 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLASER: Learning a Latent Action Space for Efficient Reinforcement Learning
Mar 30, 2021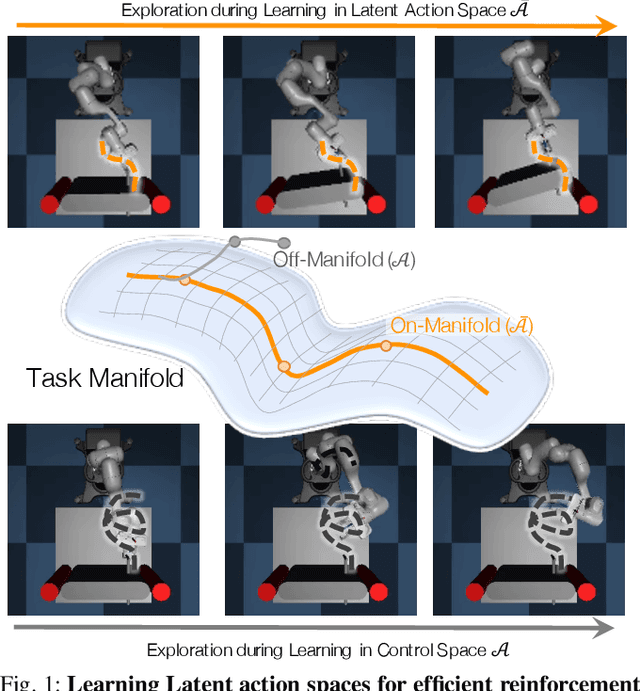
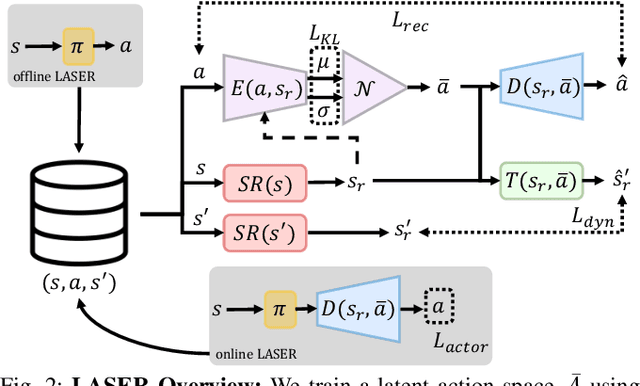

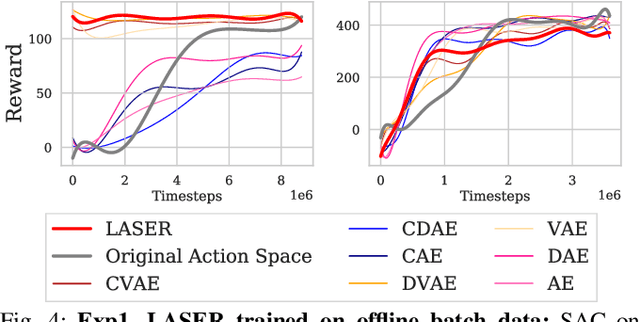
The process of learning a manipulation task depends strongly on the action space used for exploration: posed in the incorrect action space, solving a task with reinforcement learning can be drastically inefficient. Additionally, similar tasks or instances of the same task family impose latent manifold constraints on the most effective action space: the task family can be best solved with actions in a manifold of the entire action space of the robot. Combining these insights we present LASER, a method to learn latent action spaces for efficient reinforcement learning. LASER factorizes the learning problem into two sub-problems, namely action space learning and policy learning in the new action space. It leverages data from similar manipulation task instances, either from an offline expert or online during policy learning, and learns from these trajectories a mapping from the original to a latent action space. LASER is trained as a variational encoder-decoder model to map raw actions into a disentangled latent action space while maintaining action reconstruction and latent space dynamic consistency. We evaluate LASER on two contact-rich robotic tasks in simulation, and analyze the benefit of policy learning in the generated latent action space. We show improved sample efficiency compared to the original action space from better alignment of the action space to the task space, as we observe with visualizations of the learned action space manifold. Additional details: https://www.pair.toronto.edu/laser
Articulated Object Interaction in Unknown Scenes with Whole-Body Mobile Manipulation
Mar 18, 2021
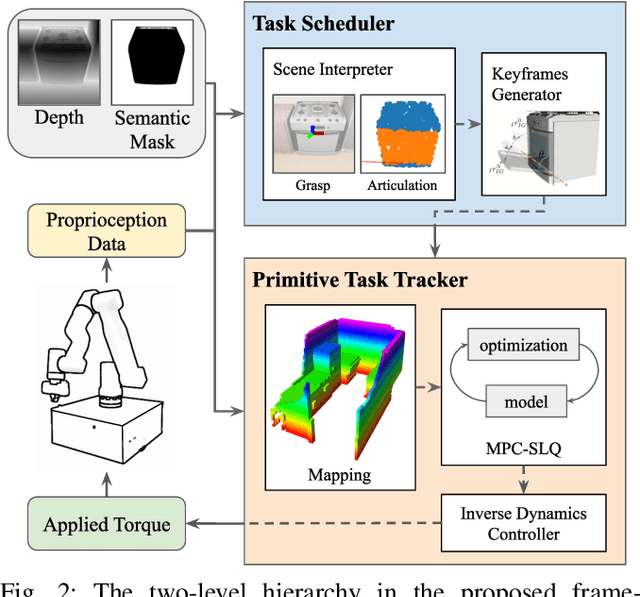
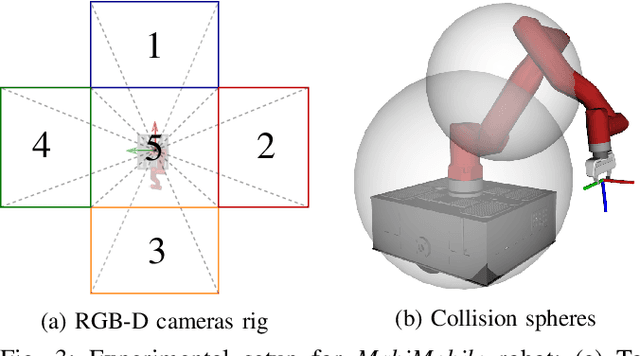

A kitchen assistant needs to operate human-scale objects, such as cabinets and ovens, in unmapped environments with dynamic obstacles. Autonomous interactions in such real-world environments require integrating dexterous manipulation and fluid mobility. While mobile manipulators in different form-factors provide an extended workspace, their real-world adoption has been limited. This limitation is in part due to two main reasons: 1) inability to interact with unknown human-scale objects such as cabinets and ovens, and 2) inefficient coordination between the arm and the mobile base. Executing a high-level task for general objects requires a perceptual understanding of the object as well as adaptive whole-body control among dynamic obstacles. In this paper, we propose a two-stage architecture for autonomous interaction with large articulated objects in unknown environments. The first stage uses a learned model to estimate the articulated model of a target object from an RGB-D input and predicts an action-conditional sequence of states for interaction. The second stage comprises of a whole-body motion controller to manipulate the object along the generated kinematic plan. We show that our proposed pipeline can handle complicated static and dynamic kitchen settings. Moreover, we demonstrate that the proposed approach achieves better performance than commonly used control methods in mobile manipulation. For additional material, please check: https://www.pair.toronto.edu/articulated-mm/ .
S4RL: Surprisingly Simple Self-Supervision for Offline Reinforcement Learning
Mar 10, 2021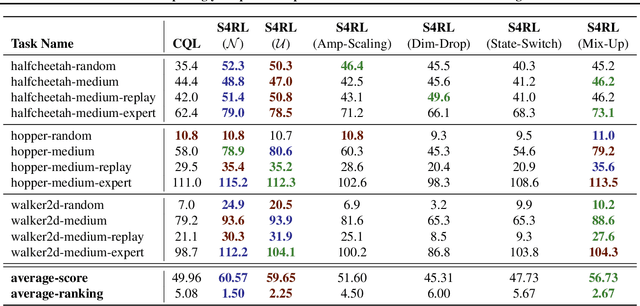
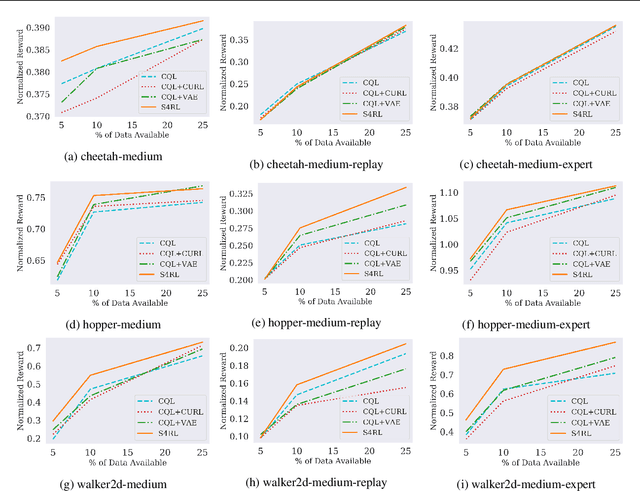
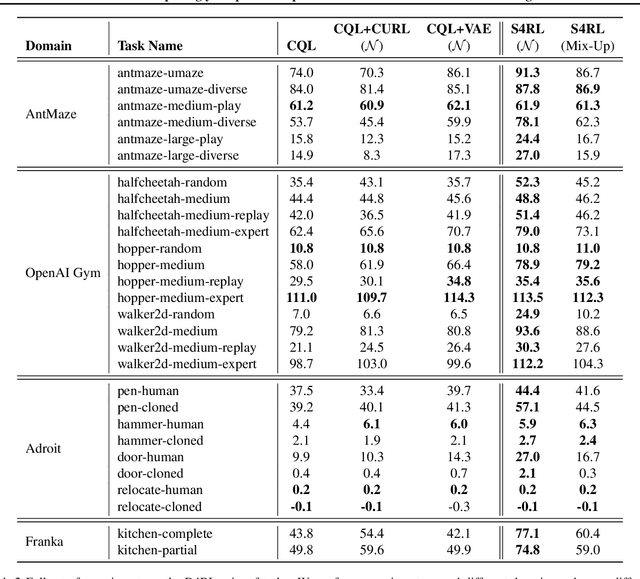
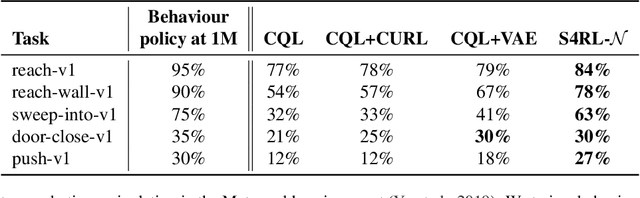
Offline reinforcement learning proposes to learn policies from large collected datasets without interaction. These algorithms have made it possible to learn useful skills from data that can then be transferred to the environment, making it feasible to deploy the trained policies in real-world settings where interactions may be costly or dangerous, such as self-driving. However, current algorithms overfit to the dataset they are trained on and perform poor out-of-distribution (OOD) generalization to the environment when deployed. We propose a Surprisingly Simple Self-Supervision algorithm (S4RL), which utilizes data augmentations from states to learn value functions that are better at generalizing and extrapolating when deployed in the environment. We investigate different data augmentation techniques that help learning a value function that can extrapolate to OOD data, and how to combine data augmentations and offline RL algorithms to learn a policy. We experimentally show that using S4RL significantly improves the state-of-the-art on most benchmark offline reinforcement learning tasks on popular benchmark datasets from D4RL, despite being simple and easy to implement.
Learning by Watching: Physical Imitation of Manipulation Skills from Human Videos
Jan 18, 2021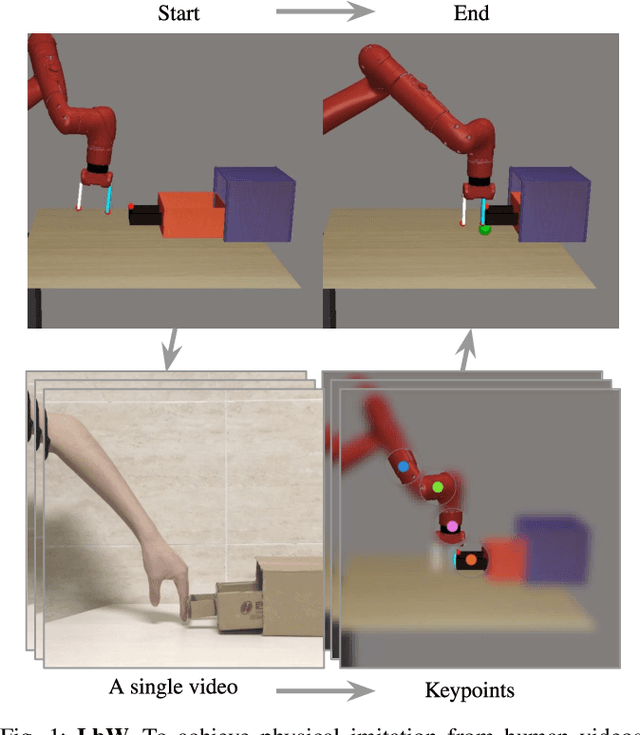
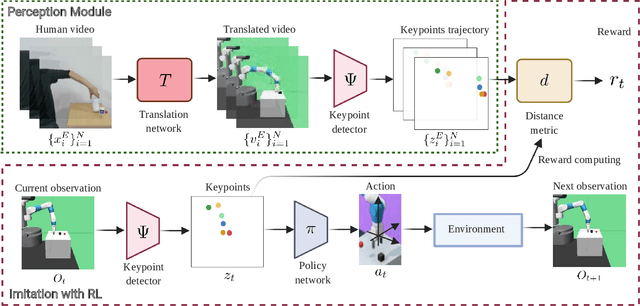
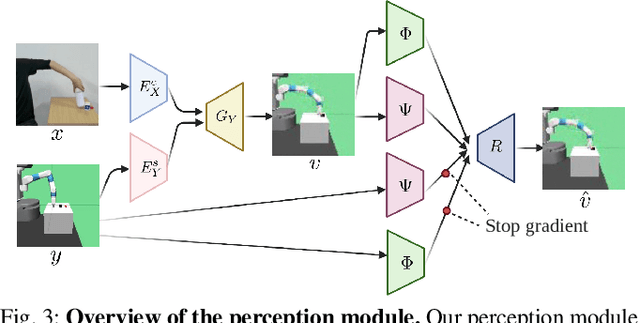

We present an approach for physical imitation from human videos for robot manipulation tasks. The key idea of our method lies in explicitly exploiting the kinematics and motion information embedded in the video to learn structured representations that endow the robot with the ability to imagine how to perform manipulation tasks in its own context. To achieve this, we design a perception module that learns to translate human videos to the robot domain followed by unsupervised keypoint detection. The resulting keypoint-based representations provide semantically meaningful information that can be directly used for reward computing and policy learning. We evaluate the effectiveness of our approach on five robot manipulation tasks, including reaching, pushing, sliding, coffee making, and drawer closing. Detailed experimental evaluations demonstrate that our method performs favorably against previous approaches.
Emergent Hand Morphology and Control from Optimizing Robust Grasps of Diverse Objects
Dec 22, 2020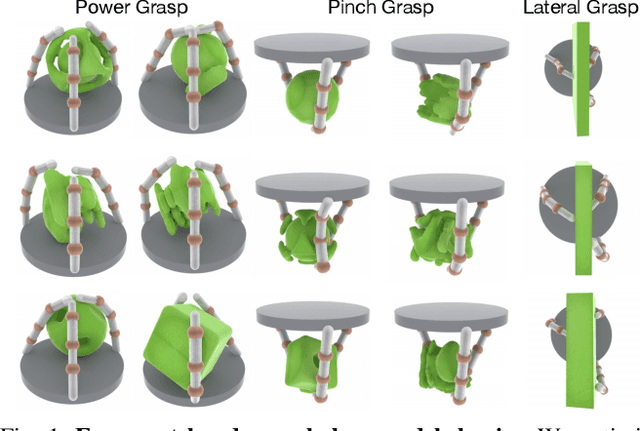
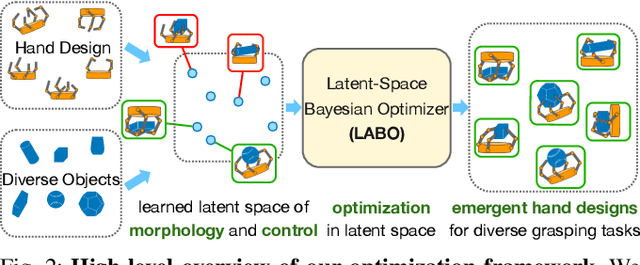
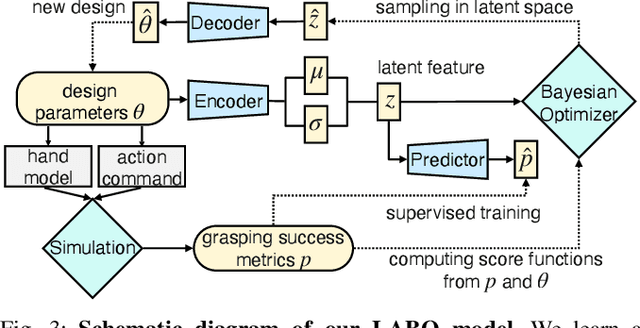
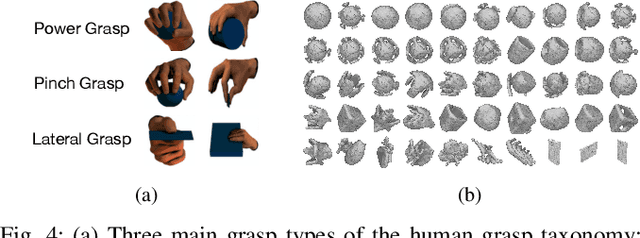
Evolution in nature illustrates that the creatures' biological structure and their sensorimotor skills adapt to the environmental changes for survival. Likewise, the ability to morph and acquire new skills can facilitate an embodied agent to solve tasks of varying complexities. In this work, we introduce a data-driven approach where effective hand designs naturally emerge for the purpose of grasping diverse objects. Jointly optimizing morphology and control imposes computational challenges since it requires constant evaluation of a black-box function that measures the performance of a combination of embodiment and behavior. We develop a novel Bayesian Optimization algorithm that efficiently co-designs the morphology and grasping skills jointly through learned latent-space representations. We design the grasping tasks based on a taxonomy of three human grasp types: power grasp, pinch grasp, and lateral grasp. Through experimentation and comparative study, we demonstrate the effectiveness of our approach in discovering robust and cost-efficient hand morphologies for grasping novel objects.
C-Learning: Horizon-Aware Cumulative Accessibility Estimation
Dec 14, 2020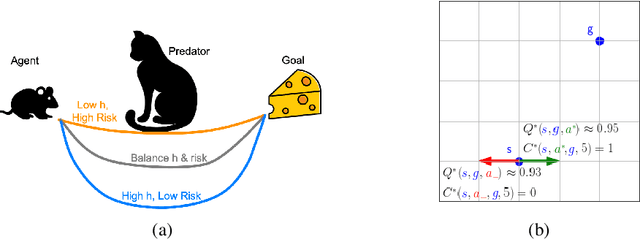
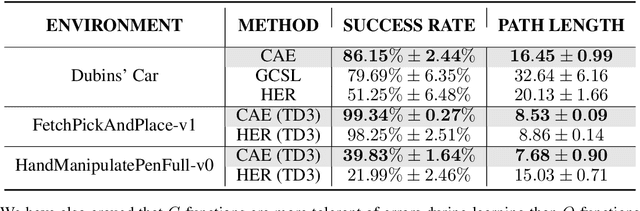
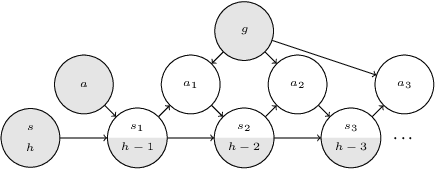

Multi-goal reaching is an important problem in reinforcement learning needed to achieve algorithmic generalization. Despite recent advances in this field, current algorithms suffer from three major challenges: high sample complexity, learning only a single way of reaching the goals, and difficulties in solving complex motion planning tasks. In order to address these limitations, we introduce the concept of cumulative accessibility functions, which measure the reachability of a goal from a given state within a specified horizon. We show that these functions obey a recurrence relation, which enables learning from offline interactions. We also prove that optimal cumulative accessibility functions are monotonic in the planning horizon. Additionally, our method can trade off speed and reliability in goal-reaching by suggesting multiple paths to a single goal depending on the provided horizon. We evaluate our approach on a set of multi-goal discrete and continuous control tasks. We show that our method outperforms state-of-the-art goal-reaching algorithms in success rate, sample complexity, and path optimality. Additional visualizations can be found at https://sites.google.com/view/learning-cae/.
Skill Transfer via Partially Amortized Hierarchical Planning
Nov 27, 2020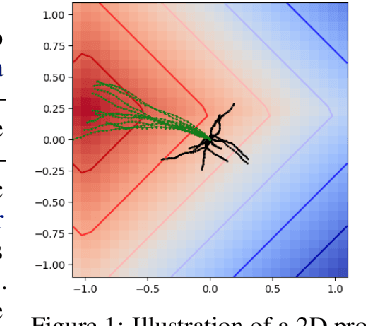
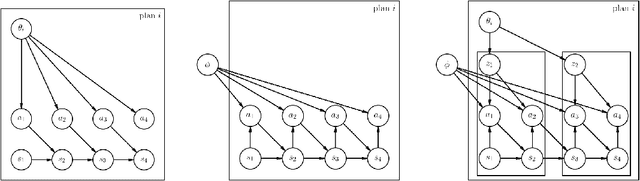
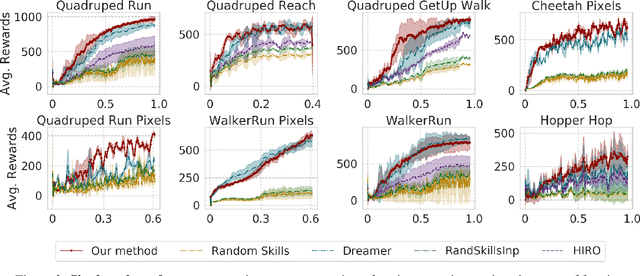
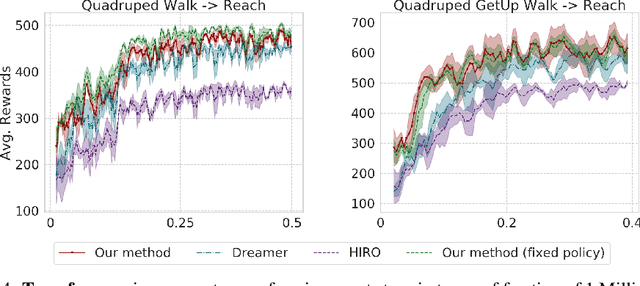
To quickly solve new tasks in complex environments, intelligent agents need to build up reusable knowledge. For example, a learned world model captures knowledge about the environment that applies to new tasks. Similarly, skills capture general behaviors that can apply to new tasks. In this paper, we investigate how these two approaches can be integrated into a single reinforcement learning agent. Specifically, we leverage the idea of partial amortization for fast adaptation at test time. For this, actions are produced by a policy that is learned over time while the skills it conditions on are chosen using online planning. We demonstrate the benefits of our design decisions across a suite of challenging locomotion tasks and demonstrate improved sample efficiency in single tasks as well as in transfer from one task to another, as compared to competitive baselines. Videos are available at: https://sites.google.com/view/partial-amortization-hierarchy/home
Action Concept Grounding Network for Semantically-Consistent Video Generation
Nov 23, 2020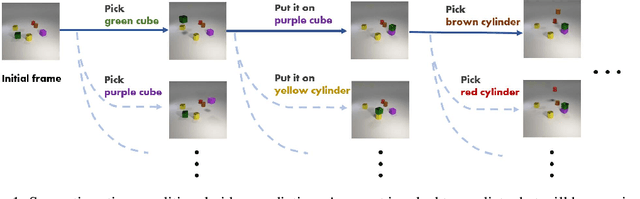
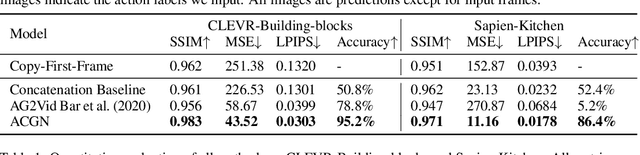
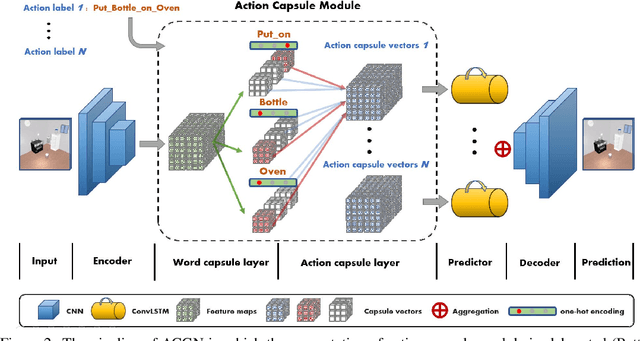

Recent works in self-supervised video prediction have mainly focused on passive forecasting and low-level action-conditional prediction, which sidesteps the problem of semantic learning. We introduce the task of semantic action-conditional video prediction, which can be regarded as an inverse problem of action recognition. The challenge of this new task primarily lies in how to effectively inform the model of semantic action information. To bridge vision and language, we utilize the idea of capsule and propose a novel video prediction model Action Concept Grounding Network (AGCN). Our method is evaluated on two newly designed synthetic datasets, CLEVR-Building-Blocks and Sapien-Kitchen, and experiments show that given different action labels, our ACGN can correctly condition on instructions and generate corresponding future frames without need of bounding boxes. We further demonstrate our trained model can make out-of-distribution predictions for concurrent actions, be quickly adapted to new object categories and exploit its learnt features for object detection. Additional visualizations can be found at https://iclr-acgn.github.io/ACGN/.
Solving Physics Puzzles by Reasoning about Paths
Nov 14, 2020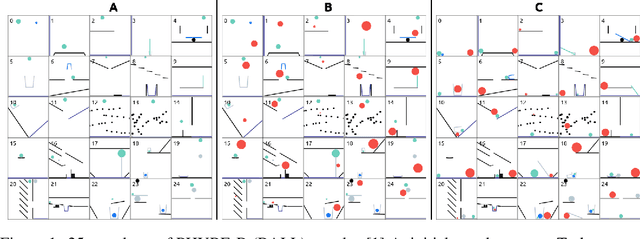

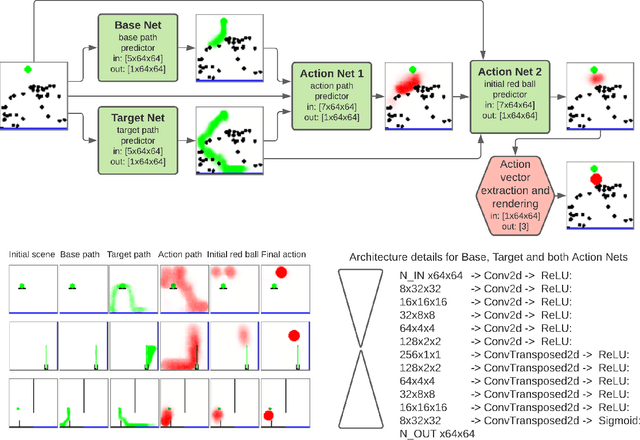
We propose a new deep learning model for goal-driven tasks that require intuitive physical reasoning and intervention in the scene to achieve a desired end goal. Its modular structure is motivated by hypothesizing a sequence of intuitive steps that humans apply when trying to solve such a task. The model first predicts the path the target object would follow without intervention and the path the target object should follow in order to solve the task. Next, it predicts the desired path of the action object and generates the placement of the action object. All components of the model are trained jointly in a supervised way; each component receives its own learning signal but learning signals are also backpropagated through the entire architecture. To evaluate the model we use PHYRE - a benchmark test for goal-driven physical reasoning in 2D mechanics puzzles.
Dynamics Randomization Revisited:A Case Study for Quadrupedal Locomotion
Nov 04, 2020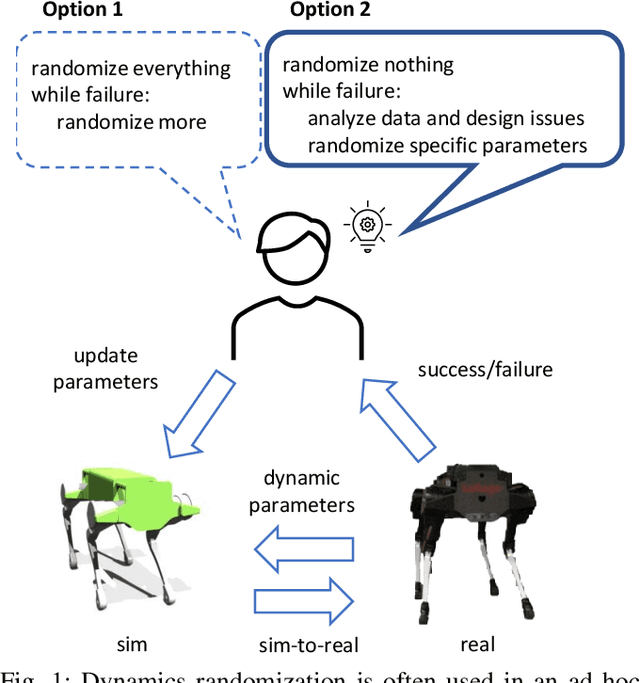
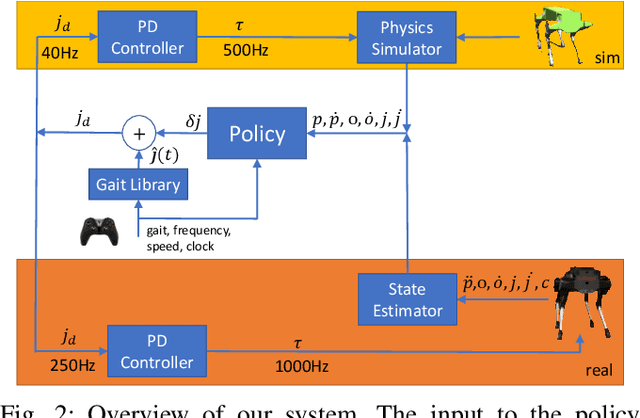

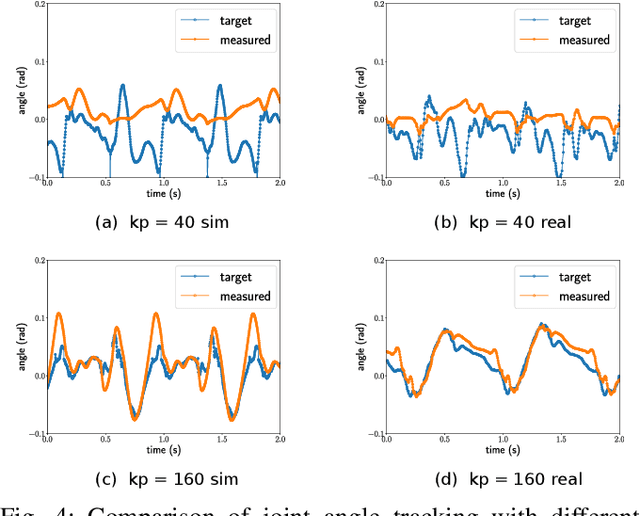
Understanding the gap between simulation andreality is critical for reinforcement learning with legged robots,which are largely trained in simulation. However, recent workhas resulted in sometimes conflicting conclusions with regardto which factors are important for success, including therole of dynamics randomization. In this paper, we aim toprovide clarity and understanding on the role of dynamicsrandomization in learning robust locomotion policies for theLaikago quadruped robot. Surprisingly, in contrast to priorwork with the same robot model, we find that direct sim-to-real transfer is possible without dynamics randomizationor on-robot adaptation schemes. We conduct extensive abla-tion studies in a sim-to-sim setting to understand the keyissues underlying successful policy transfer, including otherdesign decisions that can impact policy robustness. We furtherground our conclusions via sim-to-real experiments with variousgaits, speeds, and stepping frequencies. Additional Details: https://www.pair.toronto.edu/understanding-dr/.