 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Retrieval Heads Improve Attention-Based Re-Ranking
Oct 02, 2025The strong zero-shot and long-context capabilities of recent Large Language Models (LLMs) have paved the way for highly effective re-ranking systems. Attention-based re-rankers leverage attention weights from transformer heads to produce relevance scores, but not all heads are created equally: many contribute noise and redundancy, thus limiting performance. To address this, we introduce CoRe heads, a small set of retrieval heads identified via a contrastive scoring metric that explicitly rewards high attention heads that correlate with relevant documents, while downplaying nodes with higher attention that correlate with irrelevant documents. This relative ranking criterion isolates the most discriminative heads for re-ranking and yields a state-of-the-art list-wise re-ranker. Extensive experiments with three LLMs show that aggregated signals from CoRe heads, constituting less than 1% of all heads, substantially improve re-ranking accuracy over strong baselines. We further find that CoRe heads are concentrated in middle layers, and pruning the computation of final 50% of model layers preserves accuracy while significantly reducing inference time and memory usage.
Assessing Historical Structural Oppression Worldwide via Rule-Guided Prompting of Large Language Models
Sep 18, 2025



Traditional efforts to measure historical structural oppression struggle with cross-national validity due to the unique, locally specified histories of exclusion, colonization, and social status in each country, and often have relied on structured indices that privilege material resources while overlooking lived, identity-based exclusion. We introduce a novel framework for oppression measurement that leverages Large Language Models (LLMs) to generate context-sensitive scores of lived historical disadvantage across diverse geopolitical settings. Using unstructured self-identified ethnicity utterances from a multilingual COVID-19 global study, we design rule-guided prompting strategies that encourage models to produce interpretable, theoretically grounded estimations of oppression. We systematically evaluate these strategies across multiple state-of-the-art LLMs. Our results demonstrate that LLMs, when guided by explicit rules, can capture nuanced forms of identity-based historical oppression within nations. This approach provides a complementary measurement tool that highlights dimensions of systemic exclusion, offering a scalable, cross-cultural lens for understanding how oppression manifests in data-driven research and public health contexts. To support reproducible evaluation, we release an open-sourced benchmark dataset for assessing LLMs on oppression measurement (https://github.com/chattergpt/llm-oppression-benchmark).
PBM-VFL: Vertical Federated Learning with Feature and Sample Privacy
Jan 27, 2025We present Poisson Binomial Mechanism Vertical Federated Learning (PBM-VFL), a communication-efficient Vertical Federated Learning algorithm with Differential Privacy guarantees. PBM-VFL combines Secure Multi-Party Computation with the recently introduced Poisson Binomial Mechanism to protect parties' private datasets during model training. We define the novel concept of feature privacy and analyze end-to-end feature and sample privacy of our algorithm. We compare sample privacy loss in VFL with privacy loss in HFL. We also provide the first theoretical characterization of the relationship between privacy budget, convergence error, and communication cost in differentially-private VFL. Finally, we empirically show that our model performs well with high levels of privacy.
Privacy-Preserving Personalized Federated Prompt Learning for Multimodal Large Language Models
Jan 23, 2025



Multimodal Large Language Models (LLMs) are pivotal in revolutionizing customer support and operations by integrating multiple modalities such as text, images, and audio. Federated Prompt Learning (FPL) is a recently proposed approach that combines pre-trained multimodal LLMs such as vision-language models with federated learning to create personalized, privacy-preserving AI systems. However, balancing the competing goals of personalization, generalization, and privacy remains a significant challenge. Over-personalization can lead to overfitting, reducing generalizability, while stringent privacy measures, such as differential privacy, can hinder both personalization and generalization. In this paper, we propose a Differentially Private Federated Prompt Learning (DP-FPL) approach to tackle this challenge by leveraging a low-rank adaptation scheme to capture generalization while maintaining a residual term that preserves expressiveness for personalization. To ensure privacy, we introduce a novel method where we apply local differential privacy to the two low-rank components of the local prompt, and global differential privacy to the global prompt. Our approach mitigates the impact of privacy noise on the model performance while balancing the tradeoff between personalization and generalization. Extensive experiments demonstrate the effectiveness of our approach over other benchmarks.
A Differentially Private Blockchain-Based Approach for Vertical Federated Learning
Jul 09, 2024



We present the Differentially Private Blockchain-Based Vertical Federal Learning (DP-BBVFL) algorithm that provides verifiability and privacy guarantees for decentralized applications. DP-BBVFL uses a smart contract to aggregate the feature representations, i.e., the embeddings, from clients transparently. We apply local differential privacy to provide privacy for embeddings stored on a blockchain, hence protecting the original data. We provide the first prototype application of differential privacy with blockchain for vertical federated learning. Our experiments with medical data show that DP-BBVFL achieves high accuracy with a tradeoff in training time due to on-chain aggregation. This innovative fusion of differential privacy and blockchain technology in DP-BBVFL could herald a new era of collaborative and trustworthy machine learning applications across several decentralized application domains.
Representation Learning for Sequential Volumetric Design Tasks
Sep 05, 2023



Volumetric design, also called massing design, is the first and critical step in professional building design which is sequential in nature. As the volumetric design process is complex, the underlying sequential design process encodes valuable information for designers. Many efforts have been made to automatically generate reasonable volumetric designs, but the quality of the generated design solutions varies, and evaluating a design solution requires either a prohibitively comprehensive set of metrics or expensive human expertise. While previous approaches focused on learning only the final design instead of sequential design tasks, we propose to encode the design knowledge from a collection of expert or high-performing design sequences and extract useful representations using transformer-based models. Later we propose to utilize the learned representations for crucial downstream applications such as design preference evaluation and procedural design generation. We develop the preference model by estimating the density of the learned representations whereas we train an autoregressive transformer model for sequential design generation. We demonstrate our ideas by leveraging a novel dataset of thousands of sequential volumetric designs. Our preference model can compare two arbitrarily given design sequences and is almost 90% accurate in evaluation against random design sequences. Our autoregressive model is also capable of autocompleting a volumetric design sequence from a partial design sequence.
Generalizable Pose Estimation Using Implicit Scene Representations
May 26, 2023



6-DoF pose estimation is an essential component of robotic manipulation pipelines. However, it usually suffers from a lack of generalization to new instances and object types. Most widely used methods learn to infer the object pose in a discriminative setup where the model filters useful information to infer the exact pose of the object. While such methods offer accurate poses, the model does not store enough information to generalize to new objects. In this work, we address the generalization capability of pose estimation using models that contain enough information about the object to render it in different poses. We follow the line of work that inverts neural renderers to infer the pose. We propose i-$\sigma$SRN to maximize the information flowing from the input pose to the rendered scene and invert them to infer the pose given an input image. Specifically, we extend Scene Representation Networks (SRNs) by incorporating a separate network for density estimation and introduce a new way of obtaining a weighted scene representation. We investigate several ways of initial pose estimates and losses for the neural renderer. Our final evaluation shows a significant improvement in inference performance and speed compared to existing approaches.
MaskTune: Mitigating Spurious Correlations by Forcing to Explore
Oct 08, 2022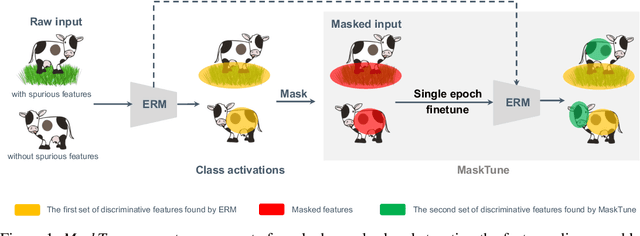
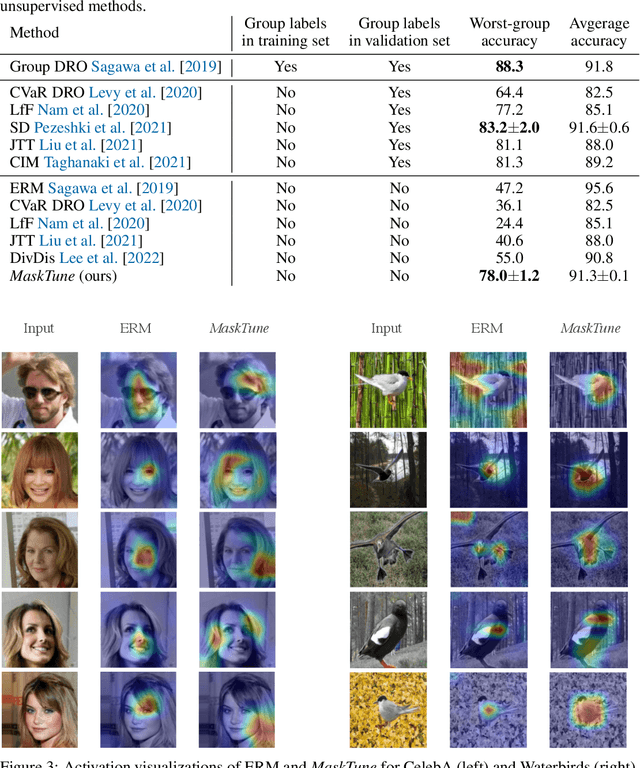
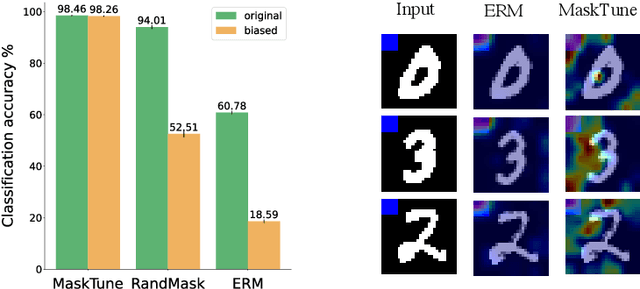

A fundamental challenge of over-parameterized deep learning models is learning meaningful data representations that yield good performance on a downstream task without over-fitting spurious input features. This work proposes MaskTune, a masking strategy that prevents over-reliance on spurious (or a limited number of) features. MaskTune forces the trained model to explore new features during a single epoch finetuning by masking previously discovered features. MaskTune, unlike earlier approaches for mitigating shortcut learning, does not require any supervision, such as annotating spurious features or labels for subgroup samples in a dataset. Our empirical results on biased MNIST, CelebA, Waterbirds, and ImagenNet-9L datasets show that MaskTune is effective on tasks that often suffer from the existence of spurious correlations. Finally, we show that MaskTune outperforms or achieves similar performance to the competing methods when applied to the selective classification (classification with rejection option) task. Code for MaskTune is available at https://github.com/aliasgharkhani/Masktune.
SimCURL: Simple Contrastive User Representation Learning from Command Sequences
Jul 29, 2022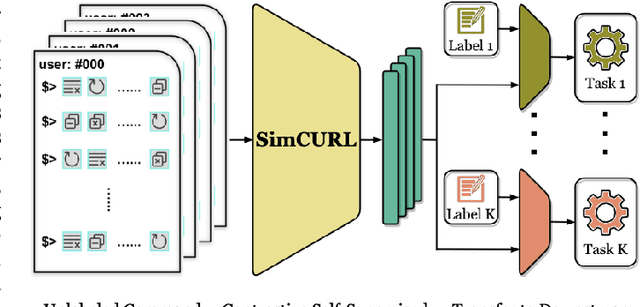

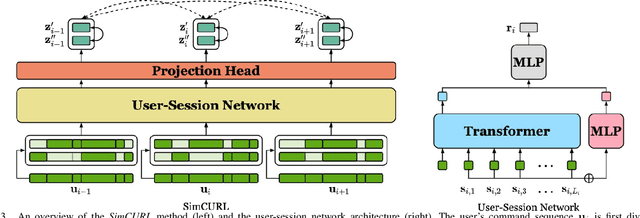
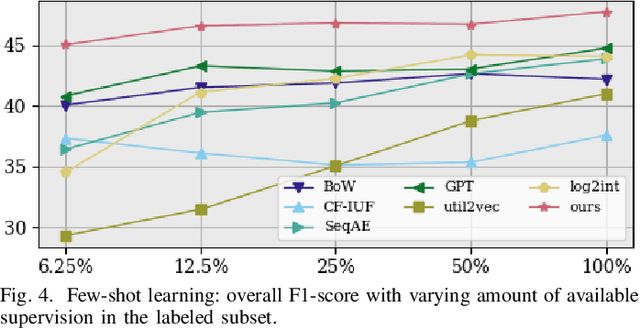
User modeling is crucial to understanding user behavior and essential for improving user experience and personalized recommendations. When users interact with software, vast amounts of command sequences are generated through logging and analytics systems. These command sequences contain clues to the users' goals and intents. However, these data modalities are highly unstructured and unlabeled, making it difficult for standard predictive systems to learn from. We propose SimCURL, a simple yet effective contrastive self-supervised deep learning framework that learns user representation from unlabeled command sequences. Our method introduces a user-session network architecture, as well as session dropout as a novel way of data augmentation. We train and evaluate our method on a real-world command sequence dataset of more than half a billion commands. Our method shows significant improvement over existing methods when the learned representation is transferred to downstream tasks such as experience and expertise classification.
Counterbalancing Teacher: Regularizing Batch Normalized Models for Robustness
Jul 04, 2022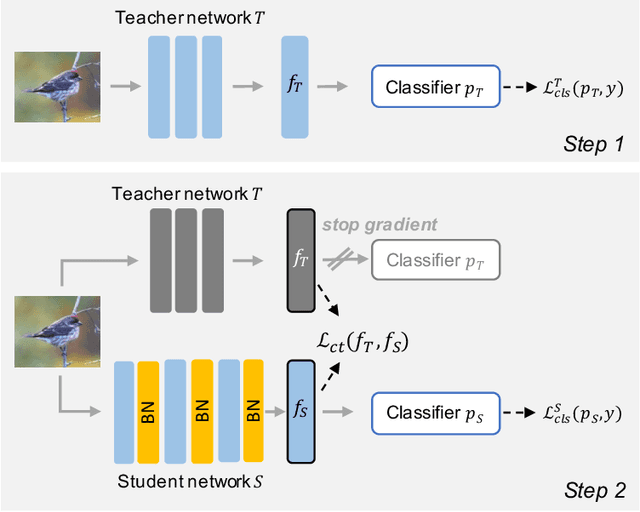
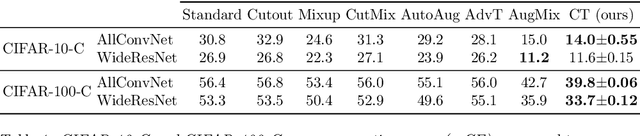
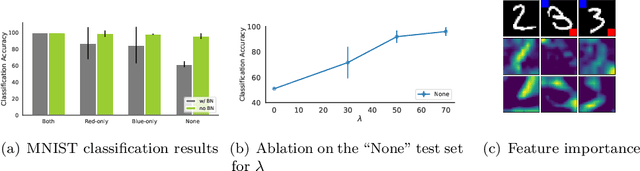
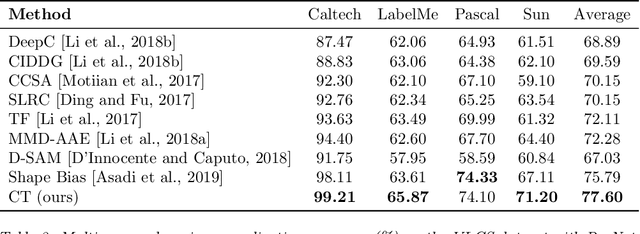
Batch normalization (BN) is a ubiquitous technique for training deep neural networks that accelerates their convergence to reach higher accuracy. However, we demonstrate that BN comes with a fundamental drawback: it incentivizes the model to rely on low-variance features that are highly specific to the training (in-domain) data, hurting generalization performance on out-of-domain examples. In this work, we investigate this phenomenon by first showing that removing BN layers across a wide range of architectures leads to lower out-of-domain and corruption errors at the cost of higher in-domain errors. We then propose Counterbalancing Teacher (CT), a method which leverages a frozen copy of the same model without BN as a teacher to enforce the student network's learning of robust representations by substantially adapting its weights through a consistency loss function. This regularization signal helps CT perform well in unforeseen data shifts, even without information from the target domain as in prior works. We theoretically show in an overparameterized linear regression setting why normalization leads to a model's reliance on such in-domain features, and empirically demonstrate the efficacy of CT by outperforming several baselines on robustness benchmarks such as CIFAR-10-C, CIFAR-100-C, and VLCS.