 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGTransPDM: A Graph-embedded Transformer with Positional Decoupling for Pedestrian Crossing Intention Prediction
Sep 30, 2024



Understanding and predicting pedestrian crossing behavioral intention is crucial for autonomous vehicles driving safety. Nonetheless, challenges emerge when using promising images or environmental context masks to extract various factors for time-series network modeling, causing pre-processing errors or a loss in efficiency. Typically, pedestrian positions captured by onboard cameras are often distorted and do not accurately reflect their actual movements. To address these issues, GTransPDM -- a Graph-embedded Transformer with a Position Decoupling Module -- was developed for pedestrian crossing intention prediction by leveraging multi-modal features. First, a positional decoupling module was proposed to decompose the pedestrian lateral movement and simulate depth variations in the image view. Then, a graph-embedded Transformer was designed to capture the spatial-temporal dynamics of human pose skeletons, integrating essential factors such as position, skeleton, and ego-vehicle motion. Experimental results indicate that the proposed method achieves 92% accuracy on the PIE dataset and 87% accuracy on the JAAD dataset, with a processing speed of 0.05ms. It outperforms the state-of-the-art in comparison.
Divide, Ensemble and Conquer: The Last Mile on Unsupervised Domain Adaptation for On-Board Semantic Segmentation
Jun 27, 2024



The last mile of unsupervised domain adaptation (UDA) for semantic segmentation is the challenge of solving the syn-to-real domain gap. Recent UDA methods have progressed significantly, yet they often rely on strategies customized for synthetic single-source datasets (e.g., GTA5), which limits their generalisation to multi-source datasets. Conversely, synthetic multi-source datasets hold promise for advancing the last mile of UDA but remain underutilized in current research. Thus, we propose DEC, a flexible UDA framework for multi-source datasets. Following a divide-and-conquer strategy, DEC simplifies the task by categorizing semantic classes, training models for each category, and fusing their outputs by an ensemble model trained exclusively on synthetic datasets to obtain the final segmentation mask. DEC can integrate with existing UDA methods, achieving state-of-the-art performance on Cityscapes, BDD100K, and Mapillary Vistas, significantly narrowing the syn-to-real domain gap.
Back to the Color: Learning Depth to Specific Color Transformation for Unsupervised Depth Estimation
Jun 11, 2024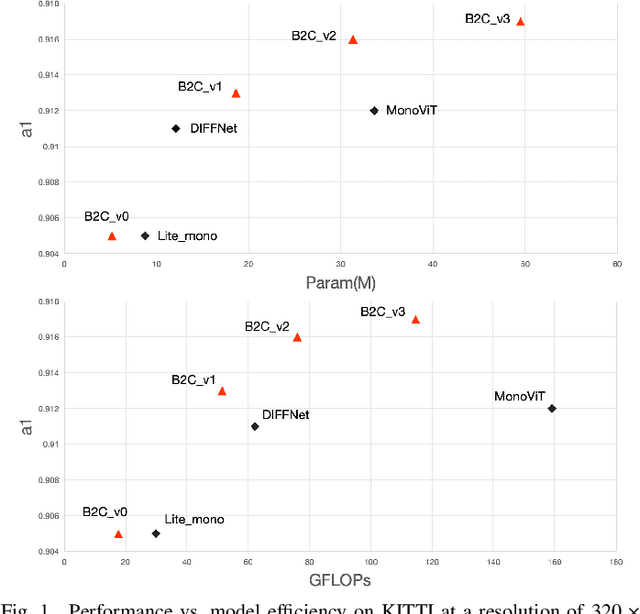



Virtual engines have the capability to generate dense depth maps for various synthetic scenes, making them invaluable for training depth estimation models. However, synthetic colors often exhibit significant discrepancies compared to real-world colors, thereby posing challenges for depth estimation in real-world scenes, particularly in complex and uncertain environments encountered in unsupervised monocular depth estimation tasks. To address this issue, we propose Back2Color, a framework that predicts realistic colors from depth utilizing a model trained on real-world data, thus facilitating the transformation of synthetic colors into real-world counterparts. Additionally, by employing the Syn-Real CutMix method for joint training with both real-world unsupervised and synthetic supervised depth samples, we achieve improved performance in monocular depth estimation for real-world scenes. Moreover, to comprehensively address the impact of non-rigid motions on depth estimation, we propose an auto-learning uncertainty temporal-spatial fusion method (Auto-UTSF), which integrates the benefits of unsupervised learning in both temporal and spatial dimensions. Furthermore, we design a depth estimation network (VADepth) based on the Vision Attention Network. Our Back2Color framework demonstrates state-of-the-art performance, as evidenced by improvements in performance metrics and the production of fine-grained details in our predictions, particularly on challenging datasets such as Cityscapes for unsupervised depth estimation.
Synth-to-Real Unsupervised Domain Adaptation for Instance Segmentation
May 15, 2024Unsupervised Domain Adaptation (UDA) aims to transfer knowledge learned from a labeled source domain to an unlabeled target domain. While UDA methods for synthetic to real-world domains (synth-to-real) show remarkable performance in tasks such as semantic segmentation and object detection, very few were proposed for the instance segmentation task. In this paper, we introduce UDA4Inst, a model of synth-to-real UDA for instance segmentation in autonomous driving. We propose a novel cross-domain bidirectional data mixing method at the instance level to fully leverage the data from both source and target domains. Rare-class balancing and category module training are also employed to further improve the performance. It is worth noting that we are the first to demonstrate results on two new synth-to-real instance segmentation benchmarks, with 39.0 mAP on UrbanSyn->Cityscapes and 35.7 mAP on Synscapes->Cityscapes. UDA4Inst also achieves the state-of-the-art result on SYNTHIA->Cityscapes with 31.3 mAP, +15.6 higher than the latest approach. Our code will be released.
Guiding Attention in End-to-End Driving Models
Apr 30, 2024



Vision-based end-to-end driving models trained by imitation learning can lead to affordable solutions for autonomous driving. However, training these well-performing models usually requires a huge amount of data, while still lacking explicit and intuitive activation maps to reveal the inner workings of these models while driving. In this paper, we study how to guide the attention of these models to improve their driving quality and obtain more intuitive activation maps by adding a loss term during training using salient semantic maps. In contrast to previous work, our method does not require these salient semantic maps to be available during testing time, as well as removing the need to modify the model's architecture to which it is applied. We perform tests using perfect and noisy salient semantic maps with encouraging results in both, the latter of which is inspired by possible errors encountered with real data. Using CIL++ as a representative state-of-the-art model and the CARLA simulator with its standard benchmarks, we conduct experiments that show the effectiveness of our method in training better autonomous driving models, especially when data and computational resources are scarce.
All for One, and One for All: UrbanSyn Dataset, the third Musketeer of Synthetic Driving Scenes
Dec 19, 2023



We introduce UrbanSyn, a photorealistic dataset acquired through semi-procedurally generated synthetic urban driving scenarios. Developed using high-quality geometry and materials, UrbanSyn provides pixel-level ground truth, including depth, semantic segmentation, and instance segmentation with object bounding boxes and occlusion degree. It complements GTAV and Synscapes datasets to form what we coin as the 'Three Musketeers'. We demonstrate the value of the Three Musketeers in unsupervised domain adaptation for image semantic segmentation. Results on real-world datasets, Cityscapes, Mapillary Vistas, and BDD100K, establish new benchmarks, largely attributed to UrbanSyn. We make UrbanSyn openly and freely accessible (www.urbansyn.org).
CARLA-BSP: a simulated dataset with pedestrians
Apr 29, 2023We present a sample dataset featuring pedestrians generated using the ARCANE framework, a new framework for generating datasets in CARLA (0.9.13). We provide use cases for pedestrian detection, autoencoding, pose estimation, and pose lifting. We also showcase baseline results. For more information, visit https://project-arcane.eu/.
Co-Training for Unsupervised Domain Adaptation of Semantic Segmentation Models
May 31, 2022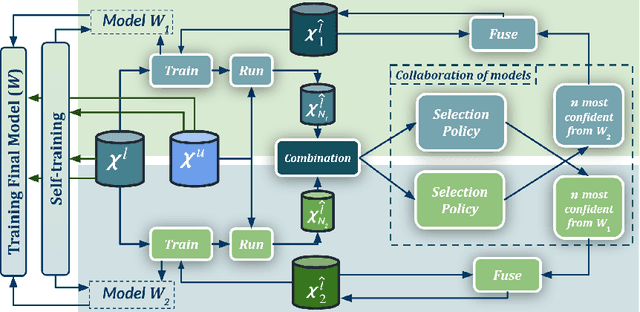

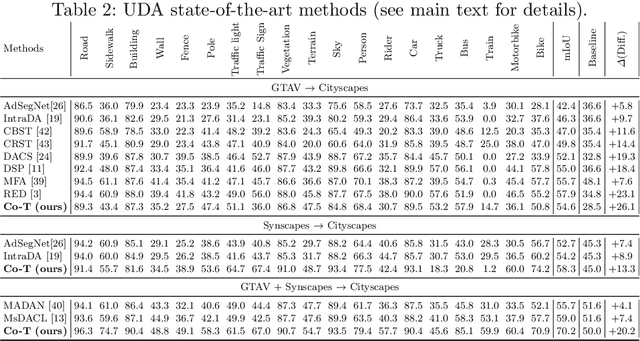
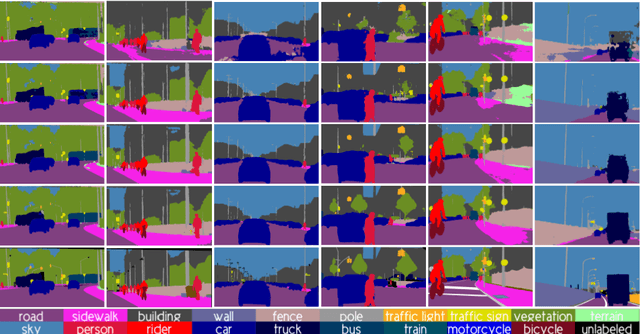
Semantic image segmentation is addressed by training deep models. Since supervised training draws to a curse of human-based image labeling, using synthetic images with automatically generated ground truth together with unlabeled real-world images is a promising alternative. This implies to address an unsupervised domain adaptation (UDA) problem. In this paper, we proposed a new co-training process for synth-to-real UDA of semantic segmentation models. First, we design a self-training procedure which provides two initial models. Then, we keep training these models in a collaborative manner for obtaining the final model. The overall process treats the deep models as black boxes and drives their collaboration at the level of pseudo-labeled target images, {\ie}, neither modifying loss functions is required, nor explicit feature alignment. We test our proposal on standard synthetic and real-world datasets. Our co-training shows improvements of 15-20 percentage points of mIoU over baselines, so establishing new state-of-the-art results.
Co-training for Deep Object Detection: Comparing Single-modal and Multi-modal Approaches
Apr 23, 2021

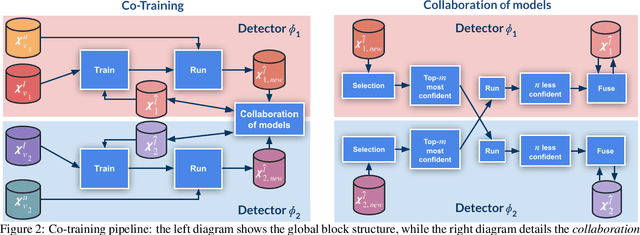
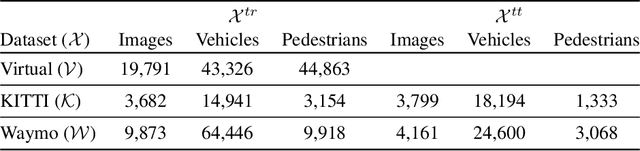
Top-performing computer vision models are powered by convolutional neural networks (CNNs). Training an accurate CNN highly depends on both the raw sensor data and their associated ground truth (GT). Collecting such GT is usually done through human labeling, which is time-consuming and does not scale as we wish. This data labeling bottleneck may be intensified due to domain shifts among image sensors, which could force per-sensor data labeling. In this paper, we focus on the use of co-training, a semi-supervised learning (SSL) method, for obtaining self-labeled object bounding boxes (BBs), i.e., the GT to train deep object detectors. In particular, we assess the goodness of multi-modal co-training by relying on two different views of an image, namely, appearance (RGB) and estimated depth (D). Moreover, we compare appearance-based single-modal co-training with multi-modal. Our results suggest that in a standard SSL setting (no domain shift, a few human-labeled data) and under virtual-to-real domain shift (many virtual-world labeled data, no human-labeled data) multi-modal co-training outperforms single-modal. In the latter case, by performing GAN-based domain translation both co-training modalities are on pair; at least, when using an off-the-shelf depth estimation model not specifically trained on the translated images.
Monocular Depth Estimation through Virtual-world Supervision and Real-world SfM Self-Supervision
Mar 22, 2021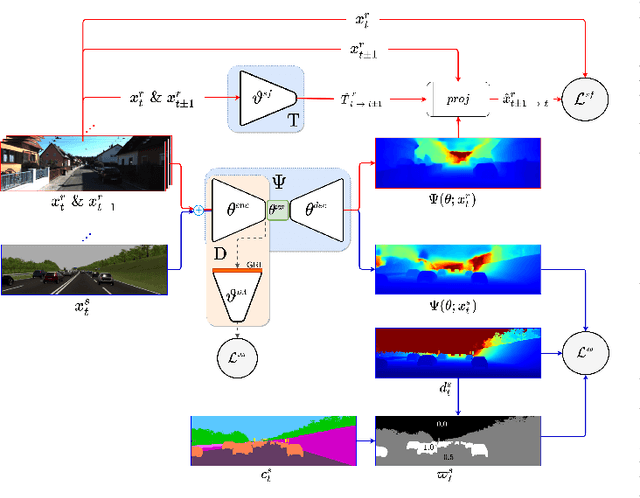
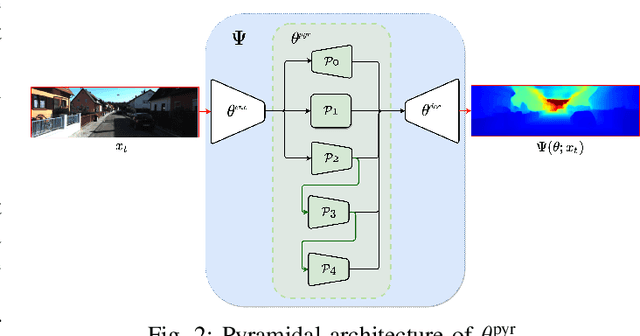
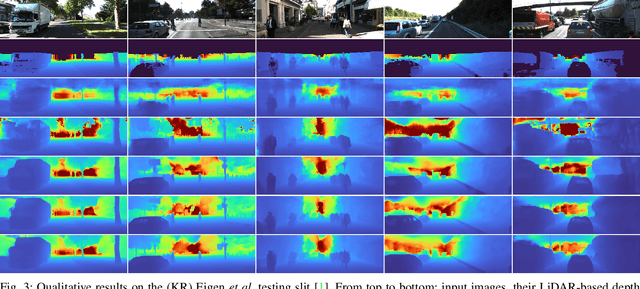
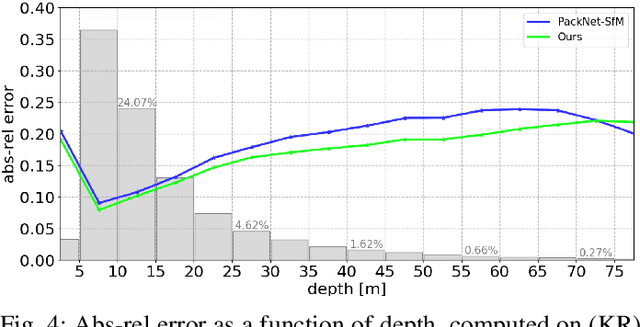
Depth information is essential for on-board perception in autonomous driving and driver assistance. Monocular depth estimation (MDE) is very appealing since it allows for appearance and depth being on direct pixelwise correspondence without further calibration. Best MDE models are based on Convolutional Neural Networks (CNNs) trained in a supervised manner, i.e., assuming pixelwise ground truth (GT). Usually, this GT is acquired at training time through a calibrated multi-modal suite of sensors. However, also using only a monocular system at training time is cheaper and more scalable. This is possible by relying on structure-from-motion (SfM) principles to generate self-supervision. Nevertheless, problems of camouflaged objects, visibility changes, static-camera intervals, textureless areas, and scale ambiguity, diminish the usefulness of such self-supervision. In this paper, we perform monocular depth estimation by virtual-world supervision (MonoDEVS) and real-world SfM self-supervision. We compensate the SfM self-supervision limitations by leveraging virtual-world images with accurate semantic and depth supervision and addressing the virtual-to-real domain gap. Our MonoDEVSNet outperforms previous MDE CNNs trained on monocular and even stereo sequences.