 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegime-Aware Peer Specialization for Robust RAG under Heterogeneous Knowledge Conflicts
Jun 29, 2026Retrieval-augmented generation (RAG) improves language models by grounding generation in external context. However, it can be fragile when the retrieved context conflicts with the model's parametric knowledge. Such conflicts span a reliability spectrum, ranging from reliable and partially reliable evidence to adversarial context. Existing remedies often handle such heterogeneous conflicts with regime-agnostic supervision, which can conflate incompatible learning signals across reliability regimes. To disentangle these signals, we propose RAPS-DA, a regime-aware peer specialization framework that addresses conflict at two complementary granularities. At the sample level, conflicts are divided into three regimes, including Grounding, Arbitration, and Resistance, with one same-scale peer specialist trained per regime from a shared base model. Each sample is then hard-routed to its regime-matched peer for on-policy reverse-KL supervision. At the token level, a dual-layer selector uses inter-teacher disagreement, student-teacher divergence, and student entropy to filter uninformative or unstable tokens, upweight confidently misaligned ones, and gradually focus supervision on high-conflict tokens as the student matures. Gains stem from specialization at a fixed model scale, not from a stronger teacher, and the peer specialists exist only during training, so the deployed student requires no regime labels or peer access. Experiments on five conflict scenarios and two out-of-distribution benchmarks show RAPS-DA surpasses all prompting, decoding, fine-tuning, RL, and single-teacher baselines.
On Aligning Hierarchical Standardized Embedding for Audio-visual Generalized Zero-shot Learning
Jun 10, 2026Audio-visual Generalized Zero-shot Learning (AV-GZSL) is a challenging task that aims to classify both seen and unseen objects or scenes by integrating data from audio and visual modalities. Recent studies primarily focus on fusing or aligning audio and visual features to generate more informative audio-visual embeddings. Also, aligning the audio-visual and textual features of most existing methods relies solely on the optimization objectives. However, those methods neglect the inherent distributional and structural differences between audio-visual and textual modalities. To address this limitation, we propose a method termed Aligning Hierarchical Standardized Embedding (AHSE), which enables hierarchical alignment of standardized audio-visual and textual embeddings within a shared embedding space. Specifically, we first apply Z-score standardization to the fused audio-visual and textual embeddings to reduce distributional mismatches. We then introduce a hierarchical alignment strategy that minimizes discrepancies at the semantic, class, and batch levels, thereby constructing a more robust and well-structured embedding space. This strategy not only preserves semantic and inter-class relationships but also maintains spatial consistency within each batch. Extensive experiments on three benchmark datasets: VGGSound-GZSL, UCF-GZSL, and ActivityNet-GZSL, demonstrate that AHSE achieves competitive performance in zero-shot learning.
MTAVG-Bench 2.0: Diagnosing Failure Modes of Cinematic Expressiveness in Multi-Talker Audio-Video Generation
May 27, 2026In recent years, Multi-Talker Audio-Video Generation (MTAVG) models have shown promising performance on fundamental metrics such as lip-sync and audio-visual alignment. However, these metrics remain insufficient for assessing cinematic expressiveness in scene-level generation. In multi-character scenes, generation models must go beyond audio-visual realism to convey coherent character performance and other higher-level cinematic qualities. To fill this gap, we introduce MTAVG-Bench 2.0, a benchmark for diagnosing failure modes of cinematic expressiveness in multi-talker audio-video generation. Unlike prior settings that mainly focus on the quality of basic multi-turn dialogue, MTAVG-Bench 2.0 targets short-drama and scene-level generation, and establishes a high-level failure taxonomy spanning acting, narrative, atmosphere, and audio-visual language. Based on this taxonomy, we construct more than 10,000 question-answering evaluation instances, together with subsets for short-drama-level assessment and temporal localization of failure modes, to systematically evaluate the ability of omni large language models to diagnose high-level audio-visual failures. Experimental results show that commercial omni models such as Gemini substantially outperform other evaluators, yet even the strongest models continue to struggle with complex failures in our benchmark. These results demonstrate that MTAVG-Bench 2.0 provides a systematic benchmark for failure diagnosis in cinematic multi-talker audio-video generation.
Face-Guided Sentiment Boundary Enhancement for Weakly-Supervised Temporal Sentiment Localization
Mar 16, 2026Point-level weakly-supervised temporal sentiment localization (P-WTSL) aims to detect sentiment-relevant segments in untrimmed multimodal videos using timestamp sentiment annotations, which greatly reduces the costly frame-level labeling. To further tackle the challenges of imprecise sentiment boundaries in P-WTSL, we propose the Face-guided Sentiment Boundary Enhancement Network (\textbf{FSENet}), a unified framework that leverages fine-grained facial features to guide sentiment localization. Specifically, our approach \textit{first} introduces the Face-guided Sentiment Discovery (FSD) module, which integrates facial features into multimodal interaction via dual-branch modeling for effective sentiment stimuli clues; We \textit{then} propose the Point-aware Sentiment Semantics Contrast (PSSC) strategy to discriminate sentiment semantics of candidate points (frame-level) near annotation points via contrastive learning, thereby enhancing the model's ability to recognize sentiment boundaries. At \textit{last}, we design the Boundary-aware Sentiment Pseudo-label Generation (BSPG) approach to convert sparse point annotations into temporally smooth supervisory pseudo-labels. Extensive experiments and visualizations on the benchmark demonstrate the effectiveness of our framework, achieving state-of-the-art performance under full supervision, video-level, and point-level weak supervision, thereby showcasing the strong generalization ability of our FSENet across different annotation settings.
Audit After Segmentation: Reference-Free Mask Quality Assessment for Language-Referred Audio-Visual Segmentation
Feb 03, 2026Language-referred audio-visual segmentation (Ref-AVS) aims to segment target objects described by natural language by jointly reasoning over video, audio, and text. Beyond generating segmentation masks, providing rich and interpretable diagnoses of mask quality remains largely underexplored. In this work, we introduce Mask Quality Assessment in the Ref-AVS context (MQA-RefAVS), a new task that evaluates the quality of candidate segmentation masks without relying on ground-truth annotations as references at inference time. Given audio-visual-language inputs and each provided segmentation mask, the task requires estimating its IoU with the unobserved ground truth, identifying the corresponding error type, and recommending an actionable quality-control decision. To support this task, we construct MQ-RAVSBench, a benchmark featuring diverse and representative mask error modes that span both geometric and semantic issues. We further propose MQ-Auditor, a multimodal large language model (MLLM)-based auditor that explicitly reasons over multimodal cues and mask information to produce quantitative and qualitative mask quality assessments. Extensive experiments demonstrate that MQ-Auditor outperforms strong open-source and commercial MLLMs and can be integrated with existing Ref-AVS systems to detect segmentation failures and support downstream segmentation improvement. Data and codes will be released at https://github.com/jasongief/MQA-RefAVS.
Pardon? Evaluating Conversational Repair in Large Audio-Language Models
Jan 19, 2026Large Audio-Language Models (LALMs) have demonstrated strong performance in spoken question answering (QA), with existing evaluations primarily focusing on answer accuracy and robustness to acoustic perturbations. However, such evaluations implicitly assume that spoken inputs remain semantically answerable, an assumption that often fails in real-world interaction when essential information is missing. In this work, we introduce a repair-aware evaluation setting that explicitly distinguishes between answerable and unanswerable audio inputs. We define answerability as a property of the input itself and construct paired evaluation conditions using a semantic-acoustic masking protocol. Based on this setting, we propose the Evaluability Awareness and Repair (EAR) score, a non-compensatory metric that jointly evaluates task competence under answerable conditions and repair behavior under unanswerable conditions. Experiments on two spoken QA benchmarks across diverse LALMs reveal a consistent gap between answer accuracy and conversational reliability: while many models perform well when inputs are answerable, most fail to recognize semantic unanswerability and initiate appropriate conversational repair. These findings expose a limitation of prevailing accuracy-centric evaluation practices and motivate reliability assessments that treat unanswerable inputs as cues for repair and continued interaction.
CLASP: Cross-modal Salient Anchor-based Semantic Propagation for Weakly-supervised Dense Audio-Visual Event Localization
Aug 06, 2025The Dense Audio-Visual Event Localization (DAVEL) task aims to temporally localize events in untrimmed videos that occur simultaneously in both the audio and visual modalities. This paper explores DAVEL under a new and more challenging weakly-supervised setting (W-DAVEL task), where only video-level event labels are provided and the temporal boundaries of each event are unknown. We address W-DAVEL by exploiting \textit{cross-modal salient anchors}, which are defined as reliable timestamps that are well predicted under weak supervision and exhibit highly consistent event semantics across audio and visual modalities. Specifically, we propose a \textit{Mutual Event Agreement Evaluation} module, which generates an agreement score by measuring the discrepancy between the predicted audio and visual event classes. Then, the agreement score is utilized in a \textit{Cross-modal Salient Anchor Identification} module, which identifies the audio and visual anchor features through global-video and local temporal window identification mechanisms. The anchor features after multimodal integration are fed into an \textit{Anchor-based Temporal Propagation} module to enhance event semantic encoding in the original temporal audio and visual features, facilitating better temporal localization under weak supervision. We establish benchmarks for W-DAVEL on both the UnAV-100 and ActivityNet1.3 datasets. Extensive experiments demonstrate that our method achieves state-of-the-art performance.
AdaKWS: Towards Robust Keyword Spotting with Test-Time Adaptation
May 20, 2025Spoken keyword spotting (KWS) aims to identify keywords in audio for wide applications, especially on edge devices. Current small-footprint KWS systems focus on efficient model designs. However, their inference performance can decline in unseen environments or noisy backgrounds. Test-time adaptation (TTA) helps models adapt to test samples without needing the original training data. In this study, we present AdaKWS, the first TTA method for robust KWS to the best of our knowledge. Specifically, 1) We initially optimize the model's confidence by selecting reliable samples based on prediction entropy minimization and adjusting the normalization statistics in each batch. 2) We introduce pseudo-keyword consistency (PKC) to identify critical, reliable features without overfitting to noise. Our experiments show that AdaKWS outperforms other methods across various conditions, including Gaussian noise and real-scenario noises. The code will be released in due course.
Efficient Non-Autoregressive GAN Voice Conversion using VQWav2vec Features and Dynamic Convolution
Mar 31, 2022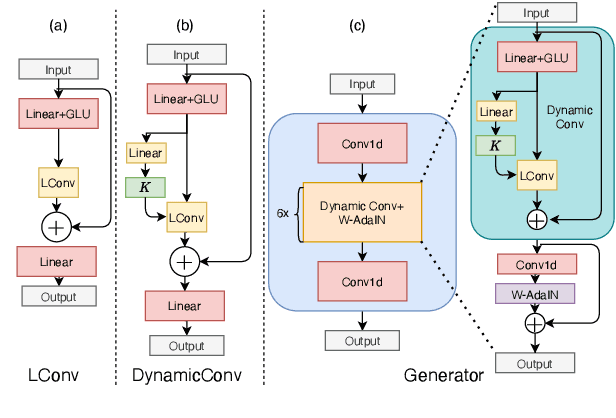
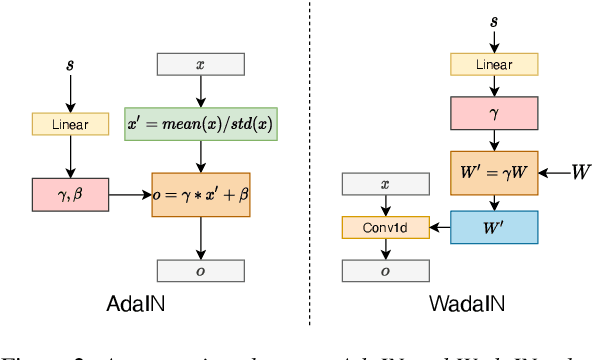
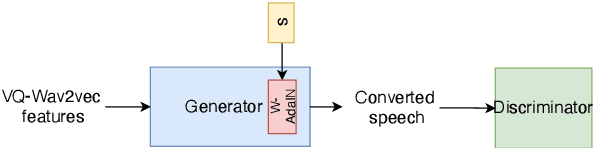

It was shown recently that a combination of ASR and TTS models yield highly competitive performance on standard voice conversion tasks such as the Voice Conversion Challenge 2020 (VCC2020). To obtain good performance both models require pretraining on large amounts of data, thereby obtaining large models that are potentially inefficient in use. In this work we present a model that is significantly smaller and thereby faster in processing while obtaining equivalent performance. To achieve this the proposed model, Dynamic-GAN-VC (DYGAN-VC), uses a non-autoregressive structure and makes use of vector quantised embeddings obtained from a VQWav2vec model. Furthermore dynamic convolution is introduced to improve speech content modeling while requiring a small number of parameters. Objective and subjective evaluation was performed using the VCC2020 task, yielding MOS scores of up to 3.86, and character error rates as low as 4.3\%. This was achieved with approximately half the number of model parameters, and up to 8 times faster decoding speed.
Temporal Network Representation Learning via Historical Neighborhoods Aggregation
Mar 30, 2020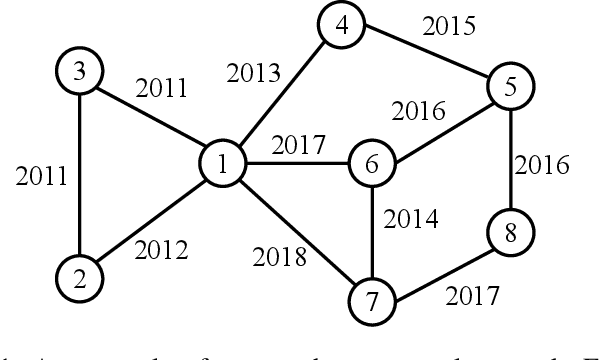
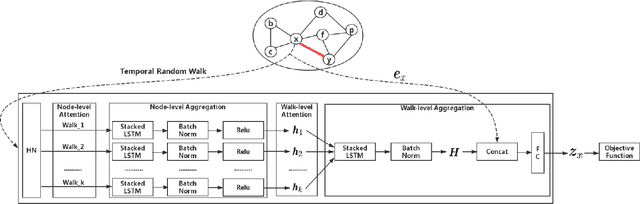
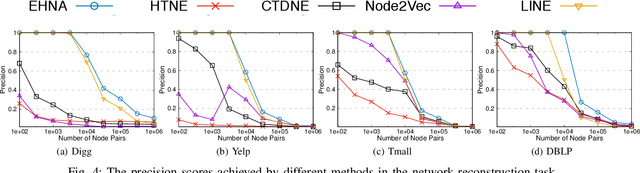
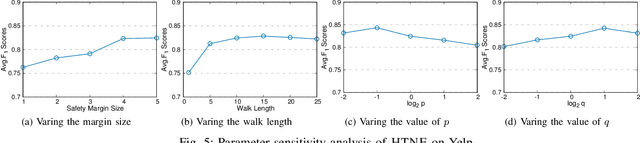
Network embedding is an effective method to learn low-dimensional representations of nodes, which can be applied to various real-life applications such as visualization, node classification, and link prediction. Although significant progress has been made on this problem in recent years, several important challenges remain, such as how to properly capture temporal information in evolving networks. In practice, most networks are continually evolving. Some networks only add new edges or nodes such as authorship networks, while others support removal of nodes or edges such as internet data routing. If patterns exist in the changes of the network structure, we can better understand the relationships between nodes and the evolution of the network, which can be further leveraged to learn node representations with more meaningful information. In this paper, we propose the Embedding via Historical Neighborhoods Aggregation (EHNA) algorithm. More specifically, we first propose a temporal random walk that can identify relevant nodes in historical neighborhoods which have impact on edge formations. Then we apply a deep learning model which uses a custom attention mechanism to induce node embeddings that directly capture temporal information in the underlying feature representation. We perform extensive experiments on a range of real-world datasets, and the results demonstrate the effectiveness of our new approach in the network reconstruction task and the link prediction task.