 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
R-BI: Regularized Batched Inputs enhance Incremental Decoding Framework for Low-Latency Simultaneous Speech Translation
Jan 11, 2024
Incremental Decoding is an effective framework that enables the use of an offline model in a simultaneous setting without modifying the original model, making it suitable for Low-Latency Simultaneous Speech Translation. However, this framework may introduce errors when the system outputs from incomplete input. To reduce these output errors, several strategies such as Hold-$n$, LA-$n$, and SP-$n$ can be employed, but the hyper-parameter $n$ needs to be carefully selected for optimal performance. Moreover, these strategies are more suitable for end-to-end systems than cascade systems. In our paper, we propose a new adaptable and efficient policy named "Regularized Batched Inputs". Our method stands out by enhancing input diversity to mitigate output errors. We suggest particular regularization techniques for both end-to-end and cascade systems. We conducted experiments on IWSLT Simultaneous Speech Translation (SimulST) tasks, which demonstrate that our approach achieves low latency while maintaining no more than 2 BLEU points loss compared to offline systems. Furthermore, our SimulST systems attained several new state-of-the-art results in various language directions.
Decoupled Spatial and Temporal Processing for Resource Efficient Multichannel Speech Enhancement
Jan 15, 2024We present a novel model designed for resource-efficient multichannel speech enhancement in the time domain, with a focus on low latency, lightweight, and low computational requirements. The proposed model incorporates explicit spatial and temporal processing within deep neural network (DNN) layers. Inspired by frequency-dependent multichannel filtering, our spatial filtering process applies multiple trainable filters to each hidden unit across the spatial dimension, resulting in a multichannel output. The temporal processing is applied over a single-channel output stream from the spatial processing using a Long Short-Term Memory (LSTM) network. The output from the temporal processing stage is then further integrated into the spatial dimension through elementwise multiplication. This explicit separation of spatial and temporal processing results in a resource-efficient network design. Empirical findings from our experiments show that our proposed model significantly outperforms robust baseline models while demanding far fewer parameters and computations, while achieving an ultra-low algorithmic latency of just 2 milliseconds.
The NPU-ASLP-LiAuto System Description for Visual Speech Recognition in CNVSRC 2023
Jan 07, 2024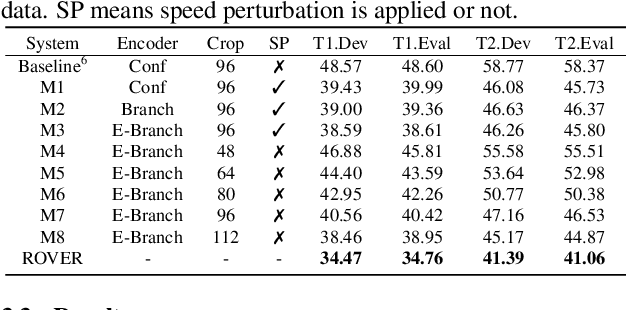
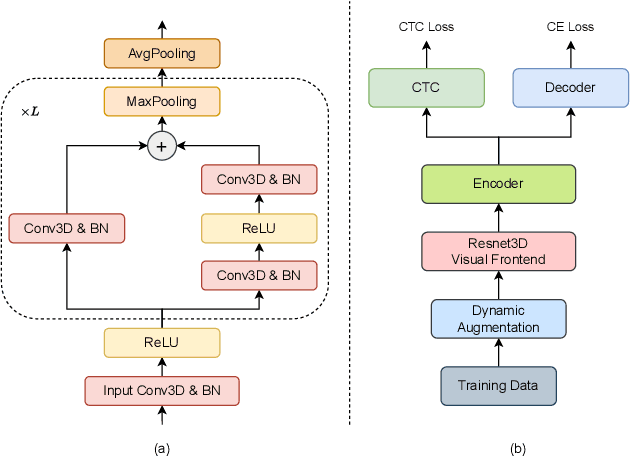
This paper delineates the visual speech recognition (VSR) system introduced by the NPU-ASLP-LiAuto (Team 237) in the first Chinese Continuous Visual Speech Recognition Challenge (CNVSRC) 2023, engaging in the fixed and open tracks of Single-Speaker VSR Task, and the open track of Multi-Speaker VSR Task. In terms of data processing, we leverage the lip motion extractor from the baseline1 to produce multi-scale video data. Besides, various augmentation techniques are applied during training, encompassing speed perturbation, random rotation, horizontal flipping, and color transformation. The VSR model adopts an end-to-end architecture with joint CTC/attention loss, comprising a ResNet3D visual frontend, an E-Branchformer encoder, and a Transformer decoder. Experiments show that our system achieves 34.76% CER for the Single-Speaker Task and 41.06% CER for the Multi-Speaker Task after multi-system fusion, ranking first place in all three tracks we participate.
TransFace: Unit-Based Audio-Visual Speech Synthesizer for Talking Head Translation
Dec 23, 2023Direct speech-to-speech translation achieves high-quality results through the introduction of discrete units obtained from self-supervised learning. This approach circumvents delays and cascading errors associated with model cascading. However, talking head translation, converting audio-visual speech (i.e., talking head video) from one language into another, still confronts several challenges compared to audio speech: (1) Existing methods invariably rely on cascading, synthesizing via both audio and text, resulting in delays and cascading errors. (2) Talking head translation has a limited set of reference frames. If the generated translation exceeds the length of the original speech, the video sequence needs to be supplemented by repeating frames, leading to jarring video transitions. In this work, we propose a model for talking head translation, \textbf{TransFace}, which can directly translate audio-visual speech into audio-visual speech in other languages. It consists of a speech-to-unit translation model to convert audio speech into discrete units and a unit-based audio-visual speech synthesizer, Unit2Lip, to re-synthesize synchronized audio-visual speech from discrete units in parallel. Furthermore, we introduce a Bounded Duration Predictor, ensuring isometric talking head translation and preventing duplicate reference frames. Experiments demonstrate that our proposed Unit2Lip model significantly improves synchronization (1.601 and 0.982 on LSE-C for the original and generated audio speech, respectively) and boosts inference speed by a factor of 4.35 on LRS2. Additionally, TransFace achieves impressive BLEU scores of 61.93 and 47.55 for Es-En and Fr-En on LRS3-T and 100% isochronous translations.
Style Modeling for Multi-Speaker Articulation-to-Speech
Dec 21, 2023In this paper, we propose a neural articulation-to-speech (ATS) framework that synthesizes high-quality speech from articulatory signal in a multi-speaker situation. Most conventional ATS approaches only focus on modeling contextual information of speech from a single speaker's articulatory features. To explicitly represent each speaker's speaking style as well as the contextual information, our proposed model estimates style embeddings, guided from the essential speech style attributes such as pitch and energy. We adopt convolutional layers and transformer-based attention layers for our model to fully utilize both local and global information of articulatory signals, measured by electromagnetic articulography (EMA). Our model significantly improves the quality of synthesized speech compared to the baseline in terms of objective and subjective measurements in the Haskins dataset.
MLCA-AVSR: Multi-Layer Cross Attention Fusion based Audio-Visual Speech Recognition
Jan 07, 2024While automatic speech recognition (ASR) systems degrade significantly in noisy environments, audio-visual speech recognition (AVSR) systems aim to complement the audio stream with noise-invariant visual cues and improve the system's robustness. However, current studies mainly focus on fusing the well-learned modality features, like the output of modality-specific encoders, without considering the contextual relationship during the modality feature learning. In this study, we propose a multi-layer cross-attention fusion based AVSR (MLCA-AVSR) approach that promotes representation learning of each modality by fusing them at different levels of audio/visual encoders. Experimental results on the MISP2022-AVSR Challenge dataset show the efficacy of our proposed system, achieving a concatenated minimum permutation character error rate (cpCER) of 30.57% on the Eval set and yielding up to 3.17% relative improvement compared with our previous system which ranked the second place in the challenge. Following the fusion of multiple systems, our proposed approach surpasses the first-place system, establishing a new SOTA cpCER of 29.13% on this dataset.
Proactive Detection of Voice Cloning with Localized Watermarking
Jan 30, 2024In the rapidly evolving field of speech generative models, there is a pressing need to ensure audio authenticity against the risks of voice cloning. We present AudioSeal, the first audio watermarking technique designed specifically for localized detection of AI-generated speech. AudioSeal employs a generator/detector architecture trained jointly with a localization loss to enable localized watermark detection up to the sample level, and a novel perceptual loss inspired by auditory masking, that enables AudioSeal to achieve better imperceptibility. AudioSeal achieves state-of-the-art performance in terms of robustness to real life audio manipulations and imperceptibility based on automatic and human evaluation metrics. Additionally, AudioSeal is designed with a fast, single-pass detector, that significantly surpasses existing models in speed - achieving detection up to two orders of magnitude faster, making it ideal for large-scale and real-time applications.
Giving Robots a Voice: Human-in-the-Loop Voice Creation and open-ended Labeling
Feb 07, 2024Speech is a natural interface for humans to interact with robots. Yet, aligning a robot's voice to its appearance is challenging due to the rich vocabulary of both modalities. Previous research has explored a few labels to describe robots and tested them on a limited number of robots and existing voices. Here, we develop a robot-voice creation tool followed by large-scale behavioral human experiments (N=2,505). First, participants collectively tune robotic voices to match 175 robot images using an adaptive human-in-the-loop pipeline. Then, participants describe their impression of the robot or their matched voice using another human-in-the-loop paradigm for open-ended labeling. The elicited taxonomy is then used to rate robot attributes and to predict the best voice for an unseen robot. We offer a web interface to aid engineers in customizing robot voices, demonstrating the synergy between cognitive science and machine learning for engineering tools.
HeadStudio: Text to Animatable Head Avatars with 3D Gaussian Splatting
Feb 09, 2024Creating digital avatars from textual prompts has long been a desirable yet challenging task. Despite the promising outcomes obtained through 2D diffusion priors in recent works, current methods face challenges in achieving high-quality and animated avatars effectively. In this paper, we present $\textbf{HeadStudio}$, a novel framework that utilizes 3D Gaussian splatting to generate realistic and animated avatars from text prompts. Our method drives 3D Gaussians semantically to create a flexible and achievable appearance through the intermediate FLAME representation. Specifically, we incorporate the FLAME into both 3D representation and score distillation: 1) FLAME-based 3D Gaussian splatting, driving 3D Gaussian points by rigging each point to a FLAME mesh. 2) FLAME-based score distillation sampling, utilizing FLAME-based fine-grained control signal to guide score distillation from the text prompt. Extensive experiments demonstrate the efficacy of HeadStudio in generating animatable avatars from textual prompts, exhibiting visually appealing appearances. The avatars are capable of rendering high-quality real-time ($\geq 40$ fps) novel views at a resolution of 1024. They can be smoothly controlled by real-world speech and video. We hope that HeadStudio can advance digital avatar creation and that the present method can widely be applied across various domains.
Investigating Training Strategies and Model Robustness of Low-Rank Adaptation for Language Modeling in Speech Recognition
Jan 19, 2024The use of low-rank adaptation (LoRA) with frozen pretrained language models (PLMs) has become increasing popular as a mainstream, resource-efficient modeling approach for memory-constrained hardware. In this study, we first explore how to enhance model performance by introducing various LoRA training strategies, achieving relative word error rate reductions of 3.50\% on the public Librispeech dataset and of 3.67\% on an internal dataset in the messaging domain. To further characterize the stability of LoRA-based second-pass speech recognition models, we examine robustness against input perturbations. These perturbations are rooted in homophone replacements and a novel metric called N-best Perturbation-based Rescoring Robustness (NPRR), both designed to measure the relative degradation in the performance of rescoring models. Our experimental results indicate that while advanced variants of LoRA, such as dynamic rank-allocated LoRA, lead to performance degradation in $1$-best perturbation, they alleviate the degradation in $N$-best perturbation. This finding is in comparison to fully-tuned models and vanilla LoRA tuning baselines, suggesting that a comprehensive selection is needed when using LoRA-based adaptation for compute-cost savings and robust language modeling.