 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUGG: Unified Generative Grasping
Nov 28, 2023Dexterous grasping aims to produce diverse grasping postures with a high grasping success rate. Regression-based methods that directly predict grasping parameters given the object may achieve a high success rate but often lack diversity. Generation-based methods that generate grasping postures conditioned on the object can often produce diverse grasping, but they are insufficient for high grasping success due to lack of discriminative information. To mitigate, we introduce a unified diffusion-based dexterous grasp generation model, dubbed the name UGG, which operates within the object point cloud and hand parameter spaces. Our all-transformer architecture unifies the information from the object, the hand, and the contacts, introducing a novel representation of contact points for improved contact modeling. The flexibility and quality of our model enable the integration of a lightweight discriminator, benefiting from simulated discriminative data, which pushes for a high success rate while preserving high diversity. Beyond grasp generation, our model can also generate objects based on hand information, offering valuable insights into object design and studying how the generative model perceives objects. Our model achieves state-of-the-art dexterous grasping on the large-scale DexGraspNet dataset while facilitating human-centric object design, marking a significant advancement in dexterous grasping research. Our project page is https://jiaxin-lu.github.io/ugg/ .
HiH: A Multi-modal Hierarchy in Hierarchy Network for Unconstrained Gait Recognition
Nov 19, 2023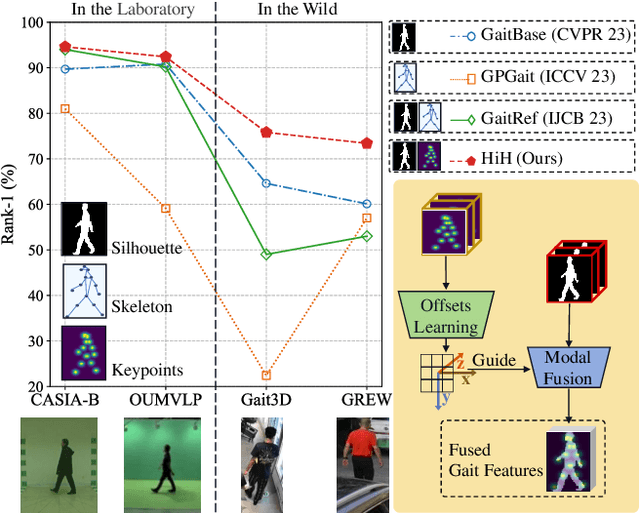
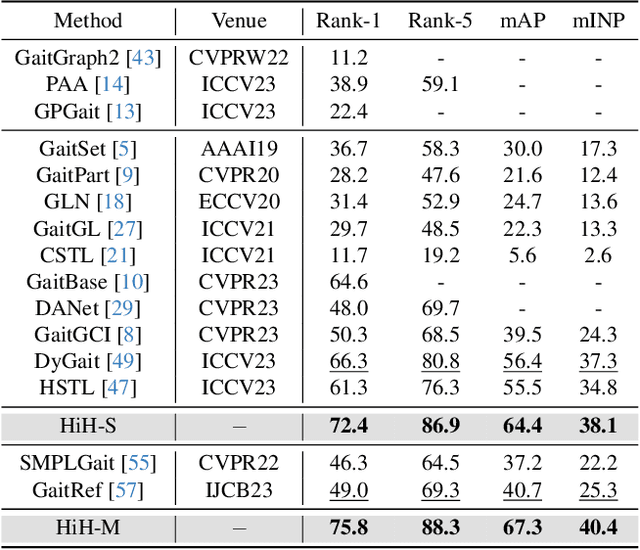
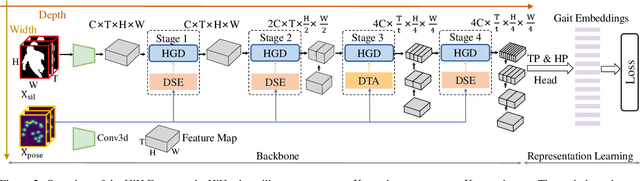
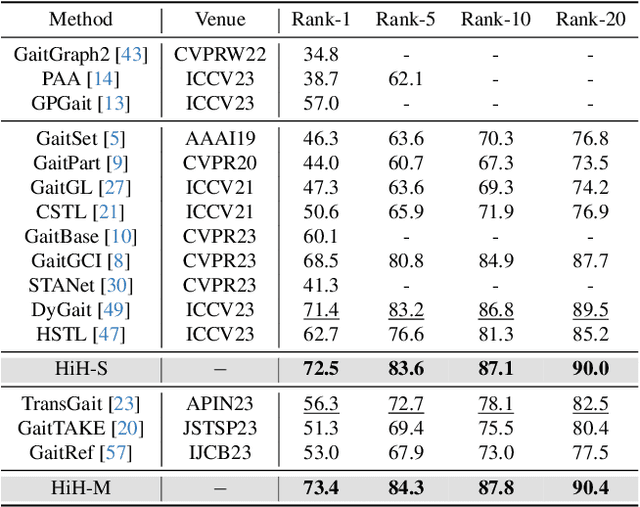
Gait recognition has achieved promising advances in controlled settings, yet it significantly struggles in unconstrained environments due to challenges such as view changes, occlusions, and varying walking speeds. Additionally, efforts to fuse multiple modalities often face limited improvements because of cross-modality incompatibility, particularly in outdoor scenarios. To address these issues, we present a multi-modal Hierarchy in Hierarchy network (HiH) that integrates silhouette and pose sequences for robust gait recognition. HiH features a main branch that utilizes Hierarchical Gait Decomposer (HGD) modules for depth-wise and intra-module hierarchical examination of general gait patterns from silhouette data. This approach captures motion hierarchies from overall body dynamics to detailed limb movements, facilitating the representation of gait attributes across multiple spatial resolutions. Complementing this, an auxiliary branch, based on 2D joint sequences, enriches the spatial and temporal aspects of gait analysis. It employs a Deformable Spatial Enhancement (DSE) module for pose-guided spatial attention and a Deformable Temporal Alignment (DTA) module for aligning motion dynamics through learned temporal offsets. Extensive evaluations across diverse indoor and outdoor datasets demonstrate HiH's state-of-the-art performance, affirming a well-balanced trade-off between accuracy and efficiency.
FD-MIA: Efficient Attacks on Fairness-enhanced Models
Nov 07, 2023



Previous studies have developed fairness methods for biased models that exhibit discriminatory behaviors towards specific subgroups. While these models have shown promise in achieving fair predictions, recent research has identified their potential vulnerability to score-based membership inference attacks (MIAs). In these attacks, adversaries can infer whether a particular data sample was used during training by analyzing the model's prediction scores. However, our investigations reveal that these score-based MIAs are ineffective when targeting fairness-enhanced models in binary classifications. The attack models trained to launch the MIAs degrade into simplistic threshold models, resulting in lower attack performance. Meanwhile, we observe that fairness methods often lead to prediction performance degradation for the majority subgroups of the training data. This raises the barrier to successful attacks and widens the prediction gaps between member and non-member data. Building upon these insights, we propose an efficient MIA method against fairness-enhanced models based on fairness discrepancy results (FD-MIA). It leverages the difference in the predictions from both the original and fairness-enhanced models and exploits the observed prediction gaps as attack clues. We also explore potential strategies for mitigating privacy leakages. Extensive experiments validate our findings and demonstrate the efficacy of the proposed method.
Detecting Generated Images by Real Images Only
Nov 02, 2023



As deep learning technology continues to evolve, the images yielded by generative models are becoming more and more realistic, triggering people to question the authenticity of images. Existing generated image detection methods detect visual artifacts in generated images or learn discriminative features from both real and generated images by massive training. This learning paradigm will result in efficiency and generalization issues, making detection methods always lag behind generation methods. This paper approaches the generated image detection problem from a new perspective: Start from real images. By finding the commonality of real images and mapping them to a dense subspace in feature space, the goal is that generated images, regardless of their generative model, are then projected outside the subspace. As a result, images from different generative models can be detected, solving some long-existing problems in the field. Experimental results show that although our method was trained only by real images and uses 99.9\% less training data than other deep learning-based methods, it can compete with state-of-the-art methods and shows excellent performance in detecting emerging generative models with high inference efficiency. Moreover, the proposed method shows robustness against various post-processing. These advantages allow the method to be used in real-world scenarios.
Grasp Multiple Objects with One Hand
Oct 24, 2023



The human hand's complex kinematics allow for simultaneous grasping and manipulation of multiple objects, essential for tasks like object transfer and in-hand manipulation. Despite its importance, robotic multi-object grasping remains underexplored and presents challenges in kinematics, dynamics, and object configurations. This paper introduces MultiGrasp, a two-stage method for multi-object grasping on a tabletop with a multi-finger dexterous hand. It involves (i) generating pre-grasp proposals and (ii) executing the grasp and lifting the objects. Experimental results primarily focus on dual-object grasping and report a 44.13% success rate, showcasing adaptability to unseen object configurations and imprecise grasps. The framework also demonstrates the capability to grasp more than two objects, albeit at a reduced inference speed.
Leveraging Large Language Models for Enhanced Product Descriptions in eCommerce
Oct 24, 2023In the dynamic field of eCommerce, the quality and comprehensiveness of product descriptions are pivotal for enhancing search visibility and customer engagement. Effective product descriptions can address the 'cold start' problem, align with market trends, and ultimately lead to increased click-through rates. Traditional methods for crafting these descriptions often involve significant human effort and may lack both consistency and scalability. This paper introduces a novel methodology for automating product description generation using the LLAMA 2.0 7B language model. We train the model on a dataset of authentic product descriptions from Walmart, one of the largest eCommerce platforms. The model is then fine-tuned for domain-specific language features and eCommerce nuances to enhance its utility in sales and user engagement. We employ multiple evaluation metrics, including NDCG, customer click-through rates, and human assessments, to validate the effectiveness of our approach. Our findings reveal that the system is not only scalable but also significantly reduces the human workload involved in creating product descriptions. This study underscores the considerable potential of large language models like LLAMA 2.0 7B in automating and optimizing various facets of eCommerce platforms, offering significant business impact, including improved search functionality and increased sales.
Towards LLM-driven Dialogue State Tracking
Oct 23, 2023



Dialogue State Tracking (DST) is of paramount importance in ensuring accurate tracking of user goals and system actions within task-oriented dialogue systems. The emergence of large language models (LLMs) such as GPT3 and ChatGPT has sparked considerable interest in assessing their efficacy across diverse applications. In this study, we conduct an initial examination of ChatGPT's capabilities in DST. Our evaluation uncovers the exceptional performance of ChatGPT in this task, offering valuable insights to researchers regarding its capabilities and providing useful directions for designing and enhancing dialogue systems. Despite its impressive performance, ChatGPT has significant limitations including its closed-source nature, request restrictions, raising data privacy concerns, and lacking local deployment capabilities. To address these concerns, we present LDST, an LLM-driven DST framework based on smaller, open-source foundation models. By utilizing a novel domain-slot instruction tuning method, LDST achieves performance on par with ChatGPT. Comprehensive evaluations across three distinct experimental settings, we find that LDST exhibits remarkable performance improvements in both zero-shot and few-shot setting compared to previous SOTA methods. The source code is provided for reproducibility.
Towards Open-World Co-Salient Object Detection with Generative Uncertainty-aware Group Selective Exchange-Masking
Oct 16, 2023The traditional definition of co-salient object detection (CoSOD) task is to segment the common salient objects in a group of relevant images. This definition is based on an assumption of group consensus consistency that is not always reasonable in the open-world setting, which results in robustness issue in the model when dealing with irrelevant images in the inputting image group under the open-word scenarios. To tackle this problem, we introduce a group selective exchange-masking (GSEM) approach for enhancing the robustness of the CoSOD model. GSEM takes two groups of images as input, each containing different types of salient objects. Based on the mixed metric we designed, GSEM selects a subset of images from each group using a novel learning-based strategy, then the selected images are exchanged. To simultaneously consider the uncertainty introduced by irrelevant images and the consensus features of the remaining relevant images in the group, we designed a latent variable generator branch and CoSOD transformer branch. The former is composed of a vector quantised-variational autoencoder to generate stochastic global variables that model uncertainty. The latter is designed to capture correlation-based local features that include group consensus. Finally, the outputs of the two branches are merged and passed to a transformer-based decoder to generate robust predictions. Taking into account that there are currently no benchmark datasets specifically designed for open-world scenarios, we constructed three open-world benchmark datasets, namely OWCoSal, OWCoSOD, and OWCoCA, based on existing datasets. By breaking the group-consistency assumption, these datasets provide effective simulations of real-world scenarios and can better evaluate the robustness and practicality of models.
Making Multimodal Generation Easier: When Diffusion Models Meet LLMs
Oct 13, 2023We present EasyGen, an efficient model designed to enhance multimodal understanding and generation by harnessing the capabilities of diffusion models and large language models (LLMs). Unlike existing multimodal models that predominately depend on encoders like CLIP or ImageBind and need ample amounts of training data to bridge the gap between modalities, EasyGen is built upon a bidirectional conditional diffusion model named BiDiffuser, which promotes more efficient interactions between modalities. EasyGen handles image-to-text generation by integrating BiDiffuser and an LLM via a simple projection layer. Unlike most existing multimodal models that are limited to generating text responses, EasyGen can also facilitate text-to-image generation by leveraging the LLM to create textual descriptions, which can be interpreted by BiDiffuser to generate appropriate visual responses. Extensive quantitative and qualitative experiments demonstrate the effectiveness of EasyGen, whose training can be easily achieved in a lab setting. The source code is available at https://github.com/zxy556677/EasyGen.
RT-SRTS: Angle-Agnostic Real-Time Simultaneous 3D Reconstruction and Tumor Segmentation from Single X-Ray Projection
Oct 12, 2023Radiotherapy is one of the primary treatment methods for tumors, but the organ movement caused by respiratory motion limits its accuracy. Recently, 3D imaging from single X-ray projection receives extensive attentions as a promising way to address this issue. However, current methods can only reconstruct 3D image without direct location of the tumor and are only validated for fixed-angle imaging, which fails to fully meet the requirement of motion control in radiotherapy. In this study, we propose a novel imaging method RT-SRTS which integrates 3D imaging and tumor segmentation into one network based on the multi-task learning (MTL) and achieves real-time simultaneous 3D reconstruction and tumor segmentation from single X-ray projection at any angle. Futhermore, we propose the attention enhanced calibrator (AEC) and uncertain-region elaboration (URE) modules to aid feature extraction and improve segmentation accuracy. We evaluated the proposed method on ten patient cases and compared it with two state-of-the-art methods. Our approach not only delivered superior 3D reconstruction but also demonstrated commendable tumor segmentation results. The simultaneous reconstruction and segmentation could be completed in approximately 70 ms, significantly faster than the required time threshold for real-time tumor tracking. The efficacy of both AEC and URE was also validated through ablation studies.