 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Efficient Transformer-based Speech Enhancement Using Long Frames and STFT Magnitudes
Jun 23, 2022
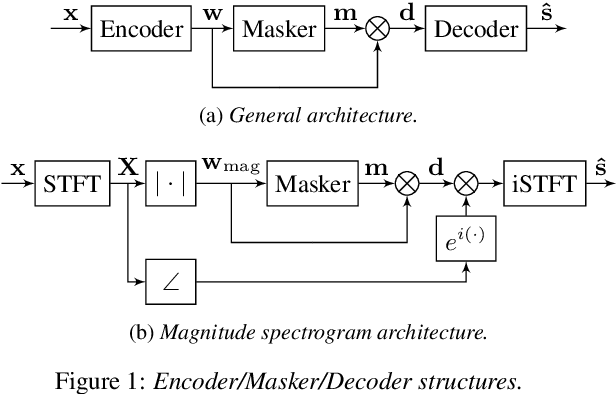
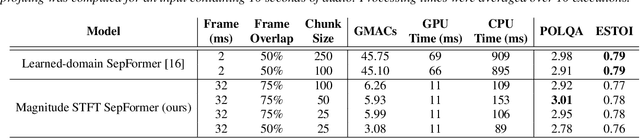
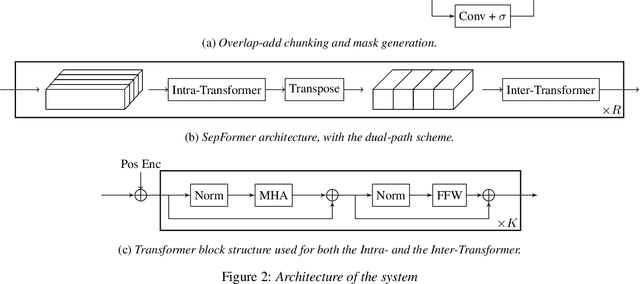
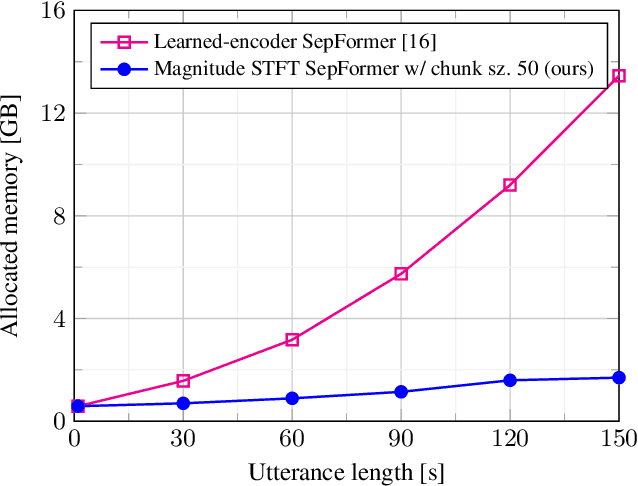
The SepFormer architecture shows very good results in speech separation. Like other learned-encoder models, it uses short frames, as they have been shown to obtain better performance in these cases. This results in a large number of frames at the input, which is problematic; since the SepFormer is transformer-based, its computational complexity drastically increases with longer sequences. In this paper, we employ the SepFormer in a speech enhancement task and show that by replacing the learned-encoder features with a magnitude short-time Fourier transform (STFT) representation, we can use long frames without compromising perceptual enhancement performance. We obtained equivalent quality and intelligibility evaluation scores while reducing the number of operations by a factor of approximately 8 for a 10-second utterance.
BrainBERT: Self-supervised representation learning for intracranial recordings
Feb 28, 2023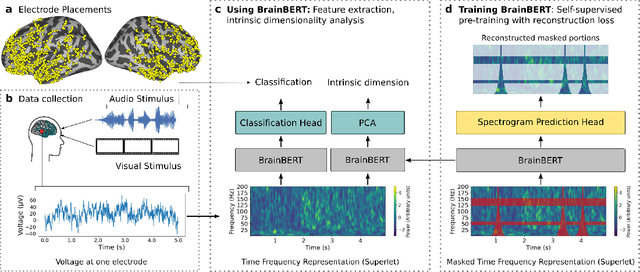
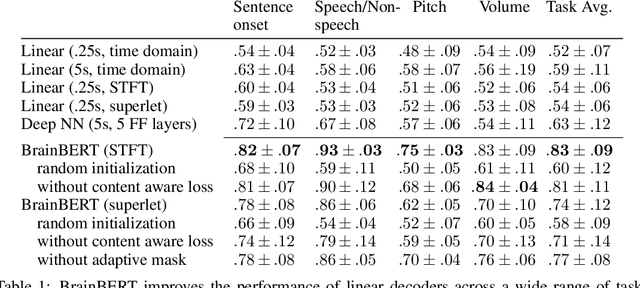
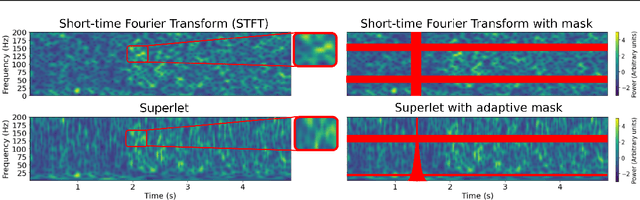
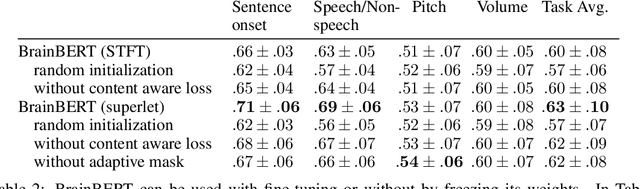
We create a reusable Transformer, BrainBERT, for intracranial recordings bringing modern representation learning approaches to neuroscience. Much like in NLP and speech recognition, this Transformer enables classifying complex concepts, i.e., decoding neural data, with higher accuracy and with much less data by being pretrained in an unsupervised manner on a large corpus of unannotated neural recordings. Our approach generalizes to new subjects with electrodes in new positions and to unrelated tasks showing that the representations robustly disentangle the neural signal. Just like in NLP where one can study language by investigating what a language model learns, this approach opens the door to investigating the brain by what a model of the brain learns. As a first step along this path, we demonstrate a new analysis of the intrinsic dimensionality of the computations in different areas of the brain. To construct these representations, we combine a technique for producing super-resolution spectrograms of neural data with an approach designed for generating contextual representations of audio by masking. In the future, far more concepts will be decodable from neural recordings by using representation learning, potentially unlocking the brain like language models unlocked language.
Meeting the Needs of Low-Resource Languages: The Value of Automatic Alignments via Pretrained Models
Feb 15, 2023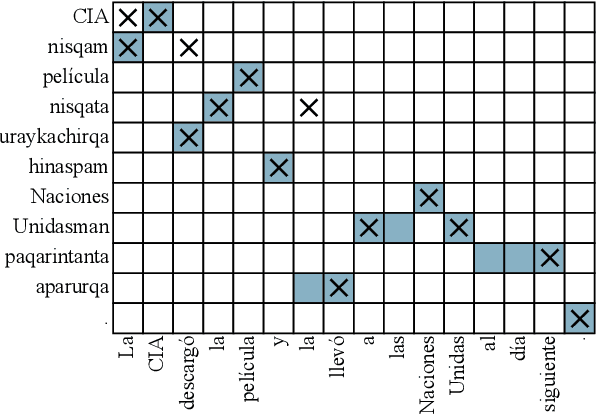
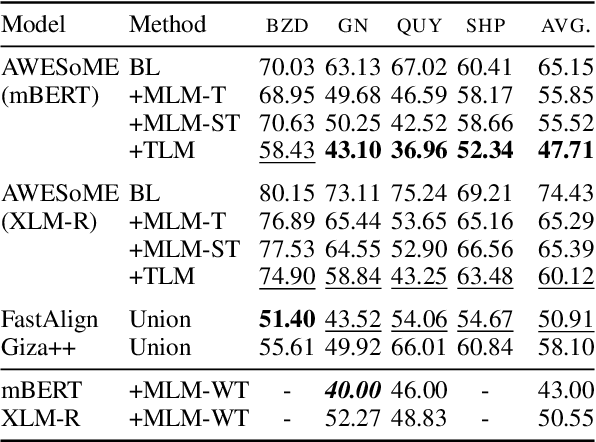
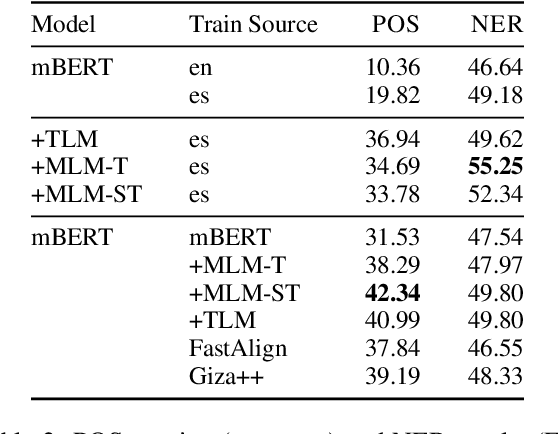
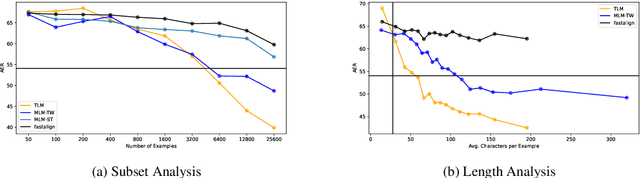
Large multilingual models have inspired a new class of word alignment methods, which work well for the model's pretraining languages. However, the languages most in need of automatic alignment are low-resource and, thus, not typically included in the pretraining data. In this work, we ask: How do modern aligners perform on unseen languages, and are they better than traditional methods? We contribute gold-standard alignments for Bribri--Spanish, Guarani--Spanish, Quechua--Spanish, and Shipibo-Konibo--Spanish. With these, we evaluate state-of-the-art aligners with and without model adaptation to the target language. Finally, we also evaluate the resulting alignments extrinsically through two downstream tasks: named entity recognition and part-of-speech tagging. We find that although transformer-based methods generally outperform traditional models, the two classes of approach remain competitive with each other.
Separator-Transducer-Segmenter: Streaming Recognition and Segmentation of Multi-party Speech
May 10, 2022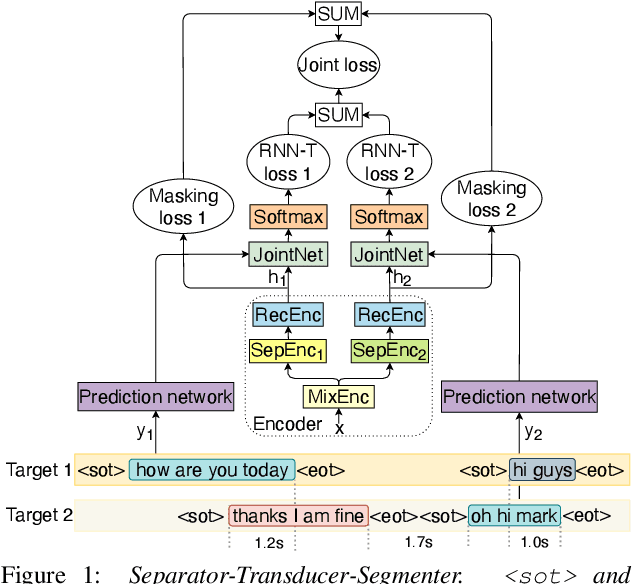
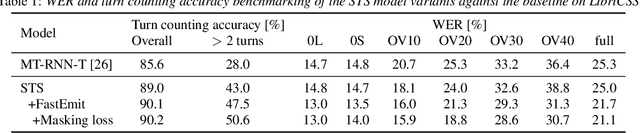

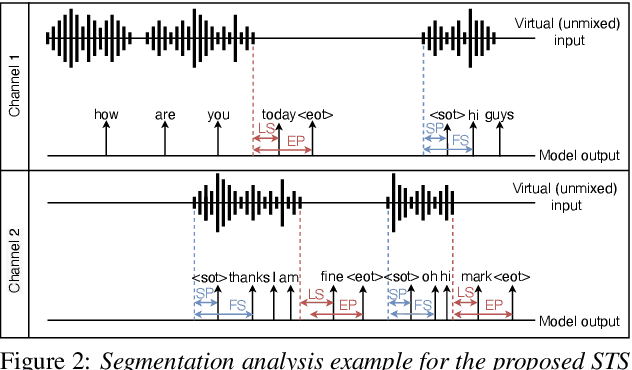
Streaming recognition and segmentation of multi-party conversations with overlapping speech is crucial for the next generation of voice assistant applications. In this work we address its challenges discovered in the previous work on multi-turn recurrent neural network transducer (MT-RNN-T) with a novel approach, separator-transducer-segmenter (STS), that enables tighter integration of speech separation, recognition and segmentation in a single model. First, we propose a new segmentation modeling strategy through start-of-turn and end-of-turn tokens that improves segmentation without recognition accuracy degradation. Second, we further improve both speech recognition and segmentation accuracy through an emission regularization method, FastEmit, and multi-task training with speech activity information as an additional training signal. Third, we experiment with end-of-turn emission latency penalty to improve end-point detection for each speaker turn. Finally, we establish a novel framework for segmentation analysis of multi-party conversations through emission latency metrics. With our best model, we report 4.6% abs. turn counting accuracy improvement and 17% rel. word error rate (WER) improvement on LibriCSS dataset compared to the previously published work.
Supervised Acoustic Embeddings And Their Transferability Across Languages
Jan 03, 2023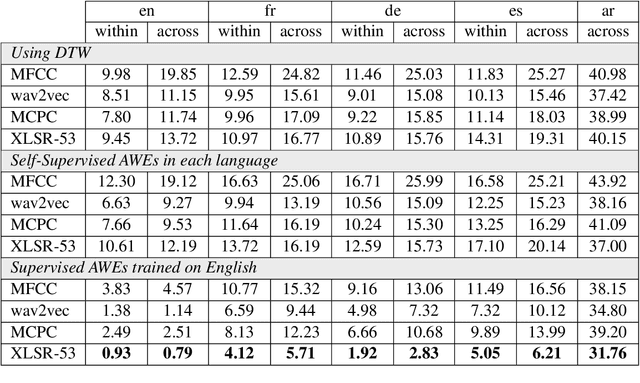
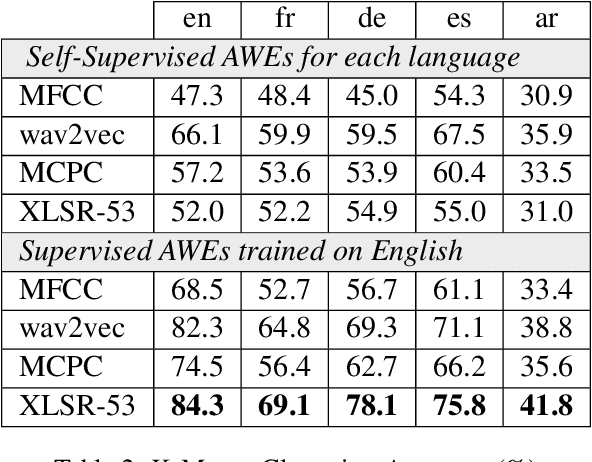
In speech recognition, it is essential to model the phonetic content of the input signal while discarding irrelevant factors such as speaker variations and noise, which is challenging in low-resource settings. Self-supervised pre-training has been proposed as a way to improve both supervised and unsupervised speech recognition, including frame-level feature representations and Acoustic Word Embeddings (AWE) for variable-length segments. However, self-supervised models alone cannot learn perfect separation of the linguistic content as they are trained to optimize indirect objectives. In this work, we experiment with different pre-trained self-supervised features as input to AWE models and show that they work best within a supervised framework. Models trained on English can be transferred to other languages with no adaptation and outperform self-supervised models trained solely on the target languages.
Efficiency 360: Efficient Vision Transformers
Feb 17, 2023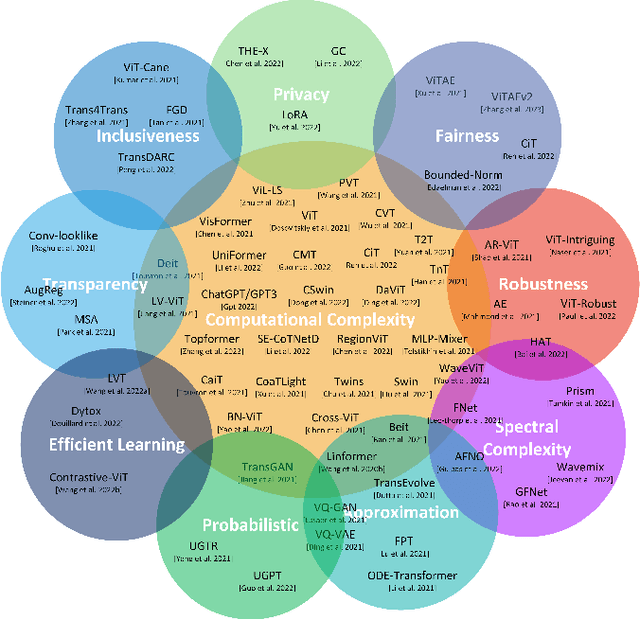
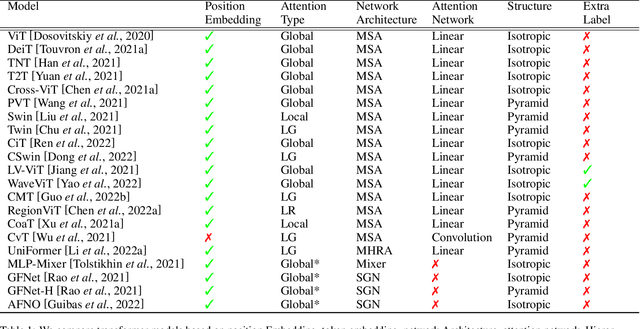
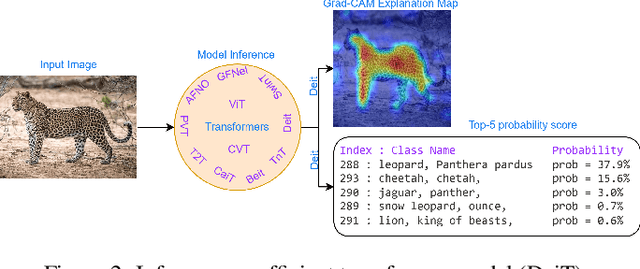
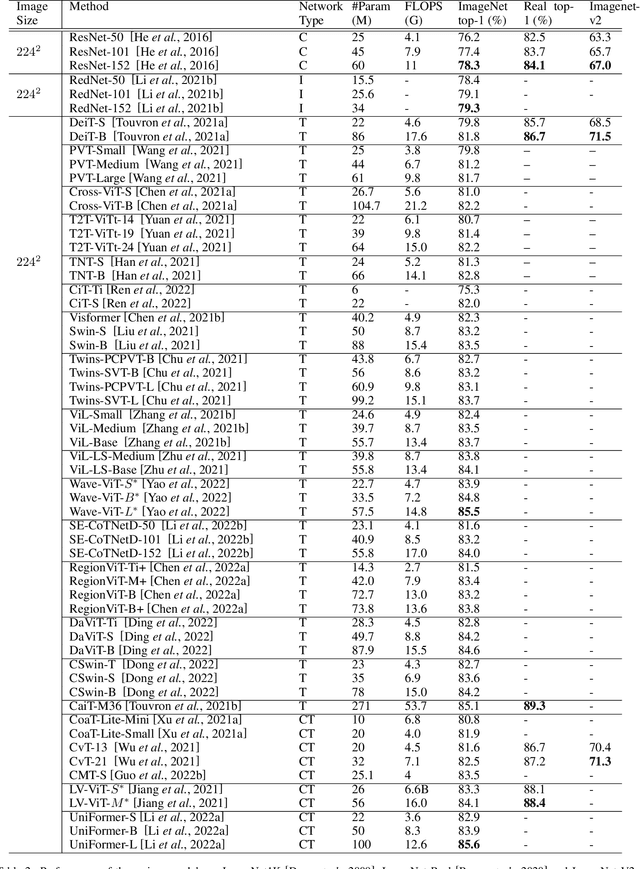
Transformers are widely used for solving tasks in natural language processing, computer vision, speech, and music domains. In this paper, we talk about the efficiency of transformers in terms of memory (the number of parameters), computation cost (number of floating points operations), and performance of models, including accuracy, the robustness of the model, and fair \& bias-free features. We mainly discuss the vision transformer for the image classification task. Our contribution is to introduce an efficient 360 framework, which includes various aspects of the vision transformer, to make it more efficient for industrial applications. By considering those applications, we categorize them into multiple dimensions such as privacy, robustness, transparency, fairness, inclusiveness, continual learning, probabilistic models, approximation, computational complexity, and spectral complexity. We compare various vision transformer models based on their performance, the number of parameters, and the number of floating point operations (FLOPs) on multiple datasets.
Minimum Processing Near-end Listening Enhancement
Oct 31, 2022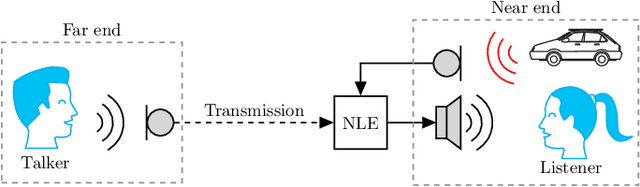
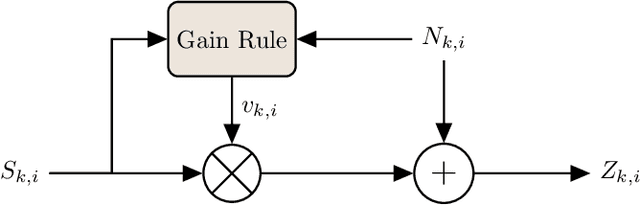
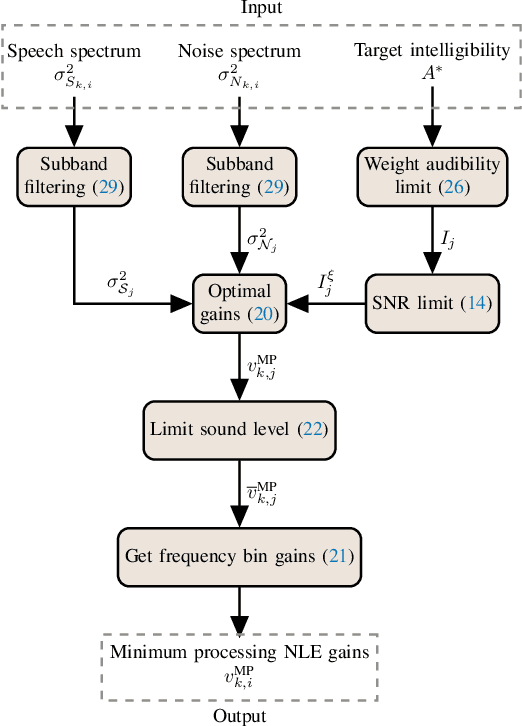
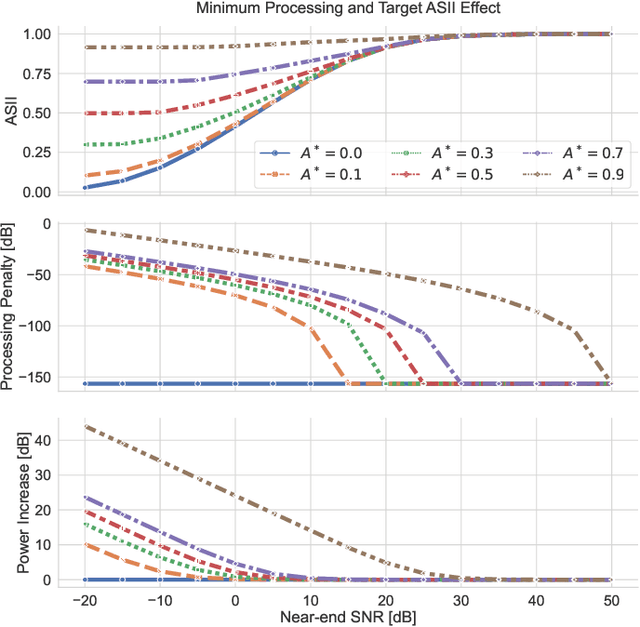
The intelligibility and quality of speech from a mobile phone or public announcement system are often affected by background noise in the listening environment. By pre-processing the speech signal it is possible to improve the speech intelligibility and quality -- this is known as near-end listening enhancement (NLE). Although, existing NLE techniques are able to greatly increase intelligibility in harsh noise environments, in favorable noise conditions the intelligibility of speech reaches a ceiling where it cannot be further enhanced. Actually, the focus of existing methods solely on improving the intelligibility causes unnecessary processing of the speech signal and leads to speech distortions and quality degradations. In this paper, we provide a new rationale for NLE, where the target speech is minimally processed in terms of a processing penalty, provided that a certain performance constraint, e.g., intelligibility, is satisfied. We present a closed-form solution for the case where the performance criterion is an intelligibility estimator based on the approximated speech intelligibility index and the processing penalty is the mean-square error between the processed and the clean speech. This produces an NLE method that adapts to changing noise conditions via a simple gain rule by limiting the processing to the minimum necessary to achieve a desired intelligibility, while at the same time focusing on quality in favorable noise situations by minimizing the amount of speech distortions. Through simulation studies, we show the proposed method attains speech quality on par or better than existing methods in both objective measurements and subjective listening tests, whilst still sustaining objective speech intelligibility performance on par with existing methods.
Data Augmentation with Locally-time Reversed Speech for Automatic Speech Recognition
Oct 09, 2021
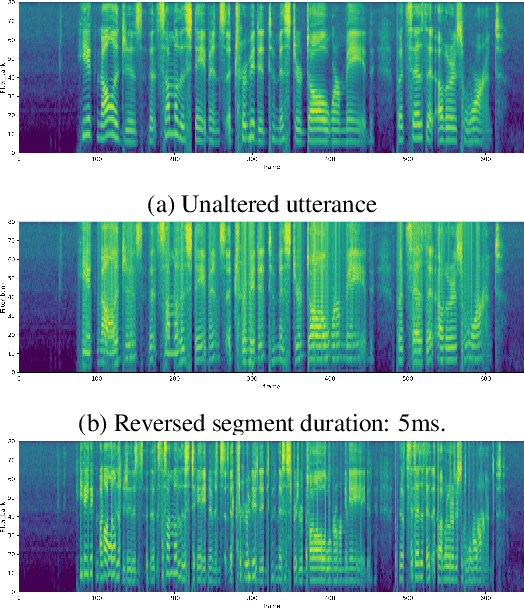
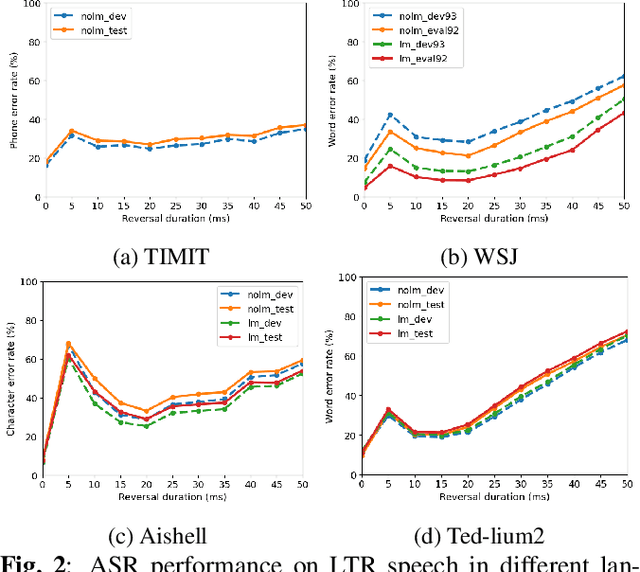
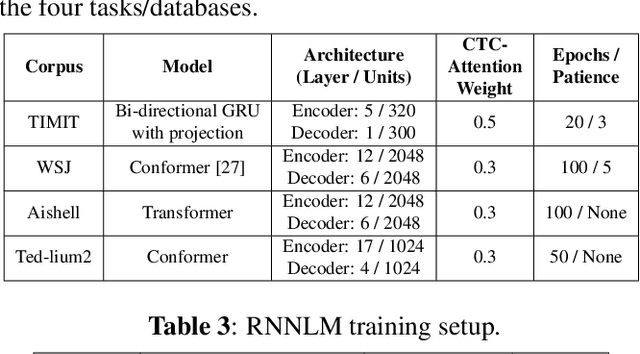
Psychoacoustic studies have shown that locally-time reversed (LTR) speech, i.e., signal samples time-reversed within a short segment, can be accurately recognised by human listeners. This study addresses the question of how well a state-of-the-art automatic speech recognition (ASR) system would perform on LTR speech. The underlying objective is to explore the feasibility of deploying LTR speech in the training of end-to-end (E2E) ASR models, as an attempt to data augmentation for improving the recognition performance. The investigation starts with experiments to understand the effect of LTR speech on general-purpose ASR. LTR speech with reversed segment duration of 5 ms - 50 ms is rendered and evaluated. For ASR training data augmentation with LTR speech, training sets are created by combining natural speech with different partitions of LTR speech. The efficacy of data augmentation is confirmed by ASR results on speech corpora in various languages and speaking styles. ASR on LTR speech with reversed segment duration of 15 ms - 30 ms is found to have lower error rate than with other segment duration. Data augmentation with these LTR speech achieves satisfactory and consistent improvement on ASR performance.
Learning Hierarchical Cross-Modal Association for Co-Speech Gesture Generation
Mar 24, 2022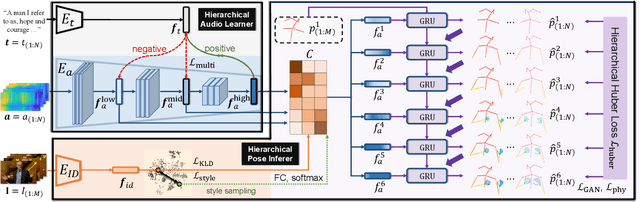
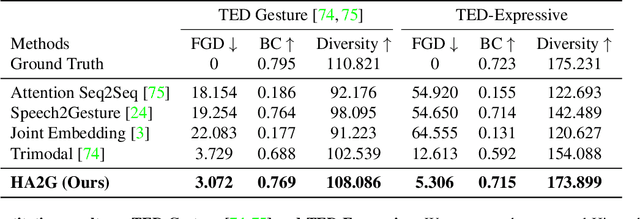
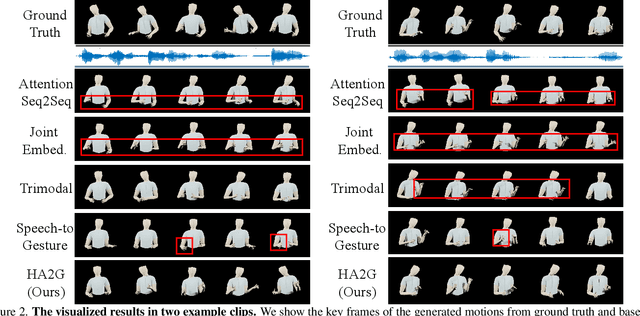

Generating speech-consistent body and gesture movements is a long-standing problem in virtual avatar creation. Previous studies often synthesize pose movement in a holistic manner, where poses of all joints are generated simultaneously. Such a straightforward pipeline fails to generate fine-grained co-speech gestures. One observation is that the hierarchical semantics in speech and the hierarchical structures of human gestures can be naturally described into multiple granularities and associated together. To fully utilize the rich connections between speech audio and human gestures, we propose a novel framework named Hierarchical Audio-to-Gesture (HA2G) for co-speech gesture generation. In HA2G, a Hierarchical Audio Learner extracts audio representations across semantic granularities. A Hierarchical Pose Inferer subsequently renders the entire human pose gradually in a hierarchical manner. To enhance the quality of synthesized gestures, we develop a contrastive learning strategy based on audio-text alignment for better audio representations. Extensive experiments and human evaluation demonstrate that the proposed method renders realistic co-speech gestures and outperforms previous methods in a clear margin. Project page: https://alvinliu0.github.io/projects/HA2G
Adaptable End-to-End ASR Models using Replaceable Internal LMs and Residual Softmax
Feb 16, 2023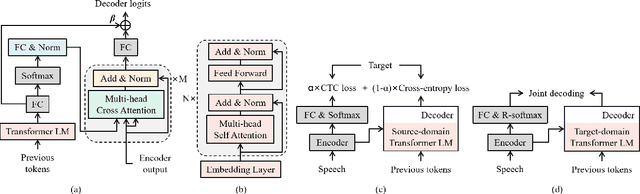
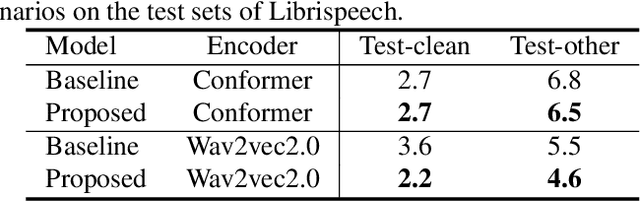
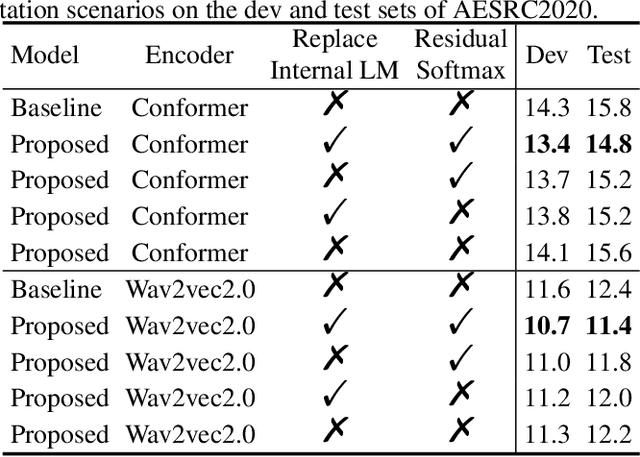
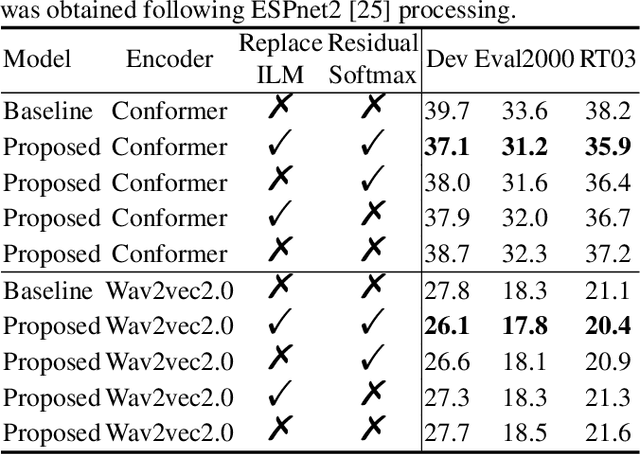
End-to-end (E2E) automatic speech recognition (ASR) implicitly learns the token sequence distribution of paired audio-transcript training data. However, it still suffers from domain shifts from training to testing, and domain adaptation is still challenging. To alleviate this problem, this paper designs a replaceable internal language model (RILM) method, which makes it feasible to directly replace the internal language model (LM) of E2E ASR models with a target-domain LM in the decoding stage when a domain shift is encountered. Furthermore, this paper proposes a residual softmax (R-softmax) that is designed for CTC-based E2E ASR models to adapt to the target domain without re-training during inference. For E2E ASR models trained on the LibriSpeech corpus, experiments showed that the proposed methods gave a 2.6% absolute WER reduction on the Switchboard data and a 1.0% WER reduction on the AESRC2020 corpus while maintaining intra-domain ASR results.