 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Combinatorial Optimization via Preference Optimization
Mar 10, 2025



Neural Combinatorial Optimization (NCO) has emerged as a promising approach for NP-hard problems. However, prevailing RL-based methods suffer from low sample efficiency due to sparse rewards and underused solutions. We propose Preference Optimization for Combinatorial Optimization (POCO), a training paradigm that leverages solution preferences via objective values. It introduces: (1) an efficient preference pair construction for better explore and exploit solutions, and (2) a novel loss function that adaptively scales gradients via objective differences, removing reliance on reward models or reference policies. Experiments on Job-Shop Scheduling (JSP), Traveling Salesman (TSP), and Flexible Job-Shop Scheduling (FJSP) show POCO outperforms state-of-the-art neural methods, reducing optimality gaps impressively with efficient inference. POCO is architecture-agnostic, enabling seamless integration with existing NCO models, and establishes preference optimization as a principled framework for combinatorial optimization.
Hybrid intelligence for dynamic job-shop scheduling with deep reinforcement learning and attention mechanism
Jan 03, 2022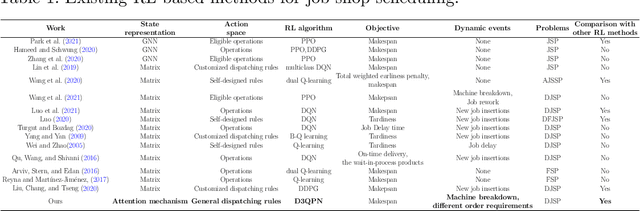
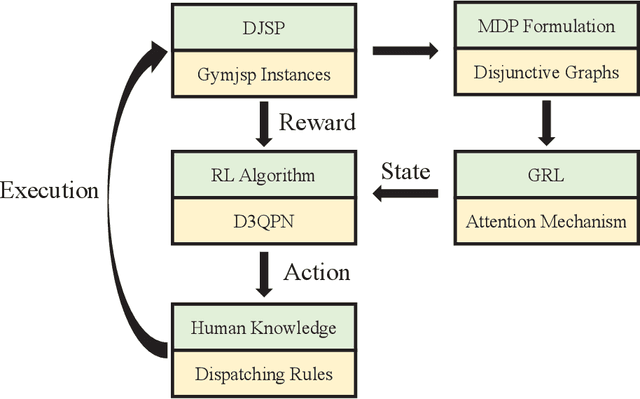
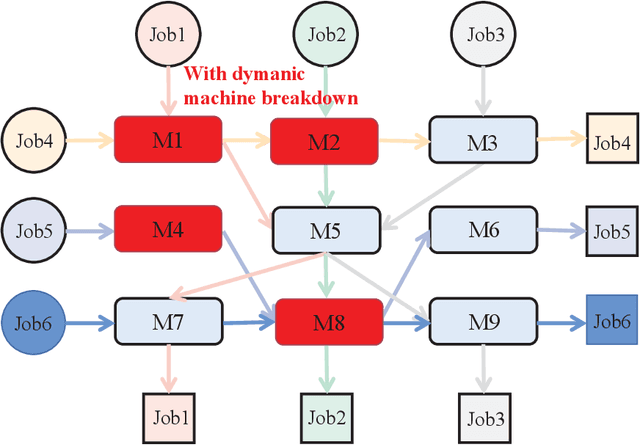

The dynamic job-shop scheduling problem (DJSP) is a class of scheduling tasks that specifically consider the inherent uncertainties such as changing order requirements and possible machine breakdown in realistic smart manufacturing settings. Since traditional methods cannot dynamically generate effective scheduling strategies in face of the disturbance of environments, we formulate the DJSP as a Markov decision process (MDP) to be tackled by reinforcement learning (RL). For this purpose, we propose a flexible hybrid framework that takes disjunctive graphs as states and a set of general dispatching rules as the action space with minimum prior domain knowledge. The attention mechanism is used as the graph representation learning (GRL) module for the feature extraction of states, and the double dueling deep Q-network with prioritized replay and noisy networks (D3QPN) is employed to map each state to the most appropriate dispatching rule. Furthermore, we present Gymjsp, a public benchmark based on the well-known OR-Library, to provide a standardized off-the-shelf facility for RL and DJSP research communities. Comprehensive experiments on various DJSP instances confirm that our proposed framework is superior to baseline algorithms with smaller makespan across all instances and provide empirical justification for the validity of the various components in the hybrid framework.