 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
How Bad Are Artifacts?: Analyzing the Impact of Speech Enhancement Errors on ASR
Jan 18, 2022
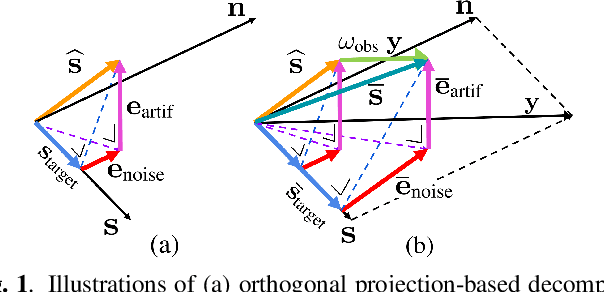
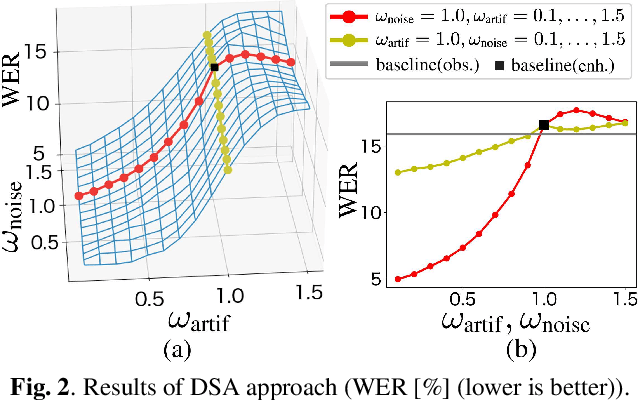
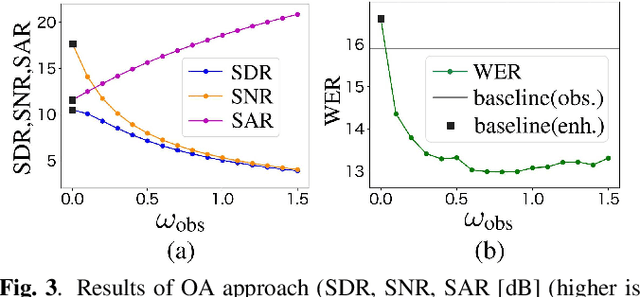
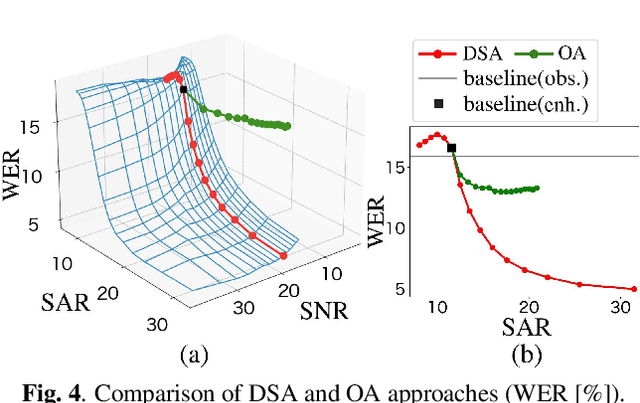
It is challenging to improve automatic speech recognition (ASR) performance in noisy conditions with single-channel speech enhancement (SE). In this paper, we investigate the causes of ASR performance degradation by decomposing the SE errors using orthogonal projection-based decomposition (OPD). OPD decomposes the SE errors into noise and artifact components. The artifact component is defined as the SE error signal that cannot be represented as a linear combination of speech and noise sources. We propose manually scaling the error components to analyze their impact on ASR. We experimentally identify the artifact component as the main cause of performance degradation, and we find that mitigating the artifact can greatly improve ASR performance. Furthermore, we demonstrate that the simple observation adding (OA) technique (i.e., adding a scaled version of the observed signal to the enhanced speech) can monotonically increase the signal-to-artifact ratio under a mild condition. Accordingly, we experimentally confirm that OA improves ASR performance for both simulated and real recordings. The findings of this paper provide a better understanding of the influence of SE errors on ASR and open the door to future research on novel approaches for designing effective single-channel SE front-ends for ASR.
Semi-Supervised Learning Based on Reference Model for Low-resource TTS
Oct 25, 2022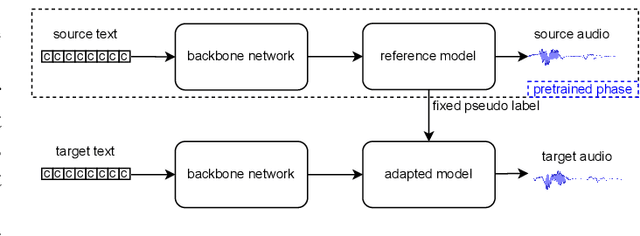
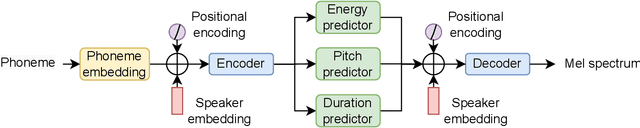
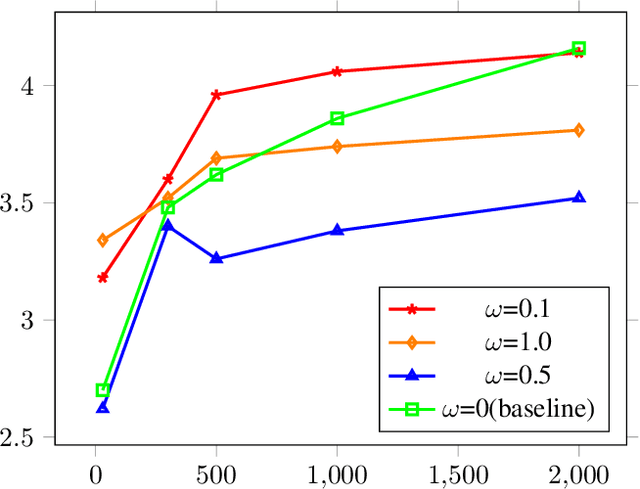
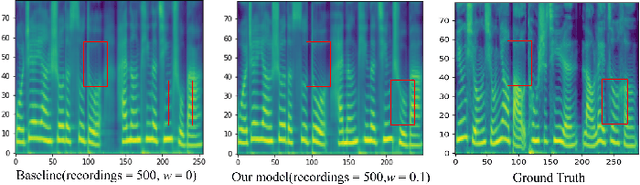
Most previous neural text-to-speech (TTS) methods are mainly based on supervised learning methods, which means they depend on a large training dataset and hard to achieve comparable performance under low-resource conditions. To address this issue, we propose a semi-supervised learning method for neural TTS in which labeled target data is limited, which can also resolve the problem of exposure bias in the previous auto-regressive models. Specifically, we pre-train the reference model based on Fastspeech2 with much source data, fine-tuned on a limited target dataset. Meanwhile, pseudo labels generated by the original reference model are used to guide the fine-tuned model's training further, achieve a regularization effect, and reduce the overfitting of the fine-tuned model during training on the limited target data. Experimental results show that our proposed semi-supervised learning scheme with limited target data significantly improves the voice quality for test data to achieve naturalness and robustness in speech synthesis.
Efficient Training of Neural Transducer for Speech Recognition
Apr 22, 2022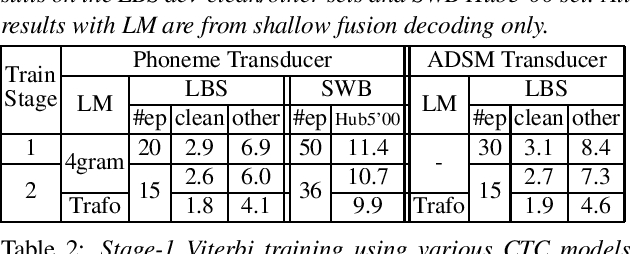
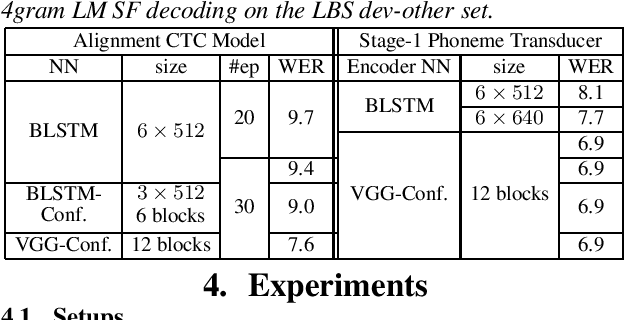
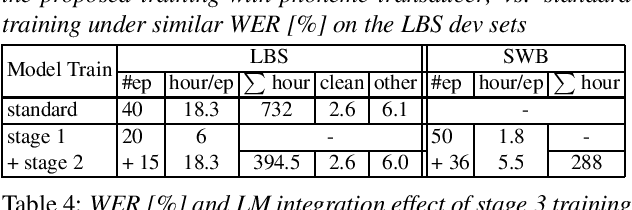
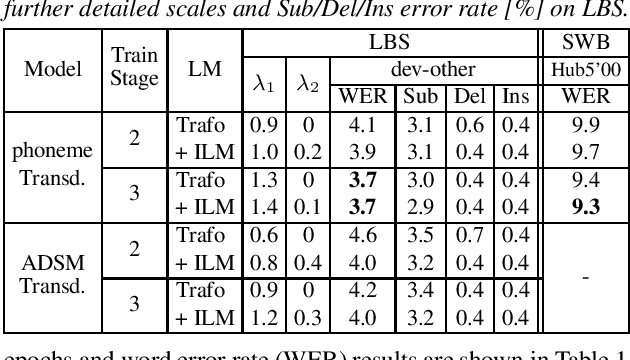
As one of the most popular sequence-to-sequence modeling approaches for speech recognition, the RNN-Transducer has achieved evolving performance with more and more sophisticated neural network models of growing size and increasing training epochs. While strong computation resources seem to be the prerequisite of training superior models, we try to overcome it by carefully designing a more efficient training pipeline. In this work, we propose an efficient 3-stage progressive training pipeline to build highly-performing neural transducer models from scratch with very limited computation resources in a reasonable short time period. The effectiveness of each stage is experimentally verified on both Librispeech and Switchboard corpora. The proposed pipeline is able to train transducer models approaching state-of-the-art performance with a single GPU in just 2-3 weeks. Our best conformer transducer achieves 4.1% WER on Librispeech test-other with only 35 epochs of training.
Compressing Transformer-based self-supervised models for speech processing
Nov 17, 2022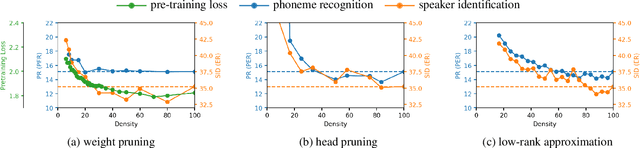
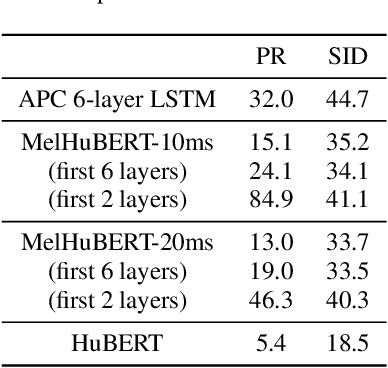
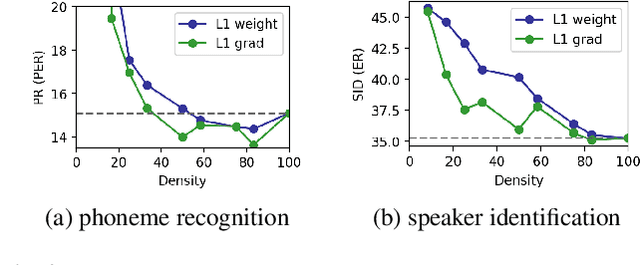
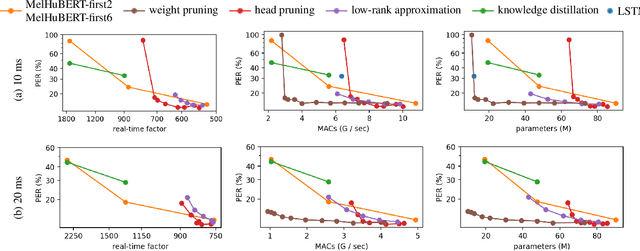
Despite the success of Transformers in self-supervised learning with applications to various downstream tasks, the computational cost of training and inference remains a major challenge for applying these models to a wide spectrum of devices. Several isolated attempts have been made to compress Transformers, prior to applying them to downstream tasks. In this work, we aim to provide context for the isolated results, studying several commonly used compression techniques, including weight pruning, head pruning, low-rank approximation, and knowledge distillation. We report wall-clock time, the number of parameters, and the number of multiply-accumulate operations for these techniques, charting the landscape of compressing Transformer-based self-supervised models.
Personal VAD 2.0: Optimizing Personal Voice Activity Detection for On-Device Speech Recognition
Apr 13, 2022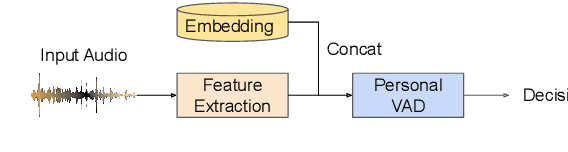
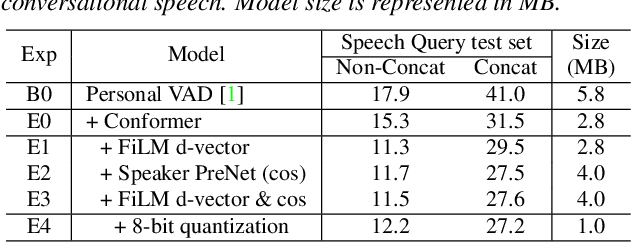
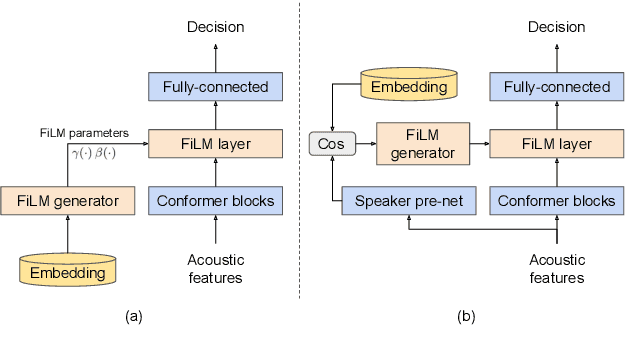
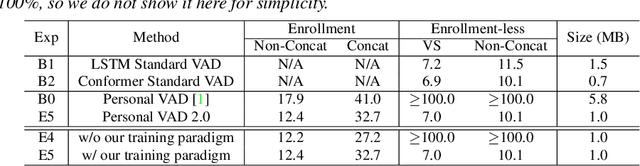
Personalization of on-device speech recognition (ASR) has seen explosive growth in recent years, largely due to the increasing popularity of personal assistant features on mobile devices and smart home speakers. In this work, we present Personal VAD 2.0, a personalized voice activity detector that detects the voice activity of a target speaker, as part of a streaming on-device ASR system. Although previous proof-of-concept studies have validated the effectiveness of Personal VAD, there are still several critical challenges to address before this model can be used in production: first, the quality must be satisfactory in both enrollment and enrollment-less scenarios; second, it should operate in a streaming fashion; and finally, the model size should be small enough to fit a limited latency and CPU/Memory budget. To meet the multi-faceted requirements, we propose a series of novel designs: 1) advanced speaker embedding modulation methods; 2) a new training paradigm to generalize to enrollment-less conditions; 3) architecture and runtime optimizations for latency and resource restrictions. Extensive experiments on a realistic speech recognition system demonstrated the state-of-the-art performance of our proposed method.
Effectiveness of Text, Acoustic, and Lattice-based representations in Spoken Language Understanding tasks
Dec 16, 2022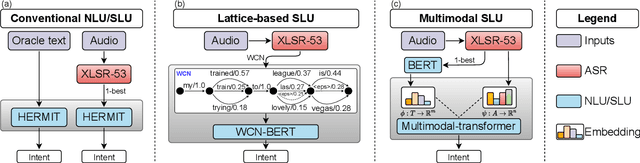
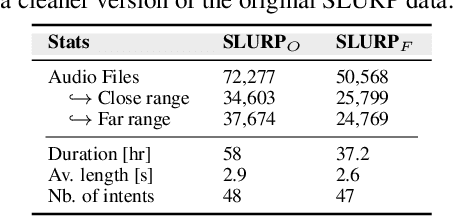
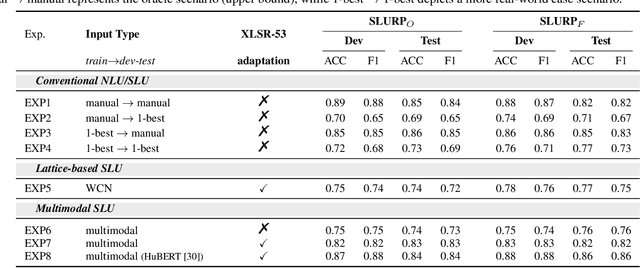

In this paper, we perform an exhaustive evaluation of different representations to address the intent classification problem in a Spoken Language Understanding (SLU) setup. We benchmark three types of systems to perform the SLU intent detection task: 1) text-based, 2) lattice-based, and a novel 3) multimodal approach. Our work provides a comprehensive analysis of what could be the achievable performance of different state-of-the-art SLU systems under different circumstances, e.g., automatically- vs. manually-generated transcripts. We evaluate the systems on the publicly available SLURP spoken language resource corpus. Our results indicate that using richer forms of Automatic Speech Recognition (ASR) outputs allows SLU systems to improve in comparison to the 1-best setup (4% relative improvement). However, crossmodal approaches, i.e., learning from acoustic and text embeddings, obtains performance similar to the oracle setup, and a relative improvement of 18% over the 1-best configuration. Thus, crossmodal architectures represent a good alternative to overcome the limitations of working purely automatically generated textual data.
Dodging the Data Bottleneck: Automatic Subtitling with Automatically Segmented ST Corpora
Sep 21, 2022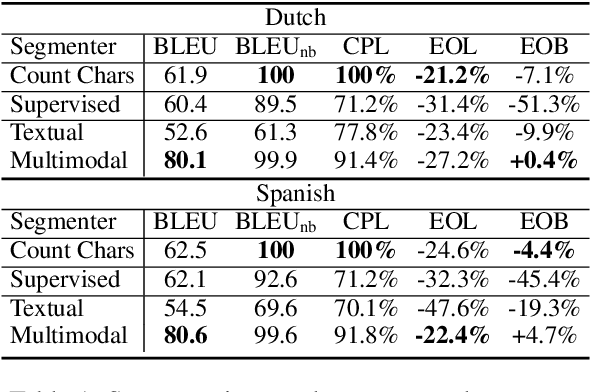
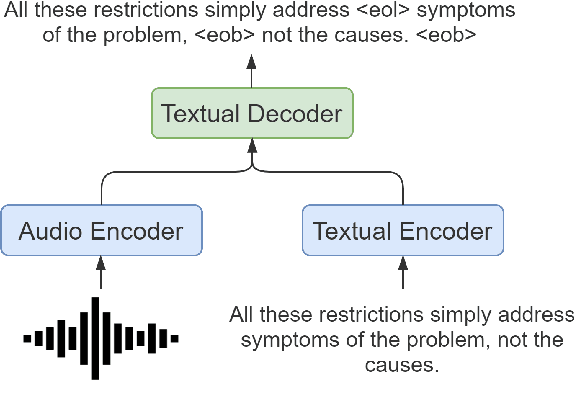
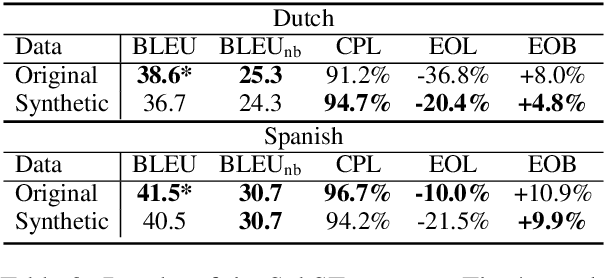
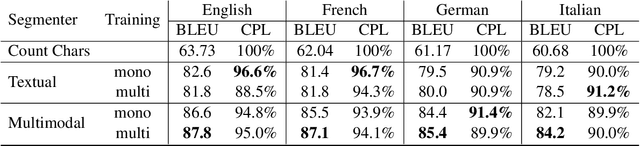
Speech translation for subtitling (SubST) is the task of automatically translating speech data into well-formed subtitles by inserting subtitle breaks compliant to specific displaying guidelines. Similar to speech translation (ST), model training requires parallel data comprising audio inputs paired with their textual translations. In SubST, however, the text has to be also annotated with subtitle breaks. So far, this requirement has represented a bottleneck for system development, as confirmed by the dearth of publicly available SubST corpora. To fill this gap, we propose a method to convert existing ST corpora into SubST resources without human intervention. We build a segmenter model that automatically segments texts into proper subtitles by exploiting audio and text in a multimodal fashion, achieving high segmentation quality in zero-shot conditions. Comparative experiments with SubST systems respectively trained on manual and automatic segmentations result in similar performance, showing the effectiveness of our approach.
Interpretable Acoustic Representation Learning on Breathing and Speech Signals for COVID-19 Detection
Jun 27, 2022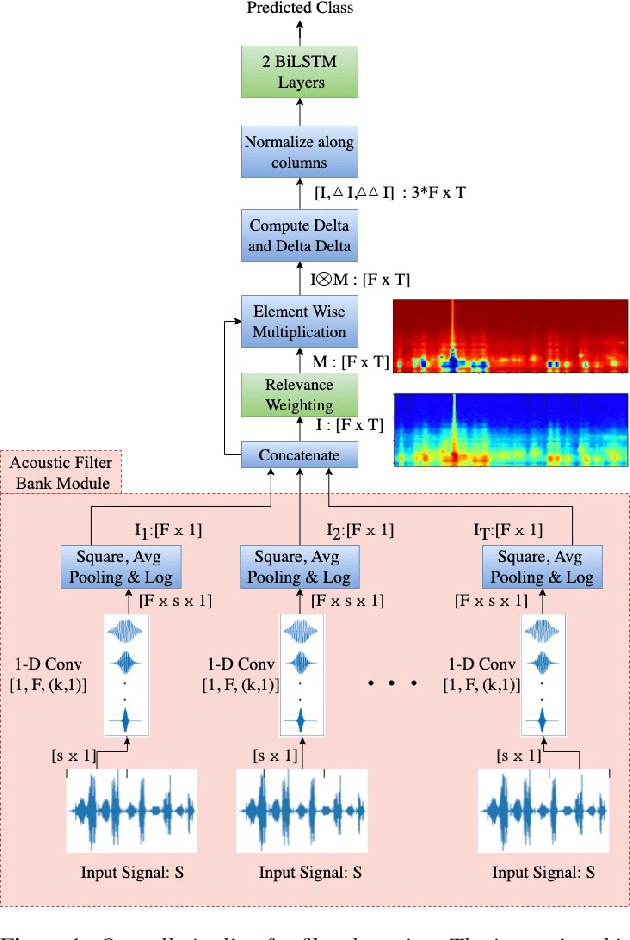
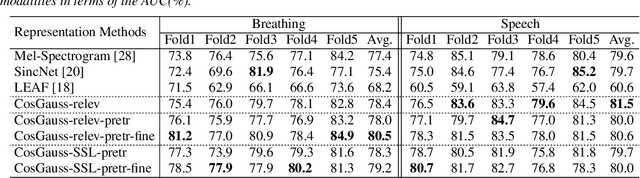
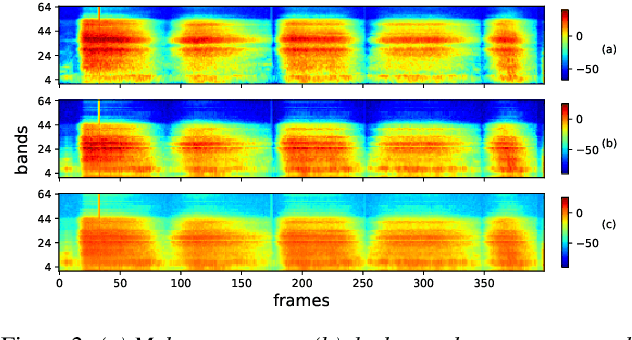
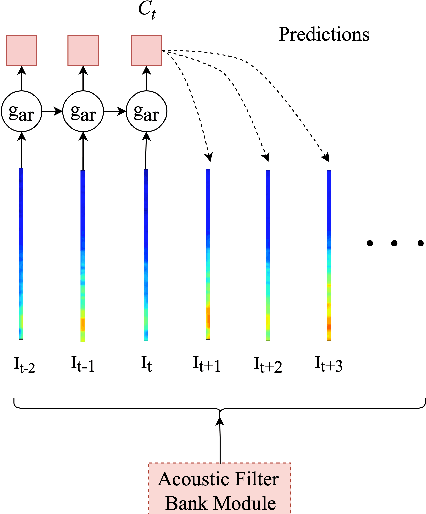
In this paper, we describe an approach for representation learning of audio signals for the task of COVID-19 detection. The raw audio samples are processed with a bank of 1-D convolutional filters that are parameterized as cosine modulated Gaussian functions. The choice of these kernels allows the interpretation of the filterbanks as smooth band-pass filters. The filtered outputs are pooled, log-compressed and used in a self-attention based relevance weighting mechanism. The relevance weighting emphasizes the key regions of the time-frequency decomposition that are important for the downstream task. The subsequent layers of the model consist of a recurrent architecture and the models are trained for a COVID-19 detection task. In our experiments on the Coswara data set, we show that the proposed model achieves significant performance improvements over the baseline system as well as other representation learning approaches. Further, the approach proposed is shown to be uniformly applicable for speech and breathing signals and for transfer learning from a larger data set.
Prabhupadavani: A Code-mixed Speech Translation Data for 25 Languages
Jan 27, 2022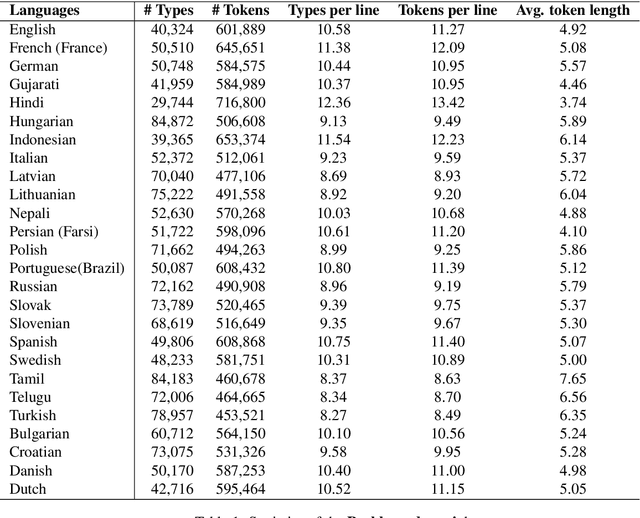
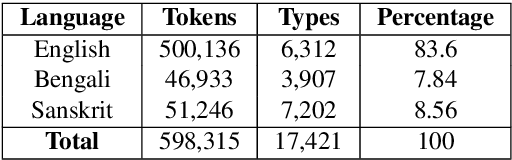


Nowadays, code-mixing has become ubiquitous in Natural Language Processing (NLP); however, no efforts have been made to address this phenomenon for Speech Translation (ST) task. This can be solely attributed to the lack of code-mixed ST task labelled data. Thus, we introduce Prabhupadavani, a multilingual code-mixed ST dataset for 25 languages, covering ten language families, containing 94 hours of speech by 130+ speakers, manually aligned with corresponding text in the target language. Prabhupadvani is the first code-mixed ST dataset available in the ST literature to the best of our knowledge. This data also can be used for a code-mixed machine translation task. All the dataset and code can be accessed at: \url{https://github.com/frozentoad9/CMST}
Predicting Knowledge Gain for MOOC Video Consumption
Dec 13, 2022Informal learning on the Web using search engines as well as more structured learning on MOOC platforms have become very popular in recent years. As a result of the vast amount of available learning resources, intelligent retrieval and recommendation methods are indispensable -- this is true also for MOOC videos. However, the automatic assessment of this content with regard to predicting (potential) knowledge gain has not been addressed by previous work yet. In this paper, we investigate whether we can predict learning success after MOOC video consumption using 1) multimodal features covering slide and speech content, and 2) a wide range of text-based features describing the content of the video. In a comprehensive experimental setting, we test four different classifiers and various feature subset combinations. We conduct a detailed feature importance analysis to gain insights in which modality benefits knowledge gain prediction the most.
* 13 pages, 1 figure, 3 tables