 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuEPT: Quantized Elastic Precision Transformers with One-Shot Calibration for Multi-Bit Switching
Feb 13, 2026Elastic precision quantization enables multi-bit deployment via a single optimization pass, fitting diverse quantization scenarios.Yet, the high storage and optimization costs associated with the Transformer architecture, research on elastic quantization remains limited, particularly for large language models.This paper proposes QuEPT, an efficient post-training scheme that reconstructs block-wise multi-bit errors with one-shot calibration on a small data slice. It can dynamically adapt to various predefined bit-widths by cascading different low-rank adapters, and supports real-time switching between uniform quantization and mixed precision quantization without repeated optimization. To enhance accuracy and robustness, we introduce Multi-Bit Token Merging (MB-ToMe) to dynamically fuse token features across different bit-widths, improving robustness during bit-width switching. Additionally, we propose Multi-Bit Cascaded Low-Rank adapters (MB-CLoRA) to strengthen correlations between bit-width groups, further improve the overall performance of QuEPT. Extensive experiments demonstrate that QuEPT achieves comparable or better performance to existing state-of-the-art post-training quantization methods.Our code is available at https://github.com/xuke225/QuEPT
Col-OLHTR: A Novel Framework for Multimodal Online Handwritten Text Recognition
Feb 10, 2025



Online Handwritten Text Recognition (OLHTR) has gained considerable attention for its diverse range of applications. Current approaches usually treat OLHTR as a sequence recognition task, employing either a single trajectory or image encoder, or multi-stream encoders, combined with a CTC or attention-based recognition decoder. However, these approaches face several drawbacks: 1) single encoders typically focus on either local trajectories or visual regions, lacking the ability to dynamically capture relevant global features in challenging cases; 2) multi-stream encoders, while more comprehensive, suffer from complex structures and increased inference costs. To tackle this, we propose a Collaborative learning-based OLHTR framework, called Col-OLHTR, that learns multimodal features during training while maintaining a single-stream inference process. Col-OLHTR consists of a trajectory encoder, a Point-to-Spatial Alignment (P2SA) module, and an attention-based decoder. The P2SA module is designed to learn image-level spatial features through trajectory-encoded features and 2D rotary position embeddings. During training, an additional image-stream encoder-decoder is collaboratively trained to provide supervision for P2SA features. At inference, the extra streams are discarded, and only the P2SA module is used and merged before the decoder, simplifying the process while preserving high performance. Extensive experimental results on several OLHTR benchmarks demonstrate the state-of-the-art (SOTA) performance, proving the effectiveness and robustness of our design.
RFL: Simplifying Chemical Structure Recognition with Ring-Free Language
Dec 10, 2024



The primary objective of Optical Chemical Structure Recognition is to identify chemical structure images into corresponding markup sequences. However, the complex two-dimensional structures of molecules, particularly those with rings and multiple branches, present significant challenges for current end-to-end methods to learn one-dimensional markup directly. To overcome this limitation, we propose a novel Ring-Free Language (RFL), which utilizes a divide-and-conquer strategy to describe chemical structures in a hierarchical form. RFL allows complex molecular structures to be decomposed into multiple parts, ensuring both uniqueness and conciseness while enhancing readability. This approach significantly reduces the learning difficulty for recognition models. Leveraging RFL, we propose a universal Molecular Skeleton Decoder (MSD), which comprises a skeleton generation module that progressively predicts the molecular skeleton and individual rings, along with a branch classification module for predicting branch information. Experimental results demonstrate that the proposed RFL and MSD can be applied to various mainstream methods, achieving superior performance compared to state-of-the-art approaches in both printed and handwritten scenarios. The code is available at https://github.com/JingMog/RFL-MSD.
NAMER: Non-Autoregressive Modeling for Handwritten Mathematical Expression Recognition
Jul 16, 2024



Recently, Handwritten Mathematical Expression Recognition (HMER) has gained considerable attention in pattern recognition for its diverse applications in document understanding. Current methods typically approach HMER as an image-to-sequence generation task within an autoregressive (AR) encoder-decoder framework. However, these approaches suffer from several drawbacks: 1) a lack of overall language context, limiting information utilization beyond the current decoding step; 2) error accumulation during AR decoding; and 3) slow decoding speed. To tackle these problems, this paper makes the first attempt to build a novel bottom-up Non-AutoRegressive Modeling approach for HMER, called NAMER. NAMER comprises a Visual Aware Tokenizer (VAT) and a Parallel Graph Decoder (PGD). Initially, the VAT tokenizes visible symbols and local relations at a coarse level. Subsequently, the PGD refines all tokens and establishes connectivities in parallel, leveraging comprehensive visual and linguistic contexts. Experiments on CROHME 2014/2016/2019 and HME100K datasets demonstrate that NAMER not only outperforms the current state-of-the-art (SOTA) methods on ExpRate by 1.93%/2.35%/1.49%/0.62%, but also achieves significant speedups of 13.7x and 6.7x faster in decoding time and overall FPS, proving the effectiveness and efficiency of NAMER.
1DFormer: Learning 1D Landmark Representations via Transformer for Facial Landmark Tracking
Nov 01, 2023Recently, heatmap regression methods based on 1D landmark representations have shown prominent performance on locating facial landmarks. However, previous methods ignored to make deep explorations on the good potentials of 1D landmark representations for sequential and structural modeling of multiple landmarks to track facial landmarks. To address this limitation, we propose a Transformer architecture, namely 1DFormer, which learns informative 1D landmark representations by capturing the dynamic and the geometric patterns of landmarks via token communications in both temporal and spatial dimensions for facial landmark tracking. For temporal modeling, we propose a recurrent token mixing mechanism, an axis-landmark-positional embedding mechanism, as well as a confidence-enhanced multi-head attention mechanism to adaptively and robustly embed long-term landmark dynamics into their 1D representations; for structure modeling, we design intra-group and inter-group structure modeling mechanisms to encode the component-level as well as global-level facial structure patterns as a refinement for the 1D representations of landmarks through token communications in the spatial dimension via 1D convolutional layers. Experimental results on the 300VW and the TF databases show that 1DFormer successfully models the long-range sequential patterns as well as the inherent facial structures to learn informative 1D representations of landmark sequences, and achieves state-of-the-art performance on facial landmark tracking.
Exploring Part-Informed Visual-Language Learning for Person Re-Identification
Aug 04, 2023



Recently, visual-language learning has shown great potential in enhancing visual-based person re-identification (ReID). Existing visual-language learning-based ReID methods often focus on whole-body scale image-text feature alignment, while neglecting supervisions on fine-grained part features. This choice simplifies the learning process but cannot guarantee within-part feature semantic consistency thus hindering the final performance. Therefore, we propose to enhance fine-grained visual features with part-informed language supervision for ReID tasks. The proposed method, named Part-Informed Visual-language Learning ($\pi$-VL), suggests that (i) a human parsing-guided prompt tuning strategy and (ii) a hierarchical fusion-based visual-language alignment paradigm play essential roles in ensuring within-part feature semantic consistency. Specifically, we combine both identity labels and parsing maps to constitute pixel-level text prompts and fuse multi-stage visual features with a light-weight auxiliary head to perform fine-grained image-text alignment. As a plug-and-play and inference-free solution, our $\pi$-VL achieves substantial improvements over previous state-of-the-arts on four common-used ReID benchmarks, especially reporting 90.3% Rank-1 and 76.5% mAP for the most challenging MSMT17 database without bells and whistles.
Bi-LRFusion: Bi-Directional LiDAR-Radar Fusion for 3D Dynamic Object Detection
Jun 02, 2023



LiDAR and Radar are two complementary sensing approaches in that LiDAR specializes in capturing an object's 3D shape while Radar provides longer detection ranges as well as velocity hints. Though seemingly natural, how to efficiently combine them for improved feature representation is still unclear. The main challenge arises from that Radar data are extremely sparse and lack height information. Therefore, directly integrating Radar features into LiDAR-centric detection networks is not optimal. In this work, we introduce a bi-directional LiDAR-Radar fusion framework, termed Bi-LRFusion, to tackle the challenges and improve 3D detection for dynamic objects. Technically, Bi-LRFusion involves two steps: first, it enriches Radar's local features by learning important details from the LiDAR branch to alleviate the problems caused by the absence of height information and extreme sparsity; second, it combines LiDAR features with the enhanced Radar features in a unified bird's-eye-view representation. We conduct extensive experiments on nuScenes and ORR datasets, and show that our Bi-LRFusion achieves state-of-the-art performance for detecting dynamic objects. Notably, Radar data in these two datasets have different formats, which demonstrates the generalizability of our method. Codes are available at https://github.com/JessieW0806/BiLRFusion.
Vision-Language Adaptive Mutual Decoder for OOV-STR
Sep 02, 2022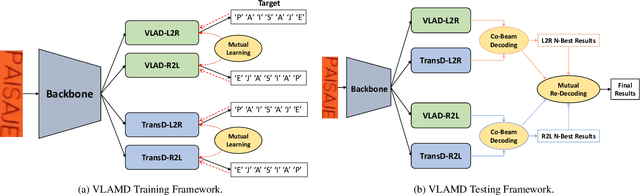
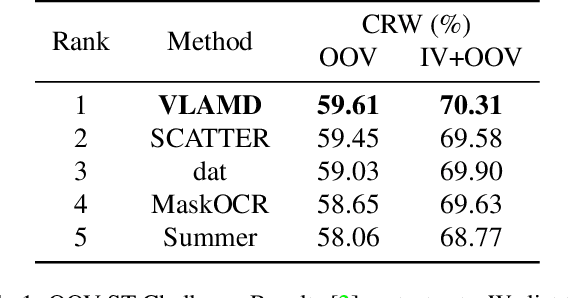
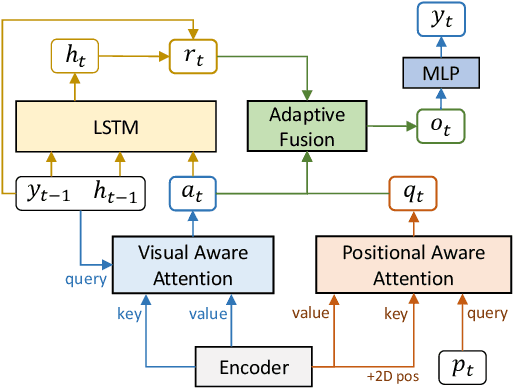

Recent works have shown huge success of deep learning models for common in vocabulary (IV) scene text recognition. However, in real-world scenarios, out-of-vocabulary (OOV) words are of great importance and SOTA recognition models usually perform poorly on OOV settings. Inspired by the intuition that the learned language prior have limited OOV preformence, we design a framework named Vision Language Adaptive Mutual Decoder (VLAMD) to tackle OOV problems partly. VLAMD consists of three main conponents. Firstly, we build an attention based LSTM decoder with two adaptively merged visual-only modules, yields a vision-language balanced main branch. Secondly, we add an auxiliary query based autoregressive transformer decoding head for common visual and language prior representation learning. Finally, we couple these two designs with bidirectional training for more diverse language modeling, and do mutual sequential decoding to get robuster results. Our approach achieved 70.31\% and 59.61\% word accuracy on IV+OOV and OOV settings respectively on Cropped Word Recognition Task of OOV-ST Challenge at ECCV 2022 TiE Workshop, where we got 1st place on both settings.