 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmall LLMs for Biomedical Claim Verification: Cost-Effective Fine-Tuning, Structural Dataset Shortcuts, and Cross-Domain Generalization
Jun 11, 2026Large Language Models such as GPT-4o and GPT-5 achieve strong zero-shot performance on biomedical claim verification, but cost and opacity limit scalable use. We fine-tune three small LLMs: Phi-3-mini (3.8B), Qwen2.5-3B, and Mistral-7B, via QLoRA on SciFact and HealthVer, providing the first study of QLoRA models against GPT-4o and fine-tuned BioLinkBERT encoders. Mistral-7B QLoRA surpasses both GPT-4o and GPT-5 (up to 12% F1 gain) at a fractional cost using just 1,008 training examples. We conduct extensive in-domain and cross-domain evaluation: models trained on SciFact tested on HealthVer and vice versa, at matched sizes to isolate dataset structure from data quantity. We identify a previously unreported structural artifact in SciFact that inflates in-domain scores, and show through bidirectional out-of-domain evaluation that training on structurally sound data enables robust cross-domain transfer. We plan to release all code and adapter checkpoints.
SEEK: Semantic Evidence Extraction via Adaptive ChunKing for Multilingual Fact-Checking
May 27, 2026Multilingual fact verification requires evidence that is both relevant and sufficiently complete for reliable factuality prediction. However, existing systems often rely on search snippets, sentence-level evidence, or locally segmented passages, which can miss decisive context and produce fragmented evidence. To overcome these limitations, we propose SEEK, a Semantic Evidence Extraction with an adaptive chunKing framework that constructs coherent evidence chunks from full fact-checking articles by identifying semantic topic transitions and preserving local verification context. The constructed chunks are encoded using a multilingual encoder and then multilingual LLMs are finetuned using LoRA adapter for veracity prediction. Experiments on X-FACT and RU22Fact show that SEEK improves macro-f1 by up to 10% over semantic chunking, 19% over sentence chunking, and 20% over search-snippet baselines. Evidence completeness and significance analyses further show that SEEK preserves richer verification context and enables more reliable multilingual fact-checking.
ClickGuard: A Trustworthy Adaptive Fusion Framework for Clickbait Detection
Apr 08, 2026The widespread use of clickbait headlines, crafted to mislead and maximize engagement, poses a significant challenge to online credibility. These headlines employ sensationalism, misleading claims, and vague language, underscoring the need for effective detection to ensure trustworthy digital content. The paper introduces, ClickGuard: a trustworthy adaptive fusion framework for clickbait detection. It combines BERT embeddings and structural features using a Syntactic-Semantic Adaptive Fusion Block (SSAFB) for dynamic integration. The framework incorporates a hybrid CNN-BiLSTM to capture patterns and dependencies. The model achieved 96.93% testing accuracy, outperforming state-of-the-art approaches. The model's trustworthiness is evaluated using LIME and Permutation Feature Importance (PFI) for interpretability and perturbation analysis. These methods assess the model's robustness and sensitivity to feature changes by measuring the average prediction variation. Ablation studies validated the SSAFB's effectiveness in optimizing feature fusion. The model demonstrated robust performance across diverse datasets, providing a scalable, reliable solution for enhancing online content credibility by addressing syntactic-semantic modelling challenges. Code of the work is available at: https://github.com/palindromeRice/ClickBait_Detection_Architecture
Schema on the Inside: A Two-Phase Fine-Tuning Method for High-Efficiency Text-to-SQL at Scale
Mar 25, 2026Applying large, proprietary API-based language models to text-to-SQL tasks poses a significant industry challenge: reliance on massive, schema-heavy prompts results in prohibitive per-token API costs and high latency, hindering scalable production deployment. We present a specialized, self-hosted 8B-parameter model designed for a conversational bot in CriQ, a sister app to Dream11, India's largest fantasy sports platform with over 250 million users, that answers user queries about cricket statistics. Our novel two-phase supervised fine-tuning approach enables the model to internalize the entire database schema, eliminating the need for long-context prompts. This reduces input tokens by over 99%, from a 17k-token baseline to fewer than 100, and replaces costly external API calls with efficient local inference. The resulting system achieves 98.4% execution success and 92.5% semantic accuracy, substantially outperforming a prompt-engineered baseline using Google's Gemini Flash 2.0 (95.6% execution, 89.4% semantic accuracy). These results demonstrate a practical path toward high-precision, low-latency text-to-SQL applications using domain-specialized, self-hosted language models in large-scale production environments.
* 8 pages, 6 figures. Published in the Proceedings of the Fortieth AAAI Conference on Artificial Intelligence (AAAI-26), 2026
B-DENSE: Branching For Dense Ensemble Network Learning
Feb 17, 2026Inspired by non-equilibrium thermodynamics, diffusion models have achieved state-of-the-art performance in generative modeling. However, their iterative sampling nature results in high inference latency. While recent distillation techniques accelerate sampling, they discard intermediate trajectory steps. This sparse supervision leads to a loss of structural information and introduces significant discretization errors. To mitigate this, we propose B-DENSE, a novel framework that leverages multi-branch trajectory alignment. We modify the student architecture to output $K$-fold expanded channels, where each subset corresponds to a specific branch representing a discrete intermediate step in the teacher's trajectory. By training these branches to simultaneously map to the entire sequence of the teacher's target timesteps, we enforce dense intermediate trajectory alignment. Consequently, the student model learns to navigate the solution space from the earliest stages of training, demonstrating superior image generation quality compared to baseline distillation frameworks.
Model-First Reasoning LLM Agents: Reducing Hallucinations through Explicit Problem Modeling
Dec 16, 2025Large Language Models (LLMs) often struggle with complex multi-step planning tasks, showing high rates of constraint violations and inconsistent solutions. Existing strategies such as Chain-of-Thought and ReAct rely on implicit state tracking and lack an explicit problem representation. Inspired by classical AI planning, we propose Model-First Reasoning (MFR), a two-phase paradigm in which the LLM first constructs an explicit model of the problem, defining entities, state variables, actions, and constraints, before generating a solution plan. Across multiple planning domains, including medical scheduling, route planning, resource allocation, logic puzzles, and procedural synthesis, MFR reduces constraint violations and improves solution quality compared to Chain-of-Thought and ReAct. Ablation studies show that the explicit modeling phase is critical for these gains. Our results suggest that many LLM planning failures stem from representational deficiencies rather than reasoning limitations, highlighting explicit modeling as a key component for robust and interpretable AI agents. All prompts, evaluation procedures, and task datasets are documented to facilitate reproducibility.
Multimodal Fact Checking with Unified Visual, Textual, and Contextual Representations
Aug 07, 2025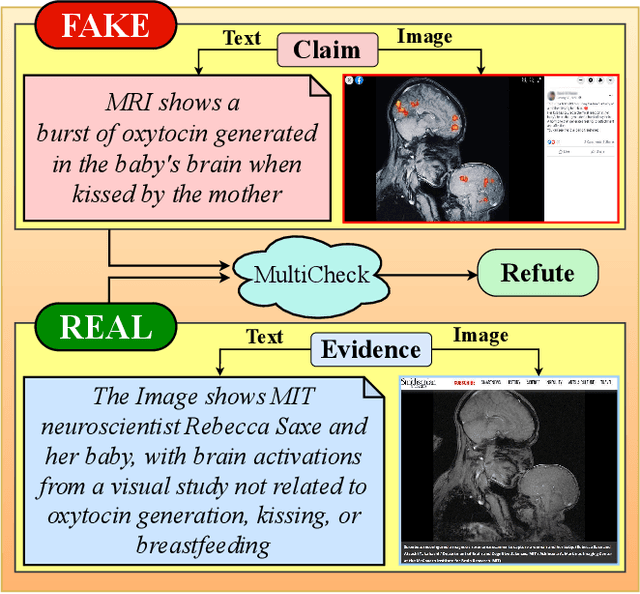



The growing rate of multimodal misinformation, where claims are supported by both text and images, poses significant challenges to fact-checking systems that rely primarily on textual evidence. In this work, we have proposed a unified framework for fine-grained multimodal fact verification called "MultiCheck", designed to reason over structured textual and visual signals. Our architecture combines dedicated encoders for text and images with a fusion module that captures cross-modal relationships using element-wise interactions. A classification head then predicts the veracity of a claim, supported by a contrastive learning objective that encourages semantic alignment between claim-evidence pairs in a shared latent space. We evaluate our approach on the Factify 2 dataset, achieving a weighted F1 score of 0.84, substantially outperforming the baseline. These results highlight the effectiveness of explicit multimodal reasoning and demonstrate the potential of our approach for scalable and interpretable fact-checking in complex, real-world scenarios.
Paired and Unpaired Image to Image Translation using Generative Adversarial Networks
May 22, 2025Image to image translation is an active area of research in the field of computer vision, enabling the generation of new images with different styles, textures, or resolutions while preserving their characteristic properties. Recent architectures leverage Generative Adversarial Networks (GANs) to transform input images from one domain to another. In this work, we focus on the study of both paired and unpaired image translation across multiple image domains. For the paired task, we used a conditional GAN model, and for the unpaired task, we trained it using cycle consistency loss. We experimented with different types of loss functions, multiple Patch-GAN sizes, and model architectures. New quantitative metrics - precision, recall, and FID score - were used for analysis. In addition, a qualitative study of the results of different experiments was conducted.
Improving the fact-checking performance of language models by relying on their entailment ability
May 21, 2025Automated fact-checking is a crucial task in this digital age. To verify a claim, current approaches majorly follow one of two strategies i.e. (i) relying on embedded knowledge of language models, and (ii) fine-tuning them with evidence pieces. While the former can make systems to hallucinate, the later have not been very successful till date. The primary reason behind this is that fact verification is a complex process. Language models have to parse through multiple pieces of evidence before making a prediction. Further, the evidence pieces often contradict each other. This makes the reasoning process even more complex. We proposed a simple yet effective approach where we relied on entailment and the generative ability of language models to produce ''supporting'' and ''refuting'' justifications (for the truthfulness of a claim). We trained language models based on these justifications and achieved superior results. Apart from that, we did a systematic comparison of different prompting and fine-tuning strategies, as it is currently lacking in the literature. Some of our observations are: (i) training language models with raw evidence sentences registered an improvement up to 8.20% in macro-F1, over the best performing baseline for the RAW-FC dataset, (ii) similarly, training language models with prompted claim-evidence understanding (TBE-2) registered an improvement (with a margin up to 16.39%) over the baselines for the same dataset, (iii) training language models with entailed justifications (TBE-3) outperformed the baselines by a huge margin (up to 28.57% and 44.26% for LIAR-RAW and RAW-FC, respectively). We have shared our code repository to reproduce the results.
Composable NLP Workflows for BERT-based Ranking and QA System
Apr 13, 2025



There has been a lot of progress towards building NLP models that scale to multiple tasks. However, real-world systems contain multiple components and it is tedious to handle cross-task interaction with varying levels of text granularity. In this work, we built an end-to-end Ranking and Question-Answering (QA) system using Forte, a toolkit that makes composable NLP pipelines. We utilized state-of-the-art deep learning models such as BERT, RoBERTa in our pipeline, evaluated the performance on MS-MARCO and Covid-19 datasets using metrics such as BLUE, MRR, F1 and compared the results of ranking and QA systems with their corresponding benchmark results. The modular nature of our pipeline and low latency of reranker makes it easy to build complex NLP applications easily.