 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Multitask-Based Joint Learning Approach To Robust ASR For Radio Communication Speech
Jul 22, 2021



To realize robust end-to-end Automatic Speech Recognition(E2E ASR) under radio communication condition, we propose a multitask-based method to joint train a Speech Enhancement (SE) module as the front-end and an E2E ASR model as the back-end in this paper. One of the advantage of the proposed method is that the entire system can be trained from scratch. Different from prior works, either component here doesn't need to perform pre-training and fine-tuning processes separately. Through analysis, we found that the success of the proposed method lies in the following aspects. Firstly, multitask learning is essential, that is the SE network is not only learning to produce more Intelligent speech, it is also aimed to generate speech that is beneficial to recognition. Secondly, we also found speech phase preserved from noisy speech is critical for improving ASR performance. Thirdly, we propose a dual channel data augmentation training method to obtain further improvement.Specifically, we combine the clean and enhanced speech to train the whole system. We evaluate the proposed method on the RATS English data set, achieving a relative WER reduction of 4.6% with the joint training method, and up to a relative WER reduction of 11.2% with the proposed data augmentation method.
Improving Accent Identification and Accented Speech Recognition Under a Framework of Self-supervised Learning
Sep 15, 2021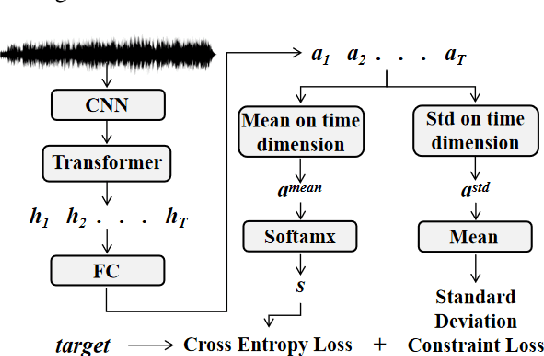
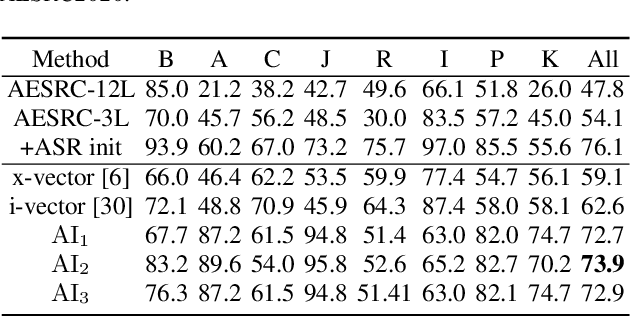
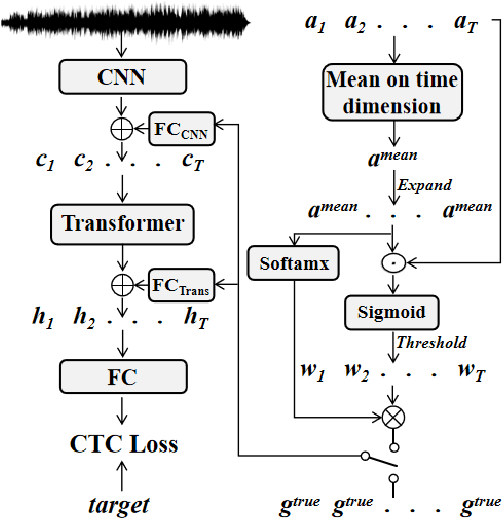

Recently, self-supervised pre-training has gained success in automatic speech recognition (ASR). However, considering the difference between speech accents in real scenarios, how to identify accents and use accent features to improve ASR is still challenging. In this paper, we employ the self-supervised pre-training method for both accent identification and accented speech recognition tasks. For the former task, a standard deviation constraint loss (SDC-loss) based end-to-end (E2E) architecture is proposed to identify accents under the same language. As for accented speech recognition task, we design an accent-dependent ASR system, which can utilize additional accent input features. Furthermore, we propose a frame-level accent feature, which is extracted based on the proposed accent identification model and can be dynamically adjusted. We pre-train our models using 960 hours unlabeled LibriSpeech dataset and fine-tune them on AESRC2020 speech dataset. The experimental results show that our proposed accent-dependent ASR system is significantly ahead of the AESRC2020 baseline and achieves $6.5\%$ relative word error rate (WER) reduction compared with our accent-independent ASR system.
A Comparative Study on Non-Autoregressive Modelings for Speech-to-Text Generation
Oct 11, 2021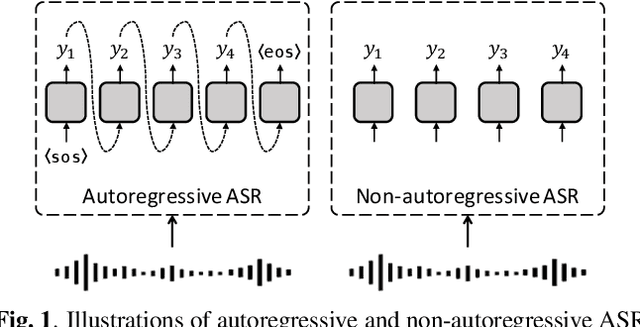

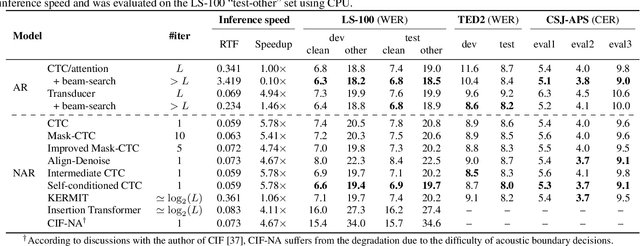
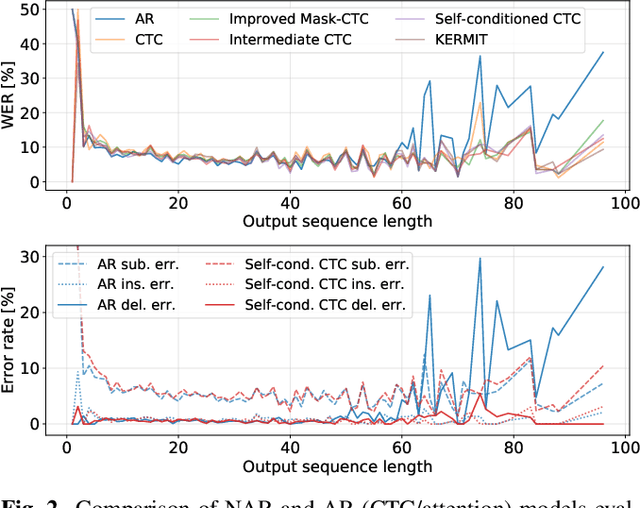
Non-autoregressive (NAR) models simultaneously generate multiple outputs in a sequence, which significantly reduces the inference speed at the cost of accuracy drop compared to autoregressive baselines. Showing great potential for real-time applications, an increasing number of NAR models have been explored in different fields to mitigate the performance gap against AR models. In this work, we conduct a comparative study of various NAR modeling methods for end-to-end automatic speech recognition (ASR). Experiments are performed in the state-of-the-art setting using ESPnet. The results on various tasks provide interesting findings for developing an understanding of NAR ASR, such as the accuracy-speed trade-off and robustness against long-form utterances. We also show that the techniques can be combined for further improvement and applied to NAR end-to-end speech translation. All the implementations are publicly available to encourage further research in NAR speech processing.
Towards Measuring Fairness in Speech Recognition: Casual Conversations Dataset Transcriptions
Nov 18, 2021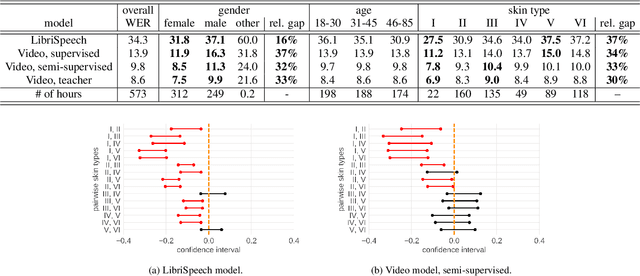

It is well known that many machine learning systems demonstrate bias towards specific groups of individuals. This problem has been studied extensively in the Facial Recognition area, but much less so in Automatic Speech Recognition (ASR). This paper presents initial Speech Recognition results on "Casual Conversations" -- a publicly released 846 hour corpus designed to help researchers evaluate their computer vision and audio models for accuracy across a diverse set of metadata, including age, gender, and skin tone. The entire corpus has been manually transcribed, allowing for detailed ASR evaluations across these metadata. Multiple ASR models are evaluated, including models trained on LibriSpeech, 14,000 hour transcribed, and over 2 million hour untranscribed social media videos. Significant differences in word error rate across gender and skin tone are observed at times for all models. We are releasing human transcripts from the Casual Conversations dataset to encourage the community to develop a variety of techniques to reduce these statistical biases.
Multimodal Transformer Distillation for Audio-Visual Synchronization
Oct 27, 2022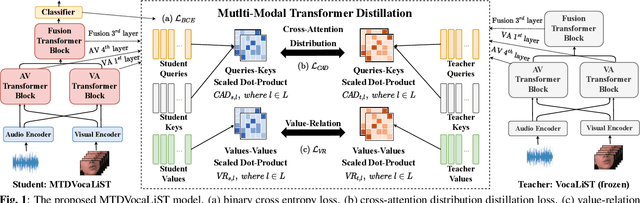
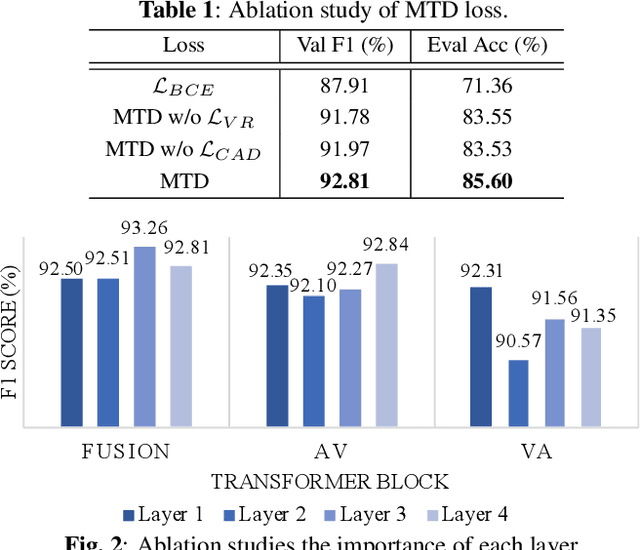
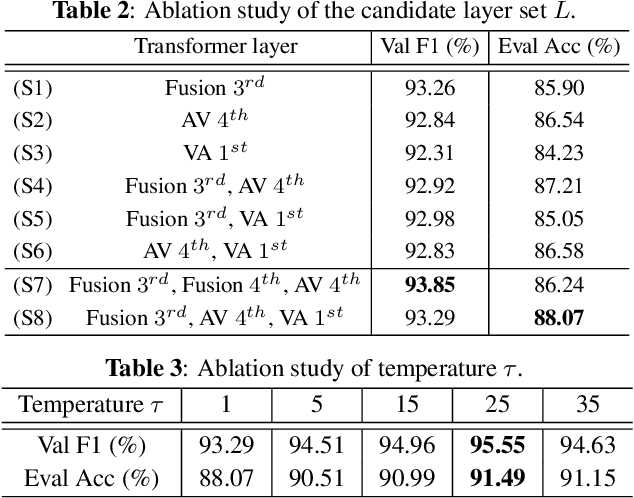
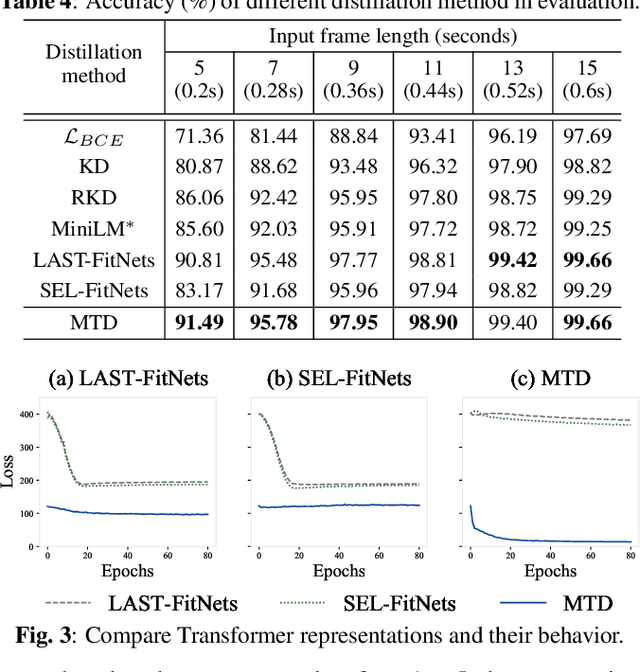
Audio-visual synchronization aims to determine whether the mouth movements and speech in the video are synchronized. VocaLiST reaches state-of-the-art performance by incorporating multimodal Transformers to model audio-visual interact information. However, it requires high computing resources, making it impractical for real-world applications. This paper proposed an MTDVocaLiST model, which is trained by our proposed multimodal Transformer distillation (MTD) loss. MTD loss enables MTDVocaLiST model to deeply mimic the cross-attention distribution and value-relation in the Transformer of VocaLiST. Our proposed method is effective in two aspects: From the distillation method perspective, MTD loss outperforms other strong distillation baselines. From the distilled model's performance perspective: 1) MTDVocaLiST outperforms similar-size SOTA models, SyncNet, and PM models by 15.69% and 3.39%; 2) MTDVocaLiST reduces the model size of VocaLiST by 83.52%, yet still maintaining similar performance.
Opening the Black Box of wav2vec Feature Encoder
Oct 27, 2022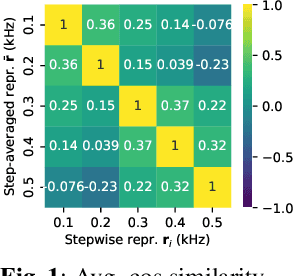
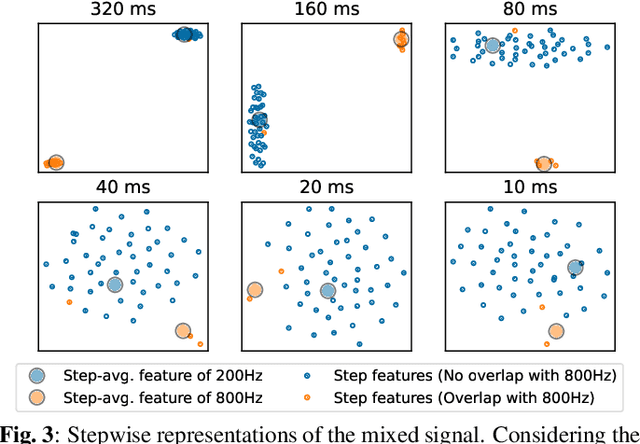
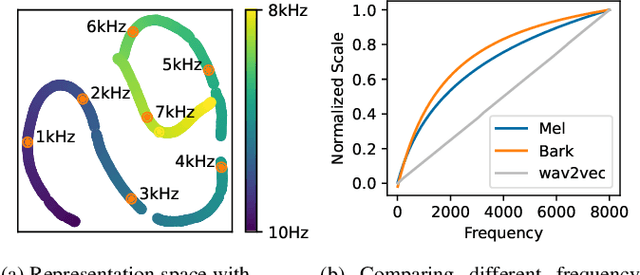
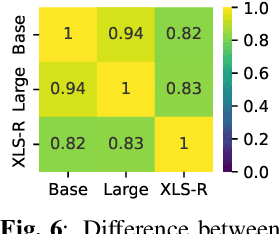
Self-supervised models, namely, wav2vec and its variants, have shown promising results in various downstream tasks in the speech domain. However, their inner workings are poorly understood, calling for in-depth analyses on what the model learns. In this paper, we concentrate on the convolutional feature encoder where its latent space is often speculated to represent discrete acoustic units. To analyze the embedding space in a reductive manner, we feed the synthesized audio signals, which is the summation of simple sine waves. Through extensive experiments, we conclude that various information is embedded inside the feature encoder representations: (1) fundamental frequency, (2) formants, and (3) amplitude, packed with (4) sufficient temporal detail. Further, the information incorporated inside the latent representations is analogous to spectrograms but with a fundamental difference: latent representations construct a metric space so that closer representations imply acoustic similarity.
Convolutive Prediction for Monaural Speech Dereverberation and Noisy-Reverberant Speaker Separation
Aug 16, 2021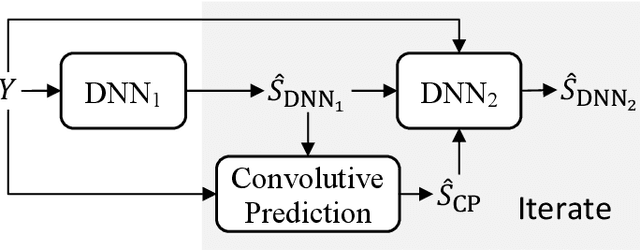
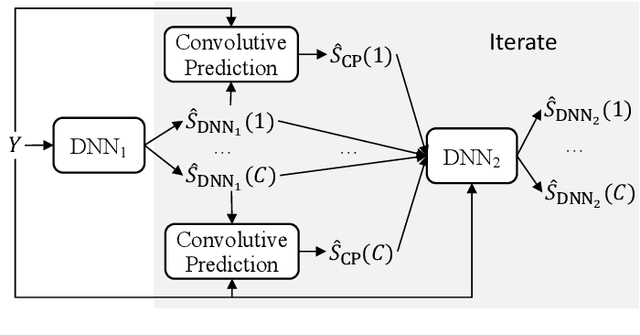
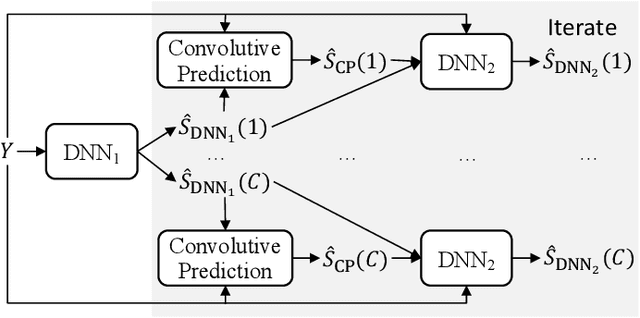
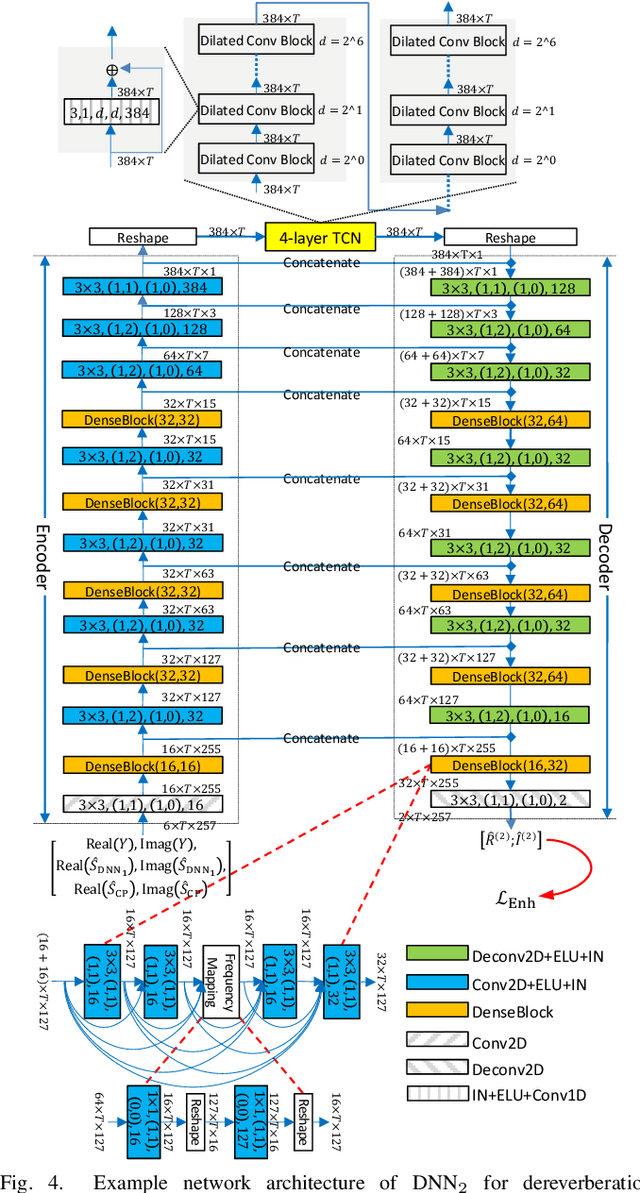
A promising approach for speech dereverberation is based on supervised learning, where a deep neural network (DNN) is trained to predict the direct sound from noisy-reverberant speech. This data-driven approach is based on leveraging prior knowledge of clean speech patterns and does not explicitly exploit the linear-filter structure in reverberation, i.e., that reverberation results from a linear convolution between a room impulse response (RIR) and a dry source signal. In this work, we propose to exploit this linear-filter structure within a deep learning based monaural speech dereverberation framework. The key idea is to first estimate the direct-path signal of the target speaker using a DNN and then identify signals that are decayed and delayed copies of the estimated direct-path signal, as these can be reliably considered as reverberation. They can be either directly removed for dereverberation, or used as extra features for another DNN to perform better dereverberation. To identify the copies, we estimate the underlying filter (or RIR) by efficiently solving a linear regression problem per frequency in the time-frequency domain. We then modify the proposed algorithm for speaker separation in reverberant and noisy-reverberant conditions. State-of-the-art speech dereverberation and speaker separation results are obtained on the REVERB, SMS-WSJ, and WHAMR! datasets.
One to rule them all: Towards Joint Indic Language Hate Speech Detection
Sep 28, 2021

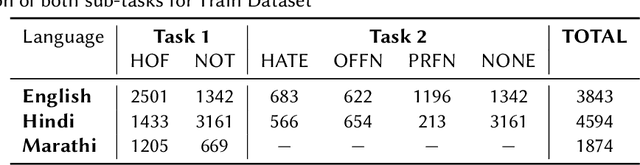
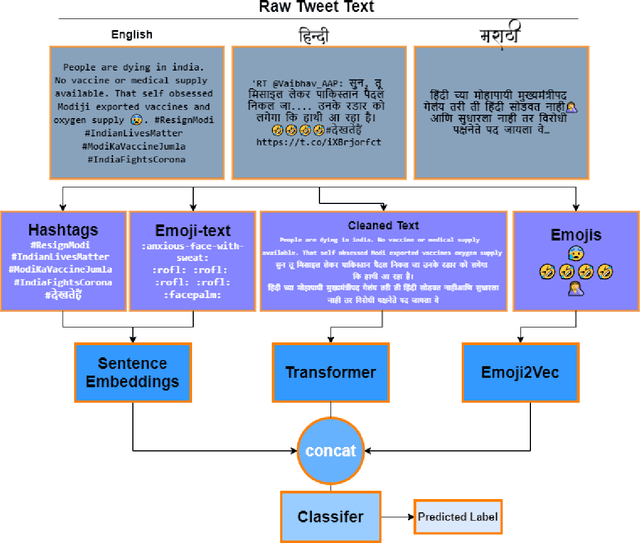
This paper is a contribution to the Hate Speech and Offensive Content Identification in Indo-European Languages (HASOC) 2021 shared task. Social media today is a hotbed of toxic and hateful conversations, in various languages. Recent news reports have shown that current models struggle to automatically identify hate posted in minority languages. Therefore, efficiently curbing hate speech is a critical challenge and problem of interest. We present a multilingual architecture using state-of-the-art transformer language models to jointly learn hate and offensive speech detection across three languages namely, English, Hindi, and Marathi. On the provided testing corpora, we achieve Macro F1 scores of 0.7996, 0.7748, 0.8651 for sub-task 1A and 0.6268, 0.5603 during the fine-grained classification of sub-task 1B. These results show the efficacy of exploiting a multilingual training scheme.
WeKws: A production first small-footprint end-to-end Keyword Spotting Toolkit
Oct 30, 2022

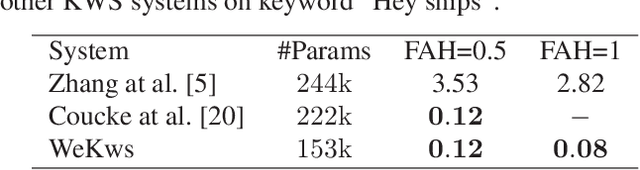
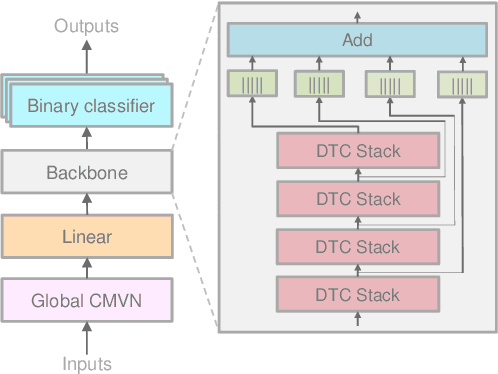
Keyword spotting (KWS) enables speech-based user interaction and gradually becomes an indispensable component of smart devices. Recently, end-to-end (E2E) methods have become the most popular approach for on-device KWS tasks. However, there is still a gap between the research and deployment of E2E KWS methods. In this paper, we introduce WeKws, a production-quality, easy-to-build, and convenient-to-be-applied E2E KWS toolkit. WeKws contains the implementations of several state-of-the-art backbone networks, making it achieve highly competitive results on three publicly available datasets. To make WeKws a pure E2E toolkit, we utilize a refined max-pooling loss to make the model learn the ending position of the keyword by itself, which significantly simplifies the training pipeline and makes WeKws very efficient to be applied in real-world scenarios. The toolkit is publicly available at https://github.com/wenet-e2e/wekws.
DuDe: Dual-Decoder Multilingual ASR for Indian Languages using Common Label Set
Oct 30, 2022

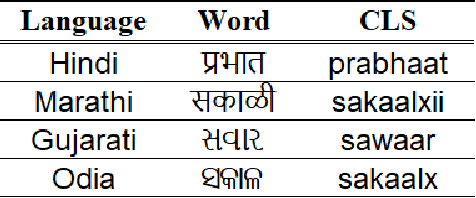
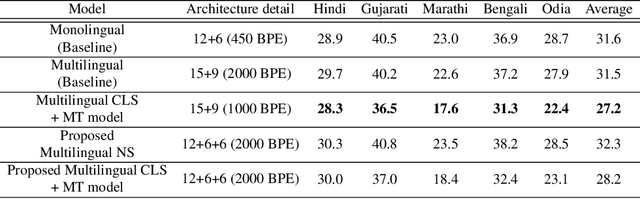
In a multilingual country like India, multilingual Automatic Speech Recognition (ASR) systems have much scope. Multilingual ASR systems exhibit many advantages like scalability, maintainability, and improved performance over the monolingual ASR systems. However, building multilingual systems for Indian languages is challenging since different languages use different scripts for writing. On the other hand, Indian languages share a lot of common sounds. Common Label Set (CLS) exploits this idea and maps graphemes of various languages with similar sounds to common labels. Since Indian languages are mostly phonetic, building a parser to convert from native script to CLS is easy. In this paper, we explore various approaches to build multilingual ASR models. We also propose a novel architecture called Encoder-Decoder-Decoder for building multilingual systems that use both CLS and native script labels. We also analyzed the effectiveness of CLS-based multilingual systems combined with machine transliteration.