 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRL-DARTS: Differentiable Architecture Search for Reinforcement Learning
Jun 04, 2021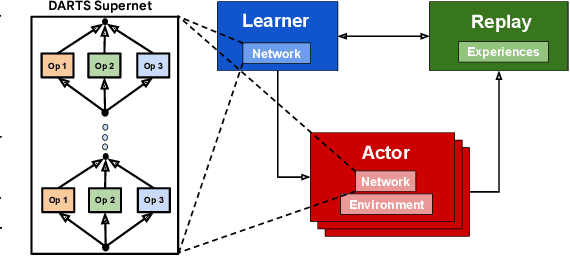
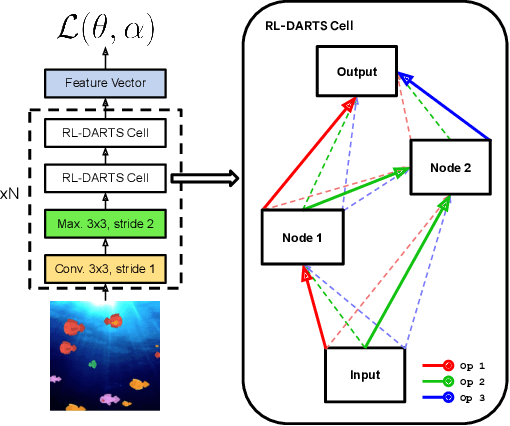
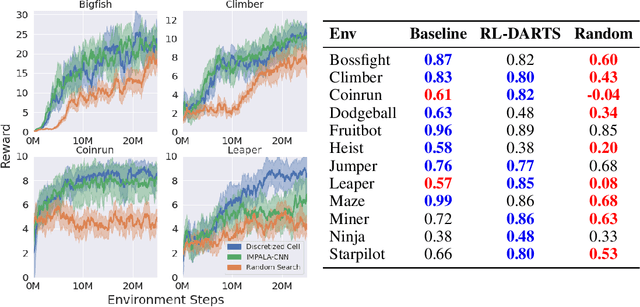
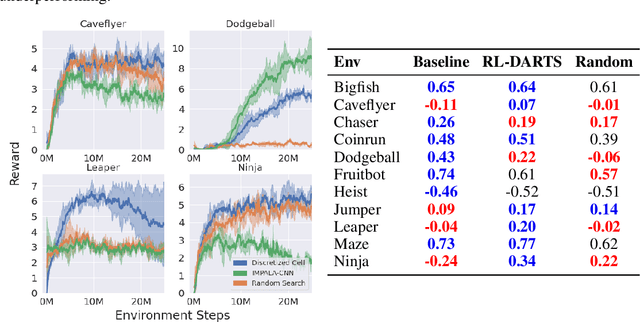
We introduce RL-DARTS, one of the first applications of Differentiable Architecture Search (DARTS) in reinforcement learning (RL) to search for convolutional cells, applied to the Procgen benchmark. We outline the initial difficulties of applying neural architecture search techniques in RL, and demonstrate that by simply replacing the image encoder with a DARTS supernet, our search method is sample-efficient, requires minimal extra compute resources, and is also compatible with off-policy and on-policy RL algorithms, needing only minor changes in preexisting code. Surprisingly, we find that the supernet can be used as an actor for inference to generate replay data in standard RL training loops, and thus train end-to-end. Throughout this training process, we show that the supernet gradually learns better cells, leading to alternative architectures which can be highly competitive against manually designed policies, but also verify previous design choices for RL policies.
Joint Attention for Multi-Agent Coordination and Social Learning
Apr 15, 2021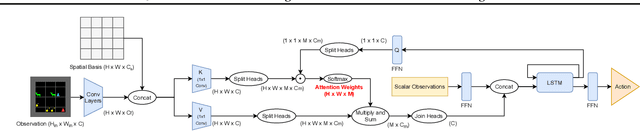
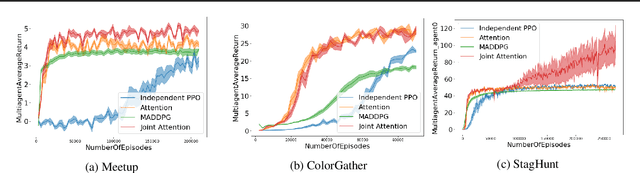
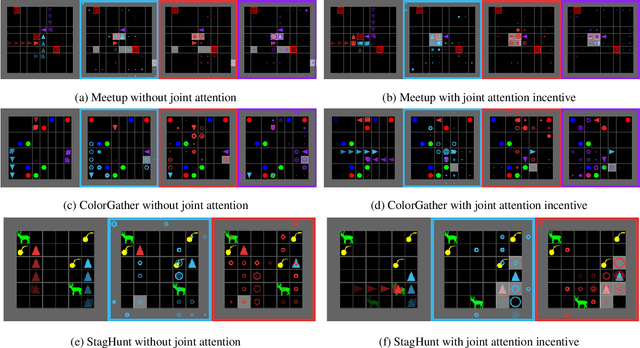
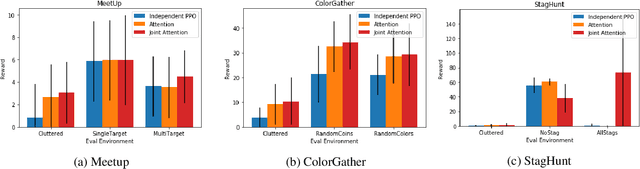
Joint attention - the ability to purposefully coordinate attention with another agent, and mutually attend to the same thing -- is a critical component of human social cognition. In this paper, we ask whether joint attention can be useful as a mechanism for improving multi-agent coordination and social learning. We first develop deep reinforcement learning (RL) agents with a recurrent visual attention architecture. We then train agents to minimize the difference between the attention weights that they apply to the environment at each timestep, and the attention of other agents. Our results show that this joint attention incentive improves agents' ability to solve difficult coordination tasks, by reducing the exponential cost of exploring the joint multi-agent action space. Joint attention leads to higher performance than a competitive centralized critic baseline across multiple environments. Further, we show that joint attention enhances agents' ability to learn from experts present in their environment, even when completing hard exploration tasks that do not require coordination. Taken together, these findings suggest that joint attention may be a useful inductive bias for multi-agent learning.
Adversarial Environment Generation for Learning to Navigate the Web
Mar 02, 2021
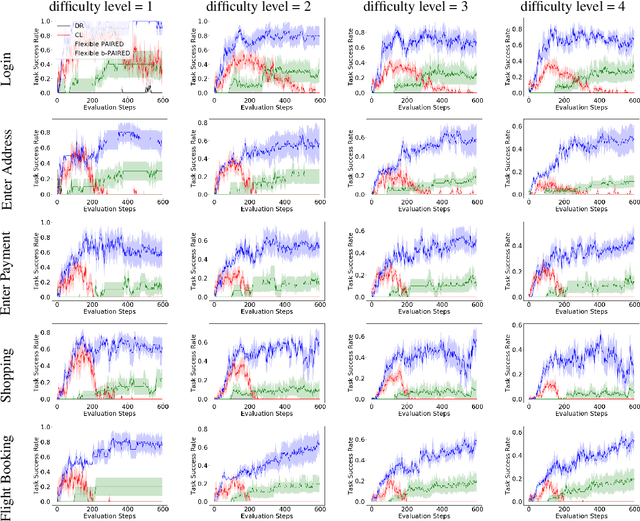
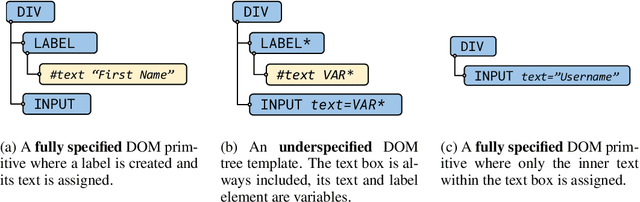
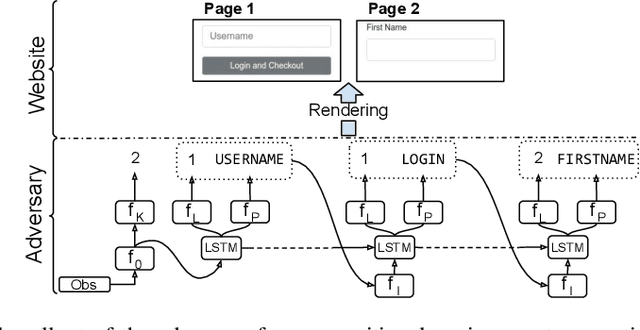
Learning to autonomously navigate the web is a difficult sequential decision making task. The state and action spaces are large and combinatorial in nature, and websites are dynamic environments consisting of several pages. One of the bottlenecks of training web navigation agents is providing a learnable curriculum of training environments that can cover the large variety of real-world websites. Therefore, we propose using Adversarial Environment Generation (AEG) to generate challenging web environments in which to train reinforcement learning (RL) agents. We provide a new benchmarking environment, gMiniWoB, which enables an RL adversary to use compositional primitives to learn to generate arbitrarily complex websites. To train the adversary, we propose a new technique for maximizing regret using the difference in the scores obtained by a pair of navigator agents. Our results show that our approach significantly outperforms prior methods for minimax regret AEG. The regret objective trains the adversary to design a curriculum of environments that are "just-the-right-challenge" for the navigator agents; our results show that over time, the adversary learns to generate increasingly complex web navigation tasks. The navigator agents trained with our technique learn to complete challenging, high-dimensional web navigation tasks, such as form filling, booking a flight etc. We show that the navigator agent trained with our proposed Flexible b-PAIRED technique significantly outperforms competitive automatic curriculum generation baselines -- including a state-of-the-art RL web navigation approach -- on a set of challenging unseen test environments, and achieves more than 80% success rate on some tasks.
Machine Learning-Based Automated Design Space Exploration for Autonomous Aerial Robots
Feb 05, 2021
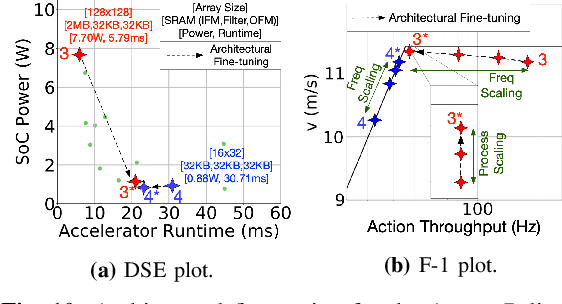
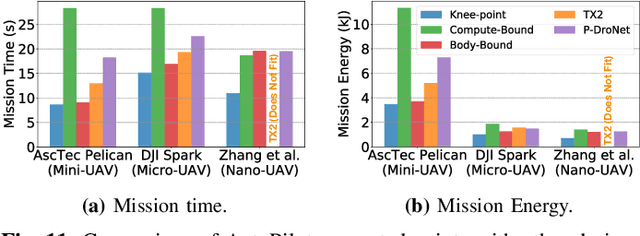

Building domain-specific architectures for autonomous aerial robots is challenging due to a lack of systematic methodology for designing onboard compute. We introduce a novel performance model called the F-1 roofline to help architects understand how to build a balanced computing system for autonomous aerial robots considering both its cyber (sensor rate, compute performance) and physical components (body-dynamics) that affect the performance of the machine. We use F-1 to characterize commonly used learning-based autonomy algorithms with onboard platforms to demonstrate the need for cyber-physical co-design. To navigate the cyber-physical design space automatically, we subsequently introduce AutoPilot. This push-button framework automates the co-design of cyber-physical components for aerial robots from a high-level specification guided by the F-1 model. AutoPilot uses Bayesian optimization to automatically co-design the autonomy algorithm and hardware accelerator while considering various cyber-physical parameters to generate an optimal design under different task level complexities for different robots and sensor framerates. As a result, designs generated by AutoPilot, on average, lower mission time up to 2x over baseline approaches, conserving battery energy.
Evolving Reinforcement Learning Algorithms
Jan 08, 2021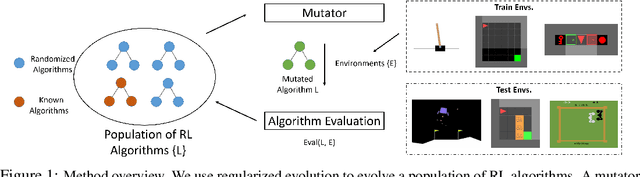
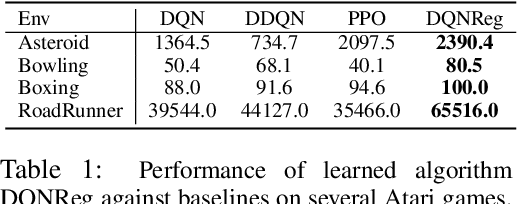
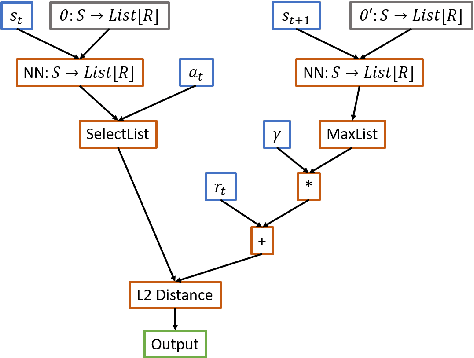
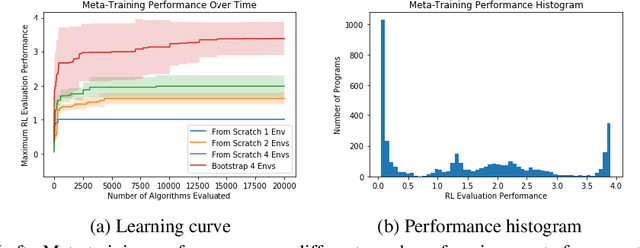
We propose a method for meta-learning reinforcement learning algorithms by searching over the space of computational graphs which compute the loss function for a value-based model-free RL agent to optimize. The learned algorithms are domain-agnostic and can generalize to new environments not seen during training. Our method can both learn from scratch and bootstrap off known existing algorithms, like DQN, enabling interpretable modifications which improve performance. Learning from scratch on simple classical control and gridworld tasks, our method rediscovers the temporal-difference (TD) algorithm. Bootstrapped from DQN, we highlight two learned algorithms which obtain good generalization performance over other classical control tasks, gridworld type tasks, and Atari games. The analysis of the learned algorithm behavior shows resemblance to recently proposed RL algorithms that address overestimation in value-based methods.
Visual Navigation Among Humans with Optimal Control as a Supervisor
Mar 20, 2020
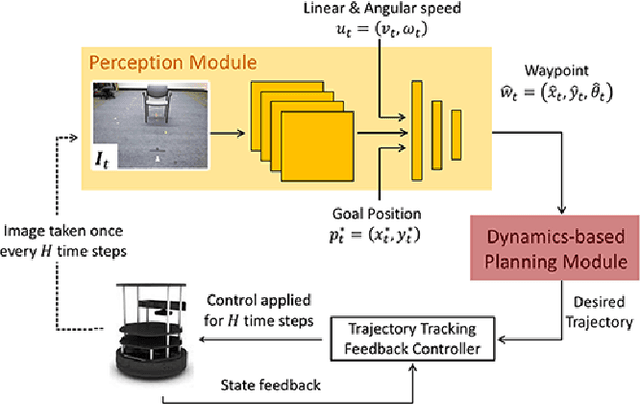
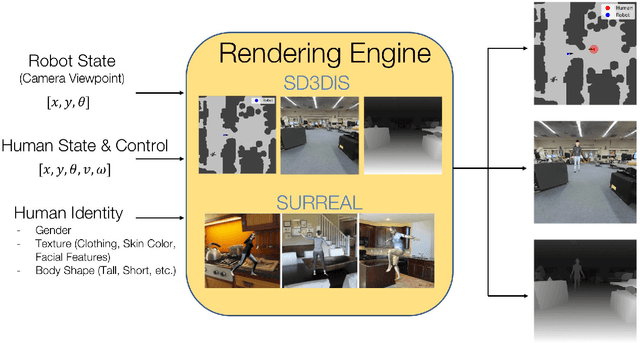

Real world navigation requires robots to operate in unfamiliar, dynamic environments, sharing spaces with humans. Navigating around humans is especially difficult because it requires predicting their future motion, which can be quite challenging. We propose a novel framework for navigation around humans which combines learning-based perception with model-based optimal control. Specifically, we train a Convolutional Neural Network (CNN)-based perception module which maps the robot's visual inputs to a waypoint, or next desired state. This waypoint is then input into planning and control modules which convey the robot safely and efficiently to the goal. To train the CNN we contribute a photo-realistic bench-marking dataset for autonomous robot navigation in the presence of humans. The CNN is trained using supervised learning on images rendered from our photo-realistic dataset. The proposed framework learns to anticipate and react to peoples' motion based only on a monocular RGB image, without explicitly predicting future human motion. Our method generalizes well to unseen buildings and humans in both simulation and real world environments. Furthermore, our experiments demonstrate that combining model-based control and learning leads to better and more data-efficient navigational behaviors as compared to a purely learning based approach. Videos describing our approach and experiments are available on the project website.
Cooperation without Coordination: Hierarchical Predictive Planning for Decentralized Multiagent Navigation
Mar 15, 2020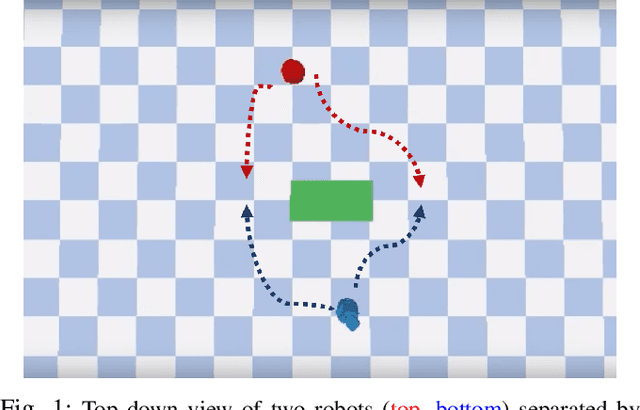
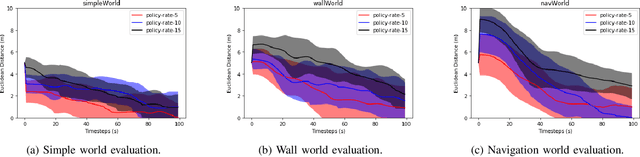
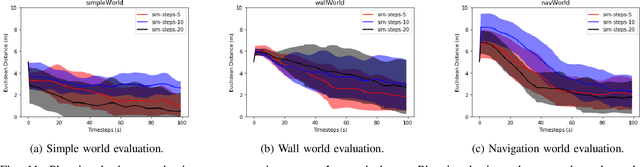
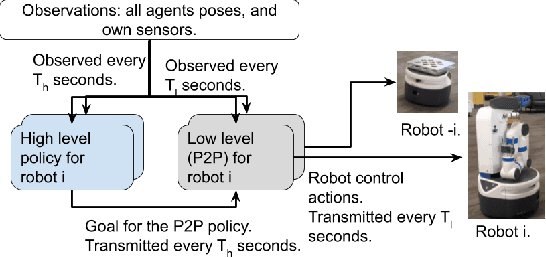
Decentralized multiagent planning raises many challenges, such as adaption to changing environments inexplicable by the agent's own behavior, coordination from noisy sensor inputs like lidar, cooperation without knowing other agents' intents. To address these challenges, we present hierarchical predictive planning (HPP) for decentralized multiagent navigation tasks. HPP learns prediction models for itself and other teammates, and uses the prediction models to propose and evaluate navigation goals that complete the cooperative task without explicit coordination. To learn the prediction models, HPP observes other agents' behavior and learns to maps own sensors to predicted locations of other agents. HPP then uses the cross-entropy method to iteratively propose, evaluate, and improve navigation goals, under assumption that all agents in the team share a common objective. HPP removes the need for a centralized operator (i.e. robots determine their own actions without coordinating their beliefs or plans) and can be trained and easily transferred to real world environments. The results show that HPP generalizes to new environments including real-world robot team. It is also 33x more sample efficient and performs better in complex environments compared to a baseline. The video and website for this paper can be found at https://youtu.be/-LqgfksqNH8 and https://sites.google.com/view/multiagent-hpp.
Neural Collision Clearance Estimator for Fast Robot Motion Planning
Oct 14, 2019

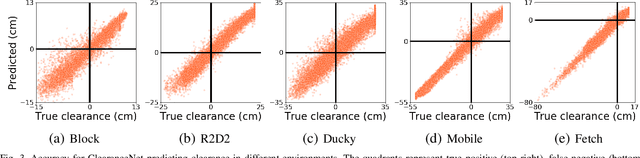
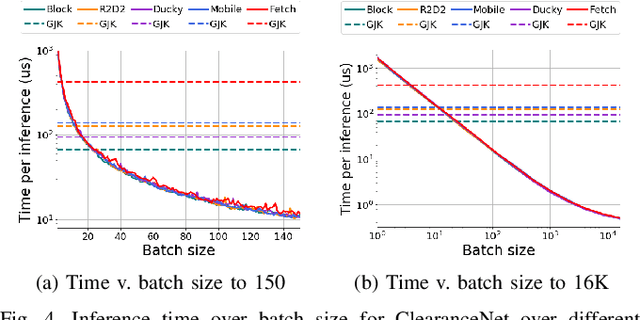
Collision checking is a well known bottleneck in sampling-based motion planning due to its computational expense and the large number of checks required. To alleviate this bottleneck, we present a fast neural network collision checking heuristic, ClearanceNet, and incorporate it within a planning algorithm, ClearanceNet-RRT (CN-RRT). ClearanceNet takes as input a robot pose and the location of all obstacles in the workspace and learns to predict the clearance, i.e., distance to nearest obstacle. CN-RRT then efficiently computes a motion plan by leveraging three key features of ClearanceNet. First, as neural network inference is massively parallel, CN-RRT explores the space via a parallel RRT, which expands nodes in parallel, allowing for thousands of collision checks at once. Second, CN-RRT adaptively relaxes its clearance threshold for more difficult problems. Third, to repair errors, CN-RRT shifts states towards higher clearance through a gradient-based approach that uses the analytic gradient of ClearanceNet. Once a path is found, any errors are repaired via RRT over the misclassified sections, thus maintaining the theoretical guarantees of sampling-based motion planning. We evaluate the collision checking speed, planning speed, and motion plan efficiency in configuration spaces with up to 30 degrees of freedom. The collision checking achieves speedups of more than two orders of magnitude over traditional collision detection methods. Sampling-based planning over multiple robotic arms in new environment configurations achieves speedups of up to 51% over a baseline, with paths up to 25% more efficient. Experiments on a physical Fetch robot reaching into shelves in a cluttered environment confirm the feasibility of this method on real robots.
Learned Critical Probabilistic Roadmaps for Robotic Motion Planning
Oct 08, 2019
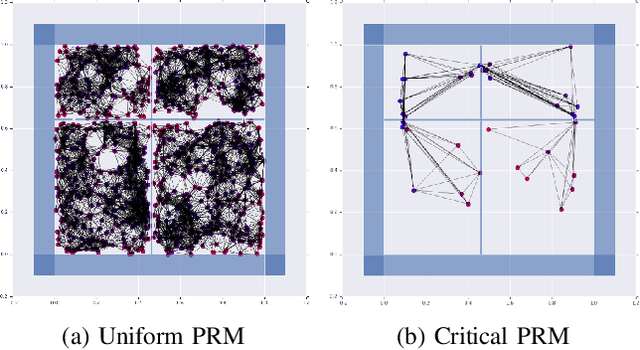
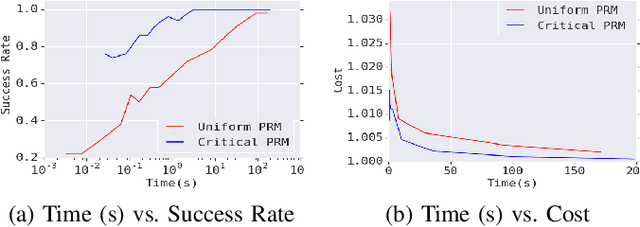
Sampling-based motion planning techniques have emerged as an efficient algorithmic paradigm for solving complex motion planning problems. These approaches use a set of probing samples to construct an implicit graph representation of the robot's state space, allowing arbitrarily accurate representations as the number of samples increases to infinity. In practice, however, solution trajectories only rely on a few critical states, often defined by structure in the state space (e.g., doorways). In this work we propose a general method to identify these critical states via graph-theoretic techniques (betweenness centrality) and learn to predict criticality from only local environment features. These states are then leveraged more heavily via global connections within a hierarchical graph, termed Critical Probabilistic Roadmaps. Critical PRMs are demonstrated to achieve up to three orders of magnitude improvement over uniform sampling, while preserving the guarantees and complexity of sampling-based motion planning. A video is available at https://youtu.be/AYoD-pGd9ms.
Quantized Reinforcement Learning (QUARL)
Oct 04, 2019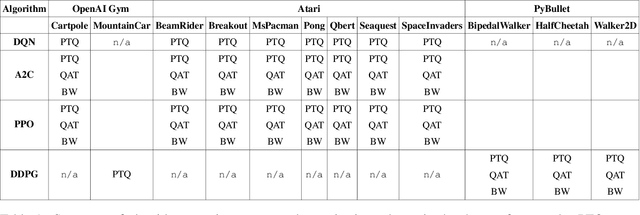
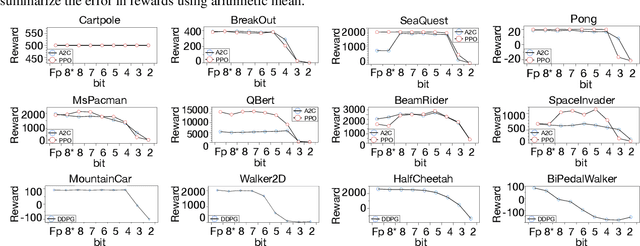
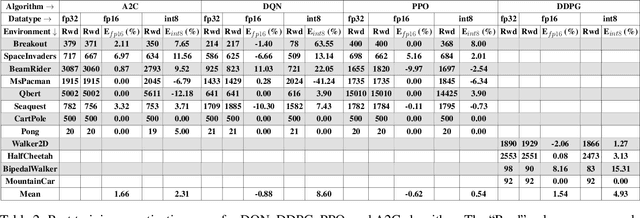
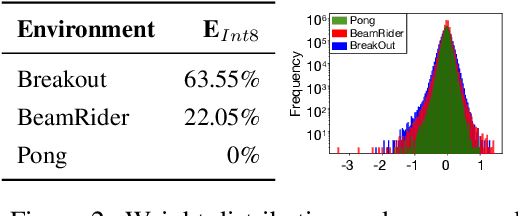
Recent work has shown that quantization can help reduce the memory, compute, and energy demands of deep neural networks without significantly harming their quality. However, whether these prior techniques, applied traditionally to image-based models, work with the same efficacy to the sequential decision making process in reinforcement learning remains an unanswered question. To address this void, we conduct the first comprehensive empirical study that quantifies the effects of quantization on various deep reinforcement learning policies with the intent to reduce their computational resource demands. We apply techniques such as post-training quantization and quantization aware training to a spectrum of reinforcement learning tasks (such as Pong, Breakout, BeamRider and more) and training algorithms (such as PPO, A2C, DDPG, and DQN). Across this spectrum of tasks and learning algorithms, we show that policies can be quantized to 6-8 bits of precision without loss of accuracy. We also show that certain tasks and reinforcement learning algorithms yield policies that are more difficult to quantize due to their effect of widening the models' distribution of weights and that quantization aware training consistently improves results over post-training quantization and oftentimes even over the full precision baseline. Finally, we demonstrate real-world applications of quantization for reinforcement learning. We use half-precision training to train a Pong model 50% faster, and we deploy a quantized reinforcement learning based navigation policy to an embedded system, achieving an 18$\times$ speedup and a 4$\times$ reduction in memory usage over an unquantized policy.