 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToo Good to Be True: A Study on Modern Automatic Speech Recognition for the Evaluation of Speech Enhancement
May 12, 2026Speech enhancement (SE) systems are typically evaluated using a variety of instrumental metrics. The use of automatic speech recognition (ASR) systems to evaluate SE performance is common in literature, usually in terms of word error rate (WER). However, WER scores depend heavily on the choice of ASR system and text normalization pipeline. In this paper, we investigate how modern ASR models correlate with human recognition of enhanced speech. A listening experiment reveals that modern ASR models with large-scale noisy training and embedded language models correlate more with human WER than simpler ones, with a transducer model providing the most reliable transcriptions. Nevertheless, we also show that these models' robustness to noise and use of context can be uninformative to an acoustics-focused evaluation of enhancement performance.
LipDiffuser: Lip-to-Speech Generation with Conditional Diffusion Models
May 16, 2025We present LipDiffuser, a conditional diffusion model for lip-to-speech generation synthesizing natural and intelligible speech directly from silent video recordings. Our approach leverages the magnitude-preserving ablated diffusion model (MP-ADM) architecture as a denoiser model. To effectively condition the model, we incorporate visual features using magnitude-preserving feature-wise linear modulation (MP-FiLM) alongside speaker embeddings. A neural vocoder then reconstructs the speech waveform from the generated mel-spectrograms. Evaluations on LRS3 and TCD-TIMIT demonstrate that LipDiffuser outperforms existing lip-to-speech baselines in perceptual speech quality and speaker similarity, while remaining competitive in downstream automatic speech recognition (ASR). These findings are also supported by a formal listening experiment. Extensive ablation studies and cross-dataset evaluation confirm the effectiveness and generalization capabilities of our approach.
Normalize Everything: A Preconditioned Magnitude-Preserving Architecture for Diffusion-Based Speech Enhancement
May 08, 2025This paper presents a new framework for diffusion-based speech enhancement. Our method employs a Schroedinger bridge to transform the noisy speech distribution into the clean speech distribution. To stabilize and improve training, we employ time-dependent scalings of the inputs and outputs of the network, known as preconditioning. We consider two skip connection configurations, which either include or omit the current process state in the denoiser's output, enabling the network to predict either environmental noise or clean speech. Each approach leads to improved performance on different speech enhancement metrics. To maintain stable magnitude levels and balance during training, we use a magnitude-preserving network architecture that normalizes all activations and network weights to unit length. Additionally, we propose learning the contribution of the noisy input within each network block for effective input conditioning. After training, we apply a method to approximate different exponential moving average (EMA) profiles and investigate their effects on the speech enhancement performance. In contrast to image generation tasks, where longer EMA lengths often enhance mode coverage, we observe that shorter EMA lengths consistently lead to better performance on standard speech enhancement metrics. Code, audio examples, and checkpoints are available online.
Non-intrusive Speech Quality Assessment with Diffusion Models Trained on Clean Speech
Oct 23, 2024



Diffusion models have found great success in generating high quality, natural samples of speech, but their potential for density estimation for speech has so far remained largely unexplored. In this work, we leverage an unconditional diffusion model trained only on clean speech for the assessment of speech quality. We show that the quality of a speech utterance can be assessed by estimating the likelihood of a corresponding sample in the terminating Gaussian distribution, obtained via a deterministic noising process. The resulting method is purely unsupervised, trained only on clean speech, and therefore does not rely on annotations. Our diffusion-based approach leverages clean speech priors to assess quality based on how the input relates to the learned distribution of clean data. Our proposed log-likelihoods show promising results, correlating well with intrusive speech quality metrics such as POLQA and SI-SDR.
Investigating Training Objectives for Generative Speech Enhancement
Sep 16, 2024


Generative speech enhancement has recently shown promising advancements in improving speech quality in noisy environments. Multiple diffusion-based frameworks exist, each employing distinct training objectives and learning techniques. This paper aims at explaining the differences between these frameworks by focusing our investigation on score-based generative models and Schr\"odinger bridge. We conduct a series of comprehensive experiments to compare their performance and highlight differing training behaviors. Furthermore, we propose a novel perceptual loss function tailored for the Schr\"odinger bridge framework, demonstrating enhanced performance and improved perceptual quality of the enhanced speech signals. All experimental code and pre-trained models are publicly available to facilitate further research and development in this.
The PESQetarian: On the Relevance of Goodhart's Law for Speech Enhancement
Jun 05, 2024



To obtain improved speech enhancement models, researchers often focus on increasing performance according to specific instrumental metrics. However, when the same metric is used in a loss function to optimize models, it may be detrimental to aspects that the given metric does not see. The goal of this paper is to illustrate the risk of overfitting a speech enhancement model to the metric used for evaluation. For this, we introduce enhancement models that exploit the widely used PESQ measure. Our "PESQetarian" model achieves 3.82 PESQ on VB-DMD while scoring very poorly in a listening experiment. While the obtained PESQ value of 3.82 would imply "state-of-the-art" PESQ-performance on the VB-DMD benchmark, our examples show that when optimizing w.r.t. a metric, an isolated evaluation on the same metric may be misleading. Instead, other metrics should be included in the evaluation and the resulting performance predictions should be confirmed by listening.
Distilling HuBERT with LSTMs via Decoupled Knowledge Distillation
Sep 18, 2023Much research effort is being applied to the task of compressing the knowledge of self-supervised models, which are powerful, yet large and memory consuming. In this work, we show that the original method of knowledge distillation (and its more recently proposed extension, decoupled knowledge distillation) can be applied to the task of distilling HuBERT. In contrast to methods that focus on distilling internal features, this allows for more freedom in the network architecture of the compressed model. We thus propose to distill HuBERT's Transformer layers into an LSTM-based distilled model that reduces the number of parameters even below DistilHuBERT and at the same time shows improved performance in automatic speech recognition.
On the Behavior of Intrusive and Non-intrusive Speech Enhancement Metrics in Predictive and Generative Settings
Jun 05, 2023Since its inception, the field of deep speech enhancement has been dominated by predictive (discriminative) approaches, such as spectral mapping or masking. Recently, however, novel generative approaches have been applied to speech enhancement, attaining good denoising performance with high subjective quality scores. At the same time, advances in deep learning also allowed for the creation of neural network-based metrics, which have desirable traits such as being able to work without a reference (non-intrusively). Since generatively enhanced speech tends to exhibit radically different residual distortions, its evaluation using instrumental speech metrics may behave differently compared to predictively enhanced speech. In this paper, we evaluate the performance of the same speech enhancement backbone trained under predictive and generative paradigms on a variety of metrics and show that intrusive and non-intrusive measures correlate differently for each paradigm. This analysis motivates the search for metrics that can together paint a complete and unbiased picture of speech enhancement performance, irrespective of the model's training process.
Leveraging Semantic Information for Efficient Self-Supervised Emotion Recognition with Audio-Textual Distilled Models
May 30, 2023



In large part due to their implicit semantic modeling, self-supervised learning (SSL) methods have significantly increased the performance of valence recognition in speech emotion recognition (SER) systems. Yet, their large size may often hinder practical implementations. In this work, we take HuBERT as an example of an SSL model and analyze the relevance of each of its layers for SER. We show that shallow layers are more important for arousal recognition while deeper layers are more important for valence. This observation motivates the importance of additional textual information for accurate valence recognition, as the distilled framework lacks the depth of its large-scale SSL teacher. Thus, we propose an audio-textual distilled SSL framework that, while having only ~20% of the trainable parameters of a large SSL model, achieves on par performance across the three emotion dimensions (arousal, valence, dominance) on the MSP-Podcast v1.10 dataset.
Efficient Transformer-based Speech Enhancement Using Long Frames and STFT Magnitudes
Jun 23, 2022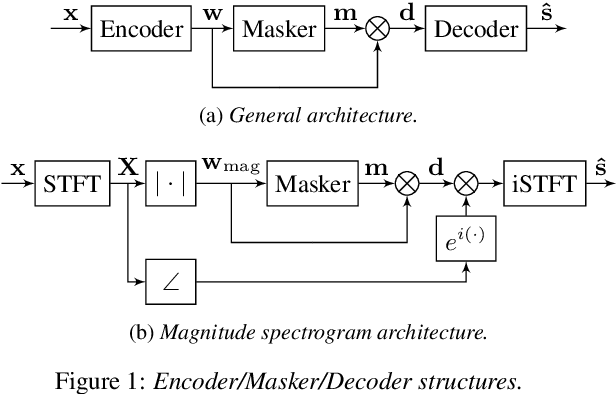
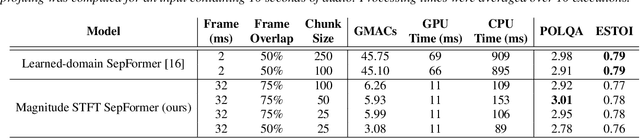
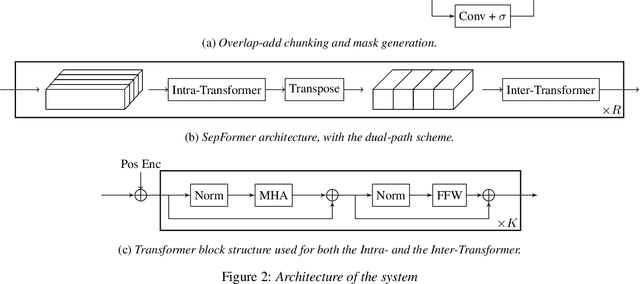
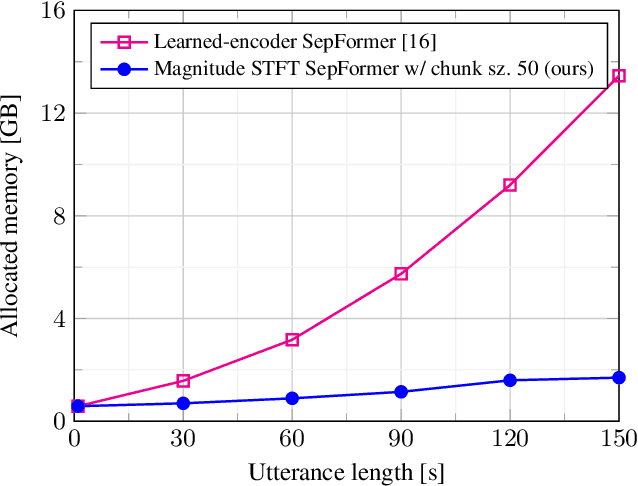
The SepFormer architecture shows very good results in speech separation. Like other learned-encoder models, it uses short frames, as they have been shown to obtain better performance in these cases. This results in a large number of frames at the input, which is problematic; since the SepFormer is transformer-based, its computational complexity drastically increases with longer sequences. In this paper, we employ the SepFormer in a speech enhancement task and show that by replacing the learned-encoder features with a magnitude short-time Fourier transform (STFT) representation, we can use long frames without compromising perceptual enhancement performance. We obtained equivalent quality and intelligibility evaluation scores while reducing the number of operations by a factor of approximately 8 for a 10-second utterance.