 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyDAR-Pano3D: A Hybrid Disentangled Anatomical Recovery Framework for Panoramic-to-3D Reconstruction
May 20, 2026Panoramic radiograph (PR) is fundamentally used in routine dental care, but it inherently provides only a two-dimensional (2D) projection of complex three-dimensional (3D) craniofacial anatomy. Most existing learning-based methods attempt to computationally recover this 3D information by directly regressing native cone-beam computed tomography (CBCT) volumes from PR. However, this direct mapping requires the model to simultaneously learn common anatomical structures and patient-specific morphological variations. This entangled formulation makes the ill-posed 2D-to-3D inverse problem highly ambiguous, often producing over-smoothed reconstructions with blurred anatomical boundaries. To address this, we propose HyDAR-Pano3D, a two-stage framework that reformulates PR-to-CBCT reconstruction as a disentangled anatomical recovery problem. In Stage 1, a dual-encoder network integrates radiographic features with SAM-derived semantic priors to reconstruct an arch-normalized canonical volume. In Stage 2, an Anatomical Restoration Network predicts a prior-constrained structured deformation field to map this canonical volume back to the native space, restoring individual morphological variations. Experiments on three large-scale datasets show that HyDAR-Pano3D significantly outperforms baseline methods ($p < 0.05$), achieving a 25.76 dB PSNR, 85.70\% SSIM, and an 83.83\% overall anatomical Dice score. The synthesized volumes successfully support downstream segmentation of whole teeth (82.4\% Dice) and the inferior alveolar canal (72.2\% Dice), demonstrating that our disentangled approach preserves clinically relevant structures to enable robust anatomy-aware assessment when CBCT data is unavailable.
3DPX: Single Panoramic X-ray Analysis Guided by 3D Oral Structure Reconstruction
Sep 27, 2024



Panoramic X-ray (PX) is a prevalent modality in dentistry practice owing to its wide availability and low cost. However, as a 2D projection of a 3D structure, PX suffers from anatomical information loss and PX diagnosis is limited compared to that with 3D imaging modalities. 2D-to-3D reconstruction methods have been explored for the ability to synthesize the absent 3D anatomical information from 2D PX for use in PX image analysis. However, there are challenges in leveraging such 3D synthesized reconstructions. First, inferring 3D depth from 2D images remains a challenging task with limited accuracy. The second challenge is the joint analysis of 2D PX with its 3D synthesized counterpart, with the aim to maximize the 2D-3D synergy while minimizing the errors arising from the synthesized image. In this study, we propose a new method termed 3DPX - PX image analysis guided by 2D-to-3D reconstruction, to overcome these challenges. 3DPX consists of (i) a novel progressive reconstruction network to improve 2D-to-3D reconstruction and, (ii) a contrastive-guided bidirectional multimodality alignment module for 3D-guided 2D PX classification and segmentation tasks. The reconstruction network progressively reconstructs 3D images with knowledge imposed on the intermediate reconstructions at multiple pyramid levels and incorporates Multilayer Perceptrons to improve semantic understanding. The downstream networks leverage the reconstructed images as 3D anatomical guidance to the PX analysis through feature alignment, which increases the 2D-3D synergy with bidirectional feature projection and decease the impact of potential errors with contrastive guidance. Extensive experiments on two oral datasets involving 464 studies demonstrate that 3DPX outperforms the state-of-the-art methods in various tasks including 2D-to-3D reconstruction, PX classification and lesion segmentation.
3DPX: Progressive 2D-to-3D Oral Image Reconstruction with Hybrid MLP-CNN Networks
Aug 02, 2024



Panoramic X-ray (PX) is a prevalent modality in dental practice for its wide availability and low cost. However, as a 2D projection image, PX does not contain 3D anatomical information, and therefore has limited use in dental applications that can benefit from 3D information, e.g., tooth angular misa-lignment detection and classification. Reconstructing 3D structures directly from 2D PX has recently been explored to address limitations with existing methods primarily reliant on Convolutional Neural Networks (CNNs) for direct 2D-to-3D mapping. These methods, however, are unable to correctly infer depth-axis spatial information. In addition, they are limited by the in-trinsic locality of convolution operations, as the convolution kernels only capture the information of immediate neighborhood pixels. In this study, we propose a progressive hybrid Multilayer Perceptron (MLP)-CNN pyra-mid network (3DPX) for 2D-to-3D oral PX reconstruction. We introduce a progressive reconstruction strategy, where 3D images are progressively re-constructed in the 3DPX with guidance imposed on the intermediate recon-struction result at each pyramid level. Further, motivated by the recent ad-vancement of MLPs that show promise in capturing fine-grained long-range dependency, our 3DPX integrates MLPs and CNNs to improve the semantic understanding during reconstruction. Extensive experiments on two large datasets involving 464 studies demonstrate that our 3DPX outperforms state-of-the-art 2D-to-3D oral reconstruction methods, including standalone MLP and transformers, in reconstruction quality, and also im-proves the performance of downstream angular misalignment classification tasks.
Layer-adaptive Structured Pruning Guided by Latency
May 23, 2023



Structured pruning can simplify network architecture and improve inference speed. Combined with the underlying hardware and inference engine in which the final model is deployed, better results can be obtained by using latency collaborative loss function to guide network pruning together. Existing pruning methods that optimize latency have demonstrated leading performance, however, they often overlook the hardware features and connection in the network. To address this problem, we propose a global importance score SP-LAMP(Structured Pruning Layer-Adaptive Magnitude-based Pruning) by deriving a global importance score LAMP from unstructured pruning to structured pruning. In SP-LAMP, each layer includes a filter with an SP-LAMP score of 1, and the remaining filters are grouped. We utilize a group knapsack solver to maximize the SP-LAMP score under latency constraints. In addition, we improve the strategy of collect the latency to make it more accurate. In particular, for ResNet50/ResNet18 on ImageNet and CIFAR10, SP-LAMP is 1.28x/8.45x faster with +1.7%/-1.57% top-1 accuracy changed, respectively. Experimental results in ResNet56 on CIFAR10 demonstrate that our algorithm achieves lower latency compared to alternative approaches while ensuring accuracy and FLOPs.
Augmentation-Aware Self-Supervision for Data-Efficient GAN Training
May 31, 2022
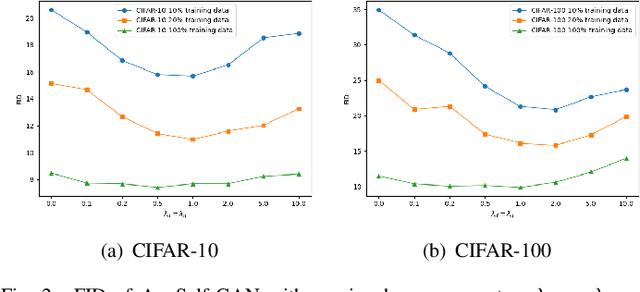
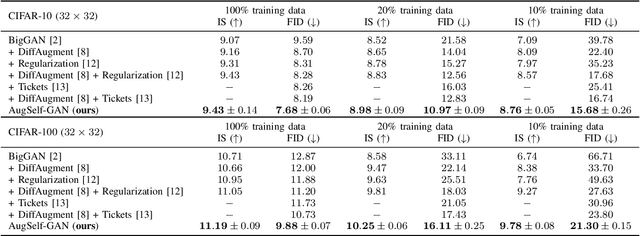
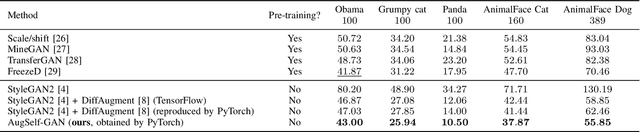
Training generative adversarial networks (GANs) with limited data is valuable but challenging because discriminators are prone to over-fitting in such situations. Recently proposed differentiable data augmentation techniques for discriminators demonstrate improved data efficiency of training GANs. However, the naive data augmentation introduces undesired invariance to augmentation into the discriminator. The invariance may degrade the representation learning ability of the discriminator, thereby affecting the generative modeling performance of the generator. To mitigate the invariance while inheriting the benefits of data augmentation, we propose a novel augmentation-aware self-supervised discriminator that predicts the parameter of augmentation given the augmented and original data. Moreover, the prediction task is required to distinguishable between real data and generated data since they are different during training. We further encourage the generator to learn from the proposed discriminator by generating augmentation-predictable real data. We compare the proposed method with state-of-the-arts across the class-conditional BigGAN and unconditional StyleGAN2 architectures on CIFAR-10/100 and several low-shot datasets, respectively. Experimental results show a significantly improved generation performance of our method over competing methods for training data-efficient GANs.
Fine-tuning Pruned Networks with Linear Over-parameterization
Apr 25, 2022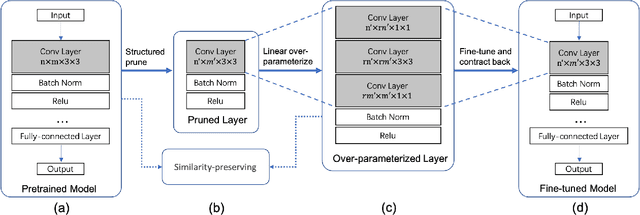
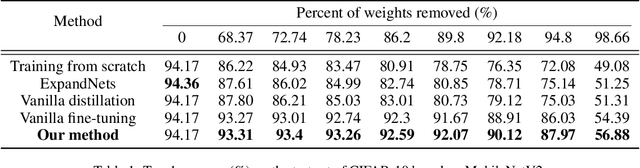
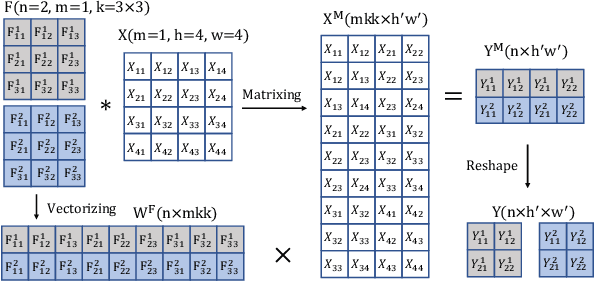
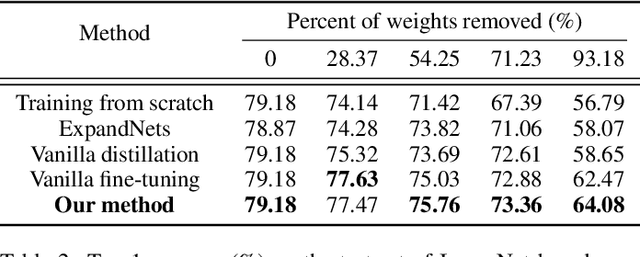
Structured pruning compresses neural networks by reducing channels (filters) for fast inference and low footprint at run-time. To restore accuracy after pruning, fine-tuning is usually applied to pruned networks. However, too few remaining parameters in pruned networks inevitably bring a great challenge to fine-tuning to restore accuracy. To address this challenge, we propose a novel method that first linearly over-parameterizes the compact layers in pruned networks to enlarge the number of fine-tuning parameters and then re-parameterizes them to the original layers after fine-tuning. Specifically, we equivalently expand the convolution/linear layer with several consecutive convolution/linear layers that do not alter the current output feature maps. Furthermore, we utilize similarity-preserving knowledge distillation that encourages the over-parameterized block to learn the immediate data-to-data similarities of the corresponding dense layer to maintain its feature learning ability. The proposed method is comprehensively evaluated on CIFAR-10 and ImageNet which significantly outperforms the vanilla fine-tuning strategy, especially for large pruning ratio.