 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Location-based Thermal Emission Side-Channel Analysis Using Iterative Transfer Learning
Dec 30, 2024



This paper proposes the use of iterative transfer learning applied to deep learning models for side-channel attacks. Currently, most of the side-channel attack methods train a model for each individual byte, without considering the correlation between bytes. However, since the models' parameters for attacking different bytes may be similar, we can leverage transfer learning, meaning that we first train the model for one of the key bytes, then use the trained model as a pretrained model for the remaining bytes. This technique can be applied iteratively, a process known as iterative transfer learning. Experimental results show that when using thermal or power consumption map images as input, and multilayer perceptron or convolutional neural network as the model, our method improves average performance, especially when the amount of data is insufficient.
Improving Real-Time Music Accompaniment Separation with MMDenseNet
Jun 30, 2024Music source separation aims to separate polyphonic music into different types of sources. Most existing methods focus on enhancing the quality of separated results by using a larger model structure, rendering them unsuitable for deployment on edge devices. Moreover, these methods may produce low-quality output when the input duration is short, making them impractical for real-time applications. Therefore, the goal of this paper is to enhance a lightweight model, MMDenstNet, to strike a balance between separation quality and latency for real-time applications. Different directions of improvement are explored or proposed in this paper, including complex ideal ratio mask, self-attention, band-merge-split method, and feature look back. Source-to-distortion ratio, real-time factor, and optimal latency are employed to evaluate the performance. To align with our application requirements, the evaluation process in this paper focuses on the separation performance of the accompaniment part. Experimental results demonstrate that our improvement achieves low real-time factor and optimal latency while maintaining acceptable separation quality.
Personalized Audio Quality Preference Prediction
Feb 16, 2023

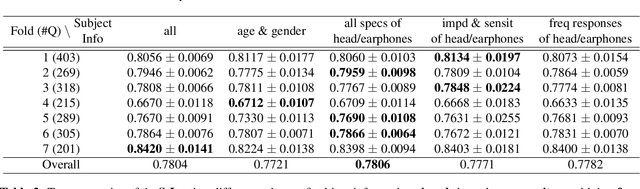

This paper proposes to use both audio input and subject information to predict the personalized preference of two audio segments with the same content in different qualities. A siamese network is used to compare the inputs and predict the preference. Several different structures for each side of the siamese network are investigated, and an LDNet with PANNs' CNN6 as the encoder and a multi-layer perceptron block as the decoder outperforms a baseline model using only audio input the most, where the overall accuracy grows from 77.56% to 78.04%. Experimental results also show that using all the subject information, including age, gender, and the specifications of headphones or earphones, is more effective than using only a part of them.
Multimodal Transformer Distillation for Audio-Visual Synchronization
Oct 27, 2022Audio-visual synchronization aims to determine whether the mouth movements and speech in the video are synchronized. VocaLiST reaches state-of-the-art performance by incorporating multimodal Transformers to model audio-visual interact information. However, it requires high computing resources, making it impractical for real-world applications. This paper proposed an MTDVocaLiST model, which is trained by our proposed multimodal Transformer distillation (MTD) loss. MTD loss enables MTDVocaLiST model to deeply mimic the cross-attention distribution and value-relation in the Transformer of VocaLiST. Our proposed method is effective in two aspects: From the distillation method perspective, MTD loss outperforms other strong distillation baselines. From the distilled model's performance perspective: 1) MTDVocaLiST outperforms similar-size SOTA models, SyncNet, and PM models by 15.69% and 3.39%; 2) MTDVocaLiST reduces the model size of VocaLiST by 83.52%, yet still maintaining similar performance.
Training strategy for a lightweight countermeasure model for automatic speaker verification
Apr 08, 2022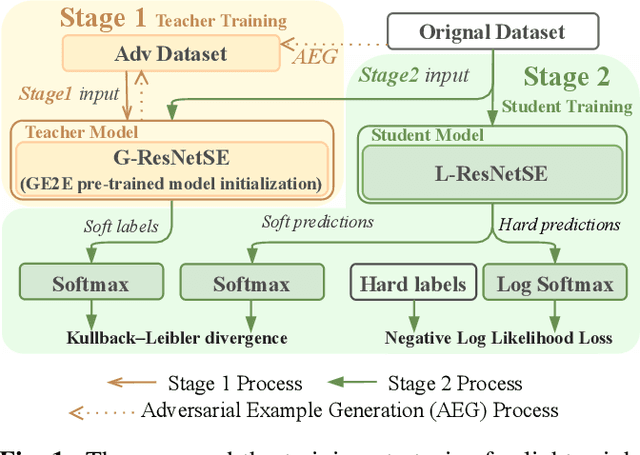
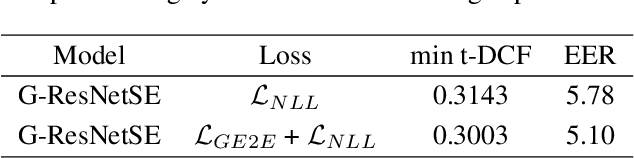
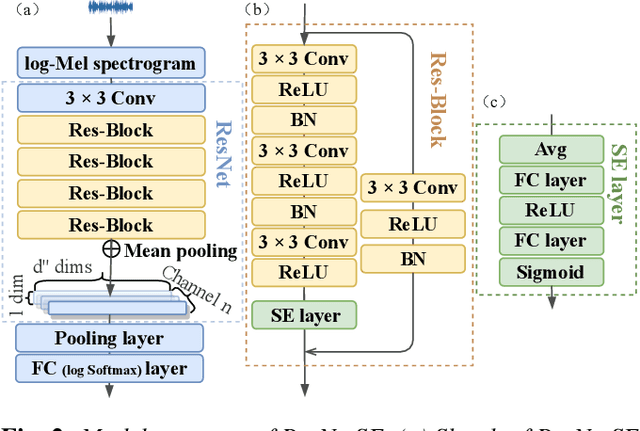
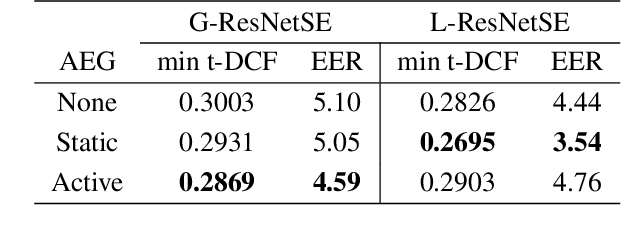
The countermeasure (CM) model is developed to protect Automatic Speaker Verification (ASV) systems from spoof attacks and prevent resulting personal information leakage. Based on practicality and security considerations, the CM model is usually deployed on edge devices, which have more limited computing resources and storage space than cloud-based systems. This work proposes training strategies for a lightweight CM model for ASV, using generalized end-to-end (GE2E) pre-training and adversarial fine-tuning to improve performance, and applying knowledge distillation (KD) to reduce the size of the CM model. In the evaluation phase of the ASVspoof 2021 Logical Access task, the lightweight ResNetSE model reaches min t-DCF 0.2695 and EER 3.54%. Compared to the teacher model, the lightweight student model only uses 22.5% of parameters and 21.1% of multiply and accumulate operands of the teacher model.