 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Your Perspective: Controllable 3D Generation from Any Viewpoint in a Driving Scene
Feb 10, 2025



Self-driving cars relying solely on ego-centric perception face limitations in sensing, often failing to detect occluded, faraway objects. Collaborative autonomous driving (CAV) seems like a promising direction, but collecting data for development is non-trivial. It requires placing multiple sensor-equipped agents in a real-world driving scene, simultaneously! As such, existing datasets are limited in locations and agents. We introduce a novel surrogate to the rescue, which is to generate realistic perception from different viewpoints in a driving scene, conditioned on a real-world sample - the ego-car's sensory data. This surrogate has huge potential: it could potentially turn any ego-car dataset into a collaborative driving one to scale up the development of CAV. We present the very first solution, using a combination of simulated collaborative data and real ego-car data. Our method, Transfer Your Perspective (TYP), learns a conditioned diffusion model whose output samples are not only realistic but also consistent in both semantics and layouts with the given ego-car data. Empirical results demonstrate TYP's effectiveness in aiding in a CAV setting. In particular, TYP enables us to (pre-)train collaborative perception algorithms like early and late fusion with little or no real-world collaborative data, greatly facilitating downstream CAV applications.
Video Creation by Demonstration
Dec 12, 2024



We explore a novel video creation experience, namely Video Creation by Demonstration. Given a demonstration video and a context image from a different scene, we generate a physically plausible video that continues naturally from the context image and carries out the action concepts from the demonstration. To enable this capability, we present $\delta$-Diffusion, a self-supervised training approach that learns from unlabeled videos by conditional future frame prediction. Unlike most existing video generation controls that are based on explicit signals, we adopts the form of implicit latent control for maximal flexibility and expressiveness required by general videos. By leveraging a video foundation model with an appearance bottleneck design on top, we extract action latents from demonstration videos for conditioning the generation process with minimal appearance leakage. Empirically, $\delta$-Diffusion outperforms related baselines in terms of both human preference and large-scale machine evaluations, and demonstrates potentials towards interactive world simulation. Sampled video generation results are available at https://delta-diffusion.github.io/.
Generating 3D-Consistent Videos from Unposed Internet Photos
Nov 20, 2024



We address the problem of generating videos from unposed internet photos. A handful of input images serve as keyframes, and our model interpolates between them to simulate a path moving between the cameras. Given random images, a model's ability to capture underlying geometry, recognize scene identity, and relate frames in terms of camera position and orientation reflects a fundamental understanding of 3D structure and scene layout. However, existing video models such as Luma Dream Machine fail at this task. We design a self-supervised method that takes advantage of the consistency of videos and variability of multiview internet photos to train a scalable, 3D-aware video model without any 3D annotations such as camera parameters. We validate that our method outperforms all baselines in terms of geometric and appearance consistency. We also show our model benefits applications that enable camera control, such as 3D Gaussian Splatting. Our results suggest that we can scale up scene-level 3D learning using only 2D data such as videos and multiview internet photos.
AllClear: A Comprehensive Dataset and Benchmark for Cloud Removal in Satellite Imagery
Oct 31, 2024



Clouds in satellite imagery pose a significant challenge for downstream applications. A major challenge in current cloud removal research is the absence of a comprehensive benchmark and a sufficiently large and diverse training dataset. To address this problem, we introduce the largest public dataset -- $\textit{AllClear}$ for cloud removal, featuring 23,742 globally distributed regions of interest (ROIs) with diverse land-use patterns, comprising 4 million images in total. Each ROI includes complete temporal captures from the year 2022, with (1) multi-spectral optical imagery from Sentinel-2 and Landsat 8/9, (2) synthetic aperture radar (SAR) imagery from Sentinel-1, and (3) auxiliary remote sensing products such as cloud masks and land cover maps. We validate the effectiveness of our dataset by benchmarking performance, demonstrating the scaling law -- the PSNR rises from $28.47$ to $33.87$ with $30\times$ more data, and conducting ablation studies on the temporal length and the importance of individual modalities. This dataset aims to provide comprehensive coverage of the Earth's surface and promote better cloud removal results.
Scale-Aware Recognition in Satellite Images under Resource Constraint
Oct 31, 2024



Recognition of features in satellite imagery (forests, swimming pools, etc.) depends strongly on the spatial scale of the concept and therefore the resolution of the images. This poses two challenges: Which resolution is best suited for recognizing a given concept, and where and when should the costlier higher-resolution (HR) imagery be acquired? We present a novel scheme to address these challenges by introducing three components: (1) A technique to distill knowledge from models trained on HR imagery to recognition models that operate on imagery of lower resolution (LR), (2) a sampling strategy for HR imagery based on model disagreement, and (3) an LLM-based approach for inferring concept "scale". With these components we present a system to efficiently perform scale-aware recognition in satellite imagery, improving accuracy over single-scale inference while following budget constraints. Our novel approach offers up to a 26.3% improvement over entirely HR baselines, using 76.3% fewer HR images.
Learning 3D Perception from Others' Predictions
Oct 03, 2024



Accurate 3D object detection in real-world environments requires a huge amount of annotated data with high quality. Acquiring such data is tedious and expensive, and often needs repeated effort when a new sensor is adopted or when the detector is deployed in a new environment. We investigate a new scenario to construct 3D object detectors: learning from the predictions of a nearby unit that is equipped with an accurate detector. For example, when a self-driving car enters a new area, it may learn from other traffic participants whose detectors have been optimized for that area. This setting is label-efficient, sensor-agnostic, and communication-efficient: nearby units only need to share the predictions with the ego agent (e.g., car). Naively using the received predictions as ground-truths to train the detector for the ego car, however, leads to inferior performance. We systematically study the problem and identify viewpoint mismatches and mislocalization (due to synchronization and GPS errors) as the main causes, which unavoidably result in false positives, false negatives, and inaccurate pseudo labels. We propose a distance-based curriculum, first learning from closer units with similar viewpoints and subsequently improving the quality of other units' predictions via self-training. We further demonstrate that an effective pseudo label refinement module can be trained with a handful of annotated data, largely reducing the data quantity necessary to train an object detector. We validate our approach on the recently released real-world collaborative driving dataset, using reference cars' predictions as pseudo labels for the ego car. Extensive experiments including several scenarios (e.g., different sensors, detectors, and domains) demonstrate the effectiveness of our approach toward label-efficient learning of 3D perception from other units' predictions.
Counter-Current Learning: A Biologically Plausible Dual Network Approach for Deep Learning
Sep 30, 2024Despite its widespread use in neural networks, error backpropagation has faced criticism for its lack of biological plausibility, suffering from issues such as the backward locking problem and the weight transport problem. These limitations have motivated researchers to explore more biologically plausible learning algorithms that could potentially shed light on how biological neural systems adapt and learn. Inspired by the counter-current exchange mechanisms observed in biological systems, we propose counter-current learning (CCL), a biologically plausible framework for credit assignment in neural networks. This framework employs a feedforward network to process input data and a feedback network to process targets, with each network enhancing the other through anti-parallel signal propagation. By leveraging the more informative signals from the bottom layer of the feedback network to guide the updates of the top layer of the feedforward network and vice versa, CCL enables the simultaneous transformation of source inputs to target outputs and the dynamic mutual influence of these transformations. Experimental results on MNIST, FashionMNIST, CIFAR10, and CIFAR100 datasets using multi-layer perceptrons and convolutional neural networks demonstrate that CCL achieves comparable performance to other biologically plausible algorithms while offering a more biologically realistic learning mechanism. Furthermore, we showcase the applicability of our approach to an autoencoder task, underscoring its potential for unsupervised representation learning. Our work presents a direction for biologically inspired and plausible learning algorithms, offering an alternative mechanisms of learning and adaptation in neural networks.
ObjectCarver: Semi-automatic segmentation, reconstruction and separation of 3D objects
Jul 26, 2024



Implicit neural fields have made remarkable progress in reconstructing 3D surfaces from multiple images; however, they encounter challenges when it comes to separating individual objects within a scene. Previous work has attempted to tackle this problem by introducing a framework to train separate signed distance fields (SDFs) simultaneously for each of N objects and using a regularization term to prevent objects from overlapping. However, all of these methods require segmentation masks to be provided, which are not always readily available. We introduce our method, ObjectCarver, to tackle the problem of object separation from just click input in a single view. Given posed multi-view images and a set of user-input clicks to prompt segmentation of the individual objects, our method decomposes the scene into separate objects and reconstructs a high-quality 3D surface for each one. We introduce a loss function that prevents floaters and avoids inappropriate carving-out due to occlusion. In addition, we introduce a novel scene initialization method that significantly speeds up the process while preserving geometric details compared to previous approaches. Despite requiring neither ground truth masks nor monocular cues, our method outperforms baselines both qualitatively and quantitatively. In addition, we introduce a new benchmark dataset for evaluation.
MegaScenes: Scene-Level View Synthesis at Scale
Jun 17, 2024



Scene-level novel view synthesis (NVS) is fundamental to many vision and graphics applications. Recently, pose-conditioned diffusion models have led to significant progress by extracting 3D information from 2D foundation models, but these methods are limited by the lack of scene-level training data. Common dataset choices either consist of isolated objects (Objaverse), or of object-centric scenes with limited pose distributions (DTU, CO3D). In this paper, we create a large-scale scene-level dataset from Internet photo collections, called MegaScenes, which contains over 100K structure from motion (SfM) reconstructions from around the world. Internet photos represent a scalable data source but come with challenges such as lighting and transient objects. We address these issues to further create a subset suitable for the task of NVS. Additionally, we analyze failure cases of state-of-the-art NVS methods and significantly improve generation consistency. Through extensive experiments, we validate the effectiveness of both our dataset and method on generating in-the-wild scenes. For details on the dataset and code, see our project page at https://megascenes.github.io .
DiffuBox: Refining 3D Object Detection with Point Diffusion
May 25, 2024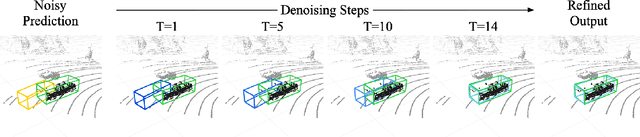
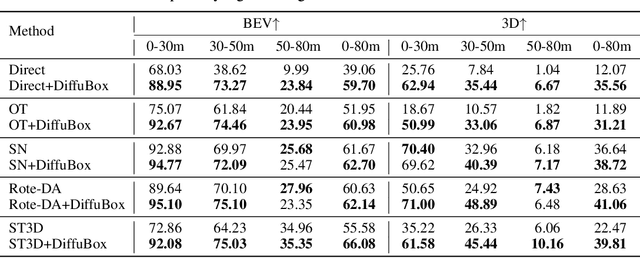
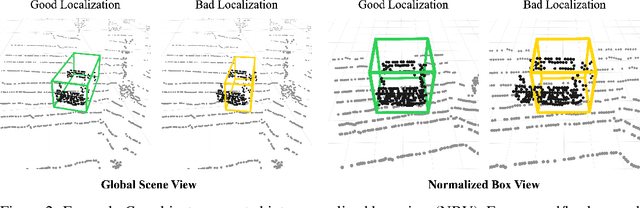
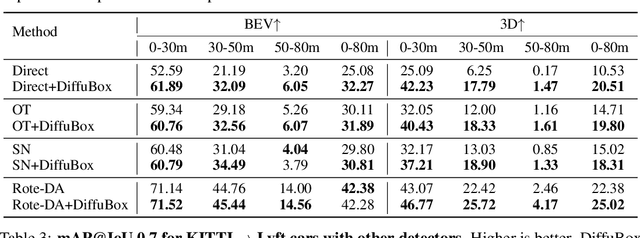
Ensuring robust 3D object detection and localization is crucial for many applications in robotics and autonomous driving. Recent models, however, face difficulties in maintaining high performance when applied to domains with differing sensor setups or geographic locations, often resulting in poor localization accuracy due to domain shift. To overcome this challenge, we introduce a novel diffusion-based box refinement approach. This method employs a domain-agnostic diffusion model, conditioned on the LiDAR points surrounding a coarse bounding box, to simultaneously refine the box's location, size, and orientation. We evaluate this approach under various domain adaptation settings, and our results reveal significant improvements across different datasets, object classes and detectors.