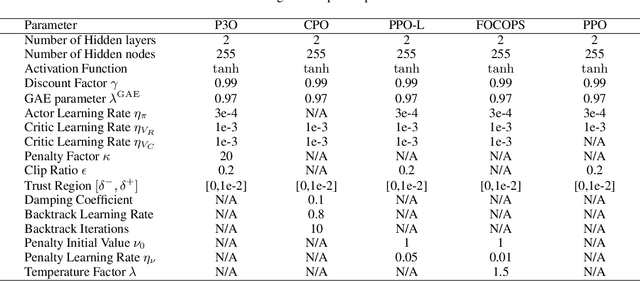
Safe reinforcement learning aims to learn the optimal policy while satisfying safety constraints, which is essential in real-world applications. However, current algorithms still struggle for efficient policy updates with hard constraint satisfaction. In this paper, we propose Penalized Proximal Policy Optimization (P3O), which solves the cumbersome constrained policy iteration via a single minimization of an equivalent unconstrained problem. Specifically, P3O utilizes a simple-yet-effective penalty function to eliminate cost constraints and removes the trust-region constraint by the clipped surrogate objective. We theoretically prove the exactness of the proposed method with a finite penalty factor and provide a worst-case analysis for approximate error when evaluated on sample trajectories. Moreover, we extend P3O to more challenging multi-constraint and multi-agent scenarios which are less studied in previous work. Extensive experiments show that P3O outperforms state-of-the-art algorithms with respect to both reward improvement and constraint satisfaction on a set of constrained locomotive tasks.
Birds of A Feather Flock Together: Category-Divergence Guidance for Domain Adaptive Segmentation
Apr 05, 2022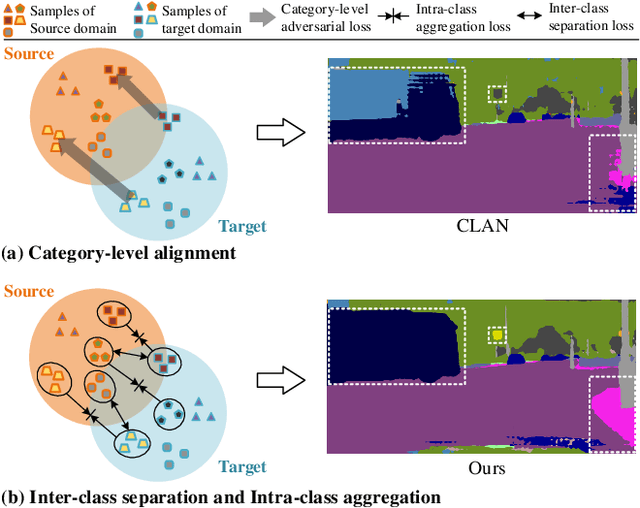

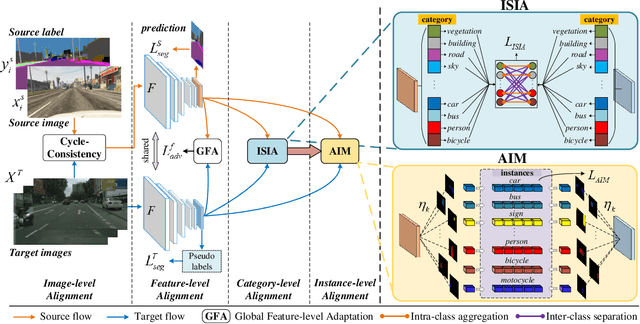
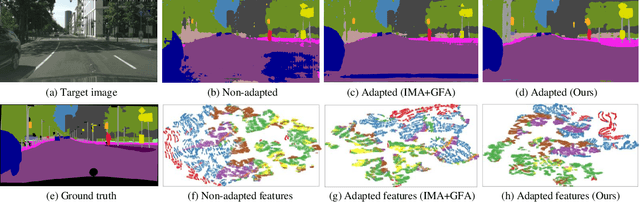
Unsupervised domain adaptation (UDA) aims to enhance the generalization capability of a certain model from a source domain to a target domain. Present UDA models focus on alleviating the domain shift by minimizing the feature discrepancy between the source domain and the target domain but usually ignore the class confusion problem. In this work, we propose an Inter-class Separation and Intra-class Aggregation (ISIA) mechanism. It encourages the cross-domain representative consistency between the same categories and differentiation among diverse categories. In this way, the features belonging to the same categories are aligned together and the confusable categories are separated. By measuring the align complexity of each category, we design an Adaptive-weighted Instance Matching (AIM) strategy to further optimize the instance-level adaptation. Based on our proposed methods, we also raise a hierarchical unsupervised domain adaptation framework for cross-domain semantic segmentation task. Through performing the image-level, feature-level, category-level and instance-level alignment, our method achieves a stronger generalization performance of the model from the source domain to the target domain. In two typical cross-domain semantic segmentation tasks, i.e., GTA5 to Cityscapes and SYNTHIA to Cityscapes, our method achieves the state-of-the-art segmentation accuracy. We also build two cross-domain semantic segmentation datasets based on the publicly available data, i.e., remote sensing building segmentation and road segmentation, for domain adaptive segmentation.
Don't Touch What Matters: Task-Aware Lipschitz Data Augmentation for Visual Reinforcement Learning
Feb 22, 2022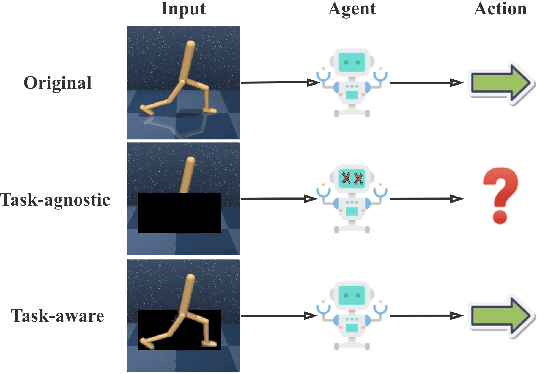
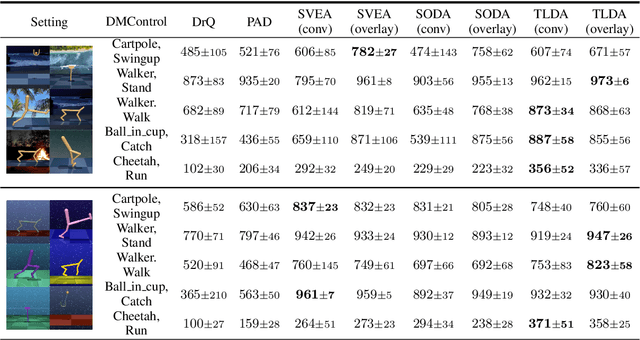
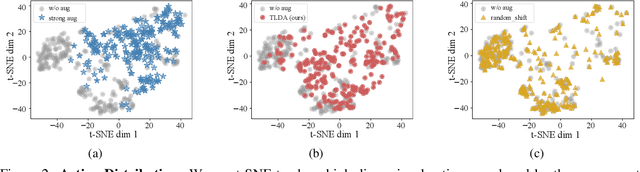
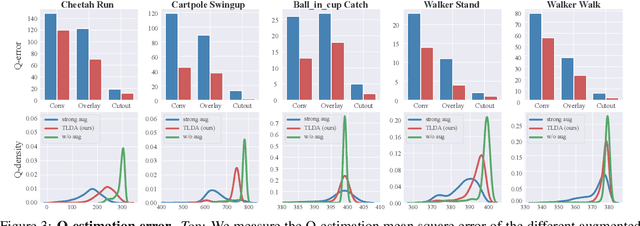
One of the key challenges in visual Reinforcement Learning (RL) is to learn policies that can generalize to unseen environments. Recently, data augmentation techniques aiming at enhancing data diversity have demonstrated proven performance in improving the generalization ability of learned policies. However, due to the sensitivity of RL training, naively applying data augmentation, which transforms each pixel in a task-agnostic manner, may suffer from instability and damage the sample efficiency, thus further exacerbating the generalization performance. At the heart of this phenomenon is the diverged action distribution and high-variance value estimation in the face of augmented images. To alleviate this issue, we propose Task-aware Lipschitz Data Augmentation (TLDA) for visual RL, which explicitly identifies the task-correlated pixels with large Lipschitz constants, and only augments the task-irrelevant pixels. To verify the effectiveness of TLDA, we conduct extensive experiments on DeepMind Control suite, CARLA and DeepMind Manipulation tasks, showing that TLDA improves both sample efficiency in training time and generalization in test time. It outperforms previous state-of-the-art methods across the 3 different visual control benchmarks.
BTPK-based learning: An Interpretable Method for Named Entity Recognition
Jan 24, 2022Named entity recognition (NER) is an essential task in natural language processing, but the internal mechanism of most NER models is a black box for users. In some high-stake decision-making areas, improving the interpretability of an NER method is crucial but challenging. In this paper, based on the existing Deterministic Talmudic Public announcement logic (TPK) model, we propose a novel binary tree model (called BTPK) and apply it to two widely used Bi-RNNs to obtain BTPK-based interpretable ones. Then, we design a counterfactual verification module to verify the BTPK-based learning method. Experimental results on three public datasets show that the BTPK-based learning outperform two classical Bi-RNNs with self-attention, especially on small, simple data and relatively large, complex data. Moreover, the counterfactual verification demonstrates that the explanations provided by the BTPK-based learning method are reasonable and accurate in NER tasks. Besides, the logical reasoning based on BTPK shows how Bi-RNNs handle NER tasks, with different distance of public announcements on long and complex sequences.
Hybrid intelligence for dynamic job-shop scheduling with deep reinforcement learning and attention mechanism
Jan 03, 2022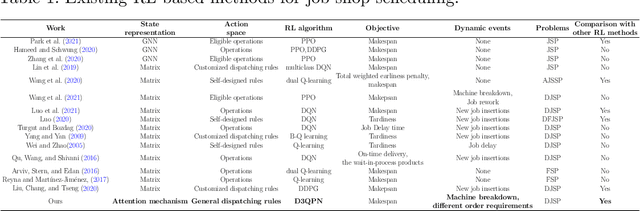
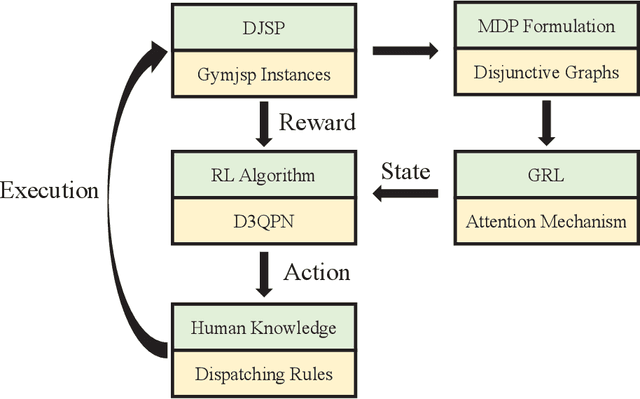
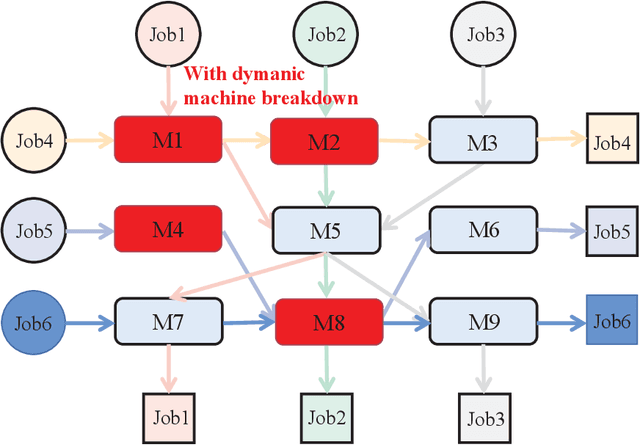

The dynamic job-shop scheduling problem (DJSP) is a class of scheduling tasks that specifically consider the inherent uncertainties such as changing order requirements and possible machine breakdown in realistic smart manufacturing settings. Since traditional methods cannot dynamically generate effective scheduling strategies in face of the disturbance of environments, we formulate the DJSP as a Markov decision process (MDP) to be tackled by reinforcement learning (RL). For this purpose, we propose a flexible hybrid framework that takes disjunctive graphs as states and a set of general dispatching rules as the action space with minimum prior domain knowledge. The attention mechanism is used as the graph representation learning (GRL) module for the feature extraction of states, and the double dueling deep Q-network with prioritized replay and noisy networks (D3QPN) is employed to map each state to the most appropriate dispatching rule. Furthermore, we present Gymjsp, a public benchmark based on the well-known OR-Library, to provide a standardized off-the-shelf facility for RL and DJSP research communities. Comprehensive experiments on various DJSP instances confirm that our proposed framework is superior to baseline algorithms with smaller makespan across all instances and provide empirical justification for the validity of the various components in the hybrid framework.