 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAll Circuits Lead to Rome: Rethinking Functional Anisotropy in Circuit and Sheaf Discovery for LLMs
May 12, 2026In this paper, we present empirical and theoretical evidence against a central but largely implicit assumption in circuit and sheaf discovery (CSD), which we term the Functional Anisotropy Hypothesis: the idea that functions in large language models (LLMs) are localised to a unique or near-unique internal mechanism. We show that a single LLM task can instead be supported by multiple, structurally distinct circuits or sheaves that are simultaneously faithful, sparse, and complete. To systematically uncover such competing mechanisms, we introduce Overlap-Aware Sheaf Repulsion, a method that augments the CSD objective with an explicit penalty on structural overlap across multiple discovery runs, enabling the discovery of circuits or sheaves with strong task performance but minimal shared structure across a plethora of common CSD benchmarks. We find that this phenomenon becomes increasingly pronounced as the number of discovered sheaves grows and persists robustly across major CSD methods. We further identify an ultra-sparse three-edge sheaf and show that none of its edges is individually indispensable, undermining even weakened notions of canonical or essential components. To explain these findings, we propose a Distributive Dense Circuit Hypothesis and provide a theoretical analysis demonstrating that non-unique, low-overlap circuit explanations arise naturally from high-dimensional superposition under mild assumptions. Together, our results suggest that mechanistic explanations in LLMs are inherently non-canonical and call for a rethinking of how CSD results should be interpreted and evaluated.
Farther the Shift, Sparser the Representation: Analyzing OOD Mechanisms in LLMs
Mar 03, 2026In this work, we investigate how Large Language Models (LLMs) adapt their internal representations when encountering inputs of increasing difficulty, quantified as the degree of out-of-distribution (OOD) shift. We reveal a consistent and quantifiable phenomenon: as task difficulty increases, whether through harder reasoning questions, longer contexts, or adding answer choices, the last hidden states of LLMs become substantially sparser. In short, \textbf{\textit{the farther the shift, the sparser the representations}}. This sparsity--difficulty relation is observable across diverse models and domains, suggesting that language models respond to unfamiliar or complex inputs by concentrating computation into specialized subspaces in the last hidden state. Through a series of controlled analyses with a learning dynamic explanation, we demonstrate that this sparsity is not incidental but an adaptive mechanism for stabilizing reasoning under OOD. Leveraging this insight, we design \textit{Sparsity-Guided Curriculum In-Context Learning (SG-ICL)}, a strategy that explicitly uses representation sparsity to schedule few-shot demonstrations, leading to considerable performance enhancements. Our study provides new mechanistic insights into how LLMs internalize OOD challenges. The source code is available at the URL: https://github.com/MingyuJ666/sparsityLLM.
Local Linear Attention: An Optimal Interpolation of Linear and Softmax Attention For Test-Time Regression
Oct 01, 2025Transformer architectures have achieved remarkable success in various domains. While efficient alternatives to Softmax Attention have been widely studied, the search for more expressive mechanisms grounded in theoretical insight-even at greater computational cost-has been relatively underexplored. In this work, we bridge this gap by proposing Local Linear Attention (LLA), a novel attention mechanism derived from nonparametric statistics through the lens of test-time regression. First, we show that LLA offers theoretical advantages over Linear and Softmax Attention for associative memory via a bias-variance trade-off analysis. Next, we address its computational challenges and propose two memory-efficient primitives to tackle the $\Theta(n^2 d)$ and $\Theta(n d^2)$ complexity. We then introduce FlashLLA, a hardware-efficient, blockwise algorithm that enables scalable and parallel computation on modern accelerators. In addition, we implement and profile a customized inference kernel that significantly reduces memory overheads. Finally, we empirically validate the advantages and limitations of LLA on test-time regression, in-context regression, associative recall and state tracking tasks. Experiment results demonstrate that LLA effectively adapts to non-stationarity, outperforming strong baselines in test-time training and in-context learning, and exhibiting promising evidence for its scalability and applicability in large-scale models. Code is available at https://github.com/Yifei-Zuo/Flash-LLA.
BRiTE: Bootstrapping Reinforced Thinking Process to Enhance Language Model Reasoning
Jan 31, 2025



Large Language Models (LLMs) have demonstrated remarkable capabilities in complex reasoning tasks, yet generating reliable reasoning processes remains a significant challenge. We present a unified probabilistic framework that formalizes LLM reasoning through a novel graphical model incorporating latent thinking processes and evaluation signals. Within this framework, we introduce the Bootstrapping Reinforced Thinking Process (BRiTE) algorithm, which works in two steps. First, it generates high-quality rationales by approximating the optimal thinking process through reinforcement learning, using a novel reward shaping mechanism. Second, it enhances the base LLM by maximizing the joint probability of rationale generation with respect to the model's parameters. Theoretically, we demonstrate BRiTE's convergence at a rate of $1/T$ with $T$ representing the number of iterations. Empirical evaluations on math and coding benchmarks demonstrate that our approach consistently improves performance across different base models without requiring human-annotated thinking processes. In addition, BRiTE demonstrates superior performance compared to existing algorithms that bootstrap thinking processes use alternative methods such as rejection sampling, and can even match or exceed the results achieved through supervised fine-tuning with human-annotated data.
Are Transformers Able to Reason by Connecting Separated Knowledge in Training Data?
Jan 27, 2025Humans exhibit remarkable compositional reasoning by integrating knowledge from various sources. For example, if someone learns ( B = f(A) ) from one source and ( C = g(B) ) from another, they can deduce ( C=g(B)=g(f(A)) ) even without encountering ( ABC ) together, showcasing the generalization ability of human intelligence. In this paper, we introduce a synthetic learning task, "FTCT" (Fragmented at Training, Chained at Testing), to validate the potential of Transformers in replicating this skill and interpret its inner mechanism. In the training phase, data consist of separated knowledge fragments from an overall causal graph. During testing, Transformers must infer complete causal graph traces by integrating these fragments. Our findings demonstrate that few-shot Chain-of-Thought prompting enables Transformers to perform compositional reasoning on FTCT by revealing correct combinations of fragments, even if such combinations were absent in the training data. Furthermore, the emergence of compositional reasoning ability is strongly correlated with the model complexity and training-testing data similarity. We propose, both theoretically and empirically, that Transformers learn an underlying generalizable program from training, enabling effective compositional reasoning during testing.
A Context-Integrated Transformer-Based Neural Network for Auction Design
Jan 29, 2022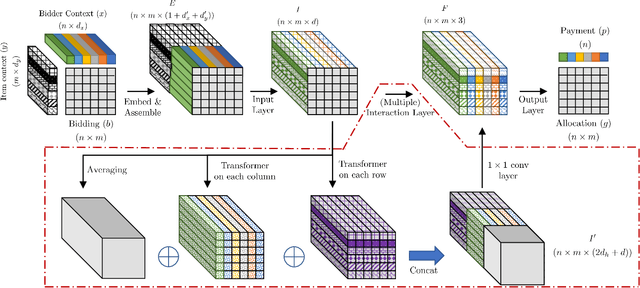
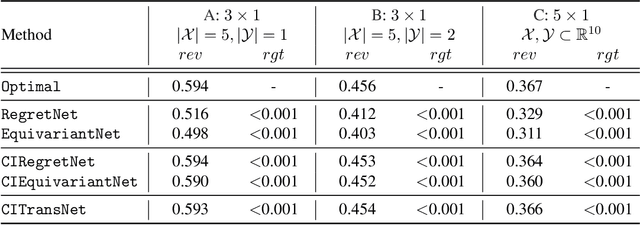
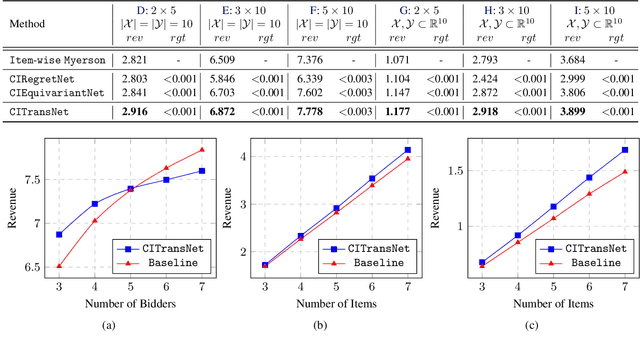
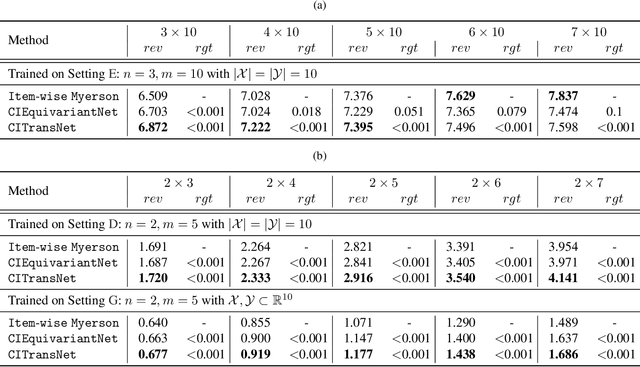
One of the central problems in auction design is developing an incentive-compatible mechanism that maximizes the auctioneer's expected revenue. While theoretical approaches have encountered bottlenecks in multi-item auctions, recently, there has been much progress on finding the optimal mechanism through deep learning. However, these works either focus on a fixed set of bidders and items, or restrict the auction to be symmetric. In this work, we overcome such limitations by factoring \emph{public} contextual information of bidders and items into the auction learning framework. We propose $\mathtt{CITransNet}$, a context-integrated transformer-based neural network for optimal auction design, which maintains permutation-equivariance over bids and contexts while being able to find asymmetric solutions. We show by extensive experiments that $\mathtt{CITransNet}$ can recover the known optimal solutions in single-item settings, outperform strong baselines in multi-item auctions, and generalize well to cases other than those in training.