 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOBALT: Crowdsourcing Robot Learning via Cloud-Based Teleoperation with Smartphones
May 20, 2026The scarcity of large-scale, high-quality demonstration data remains a bottleneck in scaling imitation learning for robotic manipulation. We present COBALT, a teleoperation platform designed to democratize robot learning at scale both in simulation and in the real world. By leveraging vectorized environments, our scalable, load-balanced infrastructure supports concurrent teleoperation by multiple users on a single GPU, yielding a significant reduction in teleoperation cost. Operators can connect from nearly anywhere on Earth using commonly available devices, including single or dual smartphones, VR headsets, 3D mice, and keyboards. An inmemory data cache and efficient video streaming keep control and rendering synchronous, sustaining dozens of concurrent users at 20 Hz with sub-100 ms end-to-end latency for up to 8 concurrent users per GPU. We also demonstrate stable operation supporting 256 simulated clients across 8 GPUs, underscoring the system's ability to scale across hardware and within individual servers. We perform a comprehensive user study showing that phone-based teleoperation performs comparably to or better than specialized hardware, enabling faster, more ergonomic data collection. To ensure data quality, COBALT logs a suite of real-time metrics to automatically filter suboptimal demonstrations. We further demonstrate that a structured user training curriculum significantly improves data collection quality. Guided by insights from our user study, we crowdsource the collection of a large-scale, high-quality pilot dataset with 7500+ demonstrations (50+ hours) collected with smartphones across nine countries over five days. We validate the dataset's quality by training state-of-the-art imitation learning algorithms. Please visit https://cobalt-teleop.github.io/ for more details.
AMPLIFY: Actionless Motion Priors for Robot Learning from Videos
Jun 17, 2025Action-labeled data for robotics is scarce and expensive, limiting the generalization of learned policies. In contrast, vast amounts of action-free video data are readily available, but translating these observations into effective policies remains a challenge. We introduce AMPLIFY, a novel framework that leverages large-scale video data by encoding visual dynamics into compact, discrete motion tokens derived from keypoint trajectories. Our modular approach separates visual motion prediction from action inference, decoupling the challenges of learning what motion defines a task from how robots can perform it. We train a forward dynamics model on abundant action-free videos and an inverse dynamics model on a limited set of action-labeled examples, allowing for independent scaling. Extensive evaluations demonstrate that the learned dynamics are both accurate, achieving up to 3.7x better MSE and over 2.5x better pixel prediction accuracy compared to prior approaches, and broadly useful. In downstream policy learning, our dynamics predictions enable a 1.2-2.2x improvement in low-data regimes, a 1.4x average improvement by learning from action-free human videos, and the first generalization to LIBERO tasks from zero in-distribution action data. Beyond robotic control, we find the dynamics learned by AMPLIFY to be a versatile latent world model, enhancing video prediction quality. Our results present a novel paradigm leveraging heterogeneous data sources to build efficient, generalizable world models. More information can be found at https://amplify-robotics.github.io/.
RoCoDA: Counterfactual Data Augmentation for Data-Efficient Robot Learning from Demonstrations
Nov 25, 2024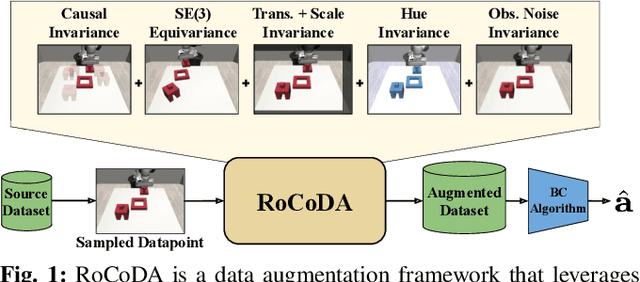

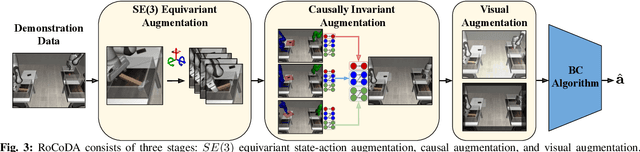
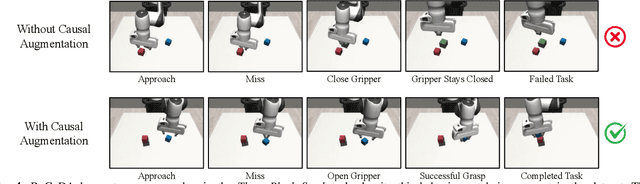
Imitation learning in robotics faces significant challenges in generalization due to the complexity of robotic environments and the high cost of data collection. We introduce RoCoDA, a novel method that unifies the concepts of invariance, equivariance, and causality within a single framework to enhance data augmentation for imitation learning. RoCoDA leverages causal invariance by modifying task-irrelevant subsets of the environment state without affecting the policy's output. Simultaneously, we exploit SE(3) equivariance by applying rigid body transformations to object poses and adjusting corresponding actions to generate synthetic demonstrations. We validate RoCoDA through extensive experiments on five robotic manipulation tasks, demonstrating improvements in policy performance, generalization, and sample efficiency compared to state-of-the-art data augmentation methods. Our policies exhibit robust generalization to unseen object poses, textures, and the presence of distractors. Furthermore, we observe emergent behavior such as re-grasping, indicating policies trained with RoCoDA possess a deeper understanding of task dynamics. By leveraging invariance, equivariance, and causality, RoCoDA provides a principled approach to data augmentation in imitation learning, bridging the gap between geometric symmetries and causal reasoning.
ForceSight: Text-Guided Mobile Manipulation with Visual-Force Goals
Sep 24, 2023



We present ForceSight, a system for text-guided mobile manipulation that predicts visual-force goals using a deep neural network. Given a single RGBD image combined with a text prompt, ForceSight determines a target end-effector pose in the camera frame (kinematic goal) and the associated forces (force goal). Together, these two components form a visual-force goal. Prior work has demonstrated that deep models outputting human-interpretable kinematic goals can enable dexterous manipulation by real robots. Forces are critical to manipulation, yet have typically been relegated to lower-level execution in these systems. When deployed on a mobile manipulator equipped with an eye-in-hand RGBD camera, ForceSight performed tasks such as precision grasps, drawer opening, and object handovers with an 81% success rate in unseen environments with object instances that differed significantly from the training data. In a separate experiment, relying exclusively on visual servoing and ignoring force goals dropped the success rate from 90% to 45%, demonstrating that force goals can significantly enhance performance. The appendix, videos, code, and trained models are available at https://force-sight.github.io/.
Visual Contact Pressure Estimation for Grippers in the Wild
Mar 13, 2023



Sensing contact pressure applied by a gripper is useful for autonomous and teleoperated robotic manipulation, but adding tactile sensing to a gripper's surface can be difficult or impractical. If a gripper visibly deforms when forces are applied, contact pressure can be visually estimated using images from an external camera that observes the gripper. While researchers have demonstrated this capability in controlled laboratory settings, prior work has not addressed challenges associated with visual pressure estimation in the wild, where lighting, surfaces, and other factors vary widely. We present a deep learning model and associated methods that enable visual pressure estimation under widely varying conditions. Our model, Visual Pressure Estimation for Robots (ViPER), takes an image from an eye-in-hand camera as input and outputs an image representing the pressure applied by a soft gripper. Our key insight is that force/torque sensing can be used as a weak label to efficiently collect training data in settings where pressure measurements would be difficult to obtain. When trained on this weakly labeled data combined with fully labeled data containing pressure measurements, ViPER outperforms prior methods, enables precision manipulation in cluttered settings, and provides accurate estimates for unseen conditions relevant to in-home use.
Visual Estimation of Fingertip Pressure on Diverse Surfaces using Easily Captured Data
Jan 05, 2023



Prior research has shown that deep models can estimate the pressure applied by a hand to a surface based on a single RGB image. Training these models requires high-resolution pressure measurements that are difficult to obtain with physical sensors. Additionally, even experts cannot reliably annotate pressure from images. Thus, data collection is a critical barrier to generalization and improved performance. We present a novel approach that enables training data to be efficiently captured from unmodified surfaces with only an RGB camera and a cooperative participant. Our key insight is that people can be prompted to perform actions that correspond with categorical labels (contact labels) describing contact pressure, such as using a specific fingertip to make low-force contact. We present ContactLabelNet, which visually estimates pressure applied by fingertips. With the use of contact labels, ContactLabelNet achieves improved performance, generalizes to novel surfaces, and outperforms models from prior work.
Force/Torque Sensing for Soft Grippers using an External Camera
Sep 30, 2022

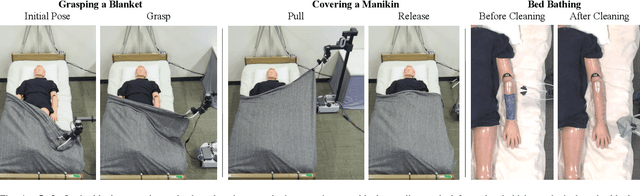
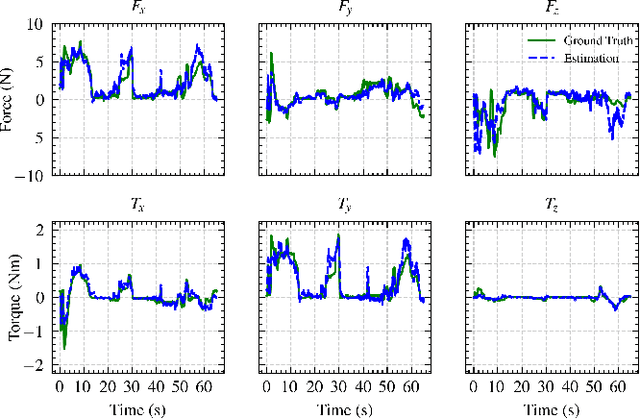
Robotic manipulation can benefit from wrist-mounted force/torque (F/T) sensors, but conventional F/T sensors can be expensive, difficult to install, and damaged by high loads. We present Visual Force/Torque Sensing (VFTS), a method that visually estimates the 6-axis F/T measurement that would be reported by a conventional F/T sensor. In contrast to approaches that sense loads using internal cameras placed behind soft exterior surfaces, our approach uses an external camera with a fisheye lens that observes a soft gripper. VFTS includes a deep learning model that takes a single RGB image as input and outputs a 6-axis F/T estimate. We trained the model with sensor data collected while teleoperating a robot (Stretch RE1 from Hello Robot Inc.) to perform manipulation tasks. VFTS outperformed F/T estimates based on motor currents, generalized to a novel home environment, and supported three autonomous tasks relevant to healthcare: grasping a blanket, pulling a blanket over a manikin, and cleaning a manikin's limbs. VFTS also performed well with a manually operated pneumatic gripper. Overall, our results suggest that an external camera observing a soft gripper can perform useful visual force/torque sensing for a variety of manipulation tasks.
Visual Pressure Estimation and Control for Soft Robotic Grippers
Apr 14, 2022

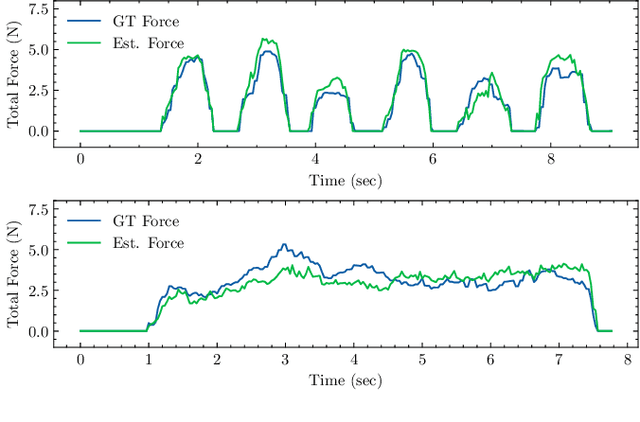
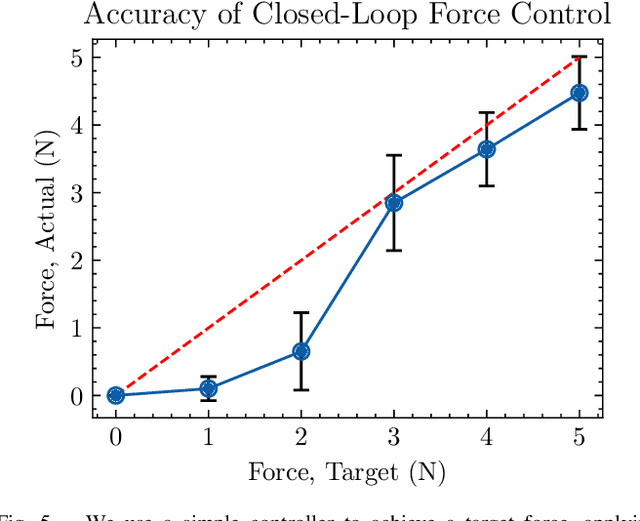
Soft robotic grippers facilitate contact-rich manipulation, including robust grasping of varied objects. Yet the beneficial compliance of a soft gripper also results in significant deformation that can make precision manipulation challenging. We present visual pressure estimation & control (VPEC), a method that uses a single RGB image of an unmodified soft gripper from an external camera to directly infer pressure applied to the world by the gripper. We present inference results for a pneumatic gripper and a tendon-actuated gripper making contact with a flat surface. We also show that VPEC enables precision manipulation via closed-loop control of inferred pressure. We present results for a mobile manipulator (Stretch RE1 from Hello Robot) using visual servoing to do the following: achieve target pressures when making contact; follow a spatial pressure trajectory; and grasp small objects, including a microSD card, a washer, a penny, and a pill. Overall, our results show that VPEC enables grippers with high compliance to perform precision manipulation.