 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Kurdish (Sorani) Speech to Text: Presenting an Experimental Dataset
Dec 02, 2019
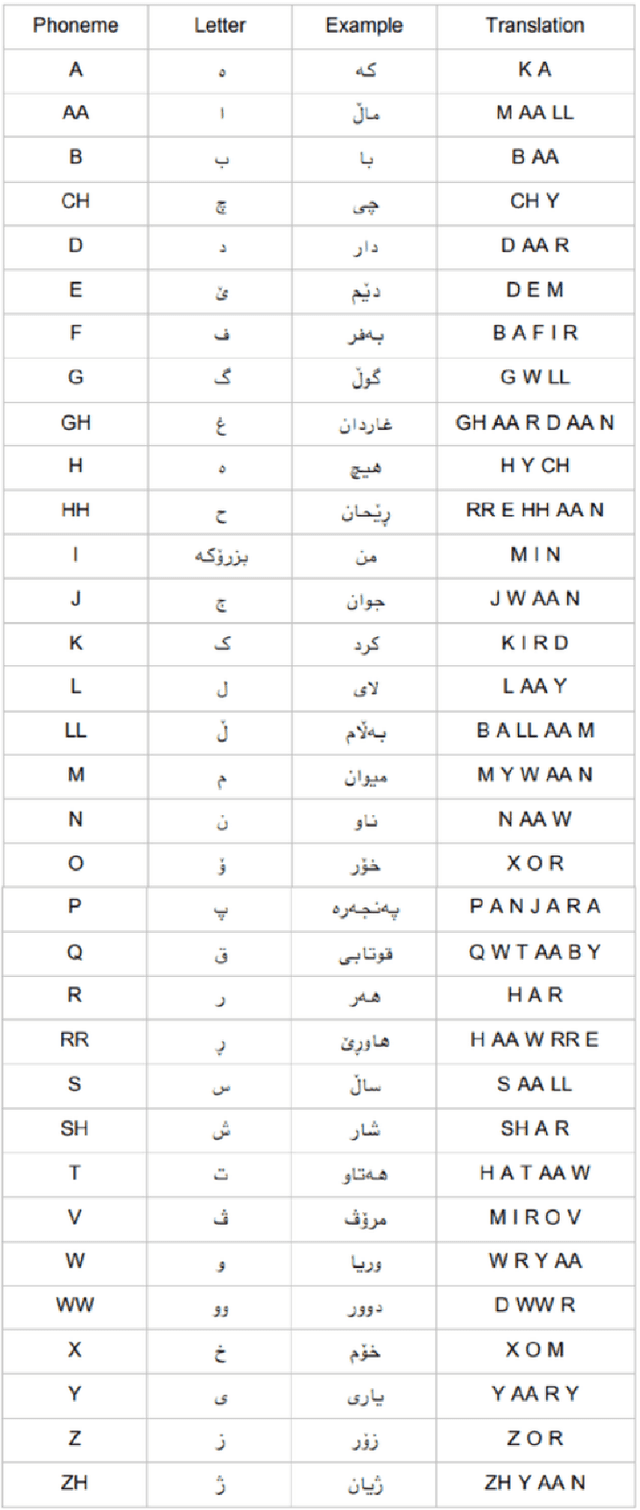
We present an experimental dataset, Basic Dataset for Sorani Kurdish Automatic Speech Recognition (BD-4SK-ASR), which we used in the first attempt in developing an automatic speech recognition for Sorani Kurdish. The objective of the project was to develop a system that automatically could recognize simple sentences based on the vocabulary which is used in grades one to three of the primary schools in the Kurdistan Region of Iraq. We used CMUSphinx as our experimental environment. We developed a dataset to train the system. The dataset is publicly available for non-commercial use under the CC BY-NC-SA 4.0 license.
Mockingjay: Unsupervised Speech Representation Learning with Deep Bidirectional Transformer Encoders
Oct 25, 2019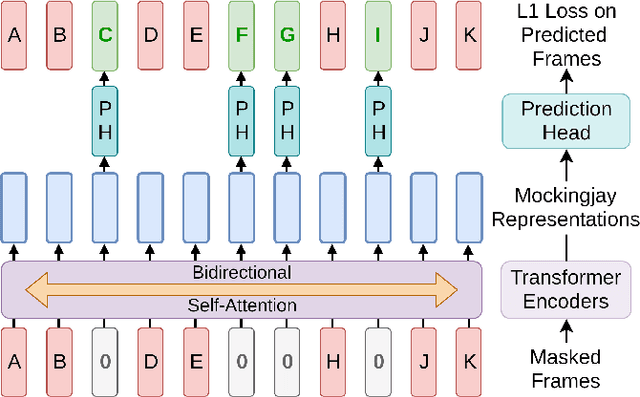
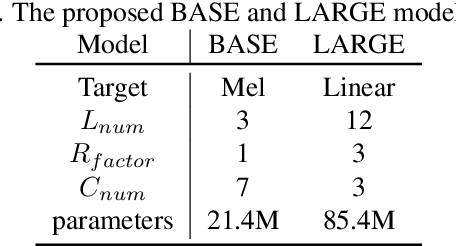
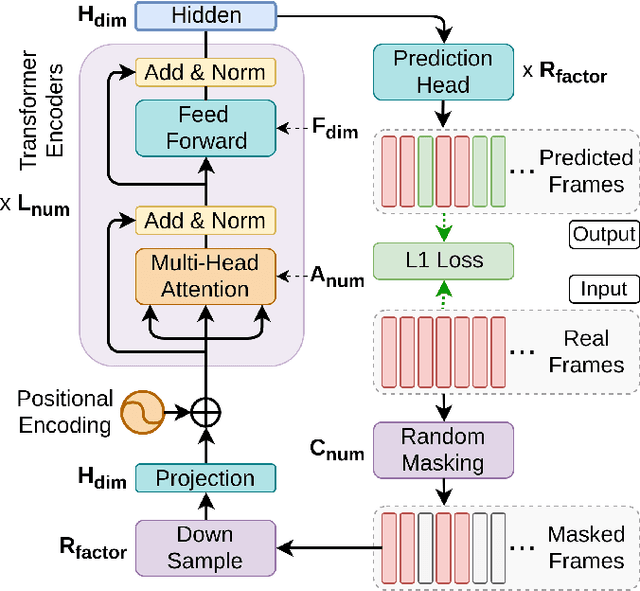
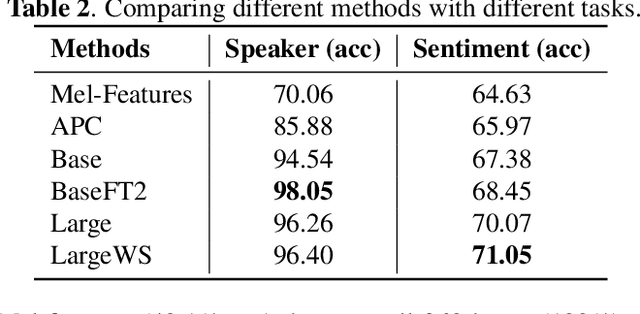
We present Mockingjay as a new speech representation learning approach, where bidirectional Transformer encoders are pre-trained on a large amount of unlabeled speech. Previous speech representation methods learn through conditioning on past frames and predicting information about future frames. Whereas Mockingjay is designed to predict the current frame through jointly conditioning on both past and future contexts. The Mockingjay representation improves performance for a wide range of downstream tasks, including phoneme classification, speaker recognition, and sentiment classification on spoken content, while outperforming other approaches. Mockingjay is empirically powerful and can be fine-tuned with downstream models, with only 2 epochs we further improve performance dramatically. In a low resource setting with only 0.1% of labeled data, we outperform the result of Mel-features that uses all 100% labeled data.
Generalization Ability of MOS Prediction Networks
Oct 18, 2021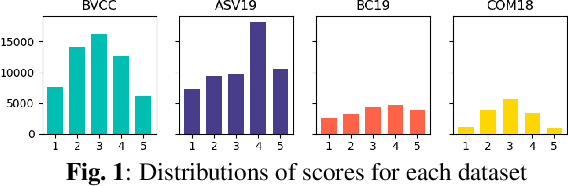
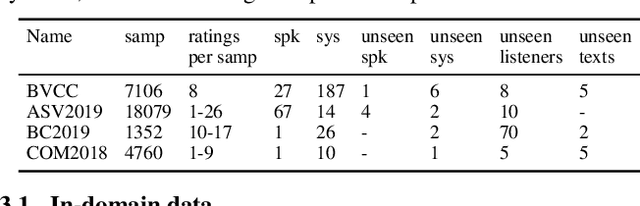
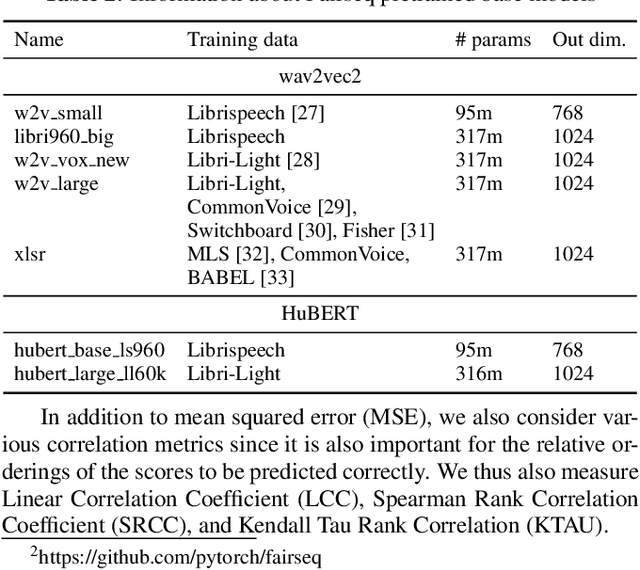
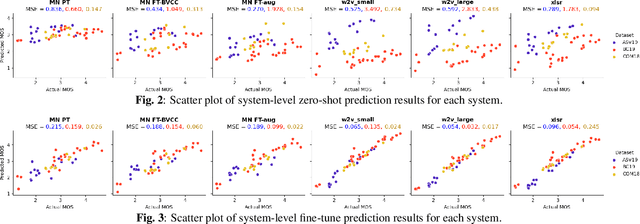
Automatic methods to predict listener opinions of synthesized speech remain elusive since listeners, systems being evaluated, characteristics of the speech, and even the instructions given and the rating scale all vary from test to test. While automatic predictors for metrics such as mean opinion score (MOS) can achieve high prediction accuracy on samples from the same test, they typically fail to generalize well to new listening test contexts. In this paper, using a variety of networks for MOS prediction including MOSNet and self-supervised speech models such as wav2vec2, we investigate their performance on data from different listening tests in both zero-shot and fine-tuned settings. We find that wav2vec2 models fine-tuned for MOS prediction have good generalization capability to out-of-domain data even for the most challenging case of utterance-level predictions in the zero-shot setting, and that fine-tuning to in-domain data can improve predictions. We also observe that unseen systems are especially challenging for MOS prediction models.
FastCorrect: Fast Error Correction with Edit Alignment for Automatic Speech Recognition
Jun 03, 2021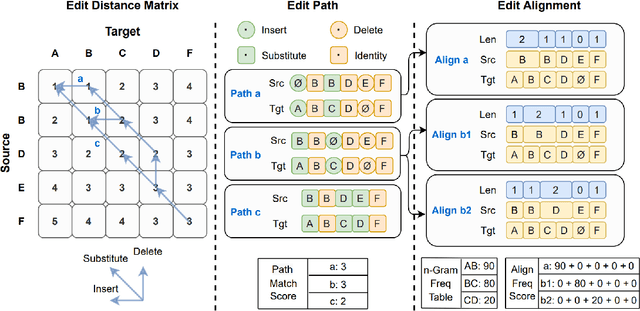
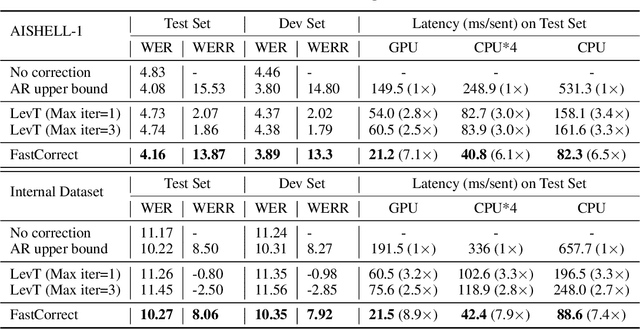
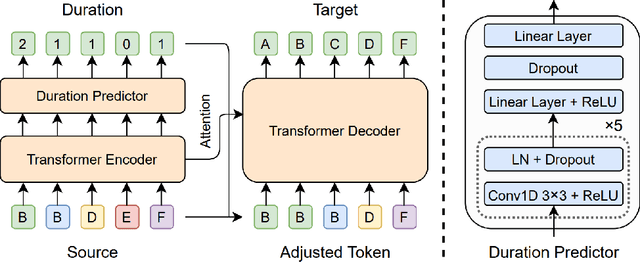
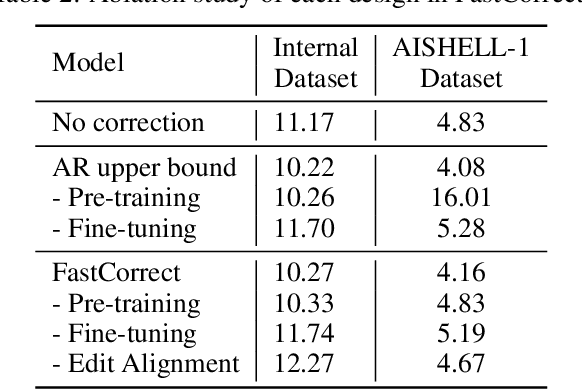
Error correction techniques have been used to refine the output sentences from automatic speech recognition (ASR) models and achieve a lower word error rate (WER) than original ASR outputs. Previous works usually use a sequence-to-sequence model to correct an ASR output sentence autoregressively, which causes large latency and cannot be deployed in online ASR services. A straightforward solution to reduce latency, inspired by non-autoregressive (NAR) neural machine translation, is to use an NAR sequence generation model for ASR error correction, which, however, comes at the cost of significantly increased ASR error rate. In this paper, observing distinctive error patterns and correction operations (i.e., insertion, deletion, and substitution) in ASR, we propose FastCorrect, a novel NAR error correction model based on edit alignment. In training, FastCorrect aligns each source token from an ASR output sentence to the target tokens from the corresponding ground-truth sentence based on the edit distance between the source and target sentences, and extracts the number of target tokens corresponding to each source token during edition/correction, which is then used to train a length predictor and to adjust the source tokens to match the length of the target sentence for parallel generation. In inference, the token number predicted by the length predictor is used to adjust the source tokens for target sequence generation. Experiments on the public AISHELL-1 dataset and an internal industrial-scale ASR dataset show the effectiveness of FastCorrect for ASR error correction: 1) it speeds up the inference by 6-9 times and maintains the accuracy (8-14% WER reduction) compared with the autoregressive correction model; and 2) it outperforms the popular NAR models adopted in neural machine translation and text edition by a large margin.
Advanced Long-context End-to-end Speech Recognition Using Context-expanded Transformers
Apr 19, 2021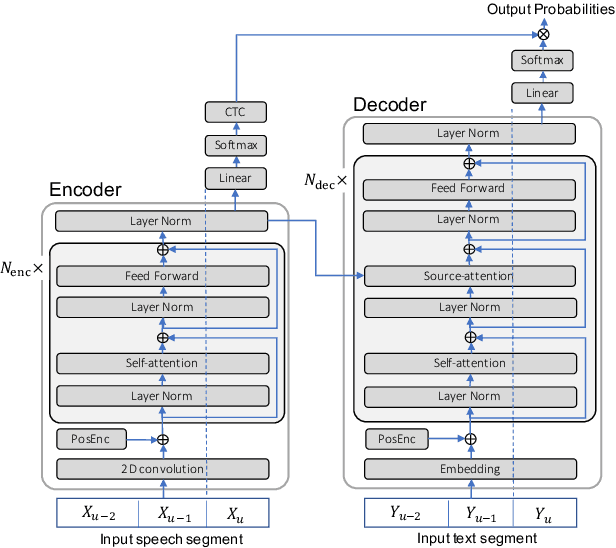
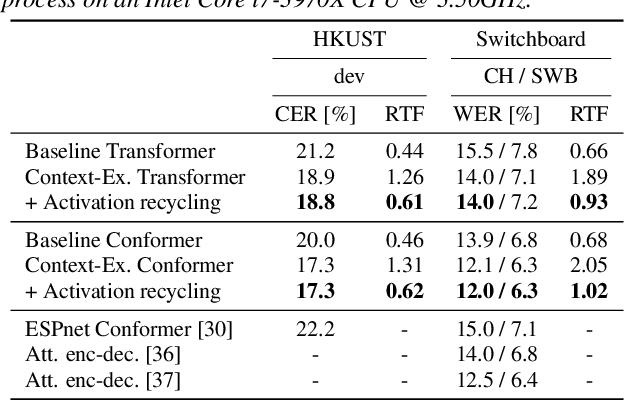
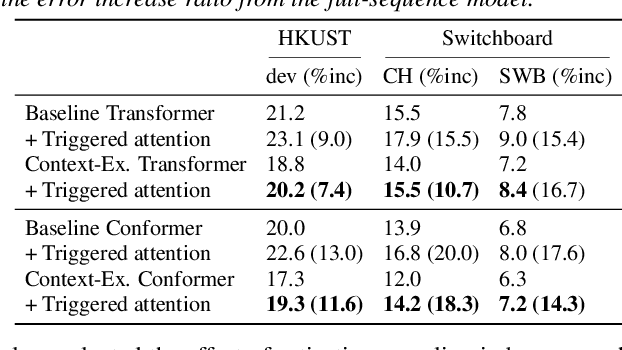
This paper addresses end-to-end automatic speech recognition (ASR) for long audio recordings such as lecture and conversational speeches. Most end-to-end ASR models are designed to recognize independent utterances, but contextual information (e.g., speaker or topic) over multiple utterances is known to be useful for ASR. In our prior work, we proposed a context-expanded Transformer that accepts multiple consecutive utterances at the same time and predicts an output sequence for the last utterance, achieving 5-15% relative error reduction from utterance-based baselines in lecture and conversational ASR benchmarks. Although the results have shown remarkable performance gain, there is still potential to further improve the model architecture and the decoding process. In this paper, we extend our prior work by (1) introducing the Conformer architecture to further improve the accuracy, (2) accelerating the decoding process with a novel activation recycling technique, and (3) enabling streaming decoding with triggered attention. We demonstrate that the extended Transformer provides state-of-the-art end-to-end ASR performance, obtaining a 17.3% character error rate for the HKUST dataset and 12.0%/6.3% word error rates for the Switchboard-300 Eval2000 CallHome/Switchboard test sets. The new decoding method reduces decoding time by more than 50% and further enables streaming ASR with limited accuracy degradation.
Towards Interpretable Multilingual Detection of Hate Speech against Immigrants and Women in Twitter at SemEval-2019 Task 5
Nov 26, 2020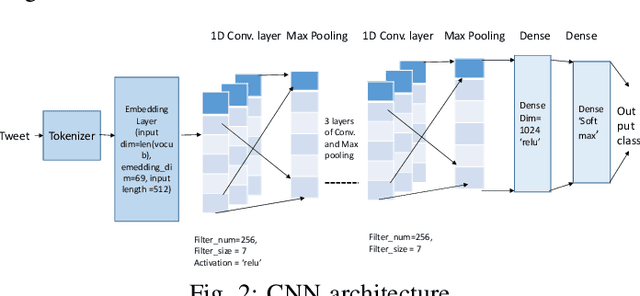
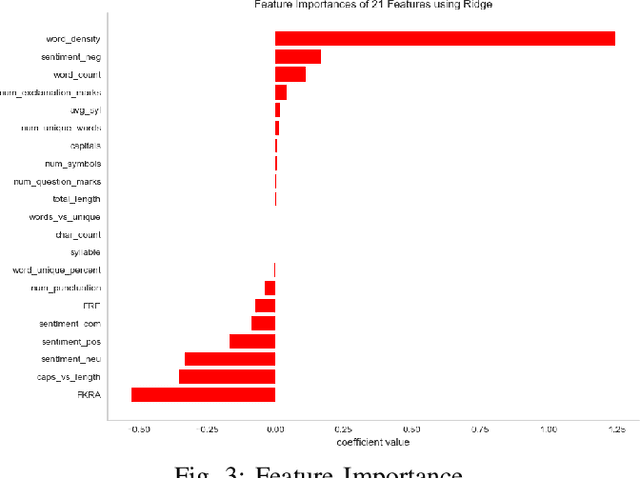
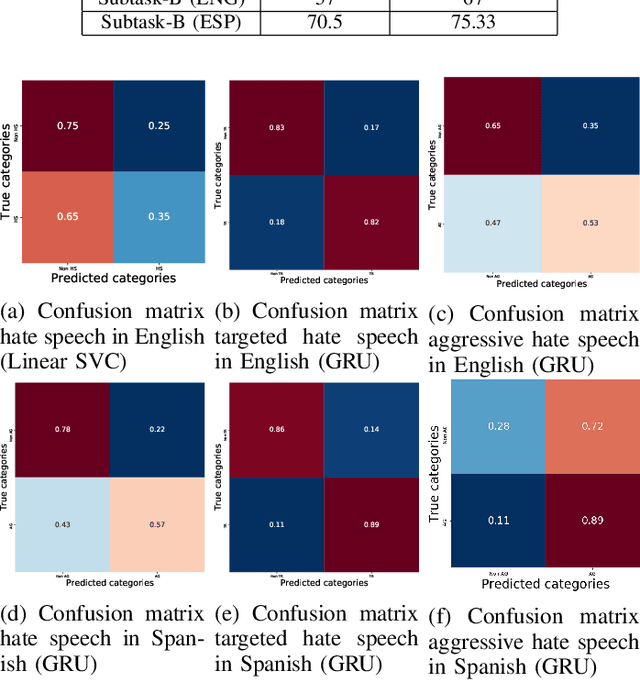
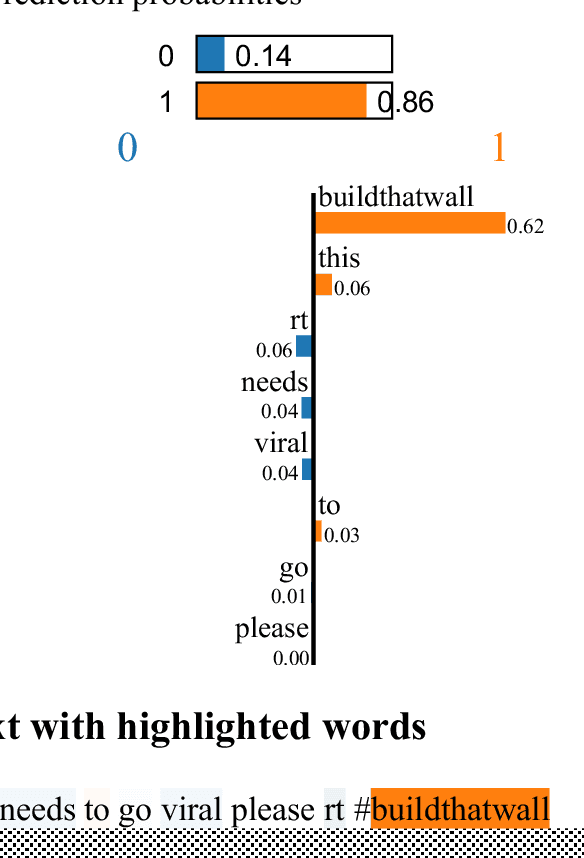
his paper describes our techniques to detect hate speech against women and immigrants on Twitter in multilingual contexts, particularly in English and Spanish. The challenge was designed by SemEval-2019 Task 5, where the participants need to design algorithms to detect hate speech in English and Spanish language with a given target (e.g., women or immigrants). Here, we have developed two deep neural networks (Bidirectional Gated Recurrent Unit (GRU), Character-level Convolutional Neural Network (CNN)), and one machine learning model by exploiting the linguistic features. Our proposed model obtained 57 and 75 F1 scores for Task A in English and Spanish language respectively. For Task B, the F1 scores are 67 for English and 75.33 for Spanish. In the case of task A (Spanish) and task B (both English and Spanish), the F1 scores are improved by 2, 10, and 5 points respectively. Besides, we present visually interpretable models that can address the generalizability issues of the custom-designed machine learning architecture by investigating the annotated dataset.
Efficient Non-Autoregressive GAN Voice Conversion using VQWav2vec Features and Dynamic Convolution
Mar 31, 2022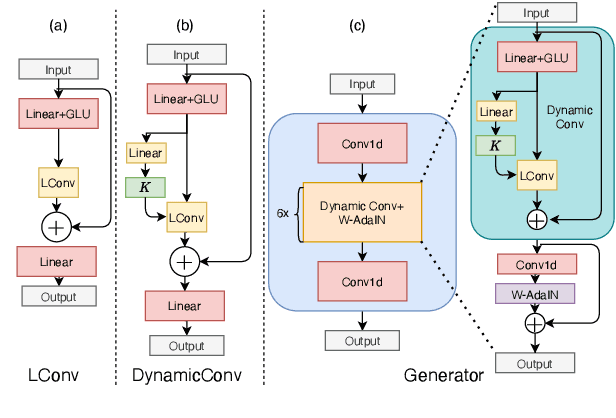
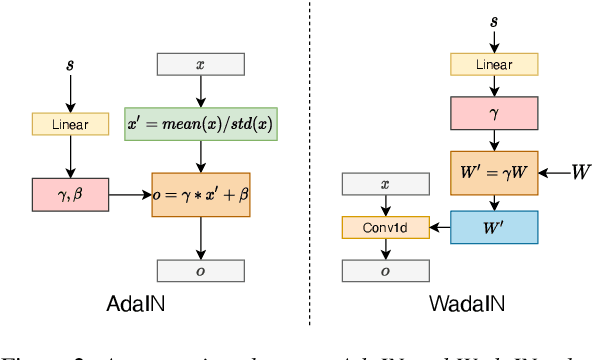
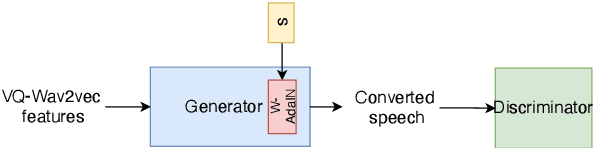

It was shown recently that a combination of ASR and TTS models yield highly competitive performance on standard voice conversion tasks such as the Voice Conversion Challenge 2020 (VCC2020). To obtain good performance both models require pretraining on large amounts of data, thereby obtaining large models that are potentially inefficient in use. In this work we present a model that is significantly smaller and thereby faster in processing while obtaining equivalent performance. To achieve this the proposed model, Dynamic-GAN-VC (DYGAN-VC), uses a non-autoregressive structure and makes use of vector quantised embeddings obtained from a VQWav2vec model. Furthermore dynamic convolution is introduced to improve speech content modeling while requiring a small number of parameters. Objective and subjective evaluation was performed using the VCC2020 task, yielding MOS scores of up to 3.86, and character error rates as low as 4.3\%. This was achieved with approximately half the number of model parameters, and up to 8 times faster decoding speed.
Language Models with Image Descriptors are Strong Few-Shot Video-Language Learners
May 24, 2022
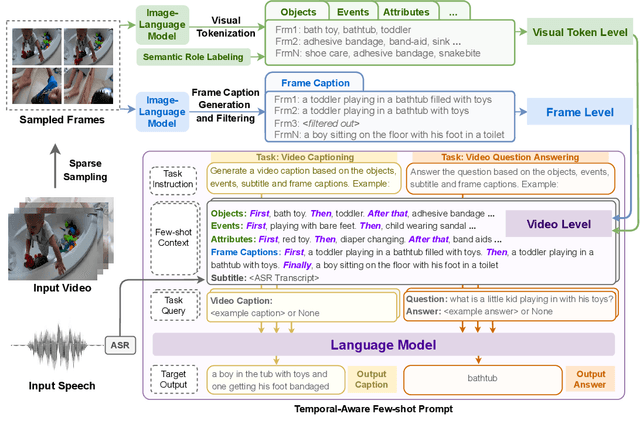
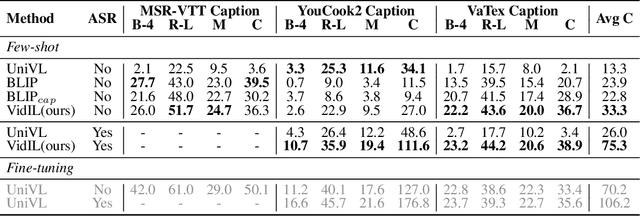

The goal of this work is to build flexible video-language models that can generalize to various video-to-text tasks from few examples, such as domain-specific captioning, question answering, and future event prediction. Existing few-shot video-language learners focus exclusively on the encoder, resulting in the absence of a video-to-text decoder to handle generative tasks. Video captioners have been pretrained on large-scale video-language datasets, but they rely heavily on finetuning and lack the ability to generate text for unseen tasks in a few-shot setting. We propose VidIL, a few-shot Video-language Learner via Image and Language models, which demonstrates strong performance on few-shot video-to-text tasks without the necessity of pretraining or finetuning on any video datasets. We use the image-language models to translate the video content into frame captions, object, attribute, and event phrases, and compose them into a temporal structure template. We then instruct a language model, with a prompt containing a few in-context examples, to generate a target output from the composed content. The flexibility of prompting allows the model to capture any form of text input, such as automatic speech recognition (ASR) transcripts. Our experiments demonstrate the power of language models in understanding videos on a wide variety of video-language tasks, including video captioning, video question answering, video caption retrieval, and video future event prediction. Especially, on video future event prediction, our few-shot model significantly outperforms state-of-the-art supervised models trained on large-scale video datasets. Code and resources are publicly available for research purposes at https://github.com/MikeWangWZHL/VidIL .
Lite Audio-Visual Speech Enhancement
May 24, 2020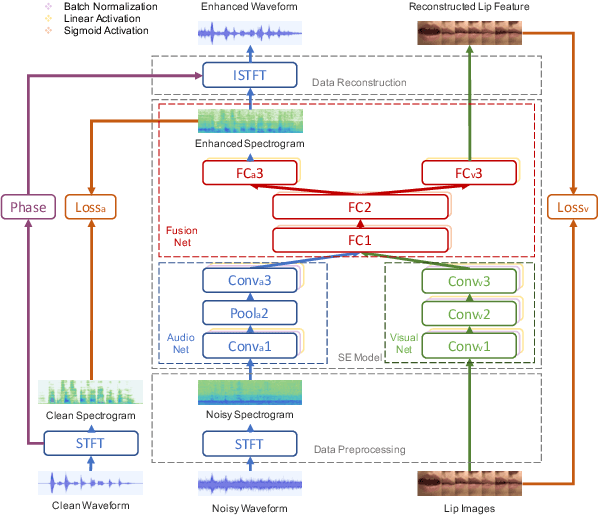
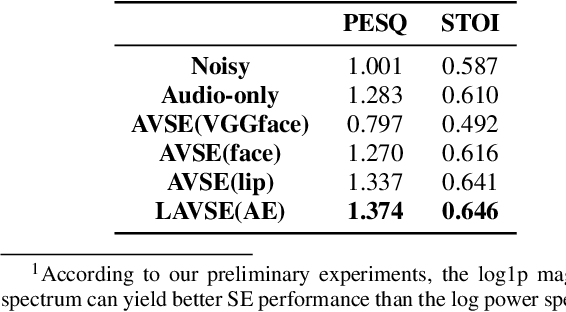
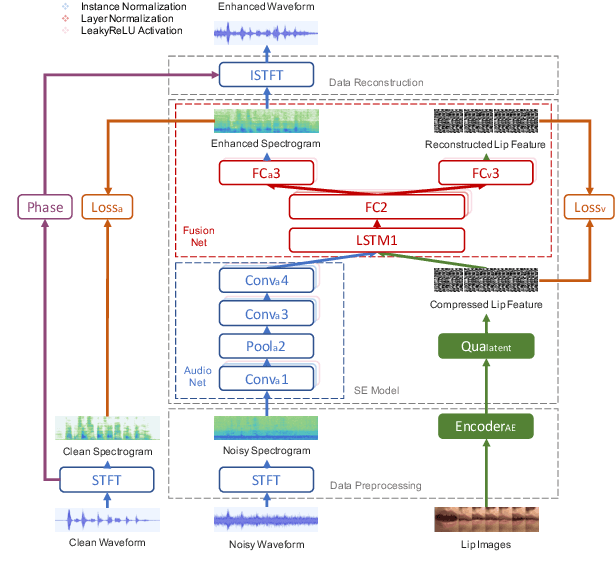
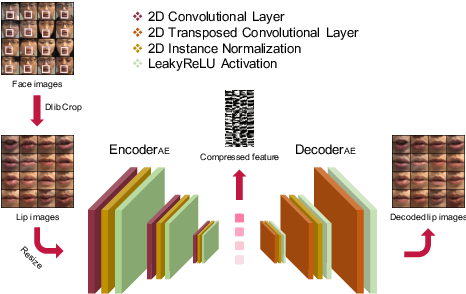
Previous studies have confirmed the effectiveness of incorporating visual information into speech enhancement (SE) systems. Despite improved denoising performance, two problems may be encountered when implementing an audio-visual SE (AVSE) system: (1) additional processing costs are incurred to incorporate visual input and (2) the use of face or lip images may cause privacy problems. In this study, we propose a Lite AVSE (LAVSE) system to address these problems. The system includes two visual data compression techniques and removes the visual feature extraction network from the training model, yielding better online computation efficiency. Our experimental results indicate that the proposed LAVSE system can provide notably better performance than an audio-only SE system with a similar number of model parameters. In addition, the experimental results confirm the effectiveness of the two techniques for visual data compression.
Unsupervised vs. transfer learning for multimodal one-shot matching of speech and images
Aug 14, 2020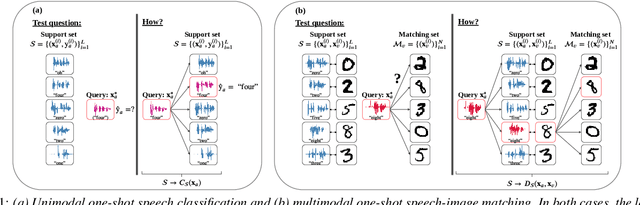
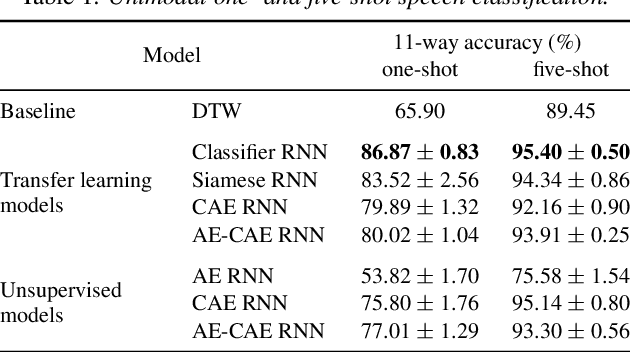
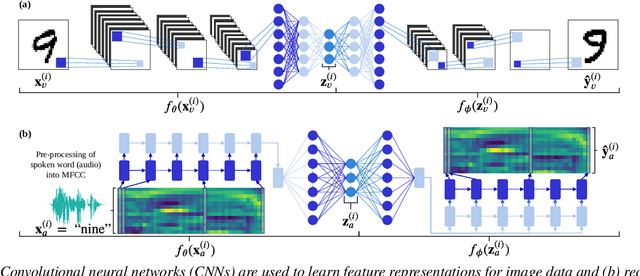
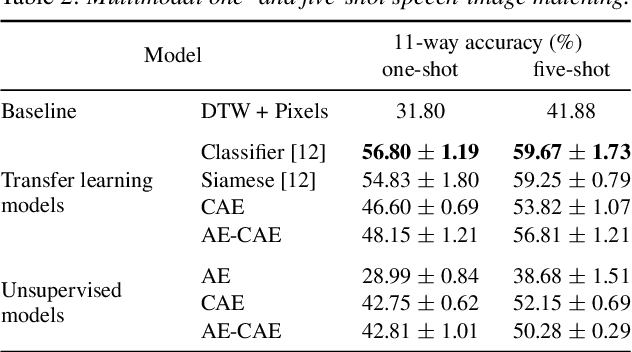
We consider the task of multimodal one-shot speech-image matching. An agent is shown a picture along with a spoken word describing the object in the picture, e.g. cookie, broccoli and ice-cream. After observing one paired speech-image example per class, it is shown a new set of unseen pictures, and asked to pick the "ice-cream". Previous work attempted to tackle this problem using transfer learning: supervised models are trained on labelled background data not containing any of the one-shot classes. Here we compare transfer learning to unsupervised models trained on unlabelled in-domain data. On a dataset of paired isolated spoken and visual digits, we specifically compare unsupervised autoencoder-like models to supervised classifier and Siamese neural networks. In both unimodal and multimodal few-shot matching experiments, we find that transfer learning outperforms unsupervised training. We also present experiments towards combining the two methodologies, but find that transfer learning still performs best (despite idealised experiments showing the benefits of unsupervised learning).