 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDuDe: Dual-Decoder Multilingual ASR for Indian Languages using Common Label Set
Oct 30, 2022



In a multilingual country like India, multilingual Automatic Speech Recognition (ASR) systems have much scope. Multilingual ASR systems exhibit many advantages like scalability, maintainability, and improved performance over the monolingual ASR systems. However, building multilingual systems for Indian languages is challenging since different languages use different scripts for writing. On the other hand, Indian languages share a lot of common sounds. Common Label Set (CLS) exploits this idea and maps graphemes of various languages with similar sounds to common labels. Since Indian languages are mostly phonetic, building a parser to convert from native script to CLS is easy. In this paper, we explore various approaches to build multilingual ASR models. We also propose a novel architecture called Encoder-Decoder-Decoder for building multilingual systems that use both CLS and native script labels. We also analyzed the effectiveness of CLS-based multilingual systems combined with machine transliteration.
Joint Encoder-Decoder Self-Supervised Pre-training for ASR
Jun 09, 2022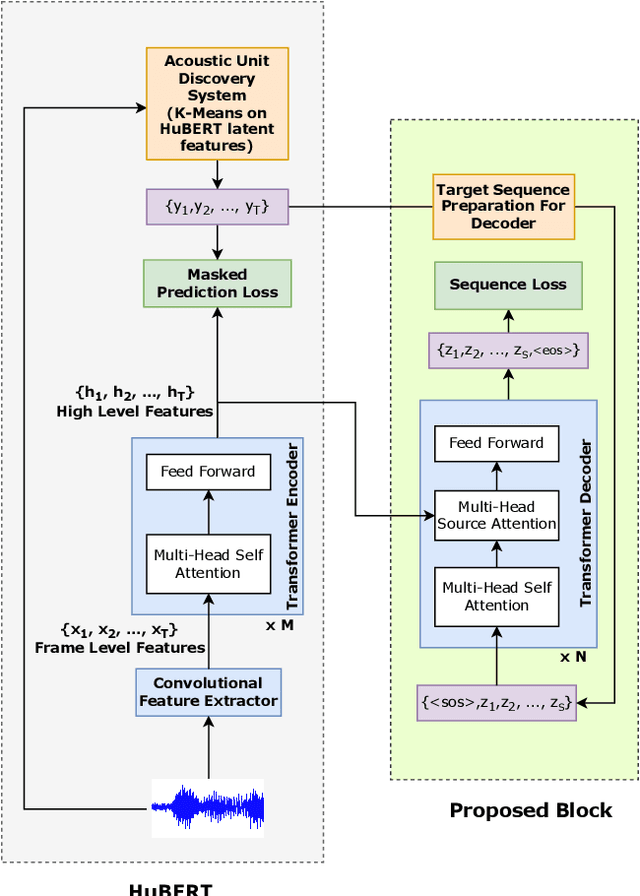
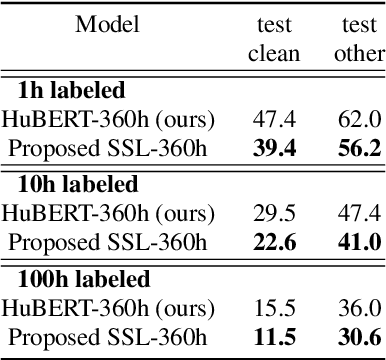
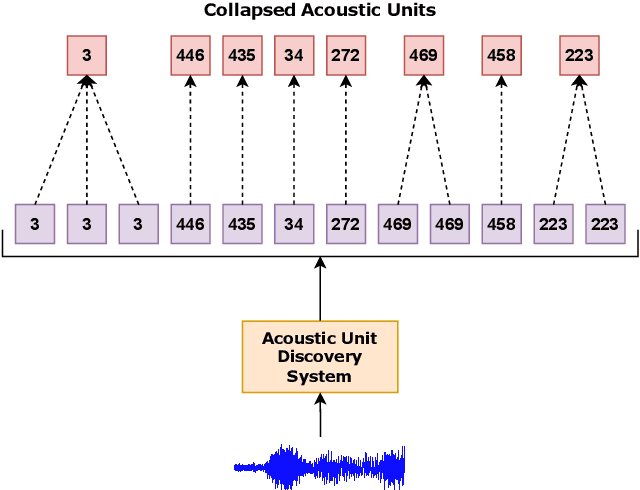
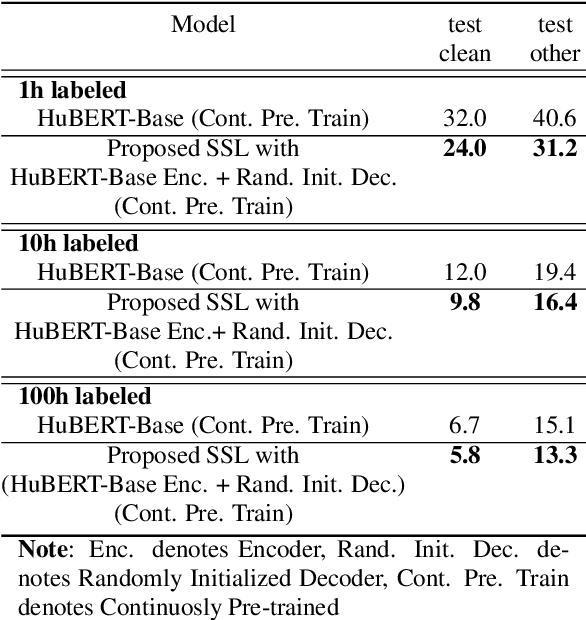
Self-supervised learning (SSL) has shown tremendous success in various speech-related downstream tasks, including Automatic Speech Recognition (ASR). The output embeddings of the SSL model are treated as powerful short-time representations of the speech signal. However, in the ASR task, the main objective is to get the correct sequence of acoustic units, characters, or byte-pair encodings (BPEs). Usually, encoder-decoder architecture works exceptionally well for a sequence-to-sequence task like ASR. Therefore, in this paper, we propose a new paradigm that exploits the power of a decoder during self-supervised learning. We use Hidden Unit BERT (HuBERT) SSL framework to compute the conventional masked prediction loss for the encoder. In addition, we have introduced a decoder in the SSL framework and proposed a target preparation strategy for the decoder. Finally, we use a multitask SSL setup wherein we jointly optimize both the encoder and decoder losses. We hypothesize that the presence of a decoder in the SSL model helps it learn an acoustic unit-based language model, which might improve the performance of an ASR downstream task. We compare our proposed SSL model with HuBERT and show up to 25% relative improvement in performance on ASR by finetuning on various LibriSpeech subsets.