 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadiomics- and Clinical Feature-Driven Prediction of Volumetric Response in Skull-Base Meningioma after CyberKnife Radiosurgery
Apr 27, 2026Skull-base meningiomas are often characterized by favorable long-term prognosis, yet their anatomical complexity and proximity to critical neurovascular structures make treatment selection challenging. Stereotactic radiosurgery with CyberKnife represents an effective therapeutic option when surgical resection is not feasible; however, not all patients benefit equally from this treatment. Early identification of patients likely to respond to radiosurgery remains an open clinical problem. In this study, we propose a radiomics- and clinical feature-driven framework for predicting volumetric response in skull-base meningiomas treated with CyberKnife. Unlike most existing approaches that focus on progression-free survival or recurrence, our method targets volumetric response as an indicator of treatment efficacy. Pre-treatment MRI images from 104 patients were processed to extract radiomic features, which were combined with clinical variables and analyzed using six models. To ensure methodological rigor, the entire modeling process was implemented within a nested cross-validation scheme. Among the evaluated models, TabPFN achieved the best overall performance, with an AUC of 0.81 and consistently favorable classification metrics. These results suggest that advanced machine learning architectures, when combined with robust validation strategies, can effectively capture patterns associated with treatment response even in small-sample, high-dimensional settings.
Touchless Intraoperative Image Access System Based on Vision-Based Hand Tracking
Apr 27, 2026Touchless interaction with medical images is becoming increasingly important in the surgical field, where sterility and continuity of the operational workflow are essential requirements. This work presents a vision-based system for intraoperative navigation of medical images through hand gestures acquired using a single RGB camera. Unlike many existing solutions, the system does not require additional hardware or user-specific training. Hand tracking is performed in real time using MediaPipe Hands, which provides a 2.5D estimation of hand landmarks. Simple and intuitive gestures are then mapped into translation, rotation, and zoom commands, enabling continuous and natural interaction with the image viewer. The system architecture is independent from the visualization software and, for implementation simplicity, in this study it was integrated with PyVista. Performance was evaluated through frame-level logging and quantitative analysis of latency, stability, and interaction robustness metrics. Experimental results highlight real-time behavior, with reduced latencies and stable control, in line with the requirements of fluid interaction. The system demonstrates the feasibility of a low-cost touchless solution for intraoperative access to medical images, laying the groundwork for future clinical evaluations.
Exploring gauge-fixing conditions with gradient-based optimization
Oct 04, 2024Lattice gauge fixing is required to compute gauge-variant quantities, for example those used in RI-MOM renormalization schemes or as objects of comparison for model calculations. Recently, gauge-variant quantities have also been found to be more amenable to signal-to-noise optimization using contour deformations. These applications motivate systematic parameterization and exploration of gauge-fixing schemes. This work introduces a differentiable parameterization of gauge fixing which is broad enough to cover Landau gauge, Coulomb gauge, and maximal tree gauges. The adjoint state method allows gradient-based optimization to select gauge-fixing schemes that minimize an arbitrary target loss function.
Cross-modulated Attention Transformer for RGBT Tracking
Aug 05, 2024



Existing Transformer-based RGBT trackers achieve remarkable performance benefits by leveraging self-attention to extract uni-modal features and cross-attention to enhance multi-modal feature interaction and template-search correlation computation. Nevertheless, the independent search-template correlation calculations ignore the consistency between branches, which can result in ambiguous and inappropriate correlation weights. It not only limits the intra-modal feature representation, but also harms the robustness of cross-attention for multi-modal feature interaction and search-template correlation computation. To address these issues, we propose a novel approach called Cross-modulated Attention Transformer (CAFormer), which performs intra-modality self-correlation, inter-modality feature interaction, and search-template correlation computation in a unified attention model, for RGBT tracking. In particular, we first independently generate correlation maps for each modality and feed them into the designed Correlation Modulated Enhancement module, modulating inaccurate correlation weights by seeking the consensus between modalities. Such kind of design unifies self-attention and cross-attention schemes, which not only alleviates inaccurate attention weight computation in self-attention but also eliminates redundant computation introduced by extra cross-attention scheme. In addition, we propose a collaborative token elimination strategy to further improve tracking inference efficiency and accuracy. Extensive experiments on five public RGBT tracking benchmarks show the outstanding performance of the proposed CAFormer against state-of-the-art methods.
Exploring Part-Informed Visual-Language Learning for Person Re-Identification
Aug 04, 2023



Recently, visual-language learning has shown great potential in enhancing visual-based person re-identification (ReID). Existing visual-language learning-based ReID methods often focus on whole-body scale image-text feature alignment, while neglecting supervisions on fine-grained part features. This choice simplifies the learning process but cannot guarantee within-part feature semantic consistency thus hindering the final performance. Therefore, we propose to enhance fine-grained visual features with part-informed language supervision for ReID tasks. The proposed method, named Part-Informed Visual-language Learning ($\pi$-VL), suggests that (i) a human parsing-guided prompt tuning strategy and (ii) a hierarchical fusion-based visual-language alignment paradigm play essential roles in ensuring within-part feature semantic consistency. Specifically, we combine both identity labels and parsing maps to constitute pixel-level text prompts and fuse multi-stage visual features with a light-weight auxiliary head to perform fine-grained image-text alignment. As a plug-and-play and inference-free solution, our $\pi$-VL achieves substantial improvements over previous state-of-the-arts on four common-used ReID benchmarks, especially reporting 90.3% Rank-1 and 76.5% mAP for the most challenging MSMT17 database without bells and whistles.
Neural-network preconditioners for solving the Dirac equation in lattice gauge theory
Aug 04, 2022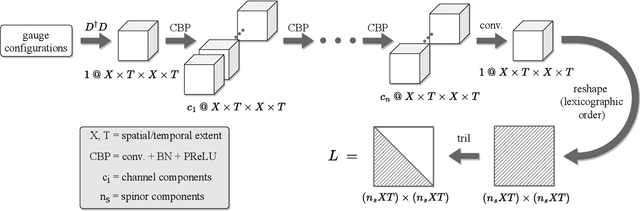
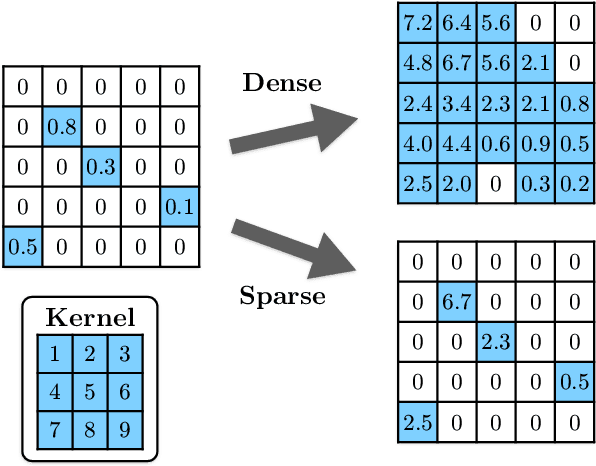
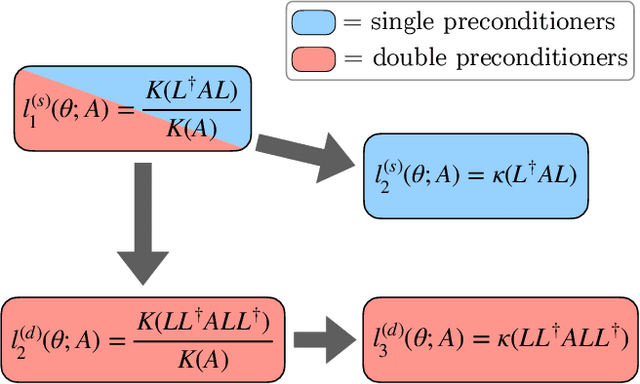
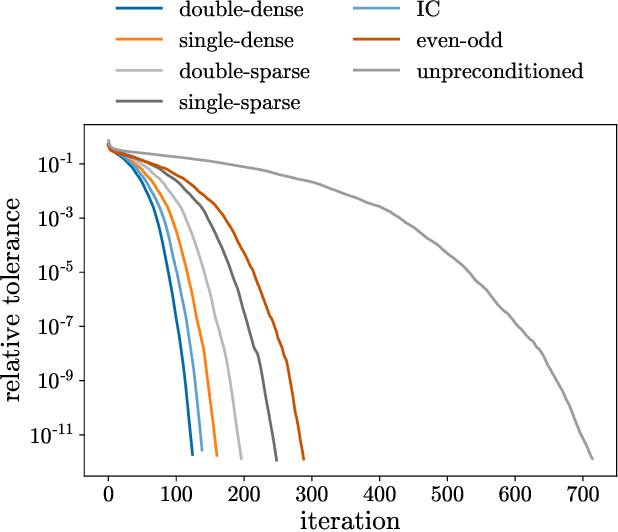
This work develops neural-network--based preconditioners to accelerate solution of the Wilson-Dirac normal equation in lattice quantum field theories. The approach is implemented for the two-flavor lattice Schwinger model near the critical point. In this system, neural-network preconditioners are found to accelerate the convergence of the conjugate gradient solver compared with the solution of unpreconditioned systems or those preconditioned with conventional approaches based on even-odd or incomplete Cholesky decompositions, as measured by reductions in the number of iterations and/or complex operations required for convergence. It is also shown that a preconditioner trained on ensembles with small lattice volumes can be used to construct preconditioners for ensembles with many times larger lattice volumes, with minimal degradation of performance. This volume-transferring technique amortizes the training cost and presents a pathway towards scaling such preconditioners to lattice field theory calculations with larger lattice volumes and in four dimensions.
A Survey on Techniques for Identifying and Resolving Representation Bias in Data
Mar 22, 2022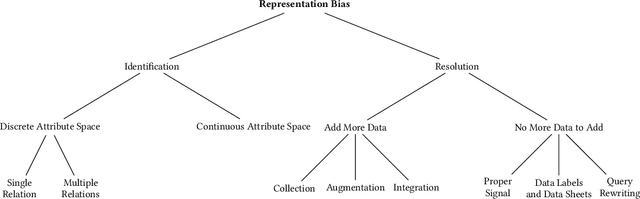
The grand goal of data-driven decision-making is to help humans make decisions, not only easily and at scale but also wisely, accurately, and just. However, data-driven algorithms are only as good as the data they work with, while data sets, especially social data, often miss representing minorities. Representation Bias in data can happen due to various reasons ranging from historical discrimination to selection and sampling biases in the data acquisition and preparation methods. One cannot expect AI-based societal solutions to have equitable outcomes without addressing the representation bias. This paper surveys the existing literature on representation bias in the data. It presents a taxonomy to categorize the studied techniques based on multiple design dimensions and provide a side-by-side comparison of their properties. There is still a long way to fully address representation bias issues in data. The authors hope that this survey motivates researchers to approach these challenges in the future by observing existing work within their respective domains.
Applications of Machine Learning to Lattice Quantum Field Theory
Feb 10, 2022There is great potential to apply machine learning in the area of numerical lattice quantum field theory, but full exploitation of that potential will require new strategies. In this white paper for the Snowmass community planning process, we discuss the unique requirements of machine learning for lattice quantum field theory research and outline what is needed to enable exploration and deployment of this approach in the future.