 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSceneFake: An Initial Dataset and Benchmarks for Scene Fake Audio Detection
Nov 11, 2022



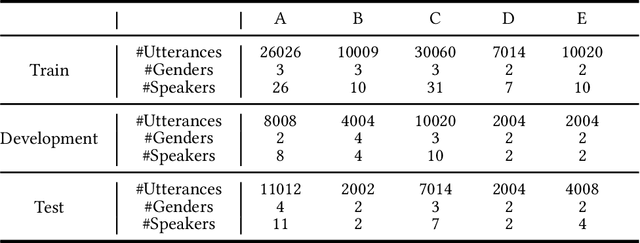
Previous databases have been designed to further the development of fake audio detection. However, fake utterances are mostly generated by altering timbre, prosody, linguistic content or channel noise of original audios. They ignore a fake situation, in which the attacker manipulates an acoustic scene of the original audio with another forgery one. It will pose a major threat to our society if some people misuse the manipulated audio with malicious purpose. Therefore, this motivates us to fill in the gap. This paper designs such a dataset for scene fake audio detection (SceneFake). A manipulated audio in the SceneFake dataset involves only tampering the acoustic scene of an utterance by using speech enhancement technologies. We can not only detect fake utterances on a seen test set but also evaluate the generalization of fake detection models to unseen manipulation attacks. Some benchmark results are described on the SceneFake dataset. Besides, an analysis of fake attacks with different speech enhancement technologies and signal-to-noise ratios are presented on the dataset. The results show that scene manipulated utterances can not be detected reliably by the existing baseline models of ASVspoof 2019. Furthermore, the detection of unseen scene manipulation audio is still challenging.
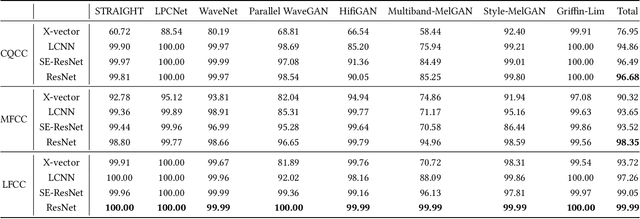
System Fingerprints Detection for DeepFake Audio: An Initial Dataset and Investigation
Aug 21, 2022
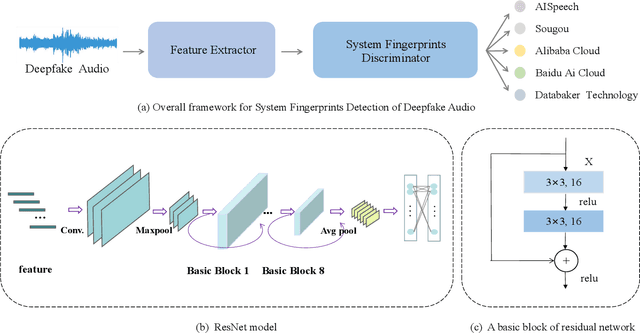
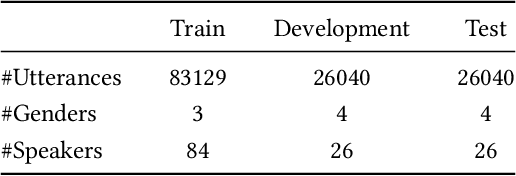
Many effective attempts have been made for deepfake audio detection. However, they can only distinguish between real and fake. For many practical application scenarios, what tool or algorithm generated the deepfake audio also is needed. This raises a question: Can we detect the system fingerprints of deepfake audio? Therefore, this paper conducts a preliminary investigation to detect system fingerprints of deepfake audio. Experiments are conducted on deepfake audio datasets from five latest deep-learning speech synthesis systems. The results show that LFCC features are relatively more suitable for system fingerprints detection. Moreover, the ResNet achieves the best detection results among LCNN and x-vector based models. The t-SNE visualization shows that different speech synthesis systems generate distinct system fingerprints.
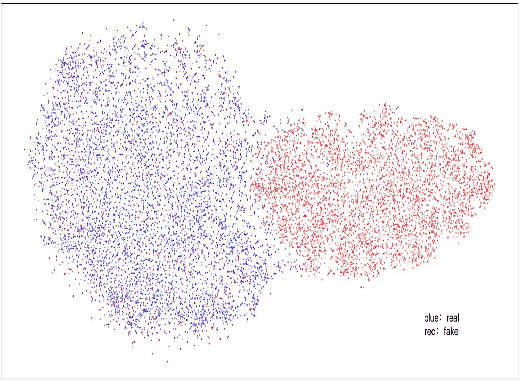
An Initial Investigation for Detecting Vocoder Fingerprints of Fake Audio
Aug 20, 2022

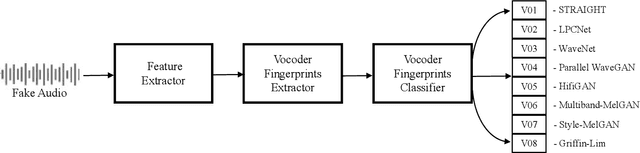
Many effective attempts have been made for fake audio detection. However, they can only provide detection results but no countermeasures to curb this harm. For many related practical applications, what model or algorithm generated the fake audio also is needed. Therefore, We propose a new problem for detecting vocoder fingerprints of fake audio. Experiments are conducted on the datasets synthesized by eight state-of-the-art vocoders. We have preliminarily explored the features and model architectures. The t-SNE visualization shows that different vocoders generate distinct vocoder fingerprints.
Fully Automated End-to-End Fake Audio Detection
Aug 20, 2022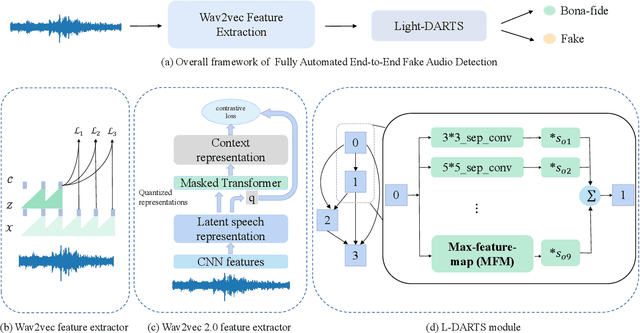
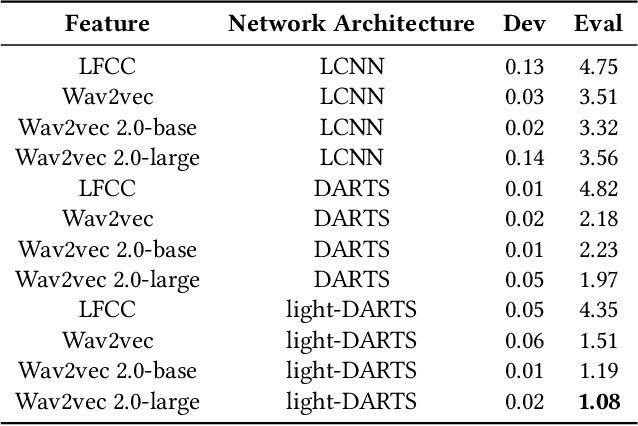

The existing fake audio detection systems often rely on expert experience to design the acoustic features or manually design the hyperparameters of the network structure. However, artificial adjustment of the parameters can have a relatively obvious influence on the results. It is almost impossible to manually set the best set of parameters. Therefore this paper proposes a fully automated end-toend fake audio detection method. We first use wav2vec pre-trained model to obtain a high-level representation of the speech. Furthermore, for the network structure, we use a modified version of the differentiable architecture search (DARTS) named light-DARTS. It learns deep speech representations while automatically learning and optimizing complex neural structures consisting of convolutional operations and residual blocks. The experimental results on the ASVspoof 2019 LA dataset show that our proposed system achieves an equal error rate (EER) of 1.08%, which outperforms the state-of-the-art single system.
ADD 2022: the First Audio Deep Synthesis Detection Challenge
Feb 26, 2022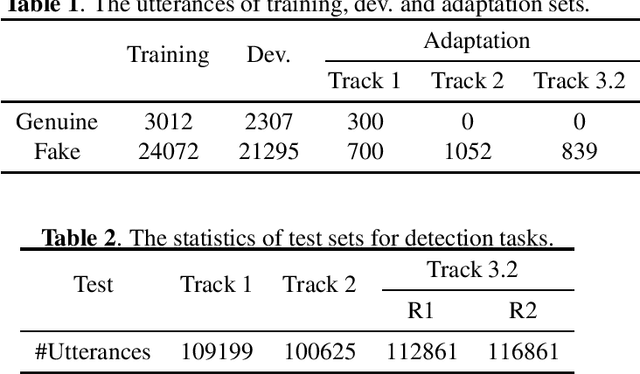
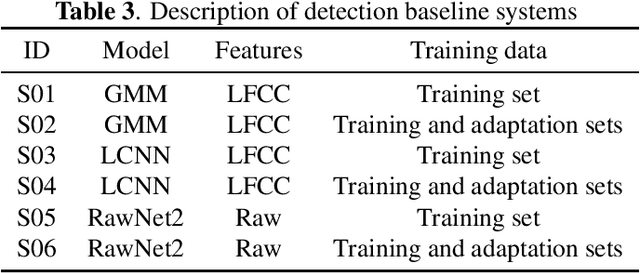
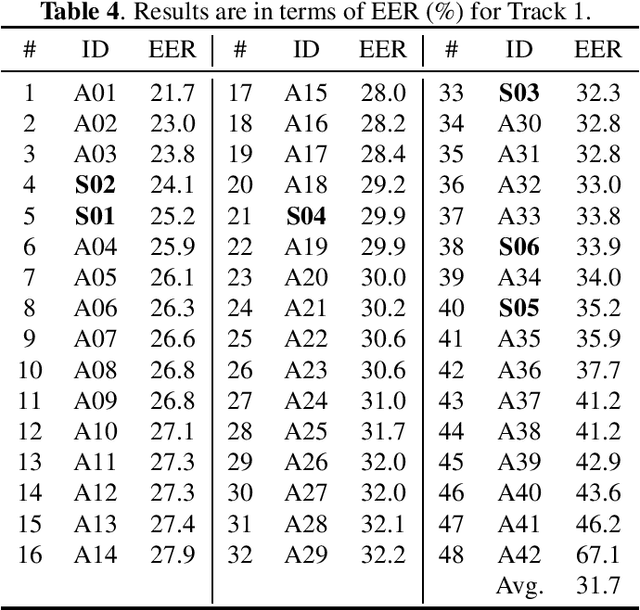
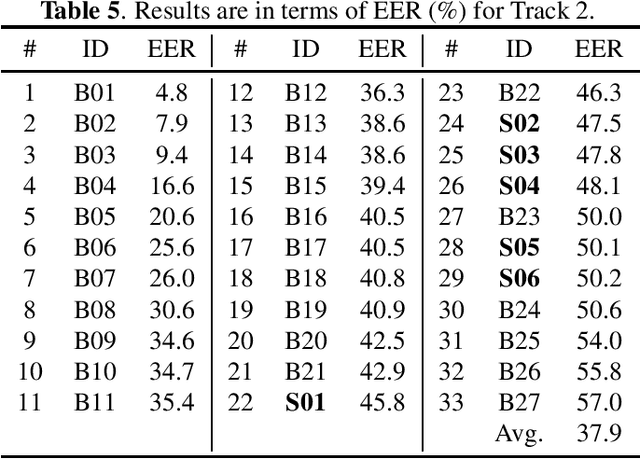
Audio deepfake detection is an emerging topic, which was included in the ASVspoof 2021. However, the recent shared tasks have not covered many real-life and challenging scenarios. The first Audio Deep synthesis Detection challenge (ADD) was motivated to fill in the gap. The ADD 2022 includes three tracks: low-quality fake audio detection (LF), partially fake audio detection (PF) and audio fake game (FG). The LF track focuses on dealing with bona fide and fully fake utterances with various real-world noises etc. The PF track aims to distinguish the partially fake audio from the real. The FG track is a rivalry game, which includes two tasks: an audio generation task and an audio fake detection task. In this paper, we describe the datasets, evaluation metrics, and protocols. We also report major findings that reflect the recent advances in audio deepfake detection tasks.
Continual Learning for Fake Audio Detection
Apr 15, 2021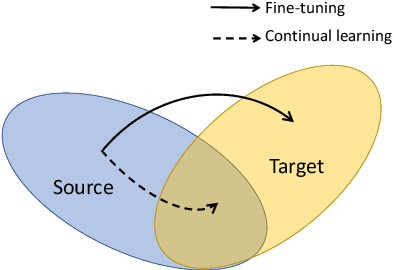
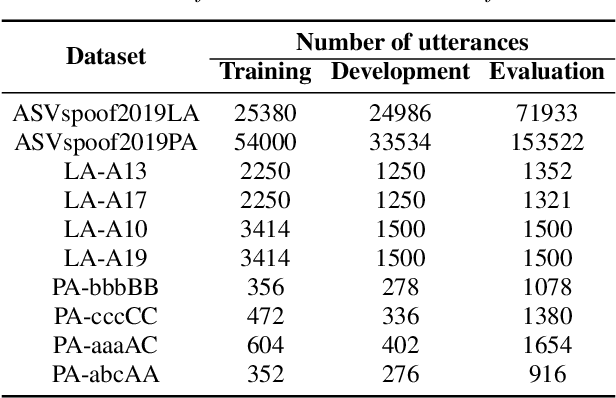
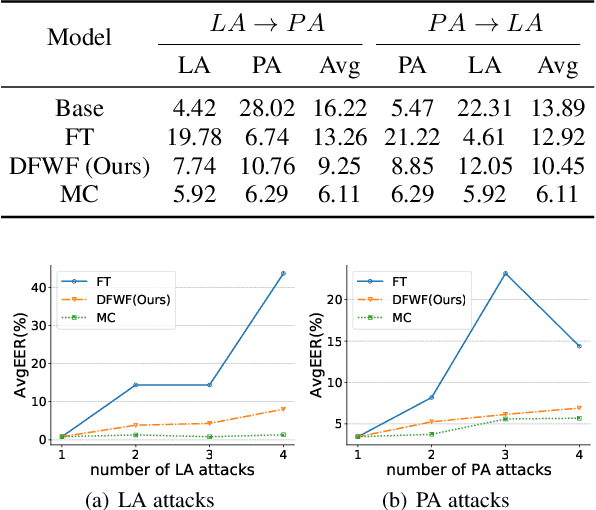

Fake audio attack becomes a major threat to the speaker verification system. Although current detection approaches have achieved promising results on dataset-specific scenarios, they encounter difficulties on unseen spoofing data. Fine-tuning and retraining from scratch have been applied to incorporate new data. However, fine-tuning leads to performance degradation on previous data. Retraining takes a lot of time and computation resources. Besides, previous data are unavailable due to privacy in some situations. To solve the above problems, this paper proposes detecting fake without forgetting, a continual-learning-based method, to make the model learn new spoofing attacks incrementally. A knowledge distillation loss is introduced to loss function to preserve the memory of original model. Supposing the distribution of genuine voice is consistent among different scenarios, an extra embedding similarity loss is used as another constraint to further do a positive sample alignment. Experiments are conducted on the ASVspoof2019 dataset. The results show that our proposed method outperforms fine-tuning by the relative reduction of average equal error rate up to 81.62%.
NavTuner: Learning a Scene-Sensitive Family of Navigation Policies
Mar 02, 2021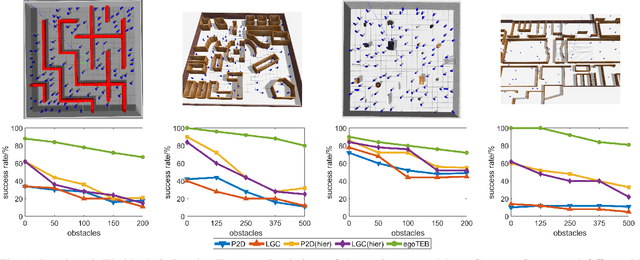
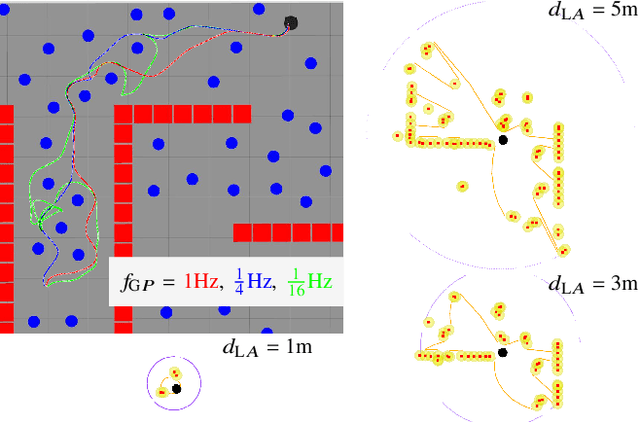

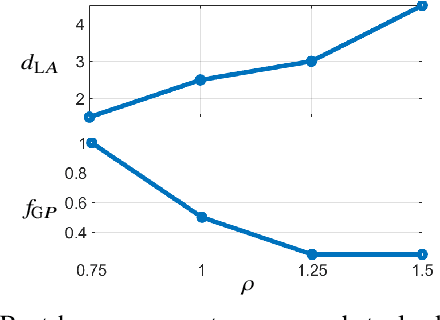
The advent of deep learning has inspired research into end-to-end learning for a variety of problem domains in robotics. For navigation, the resulting methods may not have the generalization properties desired let alone match the performance of traditional methods. Instead of learning a navigation policy, we explore learning an adaptive policy in the parameter space of an existing navigation module. Having adaptive parameters provides the navigation module with a family of policies that can be dynamically reconfigured based on the local scene structure, and addresses the common assertion in machine learning that engineered solutions are inflexible. Of the methods tested, reinforcement learning (RL) is shown to provide a significant performance boost to a modern navigation method through reduced sensitivity of its success rate to environmental clutter. The outcomes indicate that RL as a meta-policy learner, or dynamic parameter tuner, effectively robustifies algorithms sensitive to external, measurable nuisance factors.
VommaNet: an End-to-End Network for Disparity Estimation from Reflective and Texture-less Light Field Images
Nov 17, 2018
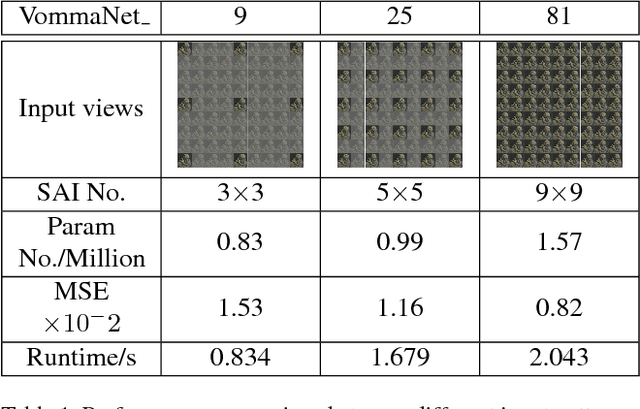
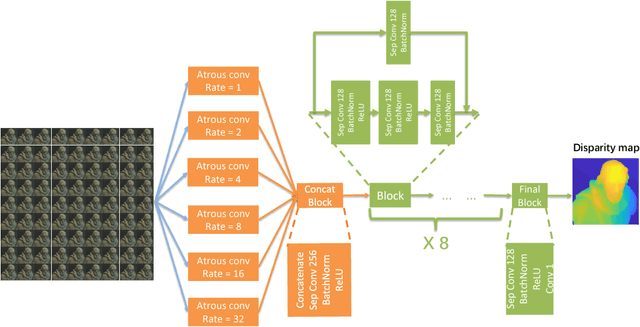
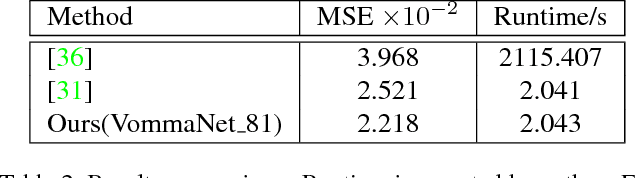
The precise combination of image sensor and micro-lens array enables lenslet light field cameras to record both angular and spatial information of incoming light, therefore, one can calculate disparity and depth from light field images. In turn, 3D models of the recorded objects can be recovered, which is a great advantage over other imaging system. However, reflective and texture-less areas in light field images have complicated conditions, making it hard to correctly calculate disparity with existing algorithms. To tackle this problem, we introduce a novel end-to-end network VommaNet to retrieve multi-scale features from reflective and texture-less regions for accurate disparity estimation. Meanwhile, our network has achieved similar or better performance in other regions for both synthetic light field images and real-world data compared to the state-of-the-art algorithms. Currently, we achieve the best score for mean squared error (MSE) on HCI 4D Light Field Benchmark.