 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion Perception in Reinforcement Learning with Dynamic Objects
Jan 10, 2019
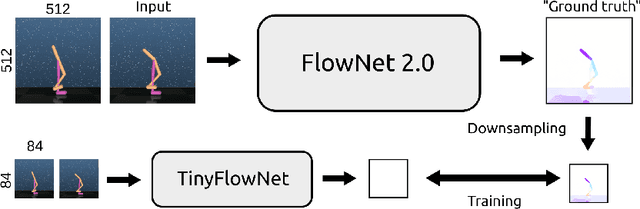
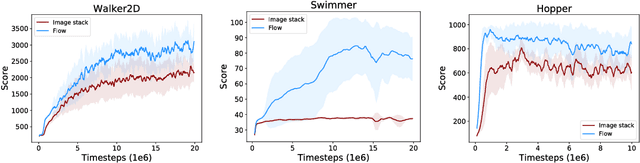

In dynamic environments, learned controllers are supposed to take motion into account when selecting the action to be taken. However, in existing reinforcement learning works motion is rarely treated explicitly; it is rather assumed that the controller learns the necessary motion representation from temporal stacks of frames implicitly. In this paper, we show that for continuous control tasks learning an explicit representation of motion improves the quality of the learned controller in dynamic scenarios. We demonstrate this on common benchmark tasks (Walker, Swimmer, Hopper), on target reaching and ball catching tasks with simulated robotic arms, and on a dynamic single ball juggling task. Moreover, we find that when equipped with an appropriate network architecture, the agent can, on some tasks, learn motion features also with pure reinforcement learning, without additional supervision. Further we find that using an image difference between the current and the previous frame as an additional input leads to better results than a temporal stack of frames.
Driving Policy Transfer via Modularity and Abstraction
Dec 13, 2018
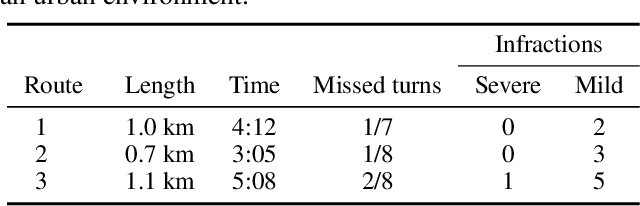
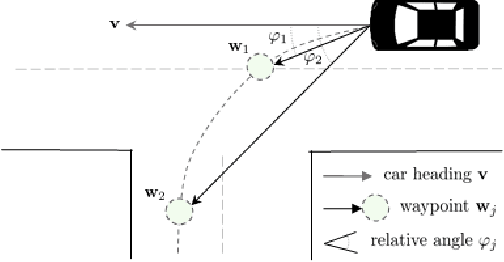
End-to-end approaches to autonomous driving have high sample complexity and are difficult to scale to realistic urban driving. Simulation can help end-to-end driving systems by providing a cheap, safe, and diverse training environment. Yet training driving policies in simulation brings up the problem of transferring such policies to the real world. We present an approach to transferring driving policies from simulation to reality via modularity and abstraction. Our approach is inspired by classic driving systems and aims to combine the benefits of modular architectures and end-to-end deep learning approaches. The key idea is to encapsulate the driving policy such that it is not directly exposed to raw perceptual input or low-level vehicle dynamics. We evaluate the presented approach in simulated urban environments and in the real world. In particular, we transfer a driving policy trained in simulation to a 1/5-scale robotic truck that is deployed in a variety of conditions, with no finetuning, on two continents. The supplementary video can be viewed at https://youtu.be/BrMDJqI6H5U
Unsupervised Learning of Shape and Pose with Differentiable Point Clouds
Oct 22, 2018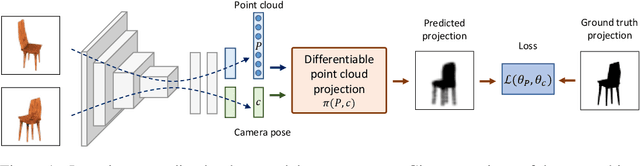

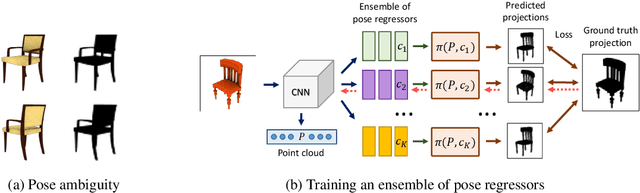
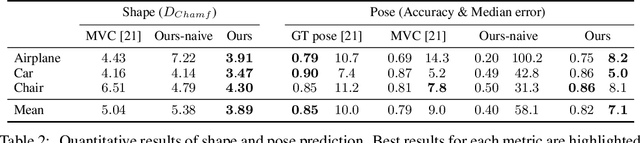
We address the problem of learning accurate 3D shape and camera pose from a collection of unlabeled category-specific images. We train a convolutional network to predict both the shape and the pose from a single image by minimizing the reprojection error: given several views of an object, the projections of the predicted shapes to the predicted camera poses should match the provided views. To deal with pose ambiguity, we introduce an ensemble of pose predictors which we then distill to a single "student" model. To allow for efficient learning of high-fidelity shapes, we represent the shapes by point clouds and devise a formulation allowing for differentiable projection of these. Our experiments show that the distilled ensemble of pose predictors learns to estimate the pose accurately, while the point cloud representation allows to predict detailed shape models. The supplementary video can be found at https://www.youtube.com/watch?v=LuIGovKeo60
Deep Drone Racing: Learning Agile Flight in Dynamic Environments
Oct 09, 2018


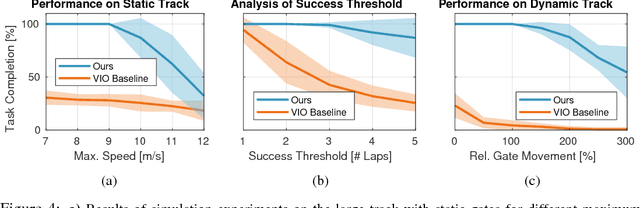
Autonomous agile flight brings up fundamental challenges in robotics, such as coping with unreliable state estimation, reacting optimally to dynamically changing environments, and coupling perception and action in real time under severe resource constraints. In this paper, we consider these challenges in the context of autonomous, vision-based drone racing in dynamic environments. Our approach combines a convolutional neural network (CNN) with a state-of-the-art path-planning and control system. The CNN directly maps raw images into a robust representation in the form of a waypoint and desired speed. This information is then used by the planner to generate a short, minimum-jerk trajectory segment and corresponding motor commands to reach the desired goal. We demonstrate our method in autonomous agile flight scenarios, in which a vision-based quadrotor traverses drone-racing tracks with possibly moving gates. Our method does not require any explicit map of the environment and runs fully onboard. We extensively test the precision and robustness of the approach in simulation and in the physical world. We also evaluate our method against state-of-the-art navigation approaches and professional human drone pilots.
* Accepted for publication in the Conference on Robotic Learning (CoRL) 2018, Zurich. 10 pages (+3 supplementary)
On Offline Evaluation of Vision-based Driving Models
Sep 13, 2018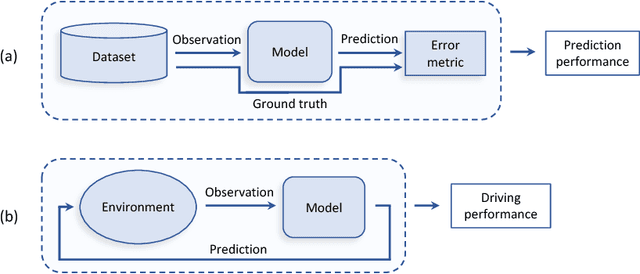
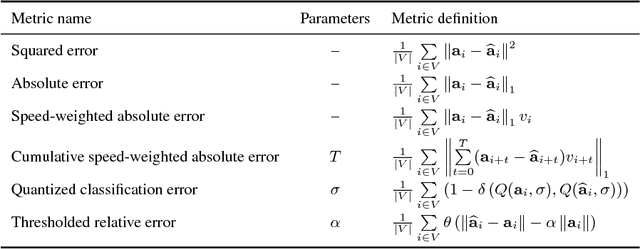
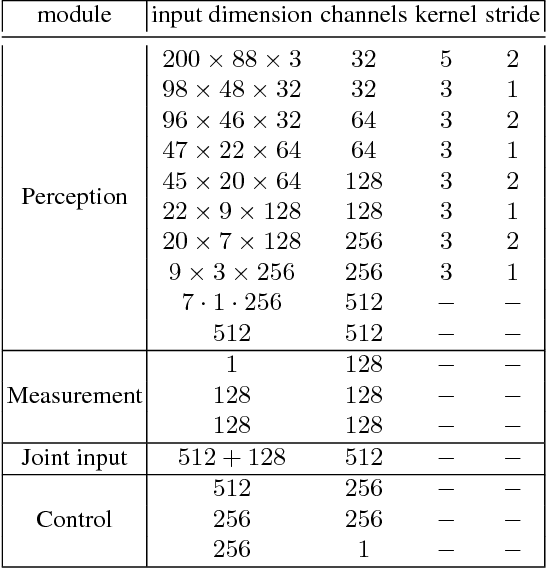
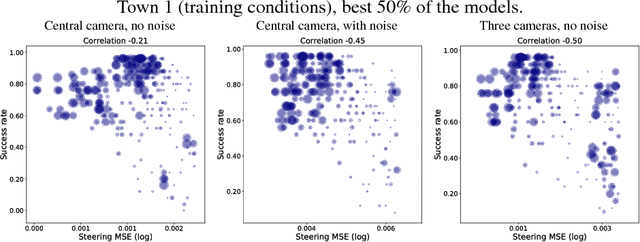
Autonomous driving models should ideally be evaluated by deploying them on a fleet of physical vehicles in the real world. Unfortunately, this approach is not practical for the vast majority of researchers. An attractive alternative is to evaluate models offline, on a pre-collected validation dataset with ground truth annotation. In this paper, we investigate the relation between various online and offline metrics for evaluation of autonomous driving models. We find that offline prediction error is not necessarily correlated with driving quality, and two models with identical prediction error can differ dramatically in their driving performance. We show that the correlation of offline evaluation with driving quality can be significantly improved by selecting an appropriate validation dataset and suitable offline metrics. The supplementary video can be viewed at https://www.youtube.com/watch?v=P8K8Z-iF0cY
Artistic style transfer for videos and spherical images
Aug 05, 2018



Manually re-drawing an image in a certain artistic style takes a professional artist a long time. Doing this for a video sequence single-handedly is beyond imagination. We present two computational approaches that transfer the style from one image (for example, a painting) to a whole video sequence. In our first approach, we adapt to videos the original image style transfer technique by Gatys et al. based on energy minimization. We introduce new ways of initialization and new loss functions to generate consistent and stable stylized video sequences even in cases with large motion and strong occlusion. Our second approach formulates video stylization as a learning problem. We propose a deep network architecture and training procedures that allow us to stylize arbitrary-length videos in a consistent and stable way, and nearly in real time. We show that the proposed methods clearly outperform simpler baselines both qualitatively and quantitatively. Finally, we propose a way to adapt these approaches also to 360 degree images and videos as they emerge with recent virtual reality hardware.
On Evaluation of Embodied Navigation Agents
Jul 18, 2018Skillful mobile operation in three-dimensional environments is a primary topic of study in Artificial Intelligence. The past two years have seen a surge of creative work on navigation. This creative output has produced a plethora of sometimes incompatible task definitions and evaluation protocols. To coordinate ongoing and future research in this area, we have convened a working group to study empirical methodology in navigation research. The present document summarizes the consensus recommendations of this working group. We discuss different problem statements and the role of generalization, present evaluation measures, and provide standard scenarios that can be used for benchmarking.
TD or not TD: Analyzing the Role of Temporal Differencing in Deep Reinforcement Learning
Jun 04, 2018

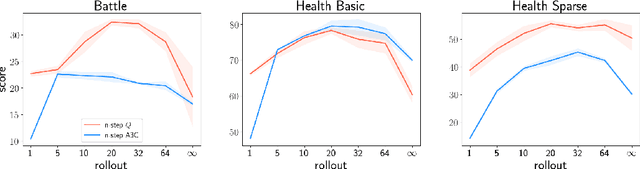
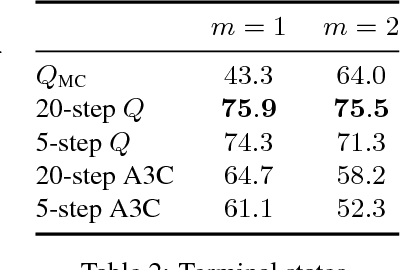
Our understanding of reinforcement learning (RL) has been shaped by theoretical and empirical results that were obtained decades ago using tabular representations and linear function approximators. These results suggest that RL methods that use temporal differencing (TD) are superior to direct Monte Carlo estimation (MC). How do these results hold up in deep RL, which deals with perceptually complex environments and deep nonlinear models? In this paper, we re-examine the role of TD in modern deep RL, using specially designed environments that control for specific factors that affect performance, such as reward sparsity, reward delay, and the perceptual complexity of the task. When comparing TD with infinite-horizon MC, we are able to reproduce classic results in modern settings. Yet we also find that finite-horizon MC is not inferior to TD, even when rewards are sparse or delayed. This makes MC a viable alternative to TD in deep RL.
What Makes Good Synthetic Training Data for Learning Disparity and Optical Flow Estimation?
Mar 22, 2018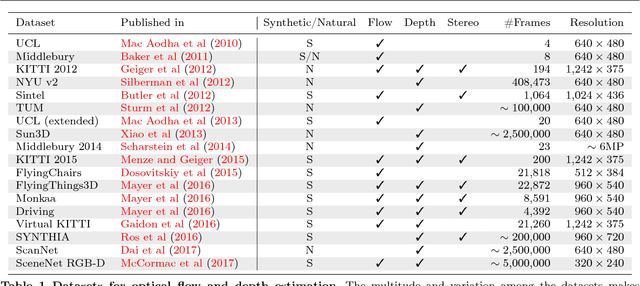

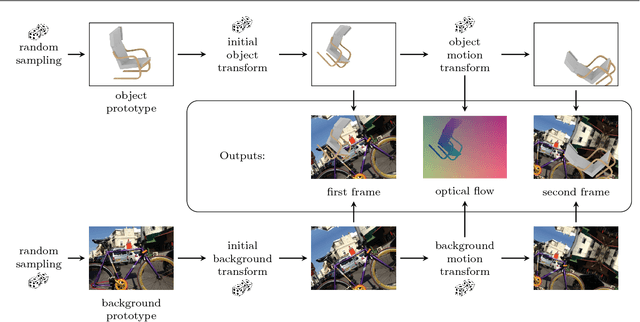
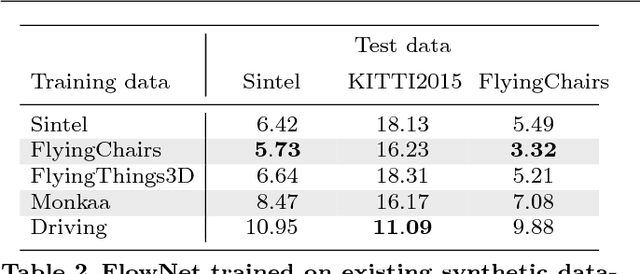
The finding that very large networks can be trained efficiently and reliably has led to a paradigm shift in computer vision from engineered solutions to learning formulations. As a result, the research challenge shifts from devising algorithms to creating suitable and abundant training data for supervised learning. How to efficiently create such training data? The dominant data acquisition method in visual recognition is based on web data and manual annotation. Yet, for many computer vision problems, such as stereo or optical flow estimation, this approach is not feasible because humans cannot manually enter a pixel-accurate flow field. In this paper, we promote the use of synthetically generated data for the purpose of training deep networks on such tasks.We suggest multiple ways to generate such data and evaluate the influence of dataset properties on the performance and generalization properties of the resulting networks. We also demonstrate the benefit of learning schedules that use different types of data at selected stages of the training process.
End-to-end Driving via Conditional Imitation Learning
Mar 02, 2018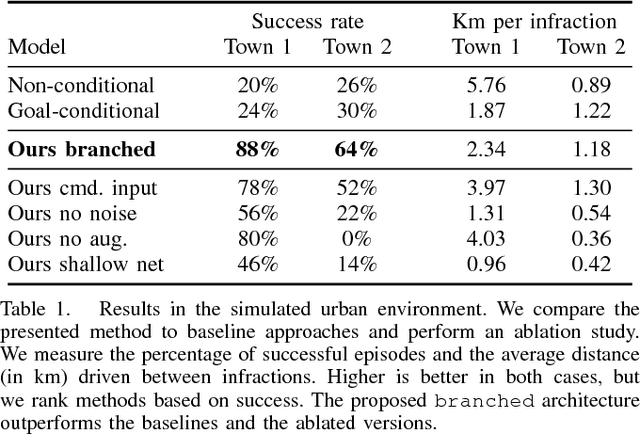
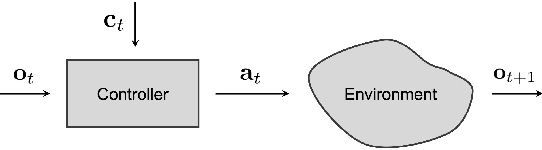
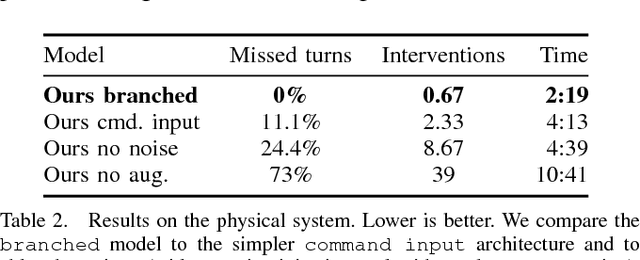
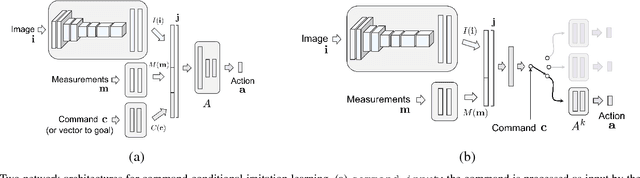
Deep networks trained on demonstrations of human driving have learned to follow roads and avoid obstacles. However, driving policies trained via imitation learning cannot be controlled at test time. A vehicle trained end-to-end to imitate an expert cannot be guided to take a specific turn at an upcoming intersection. This limits the utility of such systems. We propose to condition imitation learning on high-level command input. At test time, the learned driving policy functions as a chauffeur that handles sensorimotor coordination but continues to respond to navigational commands. We evaluate different architectures for conditional imitation learning in vision-based driving. We conduct experiments in realistic three-dimensional simulations of urban driving and on a 1/5 scale robotic truck that is trained to drive in a residential area. Both systems drive based on visual input yet remain responsive to high-level navigational commands. The supplementary video can be viewed at https://youtu.be/cFtnflNe5fM