 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DPX: Single Panoramic X-ray Analysis Guided by 3D Oral Structure Reconstruction
Sep 27, 2024



Panoramic X-ray (PX) is a prevalent modality in dentistry practice owing to its wide availability and low cost. However, as a 2D projection of a 3D structure, PX suffers from anatomical information loss and PX diagnosis is limited compared to that with 3D imaging modalities. 2D-to-3D reconstruction methods have been explored for the ability to synthesize the absent 3D anatomical information from 2D PX for use in PX image analysis. However, there are challenges in leveraging such 3D synthesized reconstructions. First, inferring 3D depth from 2D images remains a challenging task with limited accuracy. The second challenge is the joint analysis of 2D PX with its 3D synthesized counterpart, with the aim to maximize the 2D-3D synergy while minimizing the errors arising from the synthesized image. In this study, we propose a new method termed 3DPX - PX image analysis guided by 2D-to-3D reconstruction, to overcome these challenges. 3DPX consists of (i) a novel progressive reconstruction network to improve 2D-to-3D reconstruction and, (ii) a contrastive-guided bidirectional multimodality alignment module for 3D-guided 2D PX classification and segmentation tasks. The reconstruction network progressively reconstructs 3D images with knowledge imposed on the intermediate reconstructions at multiple pyramid levels and incorporates Multilayer Perceptrons to improve semantic understanding. The downstream networks leverage the reconstructed images as 3D anatomical guidance to the PX analysis through feature alignment, which increases the 2D-3D synergy with bidirectional feature projection and decease the impact of potential errors with contrastive guidance. Extensive experiments on two oral datasets involving 464 studies demonstrate that 3DPX outperforms the state-of-the-art methods in various tasks including 2D-to-3D reconstruction, PX classification and lesion segmentation.
DSDFormer: An Innovative Transformer-Mamba Framework for Robust High-Precision Driver Distraction Identification
Sep 09, 2024



Driver distraction remains a leading cause of traffic accidents, posing a critical threat to road safety globally. As intelligent transportation systems evolve, accurate and real-time identification of driver distraction has become essential. However, existing methods struggle to capture both global contextual and fine-grained local features while contending with noisy labels in training datasets. To address these challenges, we propose DSDFormer, a novel framework that integrates the strengths of Transformer and Mamba architectures through a Dual State Domain Attention (DSDA) mechanism, enabling a balance between long-range dependencies and detailed feature extraction for robust driver behavior recognition. Additionally, we introduce Temporal Reasoning Confident Learning (TRCL), an unsupervised approach that refines noisy labels by leveraging spatiotemporal correlations in video sequences. Our model achieves state-of-the-art performance on the AUC-V1, AUC-V2, and 100-Driver datasets and demonstrates real-time processing efficiency on the NVIDIA Jetson AGX Orin platform. Extensive experimental results confirm that DSDFormer and TRCL significantly improve both the accuracy and robustness of driver distraction detection, offering a scalable solution to enhance road safety.
Serp-Mamba: Advancing High-Resolution Retinal Vessel Segmentation with Selective State-Space Model
Sep 06, 2024



Ultra-Wide-Field Scanning Laser Ophthalmoscopy (UWF-SLO) images capture high-resolution views of the retina with typically 200 spanning degrees. Accurate segmentation of vessels in UWF-SLO images is essential for detecting and diagnosing fundus disease. Recent studies have revealed that the selective State Space Model (SSM) in Mamba performs well in modeling long-range dependencies, which is crucial for capturing the continuity of elongated vessel structures. Inspired by this, we propose the first Serpentine Mamba (Serp-Mamba) network to address this challenging task. Specifically, we recognize the intricate, varied, and delicate nature of the tubular structure of vessels. Furthermore, the high-resolution of UWF-SLO images exacerbates the imbalance between the vessel and background categories. Based on the above observations, we first devise a Serpentine Interwoven Adaptive (SIA) scan mechanism, which scans UWF-SLO images along curved vessel structures in a snake-like crawling manner. This approach, consistent with vascular texture transformations, ensures the effective and continuous capture of curved vascular structure features. Second, we propose an Ambiguity-Driven Dual Recalibration (ADDR) module to address the category imbalance problem intensified by high-resolution images. Our ADDR module delineates pixels by two learnable thresholds and refines ambiguous pixels through a dual-driven strategy, thereby accurately distinguishing vessels and background regions. Experiment results on three datasets demonstrate the superior performance of our Serp-Mamba on high-resolution vessel segmentation. We also conduct a series of ablation studies to verify the impact of our designs. Our code shall be released upon publication of this work.
3DPX: Progressive 2D-to-3D Oral Image Reconstruction with Hybrid MLP-CNN Networks
Aug 02, 2024



Panoramic X-ray (PX) is a prevalent modality in dental practice for its wide availability and low cost. However, as a 2D projection image, PX does not contain 3D anatomical information, and therefore has limited use in dental applications that can benefit from 3D information, e.g., tooth angular misa-lignment detection and classification. Reconstructing 3D structures directly from 2D PX has recently been explored to address limitations with existing methods primarily reliant on Convolutional Neural Networks (CNNs) for direct 2D-to-3D mapping. These methods, however, are unable to correctly infer depth-axis spatial information. In addition, they are limited by the in-trinsic locality of convolution operations, as the convolution kernels only capture the information of immediate neighborhood pixels. In this study, we propose a progressive hybrid Multilayer Perceptron (MLP)-CNN pyra-mid network (3DPX) for 2D-to-3D oral PX reconstruction. We introduce a progressive reconstruction strategy, where 3D images are progressively re-constructed in the 3DPX with guidance imposed on the intermediate recon-struction result at each pyramid level. Further, motivated by the recent ad-vancement of MLPs that show promise in capturing fine-grained long-range dependency, our 3DPX integrates MLPs and CNNs to improve the semantic understanding during reconstruction. Extensive experiments on two large datasets involving 464 studies demonstrate that our 3DPX outperforms state-of-the-art 2D-to-3D oral reconstruction methods, including standalone MLP and transformers, in reconstruction quality, and also im-proves the performance of downstream angular misalignment classification tasks.
Scene-aware Human Pose Generation using Transformer
Aug 04, 2023Affordance learning considers the interaction opportunities for an actor in the scene and thus has wide application in scene understanding and intelligent robotics. In this paper, we focus on contextual affordance learning, i.e., using affordance as context to generate a reasonable human pose in a scene. Existing scene-aware human pose generation methods could be divided into two categories depending on whether using pose templates. Our proposed method belongs to the template-based category, which benefits from the representative pose templates. Moreover, inspired by recent transformer-based methods, we associate each query embedding with a pose template, and use the interaction between query embeddings and scene feature map to effectively predict the scale and offsets for each pose template. In addition, we employ knowledge distillation to facilitate the offset learning given the predicted scale. Comprehensive experiments on Sitcom dataset demonstrate the effectiveness of our method.
Deep Dynamic Epidemiological Modelling for COVID-19 Forecasting in Multi-level Districts
Jun 21, 2023



Objective: COVID-19 has spread worldwide and made a huge influence across the world. Modeling the infectious spread situation of COVID-19 is essential to understand the current condition and to formulate intervention measurements. Epidemiological equations based on the SEIR model simulate disease development. The traditional parameter estimation method to solve SEIR equations could not precisely fit real-world data due to different situations, such as social distancing policies and intervention strategies. Additionally, learning-based models achieve outstanding fitting performance, but cannot visualize mechanisms. Methods: Thus, we propose a deep dynamic epidemiological (DDE) method that combines epidemiological equations and deep-learning advantages to obtain high accuracy and visualization. The DDE contains deep networks to fit the effect function to simulate the ever-changing situations based on the neural ODE method in solving variants' equations, ensuring the fitting performance of multi-level areas. Results: We introduce four SEIR variants to fit different situations in different countries and regions. We compare our DDE method with traditional parameter estimation methods (Nelder-Mead, BFGS, Powell, Truncated Newton Conjugate-Gradient, Neural ODE) in fitting the real-world data in the cases of countries (the USA, Columbia, South Africa) and regions (Wuhan in China, Piedmont in Italy). Our DDE method achieves the best Mean Square Error and Pearson coefficient in all five areas. Further, compared with the state-of-art learning-based approaches, the DDE outperforms all techniques, including LSTM, RNN, GRU, Random Forest, Extremely Random Trees, and Decision Tree. Conclusion: DDE presents outstanding predictive ability and visualized display of the changes in infection rates in different regions and countries.
TransMRSR: Transformer-based Self-Distilled Generative Prior for Brain MRI Super-Resolution
Jun 11, 2023Magnetic resonance images (MRI) acquired with low through-plane resolution compromise time and cost. The poor resolution in one orientation is insufficient to meet the requirement of high resolution for early diagnosis of brain disease and morphometric study. The common Single image super-resolution (SISR) solutions face two main challenges: (1) local detailed and global anatomical structural information combination; and (2) large-scale restoration when applied for reconstructing thick-slice MRI into high-resolution (HR) iso-tropic data. To address these problems, we propose a novel two-stage network for brain MRI SR named TransMRSR based on the convolutional blocks to extract local information and transformer blocks to capture long-range dependencies. TransMRSR consists of three modules: the shallow local feature extraction, the deep non-local feature capture, and the HR image reconstruction. We perform a generative task to encapsulate diverse priors into a generative network (GAN), which is the decoder sub-module of the deep non-local feature capture part, in the first stage. The pre-trained GAN is used for the second stage of SR task. We further eliminate the potential latent space shift caused by the two-stage training strategy through the self-distilled truncation trick. The extensive experiments show that our method achieves superior performance to other SSIR methods on both public and private datasets. Code is released at https://github.com/goddesshs/TransMRSR.git .
DRAC: Diabetic Retinopathy Analysis Challenge with Ultra-Wide Optical Coherence Tomography Angiography Images
Apr 05, 2023



Computer-assisted automatic analysis of diabetic retinopathy (DR) is of great importance in reducing the risks of vision loss and even blindness. Ultra-wide optical coherence tomography angiography (UW-OCTA) is a non-invasive and safe imaging modality in DR diagnosis system, but there is a lack of publicly available benchmarks for model development and evaluation. To promote further research and scientific benchmarking for diabetic retinopathy analysis using UW-OCTA images, we organized a challenge named "DRAC - Diabetic Retinopathy Analysis Challenge" in conjunction with the 25th International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI 2022). The challenge consists of three tasks: segmentation of DR lesions, image quality assessment and DR grading. The scientific community responded positively to the challenge, with 11, 12, and 13 teams from geographically diverse institutes submitting different solutions in these three tasks, respectively. This paper presents a summary and analysis of the top-performing solutions and results for each task of the challenge. The obtained results from top algorithms indicate the importance of data augmentation, model architecture and ensemble of networks in improving the performance of deep learning models. These findings have the potential to enable new developments in diabetic retinopathy analysis. The challenge remains open for post-challenge registrations and submissions for benchmarking future methodology developments.
Input-Specific Robustness Certification for Randomized Smoothing
Dec 21, 2021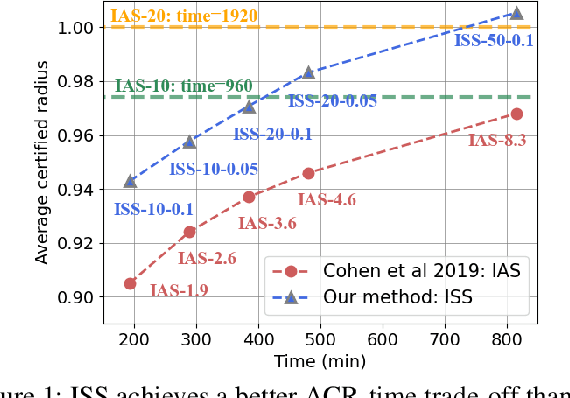
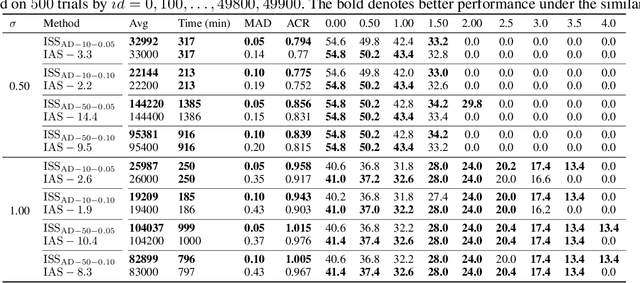
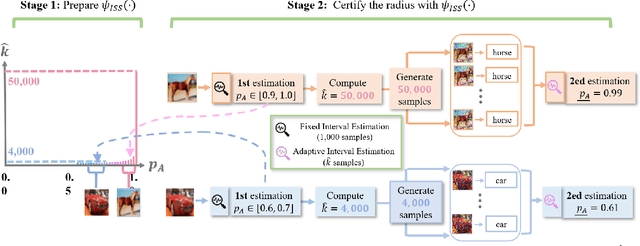
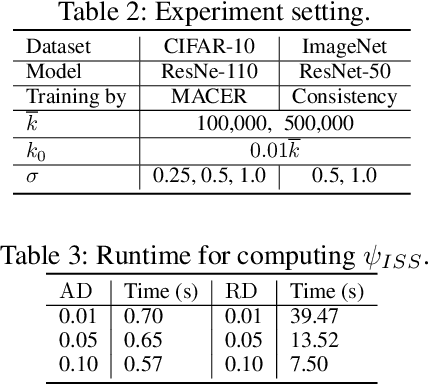
Although randomized smoothing has demonstrated high certified robustness and superior scalability to other certified defenses, the high computational overhead of the robustness certification bottlenecks the practical applicability, as it depends heavily on the large sample approximation for estimating the confidence interval. In existing works, the sample size for the confidence interval is universally set and agnostic to the input for prediction. This Input-Agnostic Sampling (IAS) scheme may yield a poor Average Certified Radius (ACR)-runtime trade-off which calls for improvement. In this paper, we propose Input-Specific Sampling (ISS) acceleration to achieve the cost-effectiveness for robustness certification, in an adaptive way of reducing the sampling size based on the input characteristic. Furthermore, our method universally controls the certified radius decline from the ISS sample size reduction. The empirical results on CIFAR-10 and ImageNet show that ISS can speed up the certification by more than three times at a limited cost of 0.05 certified radius. Meanwhile, ISS surpasses IAS on the average certified radius across the extensive hyperparameter settings. Specifically, ISS achieves ACR=0.958 on ImageNet ($\sigma=1.0$) in 250 minutes, compared to ACR=0.917 by IAS under the same condition. We release our code in \url{https://github.com/roy-ch/Input-Specific-Certification}.
A Framework of Randomized Selection Based Certified Defenses Against Data Poisoning Attacks
Oct 13, 2020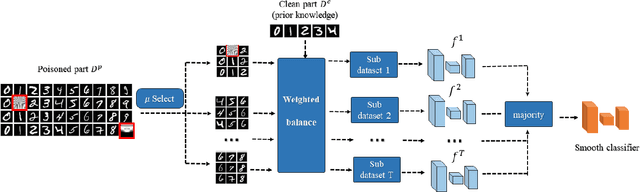
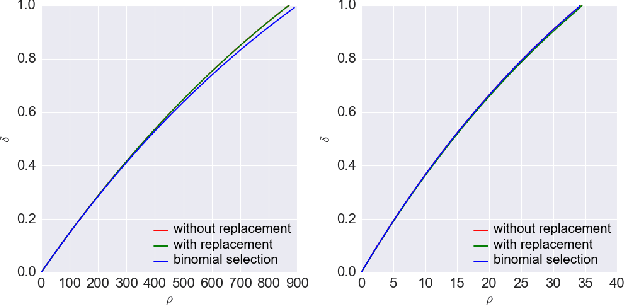
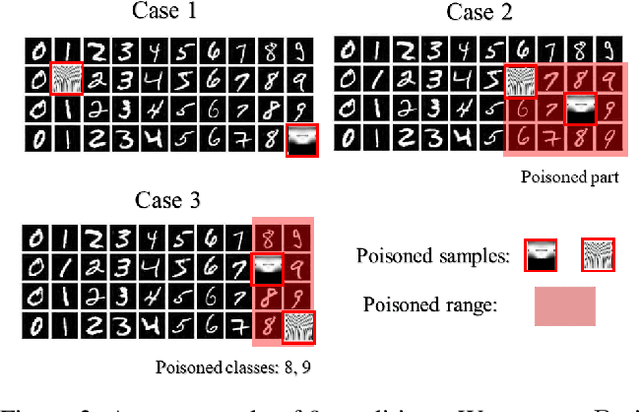
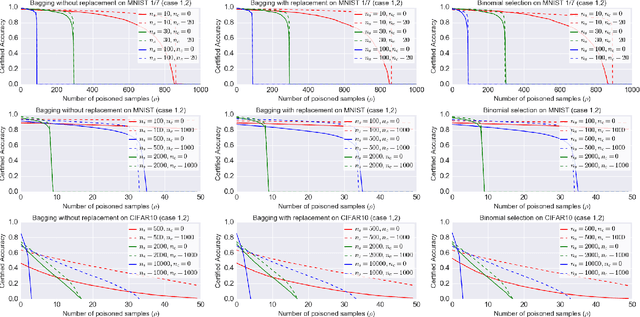
Neural network classifiers are vulnerable to data poisoning attacks, as attackers can degrade or even manipulate their predictions thorough poisoning only a few training samples. However, the robustness of heuristic defenses is hard to measure. Random selection based defenses can achieve certified robustness by averaging the classifiers' predictions on the sub-datasets sampled from the training set. This paper proposes a framework of random selection based certified defenses against data poisoning attacks. Specifically, we prove that the random selection schemes that satisfy certain conditions are robust against data poisoning attacks. We also derive the analytical form of the certified radius for the qualified random selection schemes. The certified radius of bagging derived by our framework is tighter than the previous work. Our framework allows users to improve robustness by leveraging prior knowledge about the training set and the poisoning model. Given higher level of prior knowledge, we can achieve higher certified accuracy both theoretically and practically. According to the experiments on three benchmark datasets: MNIST 1/7, MNIST, and CIFAR-10, our method outperforms the state-of-the-art.