 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWSLRec: Weakly Supervised Learning for Neural Sequential Recommendation Models
Feb 28, 2022
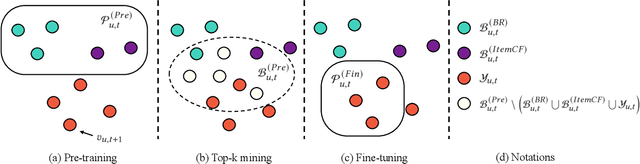
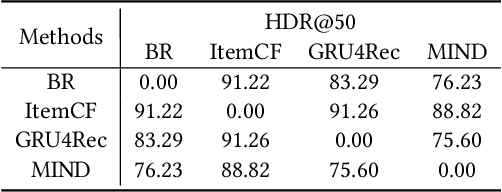
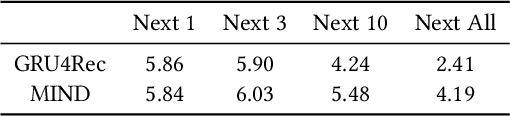
Learning the user-item relevance hidden in implicit feedback data plays an important role in modern recommender systems. Neural sequential recommendation models, which formulates learning the user-item relevance as a sequential classification problem to distinguish items in future behaviors from others based on the user's historical behaviors, have attracted a lot of interest in both industry and academic due to their substantial practical value. Though achieving many practical successes, we argue that the intrinsic {\bf incompleteness} and {\bf inaccuracy} of user behaviors in implicit feedback data is ignored and conduct preliminary experiments for supporting our claims. Motivated by the observation that model-free methods like behavioral retargeting (BR) and item-based collaborative filtering (ItemCF) hit different parts of the user-item relevance compared to neural sequential recommendation models, we propose a novel model-agnostic training approach called WSLRec, which adopts a three-stage framework: pre-training, top-$k$ mining, and fine-tuning. WSLRec resolves the incompleteness problem by pre-training models on extra weak supervisions from model-free methods like BR and ItemCF, while resolves the inaccuracy problem by leveraging the top-$k$ mining to screen out reliable user-item relevance from weak supervisions for fine-tuning. Experiments on two benchmark datasets and online A/B tests verify the rationality of our claims and demonstrate the effectiveness of WSLRec.
ADD 2022: the First Audio Deep Synthesis Detection Challenge
Feb 26, 2022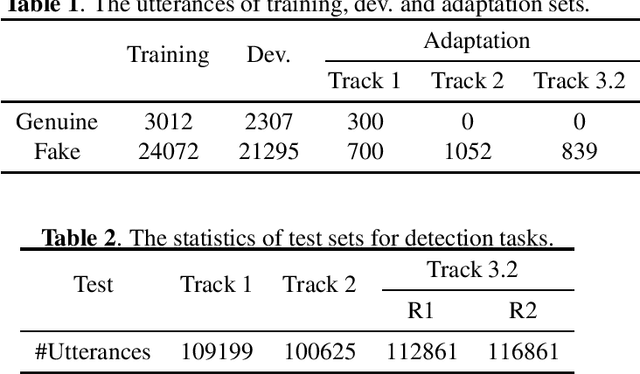
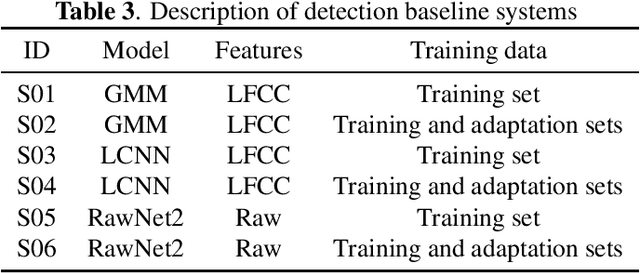
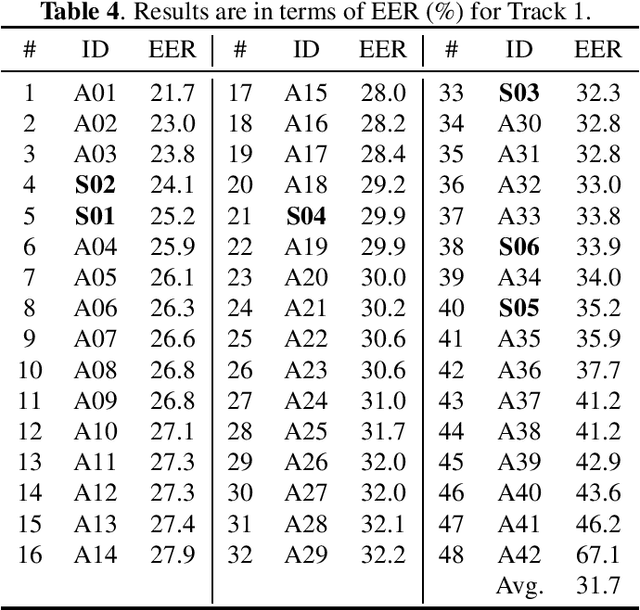
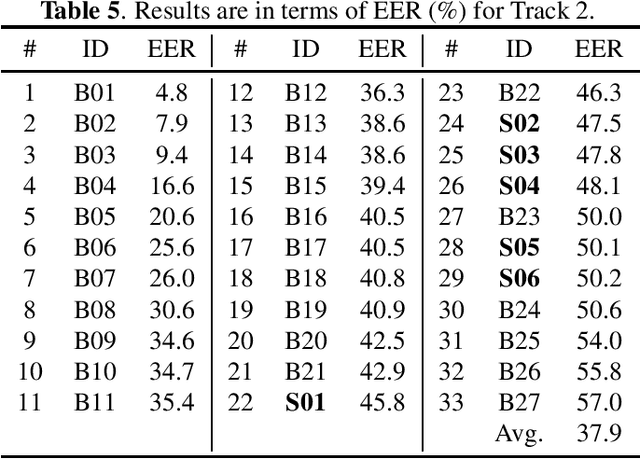
Audio deepfake detection is an emerging topic, which was included in the ASVspoof 2021. However, the recent shared tasks have not covered many real-life and challenging scenarios. The first Audio Deep synthesis Detection challenge (ADD) was motivated to fill in the gap. The ADD 2022 includes three tracks: low-quality fake audio detection (LF), partially fake audio detection (PF) and audio fake game (FG). The LF track focuses on dealing with bona fide and fully fake utterances with various real-world noises etc. The PF track aims to distinguish the partially fake audio from the real. The FG track is a rivalry game, which includes two tasks: an audio generation task and an audio fake detection task. In this paper, we describe the datasets, evaluation metrics, and protocols. We also report major findings that reflect the recent advances in audio deepfake detection tasks.
PFGE: Parsimonious Fast Geometric Ensembling of DNNs
Feb 23, 2022
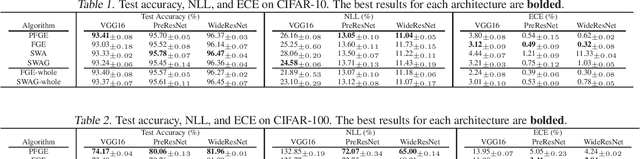
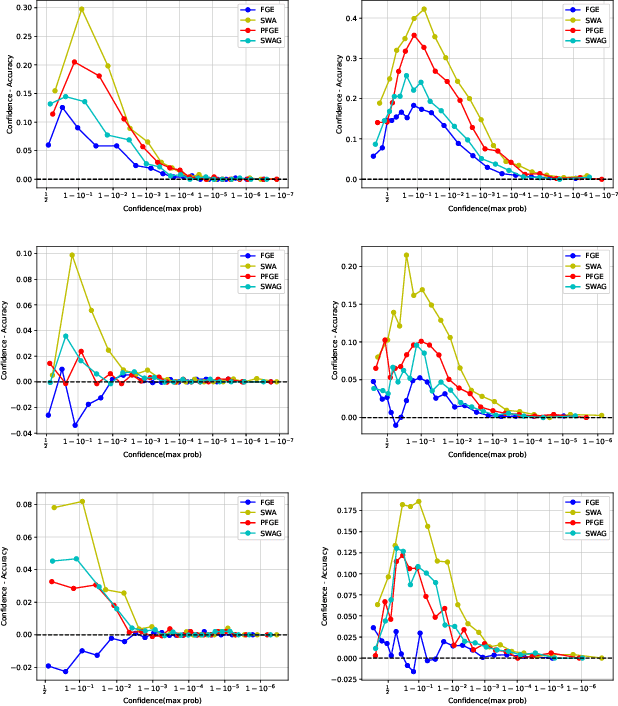

Ensemble methods have been widely used to improve the performance of machine learning methods in terms of generalization and uncertainty calibration, while they struggle to use in deep learning systems, as training an ensemble of deep neural networks (DNNs) and then deploying them for online prediction incur an extremely higher computational overhead of model training and test-time predictions. Recently, several advanced techniques, such as fast geometric ensembling (FGE) and snapshot ensemble, have been proposed. These methods can train the model ensembles in the same time as a single model, thus getting around the hurdle of training time. However, their overhead of model recording and test-time computations remains much higher than their single model based counterparts. Here we propose a parsimonious FGE (PFGE) that employs a lightweight ensemble of higher-performing DNNs generated by several successively-performed procedures of stochastic weight averaging. Experimental results across different advanced DNN architectures on different datasets, namely CIFAR-$\{$10,100$\}$ and Imagenet, demonstrate its performance. Results show that, compared with state-of-the-art methods, PFGE achieves better generalization performance and satisfactory calibration capability, while the overhead of model recording and test-time predictions is significantly reduced.
Multiple Similarity Drug-Target Interaction Prediction with Random Walks and Matrix Factorization
Jan 24, 2022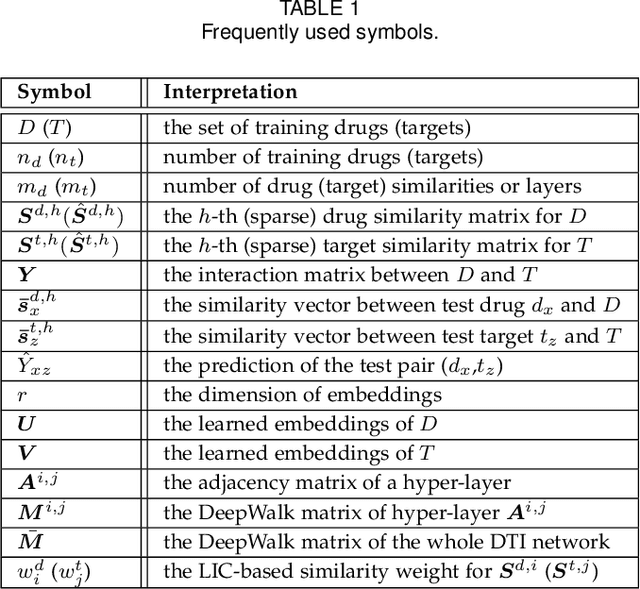
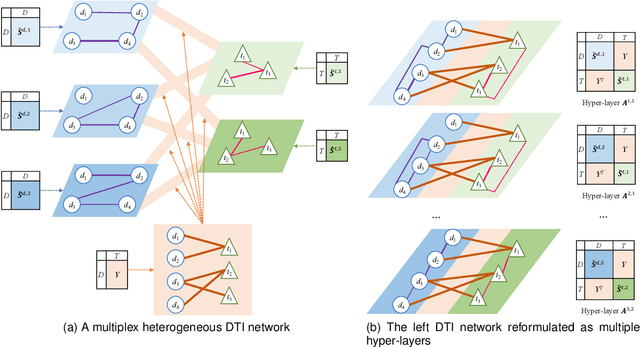
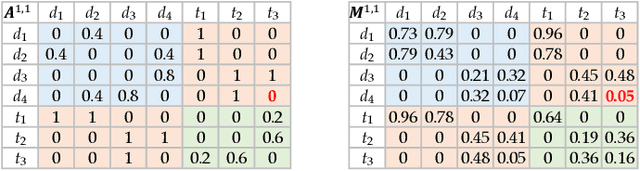
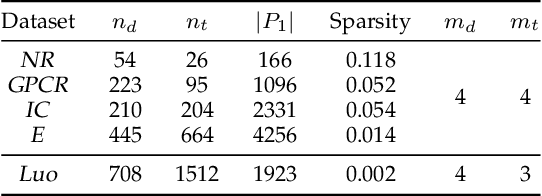
The discovery of drug-target interactions (DTIs) is a very promising area of research with great potential. In general, the identification of reliable interactions among drugs and proteins can boost the development of effective pharmaceuticals. In this work, we leverage random walks and matrix factorization techniques towards DTI prediction. In particular, we take a multi-layered network perspective, where different layers correspond to different similarity metrics between drugs and targets. To fully take advantage of topology information captured in multiple views, we develop an optimization framework, called MDMF, for DTI prediction. The framework learns vector representations of drugs and targets that not only retain higher-order proximity across all hyper-layers and layer-specific local invariance, but also approximates the interactions with their inner product. Furthermore, we propose an ensemble method, called MDMF2A, which integrates two instantiations of the MDMF model that optimize surrogate losses of the area under the precision-recall curve (AUPR) and the area under the receiver operating characteristic curve (AUC), respectively. The empirical study on real-world DTI datasets shows that our method achieves significant improvement over current state-of-the-art approaches in four different settings. Moreover, the validation of highly ranked non-interacting pairs also demonstrates the potential of MDMF2A to discover novel DTIs.
Online Multi-Object Tracking with Unsupervised Re-Identification Learning and Occlusion Estimation
Jan 04, 2022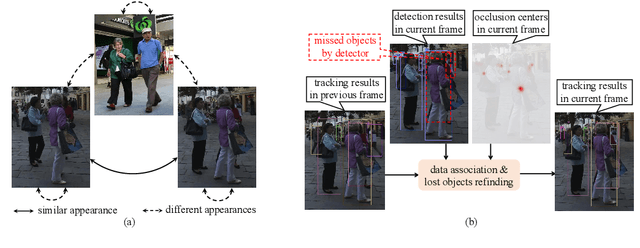

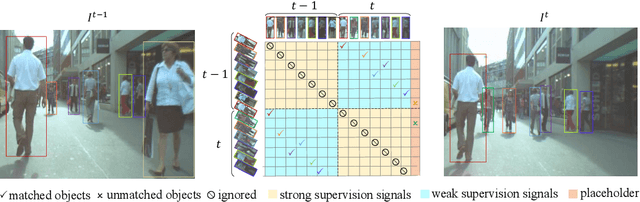

Occlusion between different objects is a typical challenge in Multi-Object Tracking (MOT), which often leads to inferior tracking results due to the missing detected objects. The common practice in multi-object tracking is re-identifying the missed objects after their reappearance. Though tracking performance can be boosted by the re-identification, the annotation of identity is required to train the model. In addition, such practice of re-identification still can not track those highly occluded objects when they are missed by the detector. In this paper, we focus on online multi-object tracking and design two novel modules, the unsupervised re-identification learning module and the occlusion estimation module, to handle these problems. Specifically, the proposed unsupervised re-identification learning module does not require any (pseudo) identity information nor suffer from the scalability issue. The proposed occlusion estimation module tries to predict the locations where occlusions happen, which are used to estimate the positions of missed objects by the detector. Our study shows that, when applied to state-of-the-art MOT methods, the proposed unsupervised re-identification learning is comparable to supervised re-identification learning, and the tracking performance is further improved by the proposed occlusion estimation module.
Stochastic Weight Averaging Revisited
Jan 03, 2022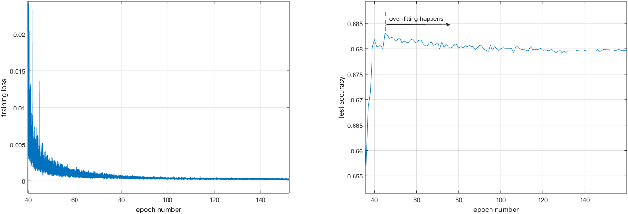

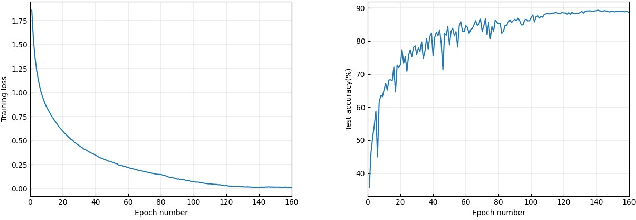
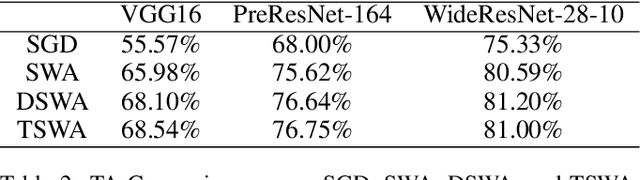
Stochastic weight averaging (SWA) is recognized as a simple while one effective approach to improve the generalization of stochastic gradient descent (SGD) for training deep neural networks (DNNs). A common insight to explain its success is that averaging weights following an SGD process equipped with cyclical or high constant learning rates can discover wider optima, which then lead to better generalization. We give a new insight that does not concur with the above one. We characterize that SWA's performance is highly dependent on to what extent the SGD process that runs before SWA converges, and the operation of weight averaging only contributes to variance reduction. This new insight suggests practical guides on better algorithm design. As an instantiation, we show that following an SGD process with insufficient convergence, running SWA more times leads to continual incremental benefits in terms of generalization. Our findings are corroborated by extensive experiments across different network architectures, including a baseline CNN, PreResNet-164, WideResNet-28-10, VGG16, ResNet-50, ResNet-152, DenseNet-161, and different datasets including CIFAR-{10,100}, and Imagenet.
Detecting and Identifying Optical Signal Attacks on Autonomous Driving Systems
Oct 20, 2021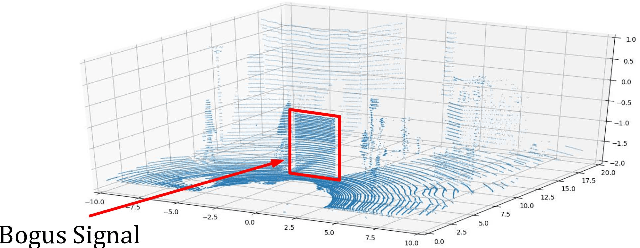

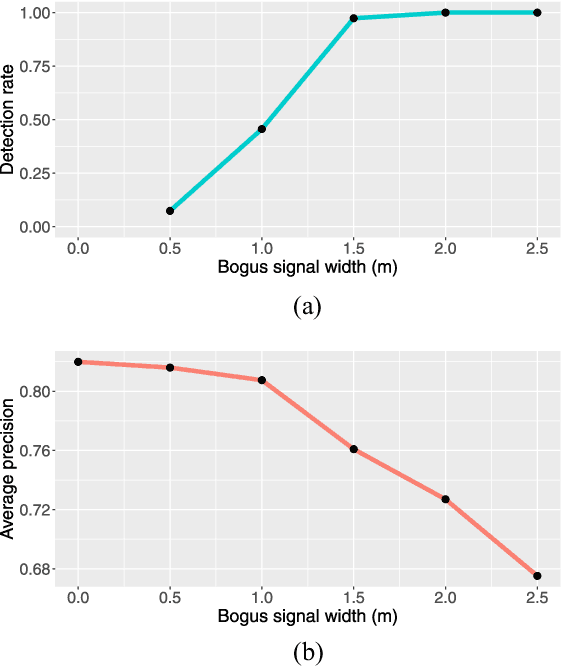
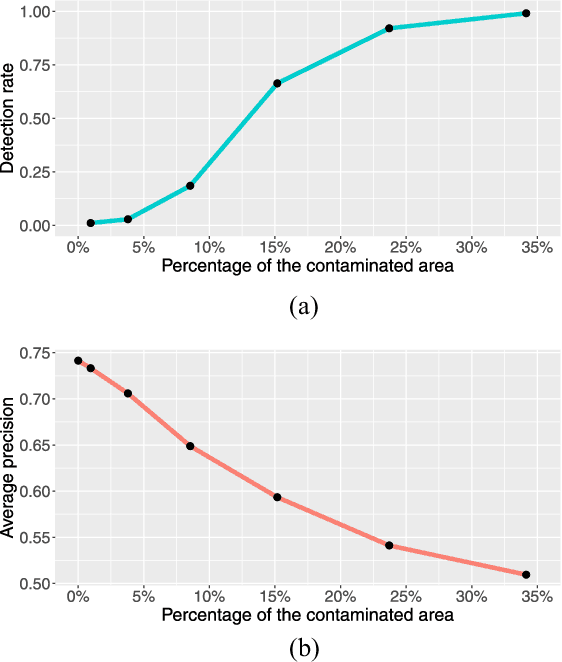
For autonomous driving, an essential task is to detect surrounding objects accurately. To this end, most existing systems use optical devices, including cameras and light detection and ranging (LiDAR) sensors, to collect environment data in real time. In recent years, many researchers have developed advanced machine learning models to detect surrounding objects. Nevertheless, the aforementioned optical devices are vulnerable to optical signal attacks, which could compromise the accuracy of object detection. To address this critical issue, we propose a framework to detect and identify sensors that are under attack. Specifically, we first develop a new technique to detect attacks on a system that consists of three sensors. Our main idea is to: 1) use data from three sensors to obtain two versions of depth maps (i.e., disparity) and 2) detect attacks by analyzing the distribution of disparity errors. In our study, we use real data sets and the state-of-the-art machine learning model to evaluate our attack detection scheme and the results confirm the effectiveness of our detection method. Based on the detection scheme, we further develop an identification model that is capable of identifying up to n-2 attacked sensors in a system with one LiDAR and n cameras. We prove the correctness of our identification scheme and conduct experiments to show the accuracy of our identification method. Finally, we investigate the overall sensitivity of our framework.
Unsupervised Finetuning
Oct 18, 2021

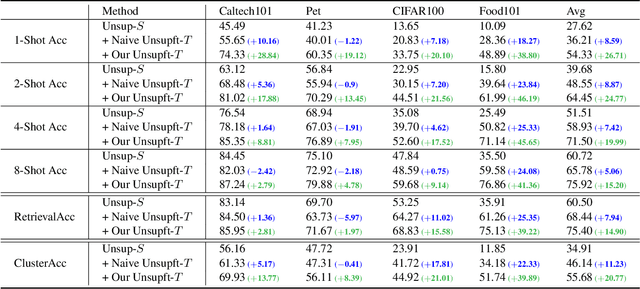
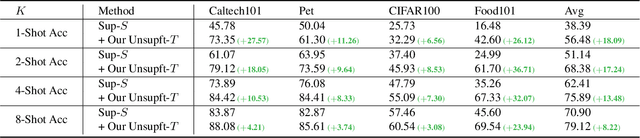
This paper studies "unsupervised finetuning", the symmetrical problem of the well-known "supervised finetuning". Given a pretrained model and small-scale unlabeled target data, unsupervised finetuning is to adapt the representation pretrained from the source domain to the target domain so that better transfer performance can be obtained. This problem is more challenging than the supervised counterpart, as the low data density in the small-scale target data is not friendly for unsupervised learning, leading to the damage of the pretrained representation and poor representation in the target domain. In this paper, we find the source data is crucial when shifting the finetuning paradigm from supervise to unsupervise, and propose two simple and effective strategies to combine source and target data into unsupervised finetuning: "sparse source data replaying", and "data mixing". The motivation of the former strategy is to add a small portion of source data back to occupy their pretrained representation space and help push the target data to reside in a smaller compact space; and the motivation of the latter strategy is to increase the data density and help learn more compact representation. To demonstrate the effectiveness of our proposed ``unsupervised finetuning'' strategy, we conduct extensive experiments on multiple different target datasets, which show better transfer performance than the naive strategy.
Asymmetric Graph Representation Learning
Oct 14, 2021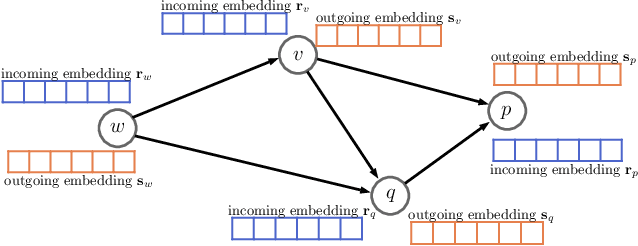
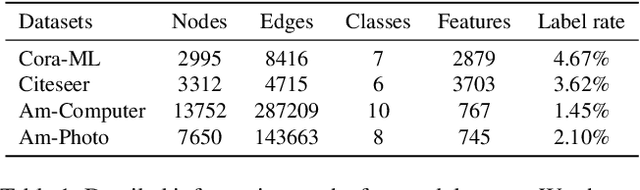
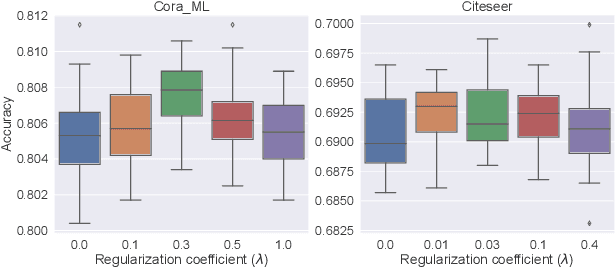
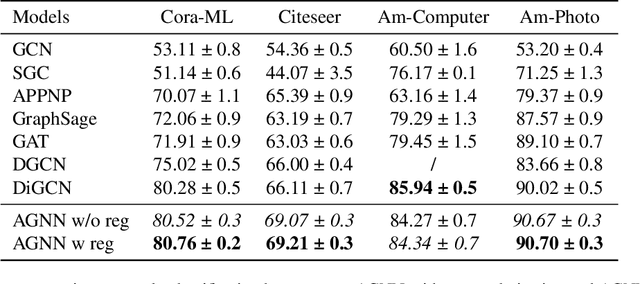
Despite the enormous success of graph neural networks (GNNs), most existing GNNs can only be applicable to undirected graphs where relationships among connected nodes are two-way symmetric (i.e., information can be passed back and forth). However, there is a vast amount of applications where the information flow is asymmetric, leading to directed graphs where information can only be passed in one direction. For example, a directed edge indicates that the information can only be conveyed forwardly from the start node to the end node, but not backwardly. To accommodate such an asymmetric structure of directed graphs within the framework of GNNs, we propose a simple yet remarkably effective framework for directed graph analysis to incorporate such one-way information passing. We define an incoming embedding and an outgoing embedding for each node to model its sending and receiving features respectively. We further develop two steps in our directed GNN model with the first one to aggregate/update the incoming features of nodes and the second one to aggregate/update the outgoing features. By imposing the two roles for each node, the likelihood of a directed edge can be calculated based on the outgoing embedding of the start node and the incoming embedding of the end node. The log-likelihood of all edges plays a natural role of regularization for the proposed model, which can alleviate the over-smoothing problem of the deep GNNs. Extensive experiments on multiple real-world directed graphs demonstrate outstanding performances of the proposed model in both node-level and graph-level tasks.
ISNet: Integrate Image-Level and Semantic-Level Context for Semantic Segmentation
Aug 27, 2021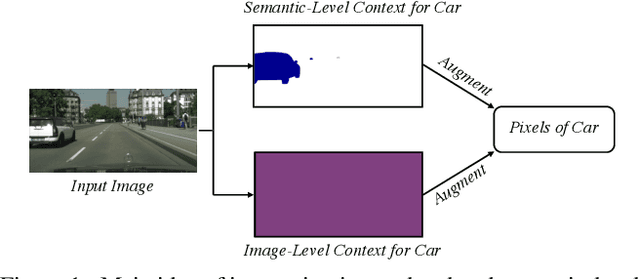

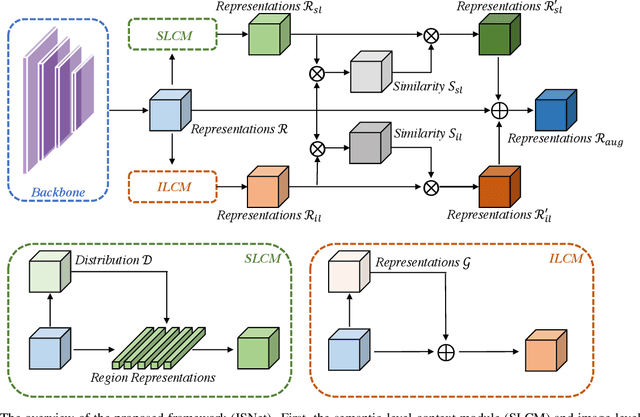
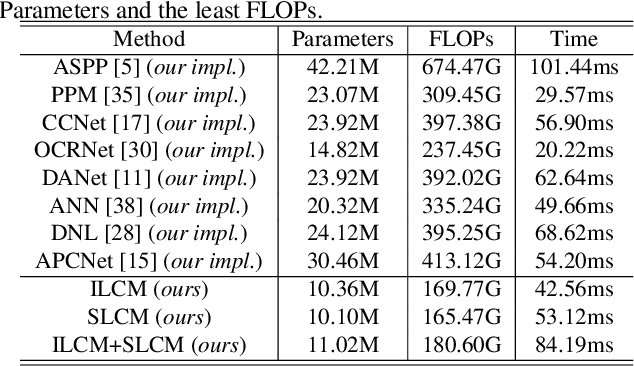
Co-occurrent visual pattern makes aggregating contextual information a common paradigm to enhance the pixel representation for semantic image segmentation. The existing approaches focus on modeling the context from the perspective of the whole image, i.e., aggregating the image-level contextual information. Despite impressive, these methods weaken the significance of the pixel representations of the same category, i.e., the semantic-level contextual information. To address this, this paper proposes to augment the pixel representations by aggregating the image-level and semantic-level contextual information, respectively. First, an image-level context module is designed to capture the contextual information for each pixel in the whole image. Second, we aggregate the representations of the same category for each pixel where the category regions are learned under the supervision of the ground-truth segmentation. Third, we compute the similarities between each pixel representation and the image-level contextual information, the semantic-level contextual information, respectively. At last, a pixel representation is augmented by weighted aggregating both the image-level contextual information and the semantic-level contextual information with the similarities as the weights. Integrating the image-level and semantic-level context allows this paper to report state-of-the-art accuracy on four benchmarks, i.e., ADE20K, LIP, COCOStuff and Cityscapes.