 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoad Similarity-Based BEV-Satellite Image Matching for UGV Localization
Apr 23, 2025To address the challenge of autonomous UGV localization in GNSS-denied off-road environments,this study proposes a matching-based localization method that leverages BEV perception image and satellite map within a road similarity space to achieve high-precision positioning.We first implement a robust LiDAR-inertial odometry system, followed by the fusion of LiDAR and image data to generate a local BEV perception image of the UGV. This approach mitigates the significant viewpoint discrepancy between ground-view images and satellite map. The BEV image and satellite map are then projected into the road similarity space, where normalized cross correlation (NCC) is computed to assess the matching score.Finally, a particle filter is employed to estimate the probability distribution of the vehicle's pose.By comparing with GNSS ground truth, our localization system demonstrated stability without divergence over a long-distance test of 10 km, achieving an average lateral error of only 0.89 meters and an average planar Euclidean error of 3.41 meters. Furthermore, it maintained accurate and stable global localization even under nighttime conditions, further validating its robustness and adaptability.
Low-Light Image Enhancement by Learning Contrastive Representations in Spatial and Frequency Domains
Mar 23, 2023



Images taken under low-light conditions tend to suffer from poor visibility, which can decrease image quality and even reduce the performance of the downstream tasks. It is hard for a CNN-based method to learn generalized features that can recover normal images from the ones under various unknow low-light conditions. In this paper, we propose to incorporate the contrastive learning into an illumination correction network to learn abstract representations to distinguish various low-light conditions in the representation space, with the purpose of enhancing the generalizability of the network. Considering that light conditions can change the frequency components of the images, the representations are learned and compared in both spatial and frequency domains to make full advantage of the contrastive learning. The proposed method is evaluated on LOL and LOL-V2 datasets, the results show that the proposed method achieves better qualitative and quantitative results compared with other state-of-the-arts.
Explore Contextual Information for 3D Scene Graph Generation
Oct 12, 2022
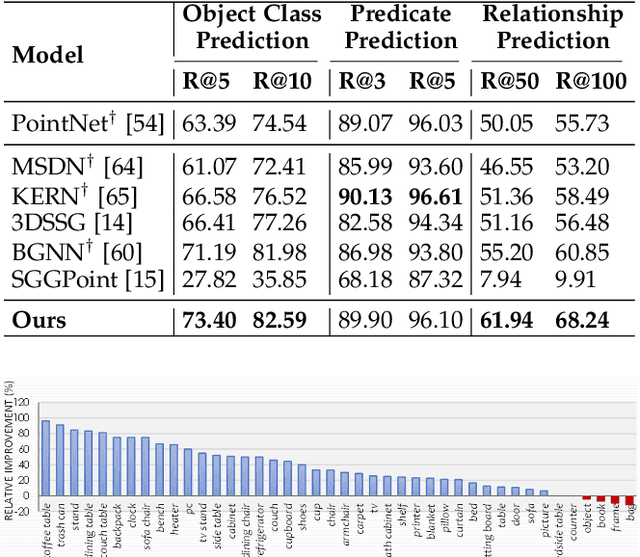
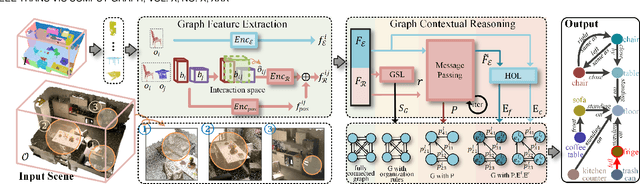
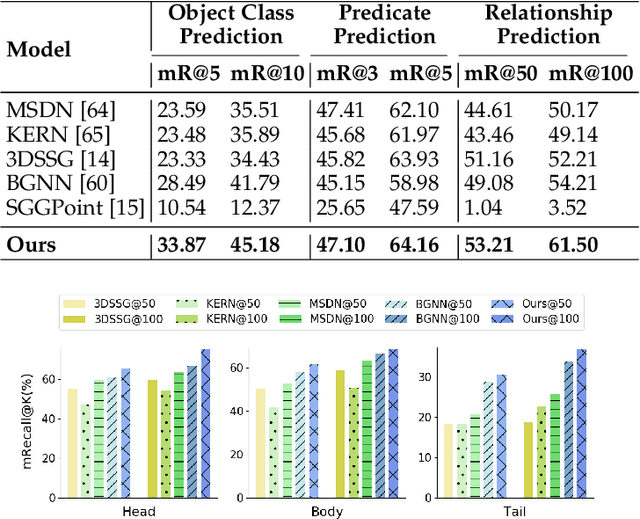
3D scene graph generation (SGG) has been of high interest in computer vision. Although the accuracy of 3D SGG on coarse classification and single relation label has been gradually improved, the performance of existing works is still far from being perfect for fine-grained and multi-label situations. In this paper, we propose a framework fully exploring contextual information for the 3D SGG task, which attempts to satisfy the requirements of fine-grained entity class, multiple relation labels, and high accuracy simultaneously. Our proposed approach is composed of a Graph Feature Extraction module and a Graph Contextual Reasoning module, achieving appropriate information-redundancy feature extraction, structured organization, and hierarchical inferring. Our approach achieves superior or competitive performance over previous methods on the 3DSSG dataset, especially on the relationship prediction sub-task.