 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhose Voice Counts? Mapping Stakeholder Perspectives on AI Through Public Submissions to the U.S. Government
May 21, 2026As artificial intelligence (AI) systems become more common in our daily lives, it is important to understand how different stakeholders comprehend and envisage the role that these technologies play in shaping social, political, and economic realities. In this paper, we investigate public perceptions of AI based on a corpus of letters submitted during the public consultation for the Trump Administration's US AI Action Plan. To this aim, we release a corpus cleaning pipeline and perform topic modelling and frequency analysis to explore predominant topics discussed by different subgroups (e.g., academia, individuals, private sector) and those appearing in the AI Action Plan. Our results show that individuals voice strong concerns related to the impact of AI on life, while other stakeholders are more concerned with AI development. Our comparison of topics suggests that the AI Action Plan reflects predominantly the concerns of the private sector on security, policies, and development, with individuals' concerns less represented.
Smarter edits? Post-editing with error highlights and translation suggestions
May 20, 2026As MT quality increases, interest in enhanced post-editing features such as QE-derived error highlights is growing, yet evidence for their usefulness remains limited. In this work, we explore the usefulness of LLM-derived error highlights and correction suggestions based on automatic post-editing (APE). We conduct a study where professional translators (En-Nl) post-edit translations using APE error highlights and correction suggestions and compare productivity, quality and user experience to regular PE and PE with QE-derived highlights. While no condition yielded productivity or quality gains compared to regular PE, APE highlights were better received than QE-derived highlights, and correction suggestions improved overall user experience.
Direct Speech Translation for Automatic Subtitling
Sep 27, 2022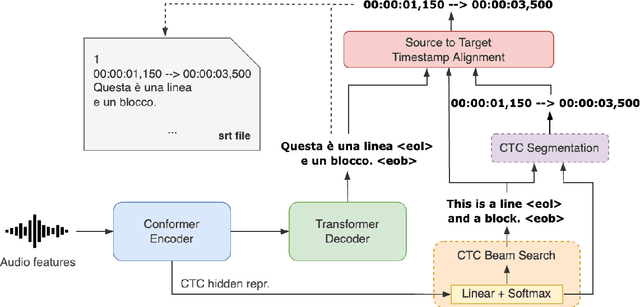
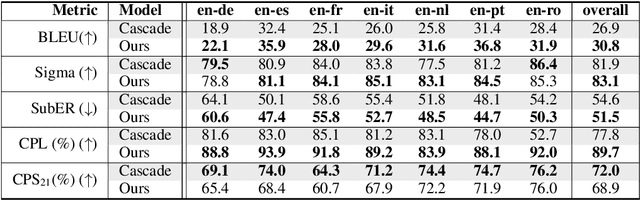
Automatic subtitling is the task of automatically translating the speech of an audiovisual product into short pieces of timed text, in other words, subtitles and their corresponding timestamps. The generated subtitles need to conform to multiple space and time requirements (length, reading speed) while being synchronised with the speech and segmented in a way that facilitates comprehension. Given its considerable complexity, automatic subtitling has so far been addressed through a pipeline of elements that deal separately with transcribing, translating, segmenting into subtitles and predicting timestamps. In this paper, we propose the first direct automatic subtitling model that generates target language subtitles and their timestamps from the source speech in a single solution. Comparisons with state-of-the-art cascaded models trained with both in- and out-domain data show that our system provides high-quality subtitles while also being competitive in terms of conformity, with all the advantages of maintaining a single model.
Dodging the Data Bottleneck: Automatic Subtitling with Automatically Segmented ST Corpora
Sep 21, 2022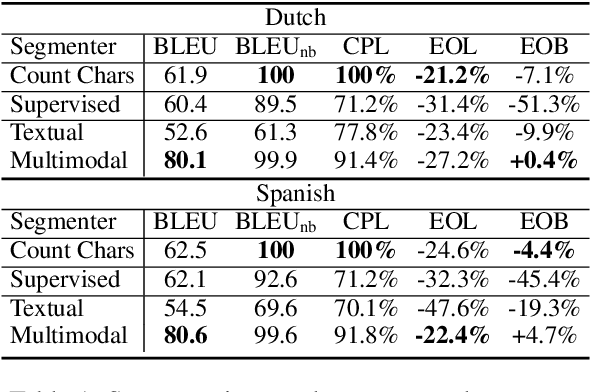
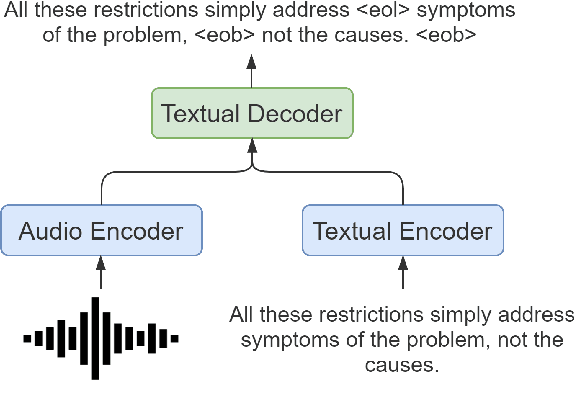
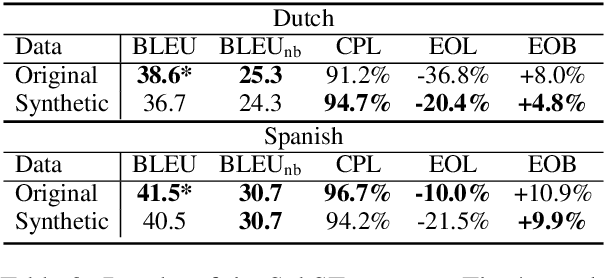
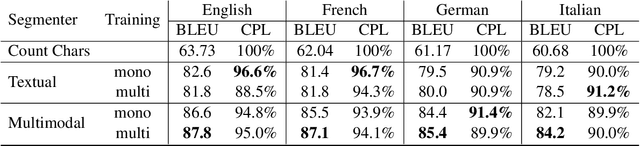
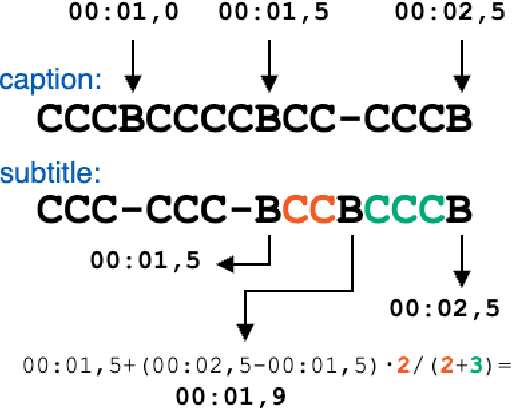
Speech translation for subtitling (SubST) is the task of automatically translating speech data into well-formed subtitles by inserting subtitle breaks compliant to specific displaying guidelines. Similar to speech translation (ST), model training requires parallel data comprising audio inputs paired with their textual translations. In SubST, however, the text has to be also annotated with subtitle breaks. So far, this requirement has represented a bottleneck for system development, as confirmed by the dearth of publicly available SubST corpora. To fill this gap, we propose a method to convert existing ST corpora into SubST resources without human intervention. We build a segmenter model that automatically segments texts into proper subtitles by exploiting audio and text in a multimodal fashion, achieving high segmentation quality in zero-shot conditions. Comparative experiments with SubST systems respectively trained on manual and automatic segmentations result in similar performance, showing the effectiveness of our approach.
Evaluating Subtitle Segmentation for End-to-end Generation Systems
May 19, 2022



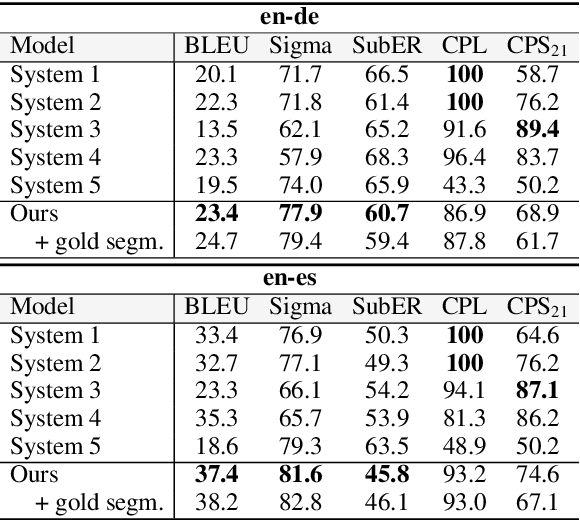
Subtitles appear on screen as short pieces of text, segmented based on formal constraints (length) and syntactic/semantic criteria. Subtitle segmentation can be evaluated with sequence segmentation metrics against a human reference. However, standard segmentation metrics cannot be applied when systems generate outputs different than the reference, e.g. with end-to-end subtitling systems. In this paper, we study ways to conduct reference-based evaluations of segmentation accuracy irrespective of the textual content. We first conduct a systematic analysis of existing metrics for evaluating subtitle segmentation. We then introduce $Sigma$, a new Subtitle Segmentation Score derived from an approximate upper-bound of BLEU on segmentation boundaries, which allows us to disentangle the effect of good segmentation from text quality. To compare $Sigma$ with existing metrics, we further propose a boundary projection method from imperfect hypotheses to the true reference. Results show that all metrics are able to reward high quality output but for similar outputs system ranking depends on each metric's sensitivity to error type. Our thorough analyses suggest $Sigma$ is a promising segmentation candidate but its reliability over other segmentation metrics remains to be validated through correlations with human judgements.
Simultaneous Speech Translation for Live Subtitling: from Delay to Display
Jul 20, 2021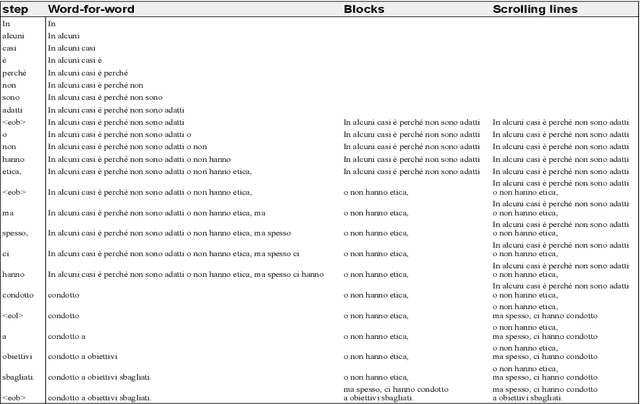
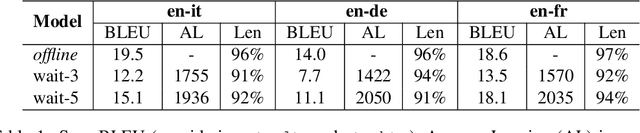
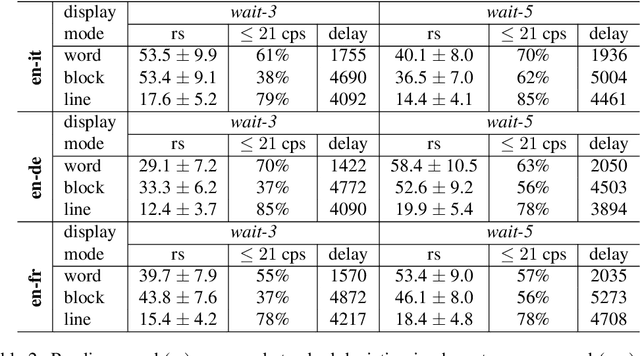
With the increased audiovisualisation of communication, the need for live subtitles in multilingual events is more relevant than ever. In an attempt to automatise the process, we aim at exploring the feasibility of simultaneous speech translation (SimulST) for live subtitling. However, the word-for-word rate of generation of SimulST systems is not optimal for displaying the subtitles in a comprehensible and readable way. In this work, we adapt SimulST systems to predict subtitle breaks along with the translation. We then propose a display mode that exploits the predicted break structure by presenting the subtitles in scrolling lines. We compare our proposed mode with a display 1) word-for-word and 2) in blocks, in terms of reading speed and delay. Experiments on three language pairs (en$\rightarrow$it, de, fr) show that scrolling lines is the only mode achieving an acceptable reading speed while keeping delay close to a 4-second threshold. We argue that simultaneous translation for readable live subtitles still faces challenges, the main one being poor translation quality, and propose directions for steering future research.
Between Flexibility and Consistency: Joint Generation of Captions and Subtitles
Jul 13, 2021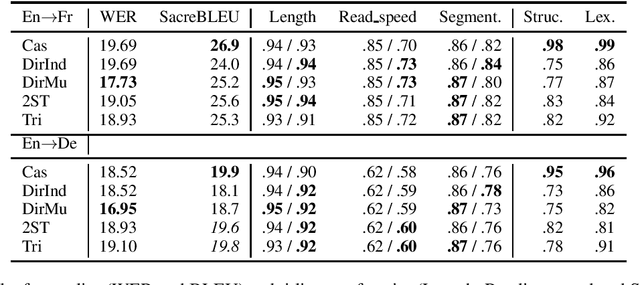
Speech translation (ST) has lately received growing interest for the generation of subtitles without the need for an intermediate source language transcription and timing (i.e. captions). However, the joint generation of source captions and target subtitles does not only bring potential output quality advantages when the two decoding processes inform each other, but it is also often required in multilingual scenarios. In this work, we focus on ST models which generate consistent captions-subtitles in terms of structure and lexical content. We further introduce new metrics for evaluating subtitling consistency. Our findings show that joint decoding leads to increased performance and consistency between the generated captions and subtitles while still allowing for sufficient flexibility to produce subtitles conforming to language-specific needs and norms.
Cascade versus Direct Speech Translation: Do the Differences Still Make a Difference?
Jun 02, 2021

Five years after the first published proofs of concept, direct approaches to speech translation (ST) are now competing with traditional cascade solutions. In light of this steady progress, can we claim that the performance gap between the two is closed? Starting from this question, we present a systematic comparison between state-of-the-art systems representative of the two paradigms. Focusing on three language directions (English-German/Italian/Spanish), we conduct automatic and manual evaluations, exploiting high-quality professional post-edits and annotations. Our multi-faceted analysis on one of the few publicly available ST benchmarks attests for the first time that: i) the gap between the two paradigms is now closed, and ii) the subtle differences observed in their behavior are not sufficient for humans neither to distinguish them nor to prefer one over the other.
Is 42 the Answer to Everything in Subtitling-oriented Speech Translation?
Jun 01, 2020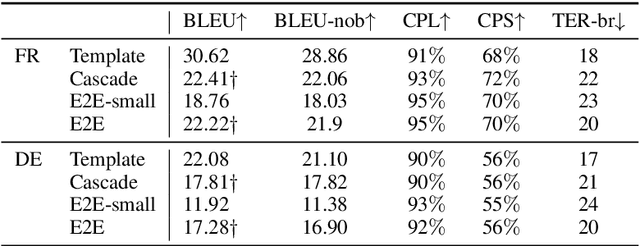
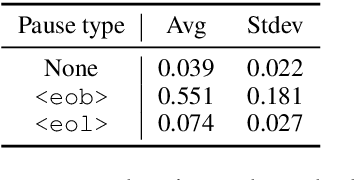

Subtitling is becoming increasingly important for disseminating information, given the enormous amounts of audiovisual content becoming available daily. Although Neural Machine Translation (NMT) can speed up the process of translating audiovisual content, large manual effort is still required for transcribing the source language, and for spotting and segmenting the text into proper subtitles. Creating proper subtitles in terms of timing and segmentation highly depends on information present in the audio (utterance duration, natural pauses). In this work, we explore two methods for applying Speech Translation (ST) to subtitling: a) a direct end-to-end and b) a classical cascade approach. We discuss the benefit of having access to the source language speech for improving the conformity of the generated subtitles to the spatial and temporal subtitling constraints and show that length is not the answer to everything in the case of subtitling-oriented ST.
MuST-Cinema: a Speech-to-Subtitles corpus
Feb 25, 2020
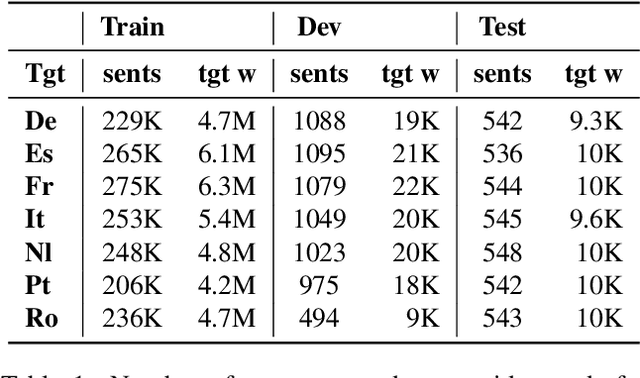

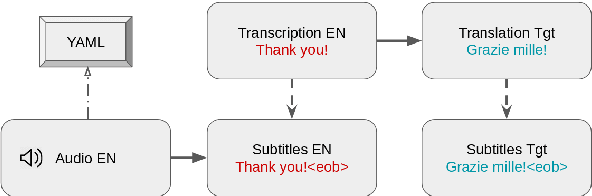
Growing needs in localising audiovisual content in multiple languages through subtitles call for the development of automatic solutions for human subtitling. Neural Machine Translation (NMT) can contribute to the automatisation of subtitling, facilitating the work of human subtitlers and reducing turn-around times and related costs. NMT requires high-quality, large, task-specific training data. The existing subtitling corpora, however, are missing both alignments to the source language audio and important information about subtitle breaks. This poses a significant limitation for developing efficient automatic approaches for subtitling, since the length and form of a subtitle directly depends on the duration of the utterance. In this work, we present MuST-Cinema, a multilingual speech translation corpus built from TED subtitles. The corpus is comprised of (audio, transcription, translation) triplets. Subtitle breaks are preserved by inserting special symbols. We show that the corpus can be used to build models that efficiently segment sentences into subtitles and propose a method for annotating existing subtitling corpora with subtitle breaks, conforming to the constraint of length.