 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRLAD: Training LLMs to Discover Abstractions for Solving Reasoning Problems
Oct 02, 2025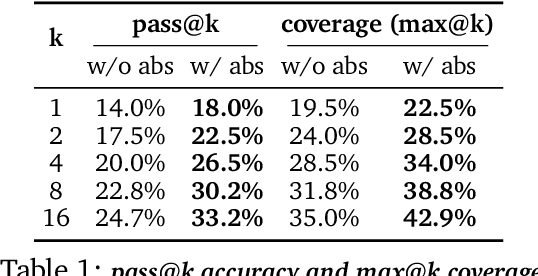
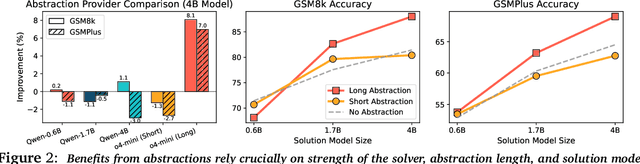
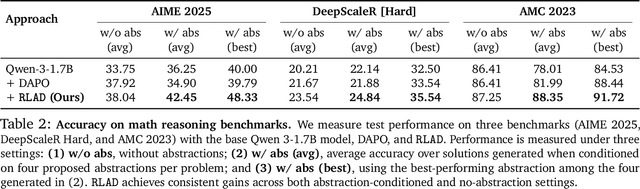
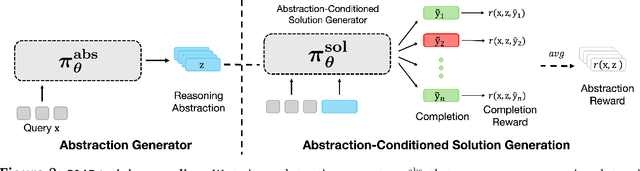
Reasoning requires going beyond pattern matching or memorization of solutions to identify and implement "algorithmic procedures" that can be used to deduce answers to hard problems. Doing so requires realizing the most relevant primitives, intermediate results, or shared procedures, and building upon them. While RL post-training on long chains of thought ultimately aims to uncover this kind of algorithmic behavior, most reasoning traces learned by large models fail to consistently capture or reuse procedures, instead drifting into verbose and degenerate exploration. To address more effective reasoning, we introduce reasoning abstractions: concise natural language descriptions of procedural and factual knowledge that guide the model toward learning successful reasoning. We train models to be capable of proposing multiple abstractions given a problem, followed by RL that incentivizes building a solution while using the information provided by these abstractions. This results in a two-player RL training paradigm, abbreviated as RLAD, that jointly trains an abstraction generator and a solution generator. This setup effectively enables structured exploration, decouples learning signals of abstraction proposal and solution generation, and improves generalization to harder problems. We also show that allocating more test-time compute to generating abstractions is more beneficial for performance than generating more solutions at large test budgets, illustrating the role of abstractions in guiding meaningful exploration.
RaC: Robot Learning for Long-Horizon Tasks by Scaling Recovery and Correction
Sep 09, 2025



Modern paradigms for robot imitation train expressive policy architectures on large amounts of human demonstration data. Yet performance on contact-rich, deformable-object, and long-horizon tasks plateau far below perfect execution, even with thousands of expert demonstrations. This is due to the inefficiency of existing ``expert'' data collection procedures based on human teleoperation. To address this issue, we introduce RaC, a new phase of training on human-in-the-loop rollouts after imitation learning pre-training. In RaC, we fine-tune a robotic policy on human intervention trajectories that illustrate recovery and correction behaviors. Specifically, during a policy rollout, human operators intervene when failure appears imminent, first rewinding the robot back to a familiar, in-distribution state and then providing a corrective segment that completes the current sub-task. Training on this data composition expands the robotic skill repertoire to include retry and adaptation behaviors, which we show are crucial for boosting both efficiency and robustness on long-horizon tasks. Across three real-world bimanual control tasks: shirt hanging, airtight container lid sealing, takeout box packing, and a simulated assembly task, RaC outperforms the prior state-of-the-art using 10$\times$ less data collection time and samples. We also show that RaC enables test-time scaling: the performance of the trained RaC policy scales linearly in the number of recovery maneuvers it exhibits. Videos of the learned policy are available at https://rac-scaling-robot.github.io/.
Compute-Optimal Scaling for Value-Based Deep RL
Aug 20, 2025As models grow larger and training them becomes expensive, it becomes increasingly important to scale training recipes not just to larger models and more data, but to do so in a compute-optimal manner that extracts maximal performance per unit of compute. While such scaling has been well studied for language modeling, reinforcement learning (RL) has received less attention in this regard. In this paper, we investigate compute scaling for online, value-based deep RL. These methods present two primary axes for compute allocation: model capacity and the update-to-data (UTD) ratio. Given a fixed compute budget, we ask: how should resources be partitioned across these axes to maximize sample efficiency? Our analysis reveals a nuanced interplay between model size, batch size, and UTD. In particular, we identify a phenomenon we call TD-overfitting: increasing the batch quickly harms Q-function accuracy for small models, but this effect is absent in large models, enabling effective use of large batch size at scale. We provide a mental model for understanding this phenomenon and build guidelines for choosing batch size and UTD to optimize compute usage. Our findings provide a grounded starting point for compute-optimal scaling in deep RL, mirroring studies in supervised learning but adapted to TD learning.
Reasoning as an Adaptive Defense for Safety
Jul 01, 2025



Reasoning methods that adaptively allocate test-time compute have advanced LLM performance on easy to verify domains such as math and code. In this work, we study how to utilize this approach to train models that exhibit a degree of robustness to safety vulnerabilities, and show that doing so can provide benefits. We build a recipe called $\textit{TARS}$ (Training Adaptive Reasoners for Safety), a reinforcement learning (RL) approach that trains models to reason about safety using chain-of-thought traces and a reward signal that balances safety with task completion. To build TARS, we identify three critical design choices: (1) a "lightweight" warmstart SFT stage, (2) a mix of harmful, harmless, and ambiguous prompts to prevent shortcut behaviors such as too many refusals, and (3) a reward function to prevent degeneration of reasoning capabilities during training. Models trained with TARS exhibit adaptive behaviors by spending more compute on ambiguous queries, leading to better safety-refusal trade-offs. They also internally learn to better distinguish between safe and unsafe prompts and attain greater robustness to both white-box (e.g., GCG) and black-box attacks (e.g., PAIR). Overall, our work provides an effective, open recipe for training LLMs against jailbreaks and harmful requests by reasoning per prompt.
e3: Learning to Explore Enables Extrapolation of Test-Time Compute for LLMs
Jun 10, 2025Test-time scaling offers a promising path to improve LLM reasoning by utilizing more compute at inference time; however, the true promise of this paradigm lies in extrapolation (i.e., improvement in performance on hard problems as LLMs keep "thinking" for longer, beyond the maximum token budget they were trained on). Surprisingly, we find that most existing reasoning models do not extrapolate well. We show that one way to enable extrapolation is by training the LLM to perform in-context exploration: training the LLM to effectively spend its test time budget by chaining operations (such as generation, verification, refinement, etc.), or testing multiple hypotheses before it commits to an answer. To enable in-context exploration, we identify three key ingredients as part of our recipe e3: (1) chaining skills that the base LLM has asymmetric competence in, e.g., chaining verification (easy) with generation (hard), as a way to implement in-context search; (2) leveraging "negative" gradients from incorrect traces to amplify exploration during RL, resulting in longer search traces that chains additional asymmetries; and (3) coupling task difficulty with training token budget during training via a specifically-designed curriculum to structure in-context exploration. Our recipe e3 produces the best known 1.7B model according to AIME'25 and HMMT'25 scores, and extrapolates to 2x the training token budget. Our e3-1.7B model not only attains high pass@1 scores, but also improves pass@k over the base model.
Thinking vs. Doing: Agents that Reason by Scaling Test-Time Interaction
Jun 09, 2025



The current paradigm of test-time scaling relies on generating long reasoning traces ("thinking" more) before producing a response. In agent problems that require interaction, this can be done by generating thinking traces before acting in the world. However, this process does not allow agents to acquire new information from the environment or adapt their behavior over time. In this work, we propose to scale test-time interaction, an untapped dimension of test-time scaling that increases the agent's interaction horizon to enable running rich behaviors such as exploration, backtracking, and dynamic re-planning within a single rollout. To demonstrate the promise of this scaling dimension, we study the domain of web agents. We first show that even prompting-based interaction scaling without any training can improve task success on web benchmarks non-trivially. Building on this, we introduce TTI (Test-Time Interaction), a curriculum-based online reinforcement learning (RL) approach that trains agents by adaptively adjusting their rollout lengths. Using a Gemma 3 12B model, TTI produces state-of-the-art open-source, open-data web agents on WebVoyager and WebArena benchmarks. We further show that TTI enables agents to balance exploration and exploitation adaptively. Our results establish interaction scaling as a powerful, complementary axis to scaling per-step compute, offering new avenues for training adaptive agents.
Horizon Reduction Makes RL Scalable
Jun 08, 2025



In this work, we study the scalability of offline reinforcement learning (RL) algorithms. In principle, a truly scalable offline RL algorithm should be able to solve any given problem, regardless of its complexity, given sufficient data, compute, and model capacity. We investigate if and how current offline RL algorithms match up to this promise on diverse, challenging, previously unsolved tasks, using datasets up to 1000x larger than typical offline RL datasets. We observe that despite scaling up data, many existing offline RL algorithms exhibit poor scaling behavior, saturating well below the maximum performance. We hypothesize that the horizon is the main cause behind the poor scaling of offline RL. We empirically verify this hypothesis through several analysis experiments, showing that long horizons indeed present a fundamental barrier to scaling up offline RL. We then show that various horizon reduction techniques substantially enhance scalability on challenging tasks. Based on our insights, we also introduce a minimal yet scalable method named SHARSA that effectively reduces the horizon. SHARSA achieves the best asymptotic performance and scaling behavior among our evaluation methods, showing that explicitly reducing the horizon unlocks the scalability of offline RL. Code: https://github.com/seohongpark/horizon-reduction
Bigger, Regularized, Categorical: High-Capacity Value Functions are Efficient Multi-Task Learners
May 29, 2025Recent advances in language modeling and vision stem from training large models on diverse, multi-task data. This paradigm has had limited impact in value-based reinforcement learning (RL), where improvements are often driven by small models trained in a single-task context. This is because in multi-task RL sparse rewards and gradient conflicts make optimization of temporal difference brittle. Practical workflows for generalist policies therefore avoid online training, instead cloning expert trajectories or distilling collections of single-task policies into one agent. In this work, we show that the use of high-capacity value models trained via cross-entropy and conditioned on learnable task embeddings addresses the problem of task interference in online RL, allowing for robust and scalable multi-task training. We test our approach on 7 multi-task benchmarks with over 280 unique tasks, spanning high degree-of-freedom humanoid control and discrete vision-based RL. We find that, despite its simplicity, the proposed approach leads to state-of-the-art single and multi-task performance, as well as sample-efficient transfer to new tasks.
Grounded Reinforcement Learning for Visual Reasoning
May 29, 2025



While reinforcement learning (RL) over chains of thought has significantly advanced language models in tasks such as mathematics and coding, visual reasoning introduces added complexity by requiring models to direct visual attention, interpret perceptual inputs, and ground abstract reasoning in spatial evidence. We introduce ViGoRL (Visually Grounded Reinforcement Learning), a vision-language model trained with RL to explicitly anchor each reasoning step to specific visual coordinates. Inspired by human visual decision-making, ViGoRL learns to produce spatially grounded reasoning traces, guiding visual attention to task-relevant regions at each step. When fine-grained exploration is required, our novel multi-turn RL framework enables the model to dynamically zoom into predicted coordinates as reasoning unfolds. Across a diverse set of visual reasoning benchmarks--including SAT-2 and BLINK for spatial reasoning, V*bench for visual search, and ScreenSpot and VisualWebArena for web-based grounding--ViGoRL consistently outperforms both supervised fine-tuning and conventional RL baselines that lack explicit grounding mechanisms. Incorporating multi-turn RL with zoomed-in visual feedback significantly improves ViGoRL's performance on localizing small GUI elements and visual search, achieving 86.4% on V*Bench. Additionally, we find that grounding amplifies other visual behaviors such as region exploration, grounded subgoal setting, and visual verification. Finally, human evaluations show that the model's visual references are not only spatially accurate but also helpful for understanding model reasoning steps. Our results show that visually grounded RL is a strong paradigm for imbuing models with general-purpose visual reasoning.
Optimizing Test-Time Compute via Meta Reinforcement Fine-Tuning
Mar 10, 2025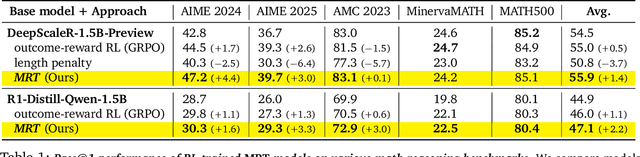
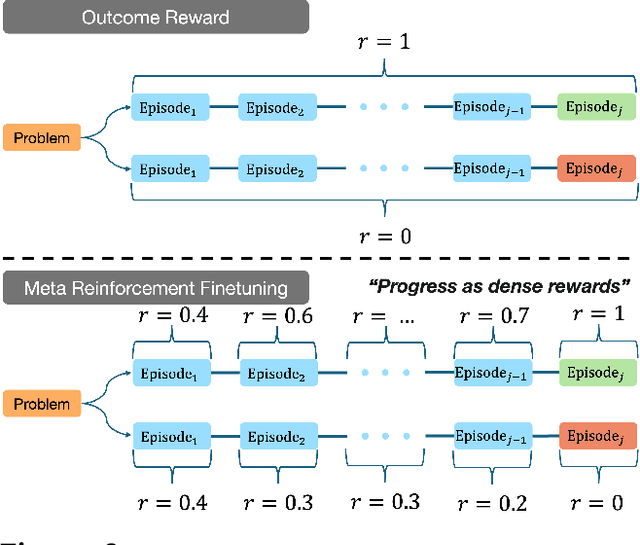
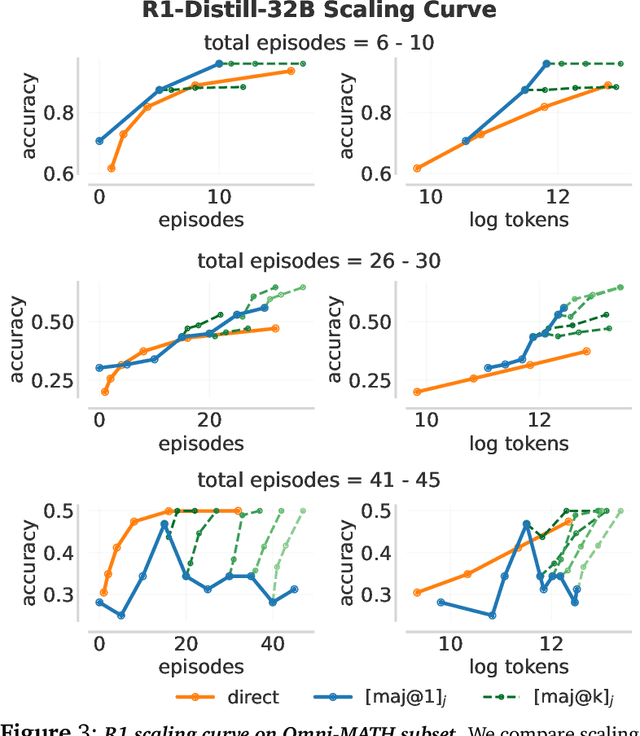
Training models to effectively use test-time compute is crucial for improving the reasoning performance of LLMs. Current methods mostly do so via fine-tuning on search traces or running RL with 0/1 outcome reward, but do these approaches efficiently utilize test-time compute? Would these approaches continue to scale as the budget improves? In this paper, we try to answer these questions. We formalize the problem of optimizing test-time compute as a meta-reinforcement learning (RL) problem, which provides a principled perspective on spending test-time compute. This perspective enables us to view the long output stream from the LLM as consisting of several episodes run at test time and leads us to use a notion of cumulative regret over output tokens as a way to measure the efficacy of test-time compute. Akin to how RL algorithms can best tradeoff exploration and exploitation over training, minimizing cumulative regret would also provide the best balance between exploration and exploitation in the token stream. While we show that state-of-the-art models do not minimize regret, one can do so by maximizing a dense reward bonus in conjunction with the outcome 0/1 reward RL. This bonus is the ''progress'' made by each subsequent block in the output stream, quantified by the change in the likelihood of eventual success. Using these insights, we develop Meta Reinforcement Fine-Tuning, or MRT, a new class of fine-tuning methods for optimizing test-time compute. MRT leads to a 2-3x relative gain in performance and roughly a 1.5x gain in token efficiency for math reasoning compared to outcome-reward RL.