 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhone2Proc: Bringing Robust Robots Into Our Chaotic World
Dec 08, 2022Training embodied agents in simulation has become mainstream for the embodied AI community. However, these agents often struggle when deployed in the physical world due to their inability to generalize to real-world environments. In this paper, we present Phone2Proc, a method that uses a 10-minute phone scan and conditional procedural generation to create a distribution of training scenes that are semantically similar to the target environment. The generated scenes are conditioned on the wall layout and arrangement of large objects from the scan, while also sampling lighting, clutter, surface textures, and instances of smaller objects with randomized placement and materials. Leveraging just a simple RGB camera, training with Phone2Proc shows massive improvements from 34.7% to 70.7% success rate in sim-to-real ObjectNav performance across a test suite of over 200 trials in diverse real-world environments, including homes, offices, and RoboTHOR. Furthermore, Phone2Proc's diverse distribution of generated scenes makes agents remarkably robust to changes in the real world, such as human movement, object rearrangement, lighting changes, or clutter.
Retrospectives on the Embodied AI Workshop
Oct 17, 2022

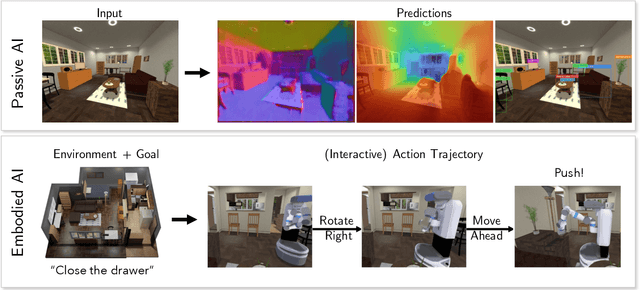
We present a retrospective on the state of Embodied AI research. Our analysis focuses on 13 challenges presented at the Embodied AI Workshop at CVPR. These challenges are grouped into three themes: (1) visual navigation, (2) rearrangement, and (3) embodied vision-and-language. We discuss the dominant datasets within each theme, evaluation metrics for the challenges, and the performance of state-of-the-art models. We highlight commonalities between top approaches to the challenges and identify potential future directions for Embodied AI research.
Towards Multimodal Multitask Scene Understanding Models for Indoor Mobile Agents
Sep 27, 2022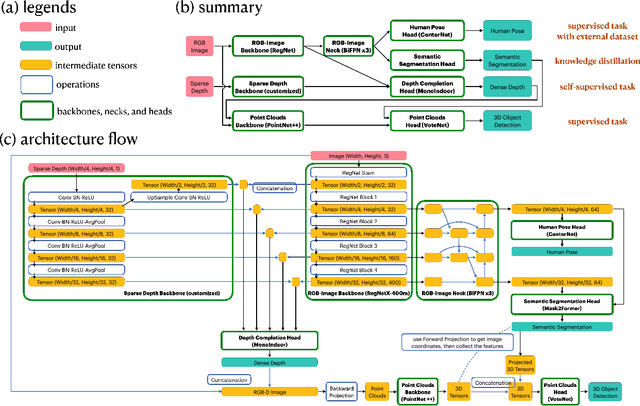
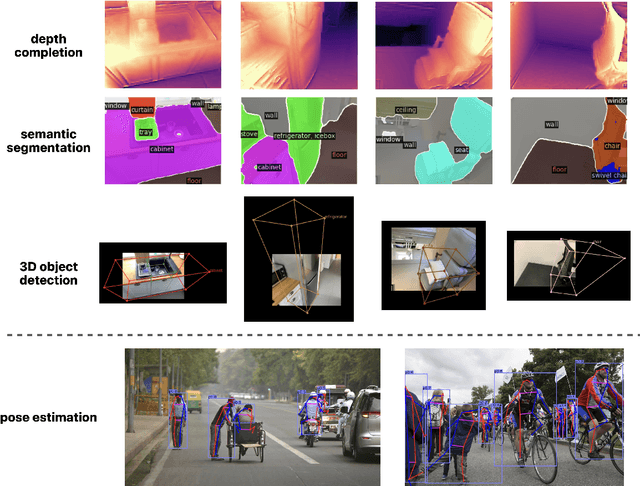
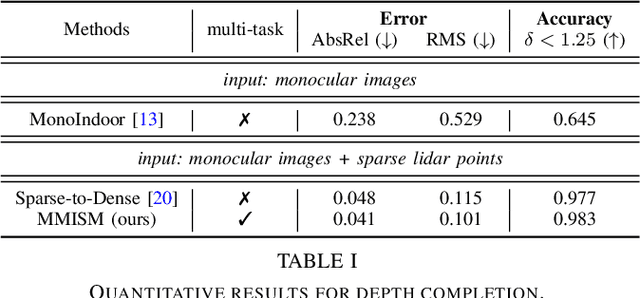
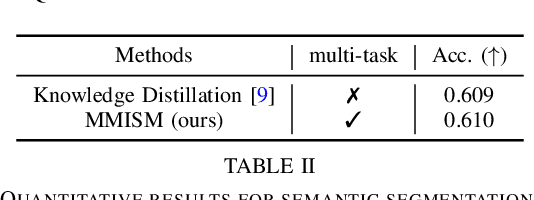
The perception system in personalized mobile agents requires developing indoor scene understanding models, which can understand 3D geometries, capture objectiveness, analyze human behaviors, etc. Nonetheless, this direction has not been well-explored in comparison with models for outdoor environments (e.g., the autonomous driving system that includes pedestrian prediction, car detection, traffic sign recognition, etc.). In this paper, we first discuss the main challenge: insufficient, or even no, labeled data for real-world indoor environments, and other challenges such as fusion between heterogeneous sources of information (e.g., RGB images and Lidar point clouds), modeling relationships between a diverse set of outputs (e.g., 3D object locations, depth estimation, and human poses), and computational efficiency. Then, we describe MMISM (Multi-modality input Multi-task output Indoor Scene understanding Model) to tackle the above challenges. MMISM considers RGB images as well as sparse Lidar points as inputs and 3D object detection, depth completion, human pose estimation, and semantic segmentation as output tasks. We show that MMISM performs on par or even better than single-task models; e.g., we improve the baseline 3D object detection results by 11.7% on the benchmark ARKitScenes dataset.
Safe Real-World Reinforcement Learning for Mobile Agent Obstacle Avoidance
Sep 23, 2022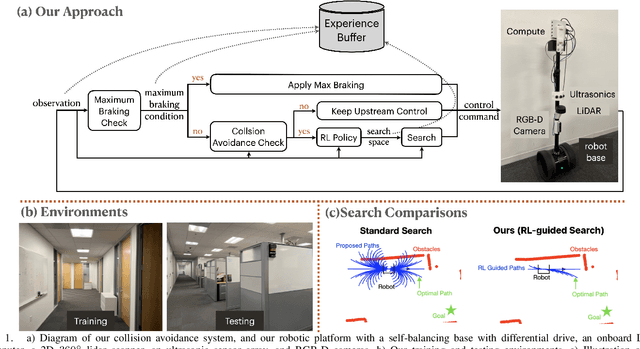
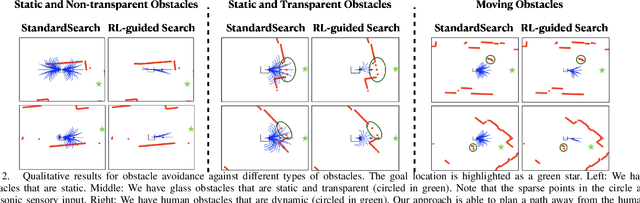


Collision avoidance is key for mobile robots and agents to operate safely in the real world. In this work, we present an efficient and effective collision avoidance system that combines real-world reinforcement learning (RL), search-based online trajectory planning, and automatic emergency intervention, e.g. automatic emergency braking (AEB). The goal of the RL is to learn effective search heuristics that speed up the search for collision-free trajectory and reduce the frequency of triggering automatic emergency interventions. This novel setup enables RL to learn safely and directly on mobile robots in a real-world indoor environment, minimizing actual crashes even during training. Our real-world experiments show that, when compared with several baselines, our approach enjoys a higher average speed, lower crash rate, higher goals reached rate, smaller computation overhead, and smoother overall control.
What does a platypus look like? Generating customized prompts for zero-shot image classification
Sep 07, 2022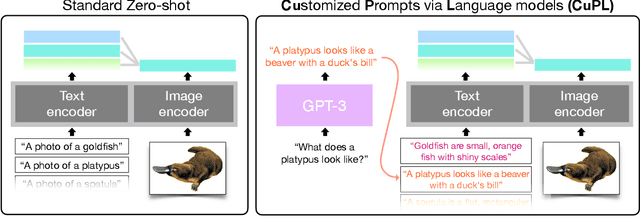
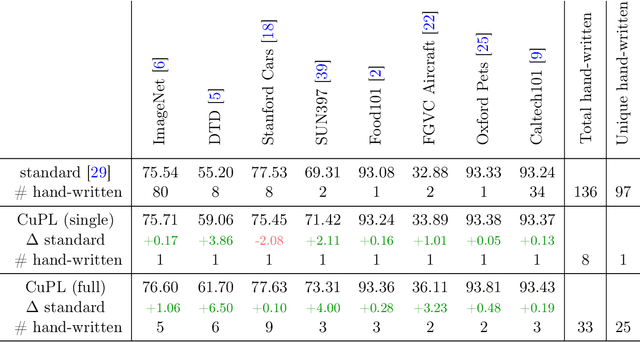
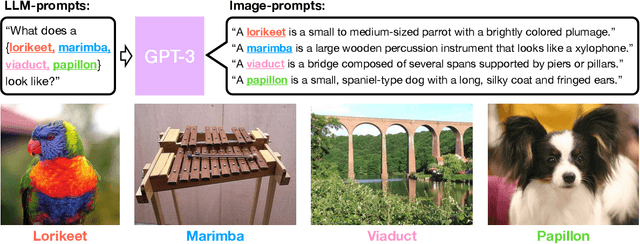
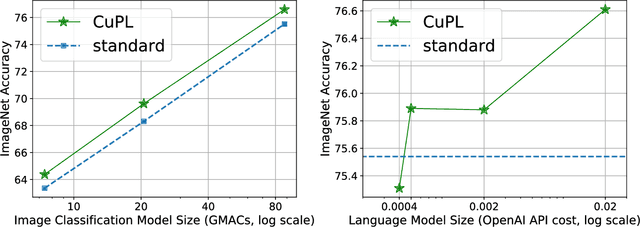
Open vocabulary models are a promising new paradigm for image classification. Unlike traditional classification models, open vocabulary models classify among any arbitrary set of categories specified with natural language during inference. This natural language, called "prompts", typically consists of a set of hand-written templates (e.g., "a photo of a {}") which are completed with each of the category names. This work introduces a simple method to generate higher accuracy prompts, without using explicit knowledge of the image domain and with far fewer hand-constructed sentences. To achieve this, we combine open vocabulary models with large language models (LLMs) to create Customized Prompts via Language models (CuPL, pronounced "couple"). In particular, we leverage the knowledge contained in LLMs in order to generate many descriptive sentences that are customized for each object category. We find that this straightforward and general approach improves accuracy on a range of zero-shot image classification benchmarks, including over one percentage point gain on ImageNet. Finally, this method requires no additional training and remains completely zero-shot. Code is available at https://github.com/sarahpratt/CuPL.
Patching open-vocabulary models by interpolating weights
Aug 10, 2022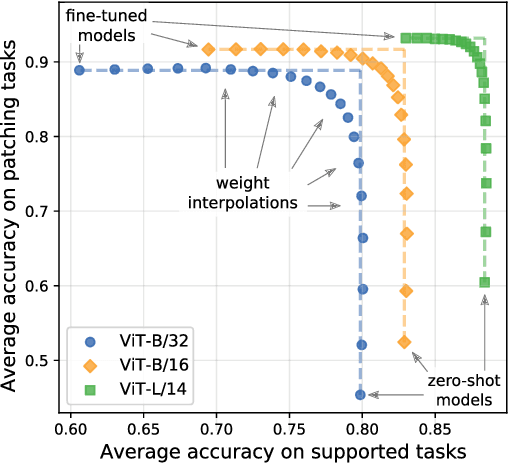

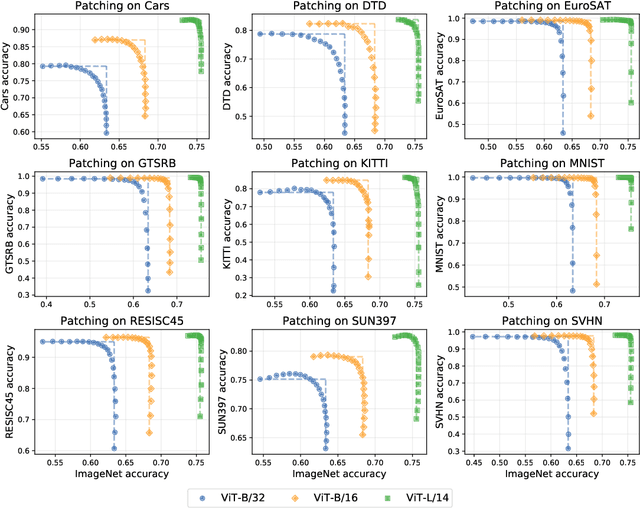

Open-vocabulary models like CLIP achieve high accuracy across many image classification tasks. However, there are still settings where their zero-shot performance is far from optimal. We study model patching, where the goal is to improve accuracy on specific tasks without degrading accuracy on tasks where performance is already adequate. Towards this goal, we introduce PAINT, a patching method that uses interpolations between the weights of a model before fine-tuning and the weights after fine-tuning on a task to be patched. On nine tasks where zero-shot CLIP performs poorly, PAINT increases accuracy by 15 to 60 percentage points while preserving accuracy on ImageNet within one percentage point of the zero-shot model. PAINT also allows a single model to be patched on multiple tasks and improves with model scale. Furthermore, we identify cases of broad transfer, where patching on one task increases accuracy on other tasks even when the tasks have disjoint classes. Finally, we investigate applications beyond common benchmarks such as counting or reducing the impact of typographic attacks on CLIP. Our findings demonstrate that it is possible to expand the set of tasks on which open-vocabulary models achieve high accuracy without re-training them from scratch.
Break and Make: Interactive Structural Understanding Using LEGO Bricks
Jul 27, 2022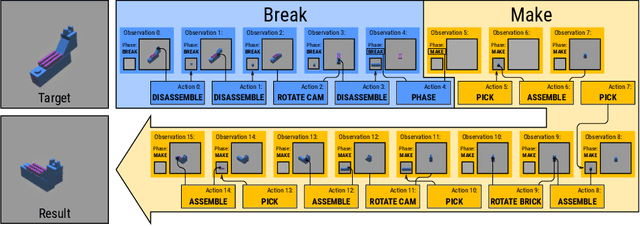
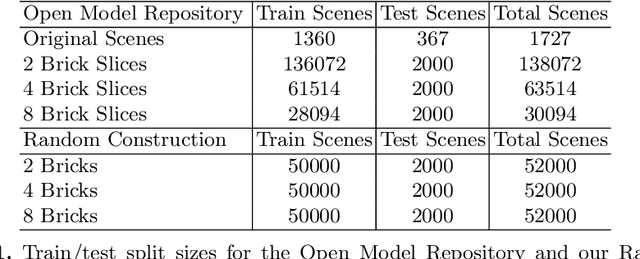
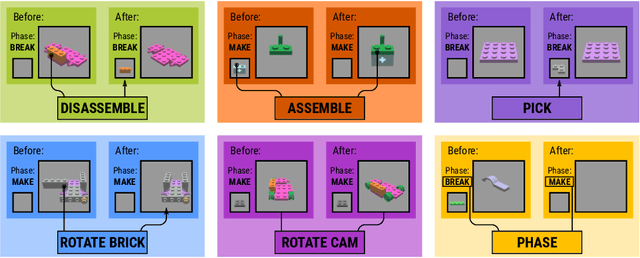
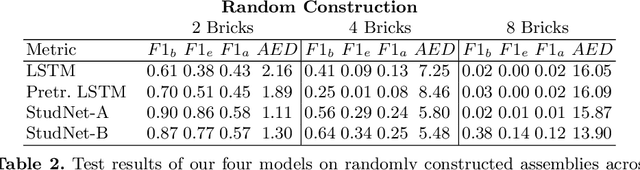
Visual understanding of geometric structures with complex spatial relationships is a fundamental component of human intelligence. As children, we learn how to reason about structure not only from observation, but also by interacting with the world around us -- by taking things apart and putting them back together again. The ability to reason about structure and compositionality allows us to not only build things, but also understand and reverse-engineer complex systems. In order to advance research in interactive reasoning for part-based geometric understanding, we propose a challenging new assembly problem using LEGO bricks that we call Break and Make. In this problem an agent is given a LEGO model and attempts to understand its structure by interactively inspecting and disassembling it. After this inspection period, the agent must then prove its understanding by rebuilding the model from scratch using low-level action primitives. In order to facilitate research on this problem we have built LTRON, a fully interactive 3D simulator that allows learning agents to assemble, disassemble and manipulate LEGO models. We pair this simulator with a new dataset of fan-made LEGO creations that have been uploaded to the internet in order to provide complex scenes containing over a thousand unique brick shapes. We take a first step towards solving this problem using sequence-to-sequence models that provide guidance for how to make progress on this challenging problem. Our simulator and data are available at github.com/aaronwalsman/ltron. Additional training code and PyTorch examples are available at github.com/aaronwalsman/ltron-torch-eccv22.
ProcTHOR: Large-Scale Embodied AI Using Procedural Generation
Jun 14, 2022

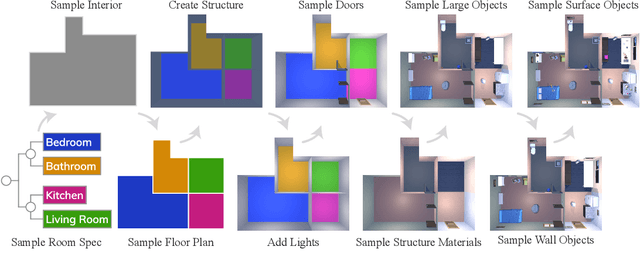
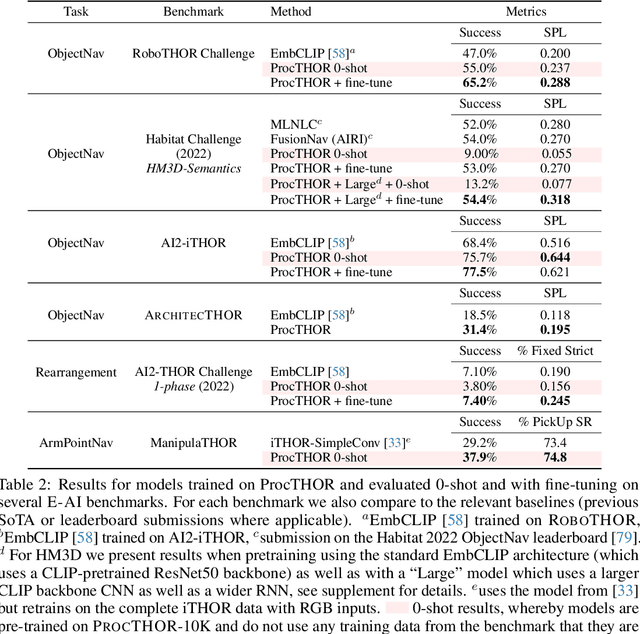
Massive datasets and high-capacity models have driven many recent advancements in computer vision and natural language understanding. This work presents a platform to enable similar success stories in Embodied AI. We propose ProcTHOR, a framework for procedural generation of Embodied AI environments. ProcTHOR enables us to sample arbitrarily large datasets of diverse, interactive, customizable, and performant virtual environments to train and evaluate embodied agents across navigation, interaction, and manipulation tasks. We demonstrate the power and potential of ProcTHOR via a sample of 10,000 generated houses and a simple neural model. Models trained using only RGB images on ProcTHOR, with no explicit mapping and no human task supervision produce state-of-the-art results across 6 embodied AI benchmarks for navigation, rearrangement, and arm manipulation, including the presently running Habitat 2022, AI2-THOR Rearrangement 2022, and RoboTHOR challenges. We also demonstrate strong 0-shot results on these benchmarks, via pre-training on ProcTHOR with no fine-tuning on the downstream benchmark, often beating previous state-of-the-art systems that access the downstream training data.
Matryoshka Representations for Adaptive Deployment
Jun 01, 2022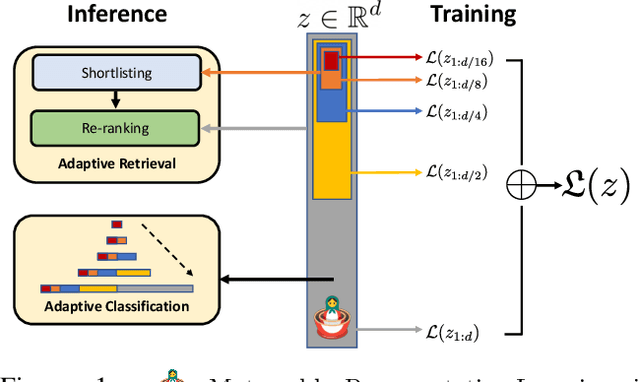
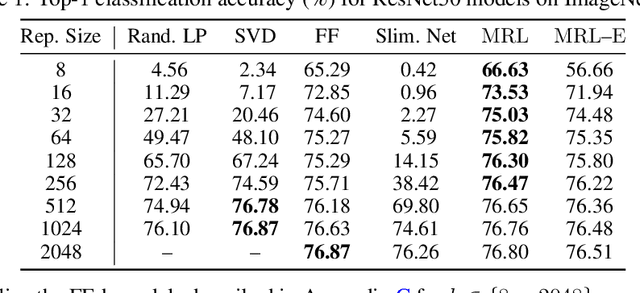
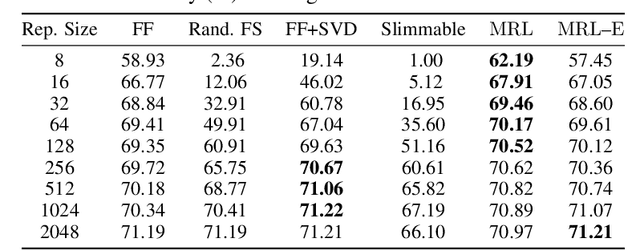
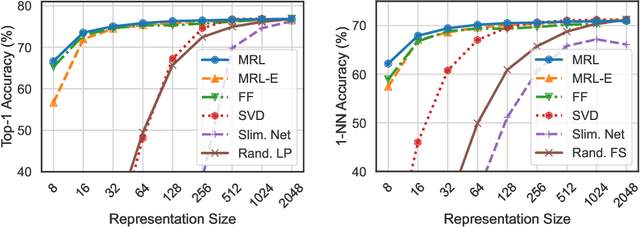
Learned representations are a central component in modern ML systems, serving a multitude of downstream tasks. When training such representations, it is often the case that computational and statistical constraints for each downstream task are unknown. In this context rigid, fixed capacity representations can be either over or under-accommodating to the task at hand. This leads us to ask: can we design a flexible representation that can adapt to multiple downstream tasks with varying computational resources? Our main contribution is Matryoshka Representation Learning (MRL) which encodes information at different granularities and allows a single embedding to adapt to the computational constraints of downstream tasks. MRL minimally modifies existing representation learning pipelines and imposes no additional cost during inference and deployment. MRL learns coarse-to-fine representations that are at least as accurate and rich as independently trained low-dimensional representations. The flexibility within the learned Matryoshka Representations offer: (a) up to 14x smaller embedding size for ImageNet-1K classification at the same level of accuracy; (b) up to 14x real-world speed-ups for large-scale retrieval on ImageNet-1K and 4K; and (c) up to 2% accuracy improvements for long-tail few-shot classification, all while being as robust as the original representations. Finally, we show that MRL extends seamlessly to web-scale datasets (ImageNet, JFT) across various modalities -- vision (ViT, ResNet), vision + language (ALIGN) and language (BERT). MRL code and pretrained models are open-sourced at https://github.com/RAIVNLab/MRL.
Object Manipulation via Visual Target Localization
Mar 15, 2022
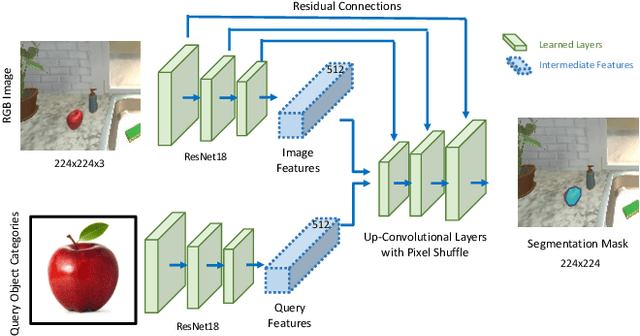
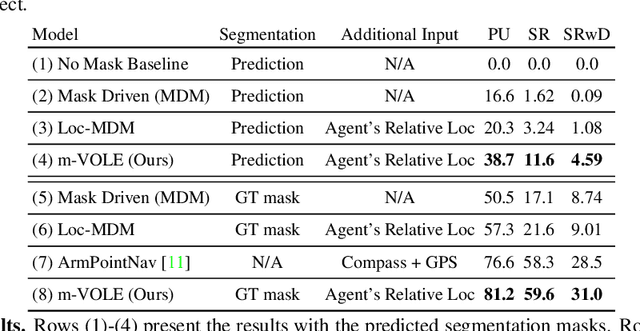
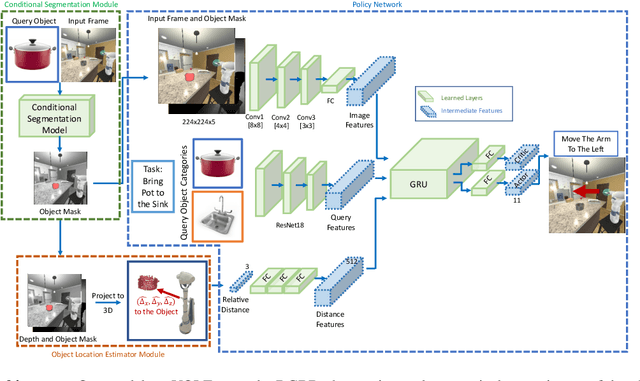
Object manipulation is a critical skill required for Embodied AI agents interacting with the world around them. Training agents to manipulate objects, poses many challenges. These include occlusion of the target object by the agent's arm, noisy object detection and localization, and the target frequently going out of view as the agent moves around in the scene. We propose Manipulation via Visual Object Location Estimation (m-VOLE), an approach that explores the environment in search for target objects, computes their 3D coordinates once they are located, and then continues to estimate their 3D locations even when the objects are not visible, thus robustly aiding the task of manipulating these objects throughout the episode. Our evaluations show a massive 3x improvement in success rate over a model that has access to the same sensory suite but is trained without the object location estimator, and our analysis shows that our agent is robust to noise in depth perception and agent localization. Importantly, our proposed approach relaxes several assumptions about idealized localization and perception that are commonly employed by recent works in embodied AI -- an important step towards training agents for object manipulation in the real world.