 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Expressive Appropriateness of Speech in Rich Contexts
May 10, 2026Evaluating expressive speech remains challenging, as existing methods mainly assess emotional intensity and overlook whether a speech sample is expressively appropriate for its contextual setting. This limitation hinders reliable evaluation of speech systems used in narrative-driven and interactive applications, such as audiobooks and conversational agents. We introduce CEAEval, a Context-rich framework for Evaluating Expressive Appropriateness in speech, which assesses whether a speech sample expressively aligns with the underlying communicative intent implied by its discourse-level narrative context. To support this task, we construct CEAEval-D, the first context-rich speech dataset with real human performances in Mandarin conversational speech, providing narrative descriptions together with fifteen dimensions of human annotations covering expressive attributes and expressive appropriateness. We further develop CEAEval-M, a model that integrates knowledge distillation, planner-based multi-model collaboration, adaptive audio attention bias, and reinforcement learning to perform context-rich expressive appropriateness evaluation. Experiments on a human-annotated test set demonstrate that CEAEval-M substantially outperforms existing speech evaluation and analysis systems.
Self-critical Sequence Training for Automatic Speech Recognition
Apr 13, 2022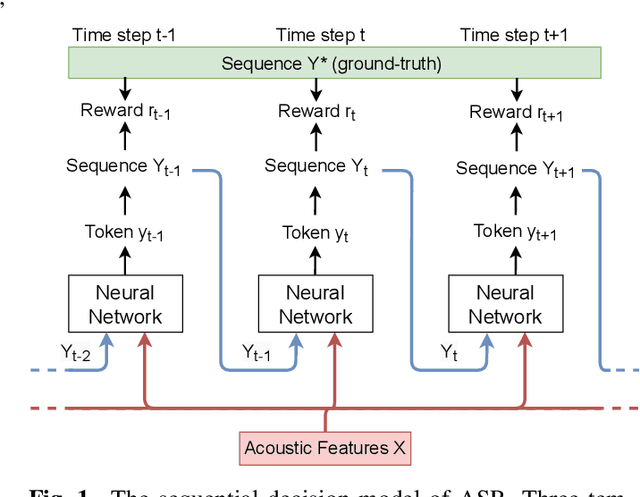
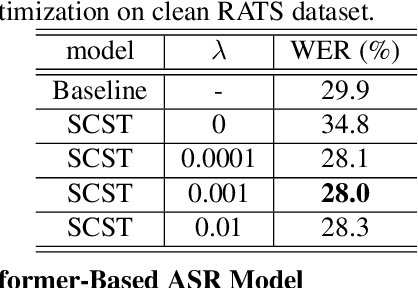
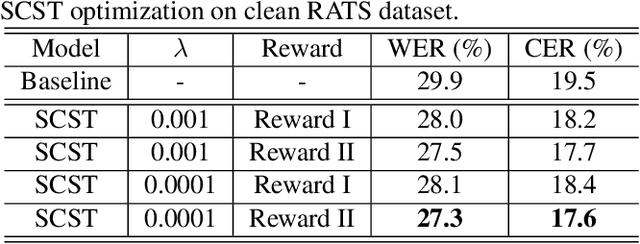
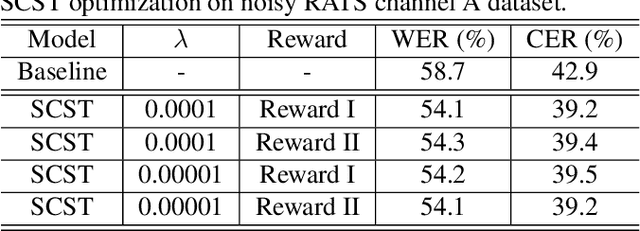
Although automatic speech recognition (ASR) task has gained remarkable success by sequence-to-sequence models, there are two main mismatches between its training and testing that might lead to performance degradation: 1) The typically used cross-entropy criterion aims to maximize log-likelihood of the training data, while the performance is evaluated by word error rate (WER), not log-likelihood; 2) The teacher-forcing method leads to the dependence on ground truth during training, which means that model has never been exposed to its own prediction before testing. In this paper, we propose an optimization method called self-critical sequence training (SCST) to make the training procedure much closer to the testing phase. As a reinforcement learning (RL) based method, SCST utilizes a customized reward function to associate the training criterion and WER. Furthermore, it removes the reliance on teacher-forcing and harmonizes the model with respect to its inference procedure. We conducted experiments on both clean and noisy speech datasets, and the results show that the proposed SCST respectively achieves 8.7% and 7.8% relative improvements over the baseline in terms of WER.
Interactive Audio-text Representation for Automated Audio Captioning with Contrastive Learning
Apr 12, 2022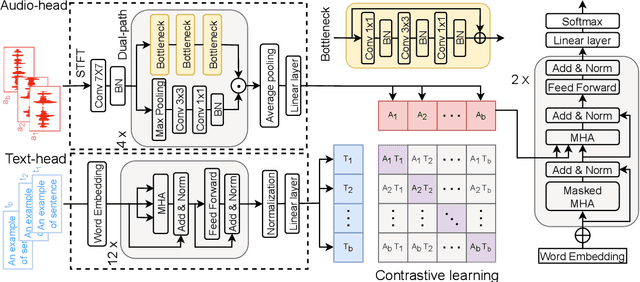

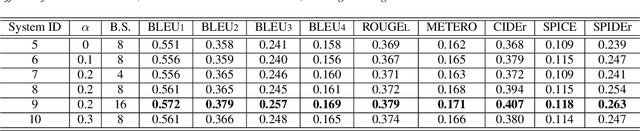
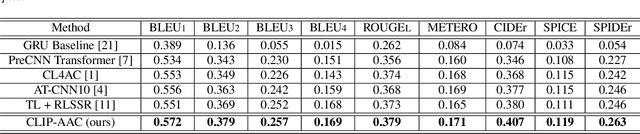
Automated Audio captioning (AAC) is a cross-modal task that generates natural language to describe the content of input audio. Most prior works usually extract single-modality acoustic features and are therefore sub-optimal for the cross-modal decoding task. In this work, we propose a novel AAC system called CLIP-AAC to learn interactive cross-modality representation with both acoustic and textual information. Specifically, the proposed CLIP-AAC introduces an audio-head and a text-head in the pre-trained encoder to extract audio-text information. Furthermore, we also apply contrastive learning to narrow the domain difference by learning the correspondence between the audio signal and its paired captions. Experimental results show that the proposed CLIP-AAC approach surpasses the best baseline by a significant margin on the Clotho dataset in terms of NLP evaluation metrics. The ablation study indicates that both the pre-trained model and contrastive learning contribute to the performance gain of the AAC model.
Rainbow Keywords: Efficient Incremental Learning for Online Spoken Keyword Spotting
Mar 30, 2022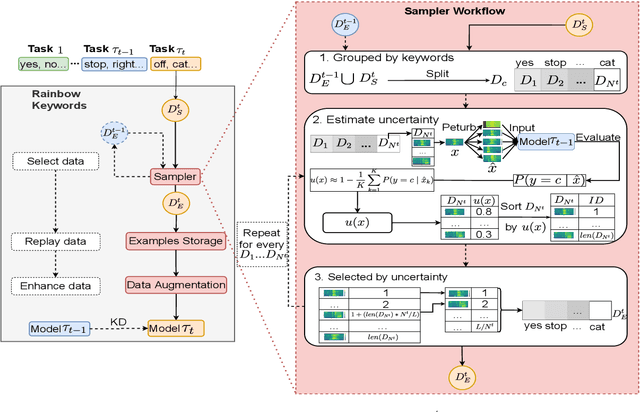

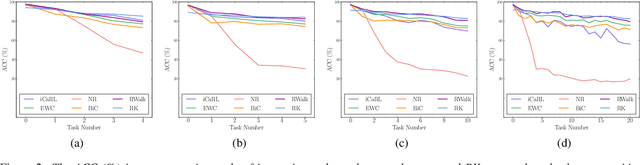
Catastrophic forgetting is a thorny challenge when updating keyword spotting (KWS) models after deployment. This problem will be more challenging if KWS models are further required for edge devices due to their limited memory. To alleviate such an issue, we propose a novel diversity-aware incremental learning method named Rainbow Keywords (RK). Specifically, the proposed RK approach introduces a diversity-aware sampler to select a diverse set from historical and incoming keywords by calculating classification uncertainty. As a result, the RK approach can incrementally learn new tasks without forgetting prior knowledge. Besides, the RK approach also proposes data augmentation and knowledge distillation loss function for efficient memory management on the edge device. Experimental results show that the proposed RK approach achieves 4.2% absolute improvement in terms of average accuracy over the best baseline on Google Speech Command dataset with less required memory. The scripts are available on GitHub.
Noise-robust Speech Recognition with 10 Minutes Unparalleled In-domain Data
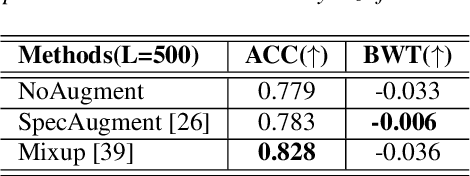
Mar 29, 2022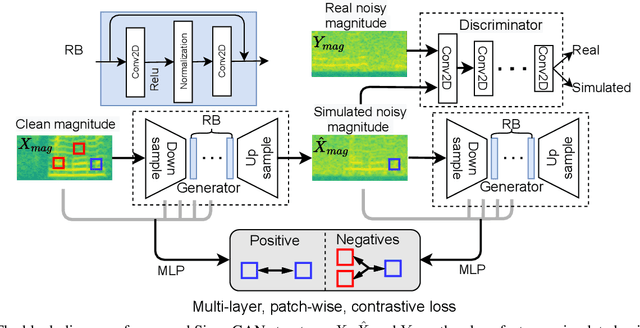
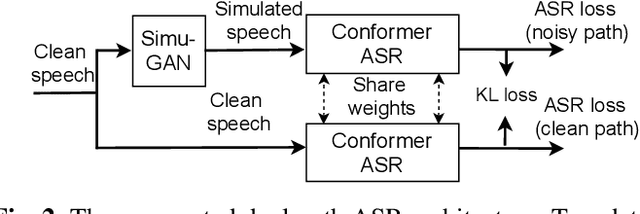
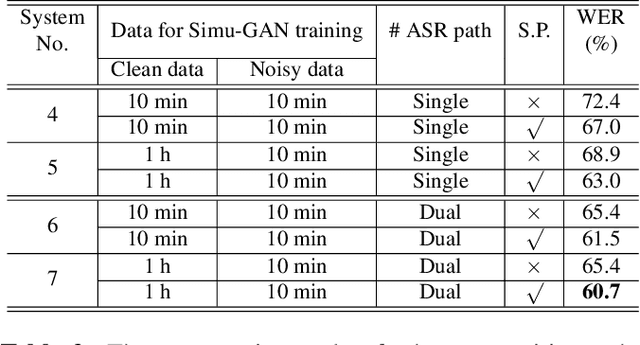
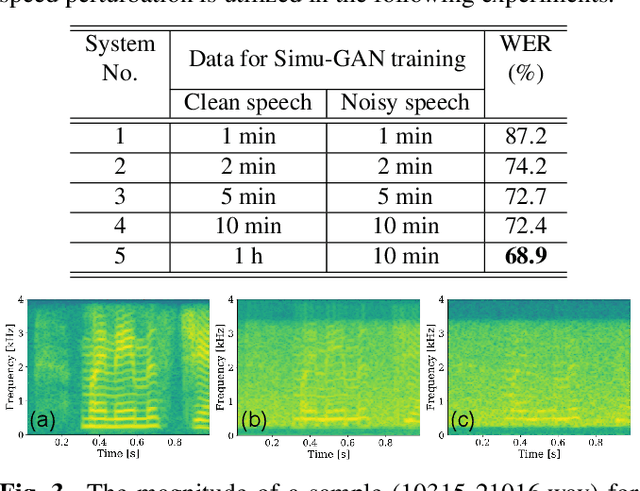
Noise-robust speech recognition systems require large amounts of training data including noisy speech data and corresponding transcripts to achieve state-of-the-art performances in face of various practical environments. However, such plenty of in-domain data is not always available in the real-life world. In this paper, we propose a generative adversarial network to simulate noisy spectrum from the clean spectrum (Simu-GAN), where only 10 minutes of unparalleled in-domain noisy speech data is required as labels. Furthermore, we also propose a dual-path speech recognition system to improve the robustness of the system under noisy conditions. Experimental results show that the proposed speech recognition system achieves 7.3% absolute improvement with simulated noisy data by Simu-GAN over the best baseline in terms of word error rate (WER).
Dual-Path Style Learning for End-to-End Noise-Robust Speech Recognition
Mar 28, 2022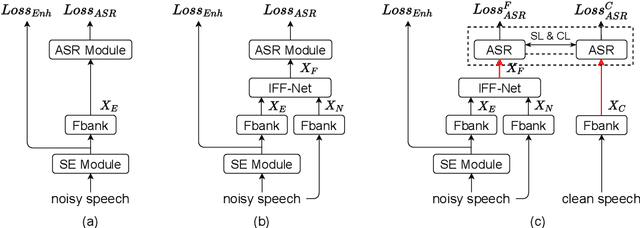

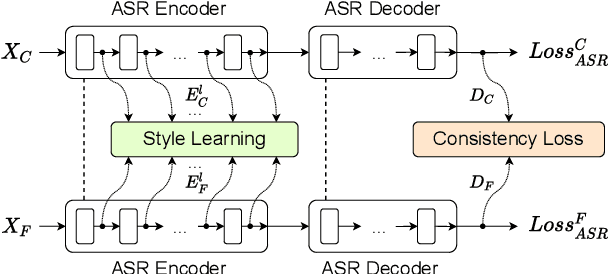
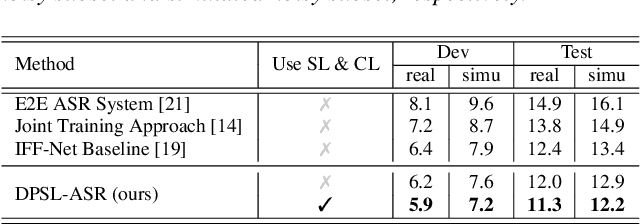
Noise-robust automatic speech recognition degrades significantly in face of over-suppression problem, which usually exists in the front-end speech enhancement module. To alleviate such issue, we propose novel dual-path style learning for end-to-end noise-robust automatic speech recognition (DPSL-ASR). Specifically, the proposed DPSL-ASR approach introduces clean feature along with fused feature by the IFF-Net as dual-path inputs to recover the over-suppressed information. Furthermore, we propose style learning to learn abundant details and latent information by mapping fused feature to clean feature. Besides, we also utilize the consistency loss to minimize the distance of decoded embeddings between two paths. Experimental results show that the proposed DPSL-ASR approach achieves relative word error rate (WER) reductions of 10.6% and 8.6%, on RATS Channel-A dataset and CHiME-4 1-Channel Track dataset, respectively. The visualizations of intermediate embeddings also indicate that the proposed DPSL-ASR can learn more details than the best baseline. Our code implementation is available at Github: https://github.com/YUCHEN005/DPSL-ASR.
Progressive Continual Learning for Spoken Keyword Spotting
Feb 07, 2022
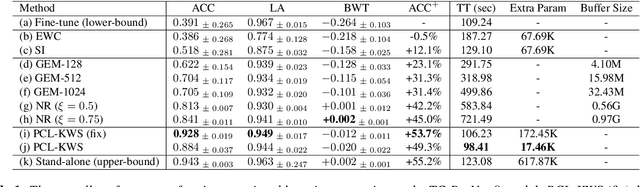
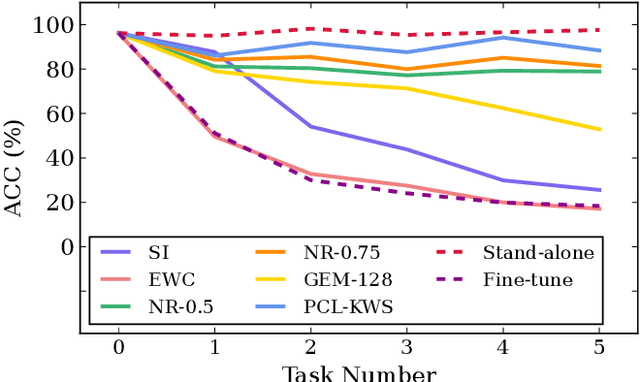
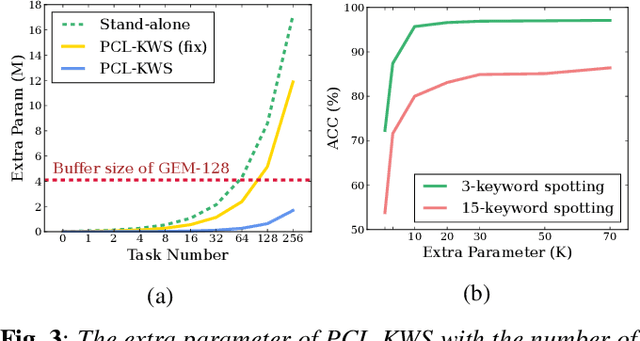
Catastrophic forgetting is a thorny challenge when updating keyword spotting (KWS) models after deployment. To tackle such challenges, we propose a progressive continual learning strategy for small-footprint spoken keyword spotting (PCL-KWS). Specifically, the proposed PCL-KWS framework introduces a network instantiator to generate the task-specific sub-networks for remembering previously learned keywords. As a result, the PCL-KWS approach incrementally learns new keywords without forgetting prior knowledge. Besides, the keyword-aware network scaling mechanism of PCL-KWS constrains the growth of model parameters while achieving high performance. Experimental results show that after learning five new tasks sequentially, our proposed PCL-KWS approach archives the new state-of-the-art performance of 92.8% average accuracy for all the tasks on Google Speech Command dataset compared with other baselines.
Interactive Feature Fusion for End-to-End Noise-Robust Speech Recognition
Oct 11, 2021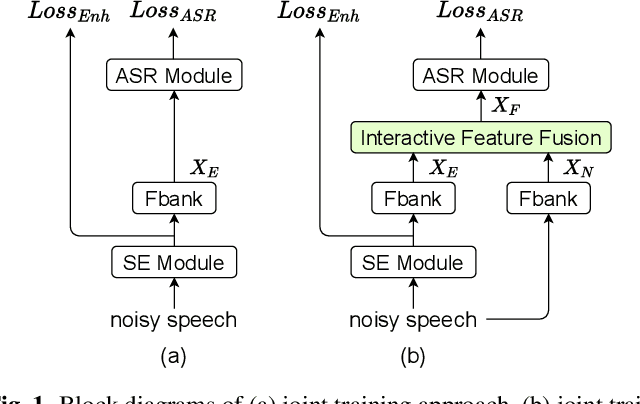
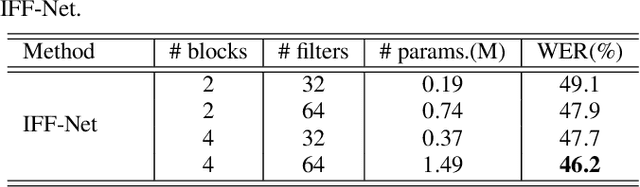
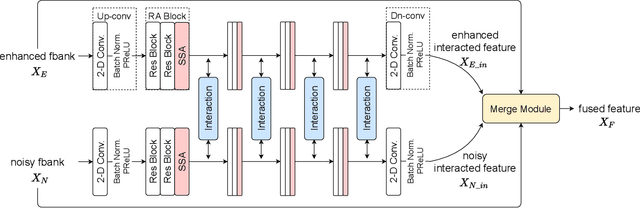
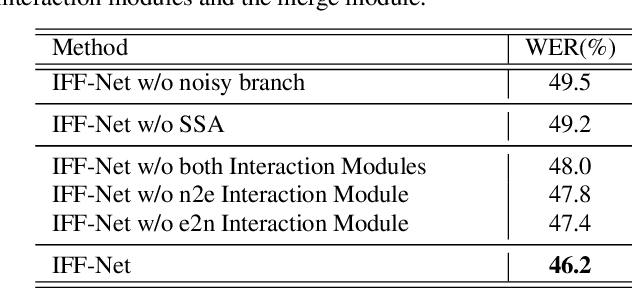
Speech enhancement (SE) aims to suppress the additive noise from a noisy speech signal to improve the speech's perceptual quality and intelligibility. However, the over-suppression phenomenon in the enhanced speech might degrade the performance of downstream automatic speech recognition (ASR) task due to the missing latent information. To alleviate such problem, we propose an interactive feature fusion network (IFF-Net) for noise-robust speech recognition to learn complementary information from the enhanced feature and original noisy feature. Experimental results show that the proposed method achieves absolute word error rate (WER) reduction of 4.1% over the best baseline on RATS Channel-A corpus. Our further analysis indicates that the proposed IFF-Net can complement some missing information in the over-suppressed enhanced feature.
Multitask-Based Joint Learning Approach To Robust ASR For Radio Communication Speech
Jul 22, 2021


To realize robust end-to-end Automatic Speech Recognition(E2E ASR) under radio communication condition, we propose a multitask-based method to joint train a Speech Enhancement (SE) module as the front-end and an E2E ASR model as the back-end in this paper. One of the advantage of the proposed method is that the entire system can be trained from scratch. Different from prior works, either component here doesn't need to perform pre-training and fine-tuning processes separately. Through analysis, we found that the success of the proposed method lies in the following aspects. Firstly, multitask learning is essential, that is the SE network is not only learning to produce more Intelligent speech, it is also aimed to generate speech that is beneficial to recognition. Secondly, we also found speech phase preserved from noisy speech is critical for improving ASR performance. Thirdly, we propose a dual channel data augmentation training method to obtain further improvement.Specifically, we combine the clean and enhanced speech to train the whole system. We evaluate the proposed method on the RATS English data set, achieving a relative WER reduction of 4.6% with the joint training method, and up to a relative WER reduction of 11.2% with the proposed data augmentation method.