 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistractor-aware Event-based Tracking
Oct 29, 2023



Event cameras, or dynamic vision sensors, have recently achieved success from fundamental vision tasks to high-level vision researches. Due to its ability to asynchronously capture light intensity changes, event camera has an inherent advantage to capture moving objects in challenging scenarios including objects under low light, high dynamic range, or fast moving objects. Thus event camera are natural for visual object tracking. However, the current event-based trackers derived from RGB trackers simply modify the input images to event frames and still follow conventional tracking pipeline that mainly focus on object texture for target distinction. As a result, the trackers may not be robust dealing with challenging scenarios such as moving cameras and cluttered foreground. In this paper, we propose a distractor-aware event-based tracker that introduces transformer modules into Siamese network architecture (named DANet). Specifically, our model is mainly composed of a motion-aware network and a target-aware network, which simultaneously exploits both motion cues and object contours from event data, so as to discover motion objects and identify the target object by removing dynamic distractors. Our DANet can be trained in an end-to-end manner without any post-processing and can run at over 80 FPS on a single V100. We conduct comprehensive experiments on two large event tracking datasets to validate the proposed model. We demonstrate that our tracker has superior performance against the state-of-the-art trackers in terms of both accuracy and efficiency.
A Geometrical Approach to Evaluate the Adversarial Robustness of Deep Neural Networks
Oct 10, 2023



Deep Neural Networks (DNNs) are widely used for computer vision tasks. However, it has been shown that deep models are vulnerable to adversarial attacks, i.e., their performances drop when imperceptible perturbations are made to the original inputs, which may further degrade the following visual tasks or introduce new problems such as data and privacy security. Hence, metrics for evaluating the robustness of deep models against adversarial attacks are desired. However, previous metrics are mainly proposed for evaluating the adversarial robustness of shallow networks on the small-scale datasets. Although the Cross Lipschitz Extreme Value for nEtwork Robustness (CLEVER) metric has been proposed for large-scale datasets (e.g., the ImageNet dataset), it is computationally expensive and its performance relies on a tractable number of samples. In this paper, we propose the Adversarial Converging Time Score (ACTS), an attack-dependent metric that quantifies the adversarial robustness of a DNN on a specific input. Our key observation is that local neighborhoods on a DNN's output surface would have different shapes given different inputs. Hence, given different inputs, it requires different time for converging to an adversarial sample. Based on this geometry meaning, ACTS measures the converging time as an adversarial robustness metric. We validate the effectiveness and generalization of the proposed ACTS metric against different adversarial attacks on the large-scale ImageNet dataset using state-of-the-art deep networks. Extensive experiments show that our ACTS metric is an efficient and effective adversarial metric over the previous CLEVER metric.
Referring Image Segmentation Using Text Supervision
Aug 28, 2023



Existing Referring Image Segmentation (RIS) methods typically require expensive pixel-level or box-level annotations for supervision. In this paper, we observe that the referring texts used in RIS already provide sufficient information to localize the target object. Hence, we propose a novel weakly-supervised RIS framework to formulate the target localization problem as a classification process to differentiate between positive and negative text expressions. While the referring text expressions for an image are used as positive expressions, the referring text expressions from other images can be used as negative expressions for this image. Our framework has three main novelties. First, we propose a bilateral prompt method to facilitate the classification process, by harmonizing the domain discrepancy between visual and linguistic features. Second, we propose a calibration method to reduce noisy background information and improve the correctness of the response maps for target object localization. Third, we propose a positive response map selection strategy to generate high-quality pseudo-labels from the enhanced response maps, for training a segmentation network for RIS inference. For evaluation, we propose a new metric to measure localization accuracy. Experiments on four benchmarks show that our framework achieves promising performances to existing fully-supervised RIS methods while outperforming state-of-the-art weakly-supervised methods adapted from related areas. Code is available at https://github.com/fawnliu/TRIS.
Fast Adversarial Training with Smooth Convergence
Aug 24, 2023Fast adversarial training (FAT) is beneficial for improving the adversarial robustness of neural networks. However, previous FAT work has encountered a significant issue known as catastrophic overfitting when dealing with large perturbation budgets, \ie the adversarial robustness of models declines to near zero during training. To address this, we analyze the training process of prior FAT work and observe that catastrophic overfitting is accompanied by the appearance of loss convergence outliers. Therefore, we argue a moderately smooth loss convergence process will be a stable FAT process that solves catastrophic overfitting. To obtain a smooth loss convergence process, we propose a novel oscillatory constraint (dubbed ConvergeSmooth) to limit the loss difference between adjacent epochs. The convergence stride of ConvergeSmooth is introduced to balance convergence and smoothing. Likewise, we design weight centralization without introducing additional hyperparameters other than the loss balance coefficient. Our proposed methods are attack-agnostic and thus can improve the training stability of various FAT techniques. Extensive experiments on popular datasets show that the proposed methods efficiently avoid catastrophic overfitting and outperform all previous FAT methods. Code is available at \url{https://github.com/FAT-CS/ConvergeSmooth}.
Exploring Part-Informed Visual-Language Learning for Person Re-Identification
Aug 04, 2023



Recently, visual-language learning has shown great potential in enhancing visual-based person re-identification (ReID). Existing visual-language learning-based ReID methods often focus on whole-body scale image-text feature alignment, while neglecting supervisions on fine-grained part features. This choice simplifies the learning process but cannot guarantee within-part feature semantic consistency thus hindering the final performance. Therefore, we propose to enhance fine-grained visual features with part-informed language supervision for ReID tasks. The proposed method, named Part-Informed Visual-language Learning ($\pi$-VL), suggests that (i) a human parsing-guided prompt tuning strategy and (ii) a hierarchical fusion-based visual-language alignment paradigm play essential roles in ensuring within-part feature semantic consistency. Specifically, we combine both identity labels and parsing maps to constitute pixel-level text prompts and fuse multi-stage visual features with a light-weight auxiliary head to perform fine-grained image-text alignment. As a plug-and-play and inference-free solution, our $\pi$-VL achieves substantial improvements over previous state-of-the-arts on four common-used ReID benchmarks, especially reporting 90.3% Rank-1 and 76.5% mAP for the most challenging MSMT17 database without bells and whistles.
A Survey on Temporal Knowledge Graph Completion: Taxonomy, Progress, and Prospects
Aug 04, 2023Temporal characteristics are prominently evident in a substantial volume of knowledge, which underscores the pivotal role of Temporal Knowledge Graphs (TKGs) in both academia and industry. However, TKGs often suffer from incompleteness for three main reasons: the continuous emergence of new knowledge, the weakness of the algorithm for extracting structured information from unstructured data, and the lack of information in the source dataset. Thus, the task of Temporal Knowledge Graph Completion (TKGC) has attracted increasing attention, aiming to predict missing items based on the available information. In this paper, we provide a comprehensive review of TKGC methods and their details. Specifically, this paper mainly consists of three components, namely, 1)Background, which covers the preliminaries of TKGC methods, loss functions required for training, as well as the dataset and evaluation protocol; 2)Interpolation, that estimates and predicts the missing elements or set of elements through the relevant available information. It further categorizes related TKGC methods based on how to process temporal information; 3)Extrapolation, which typically focuses on continuous TKGs and predicts future events, and then classifies all extrapolation methods based on the algorithms they utilize. We further pinpoint the challenges and discuss future research directions of TKGC.
Frame-Event Alignment and Fusion Network for High Frame Rate Tracking
May 25, 2023



Most existing RGB-based trackers target low frame rate benchmarks of around 30 frames per second. This setting restricts the tracker's functionality in the real world, especially for fast motion. Event-based cameras as bioinspired sensors provide considerable potential for high frame rate tracking due to their high temporal resolution. However, event-based cameras cannot offer fine-grained texture information like conventional cameras. This unique complementarity motivates us to combine conventional frames and events for high frame rate object tracking under various challenging conditions. Inthispaper, we propose an end-to-end network consisting of multi-modality alignment and fusion modules to effectively combine meaningful information from both modalities at different measurement rates. The alignment module is responsible for cross-style and cross-frame-rate alignment between frame and event modalities under the guidance of the moving cues furnished by events. While the fusion module is accountable for emphasizing valuable features and suppressing noise information by the mutual complement between the two modalities. Extensive experiments show that the proposed approach outperforms state-of-the-art trackers by a significant margin in high frame rate tracking. With the FE240hz dataset, our approach achieves high frame rate tracking up to 240Hz.
ALR-GAN: Adaptive Layout Refinement for Text-to-Image Synthesis
Apr 13, 2023We propose a novel Text-to-Image Generation Network, Adaptive Layout Refinement Generative Adversarial Network (ALR-GAN), to adaptively refine the layout of synthesized images without any auxiliary information. The ALR-GAN includes an Adaptive Layout Refinement (ALR) module and a Layout Visual Refinement (LVR) loss. The ALR module aligns the layout structure (which refers to locations of objects and background) of a synthesized image with that of its corresponding real image. In ALR module, we proposed an Adaptive Layout Refinement (ALR) loss to balance the matching of hard and easy features, for more efficient layout structure matching. Based on the refined layout structure, the LVR loss further refines the visual representation within the layout area. Experimental results on two widely-used datasets show that ALR-GAN performs competitively at the Text-to-Image generation task.
SEMv2: Table Separation Line Detection Based on Conditional Convolution
Mar 08, 2023



Table structure recognition is an indispensable element for enabling machines to comprehend tables. Its primary purpose is to identify the internal structure of a table. Nevertheless, due to the complexity and diversity of their structure and style, it is highly challenging to parse the tabular data into a structured format that machines can comprehend. In this work, we adhere to the principle of the split-and-merge based methods and propose an accurate table structure recognizer, termed SEMv2 (SEM: Split, Embed and Merge). Unlike the previous works in the ``split'' stage, we aim to address the table separation line instance-level discrimination problem and introduce a table separation line detection strategy based on conditional convolution. Specifically, we design the ``split'' in a top-down manner that detects the table separation line instance first and then dynamically predicts the table separation line mask for each instance. The final table separation line shape can be accurately obtained by processing the table separation line mask in a row-wise/column-wise manner. To comprehensively evaluate the SEMv2, we also present a more challenging dataset for table structure recognition, dubbed iFLYTAB, which encompasses multiple style tables in various scenarios such as photos, scanned documents, etc. Extensive experiments on publicly available datasets (e.g. SciTSR, PubTabNet and iFLYTAB) demonstrate the efficacy of our proposed approach. The code and iFLYTAB dataset will be made publicly available upon acceptance of this paper.
Point Cloud Scene Completion with Joint Color and Semantic Estimation from Single RGB-D Image
Oct 12, 2022
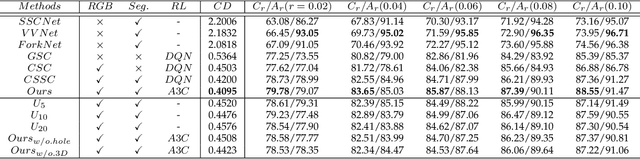
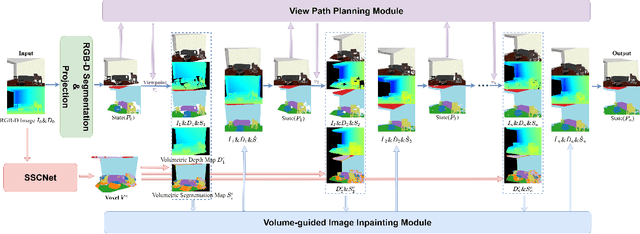
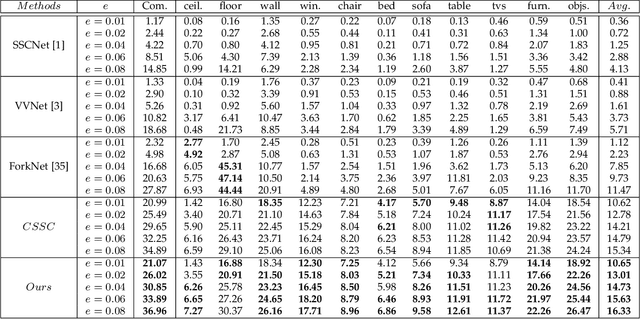
We present a deep reinforcement learning method of progressive view inpainting for colored semantic point cloud scene completion under volume guidance, achieving high-quality scene reconstruction from only a single RGB-D image with severe occlusion. Our approach is end-to-end, consisting of three modules: 3D scene volume reconstruction, 2D RGB-D and segmentation image inpainting, and multi-view selection for completion. Given a single RGB-D image, our method first predicts its semantic segmentation map and goes through the 3D volume branch to obtain a volumetric scene reconstruction as a guide to the next view inpainting step, which attempts to make up the missing information; the third step involves projecting the volume under the same view of the input, concatenating them to complete the current view RGB-D and segmentation map, and integrating all RGB-D and segmentation maps into the point cloud. Since the occluded areas are unavailable, we resort to a A3C network to glance around and pick the next best view for large hole completion progressively until a scene is adequately reconstructed while guaranteeing validity. All steps are learned jointly to achieve robust and consistent results. We perform qualitative and quantitative evaluations with extensive experiments on the 3D-FUTURE data, obtaining better results than state-of-the-arts.