 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
PolyHope: Two-Level Hope Speech Detection from Tweets
Nov 03, 2022

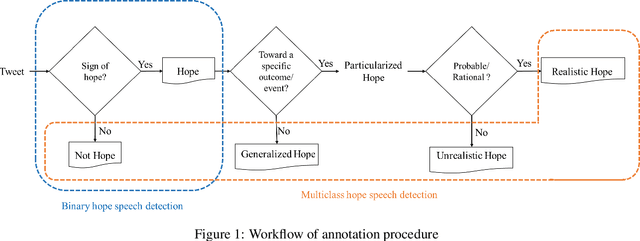
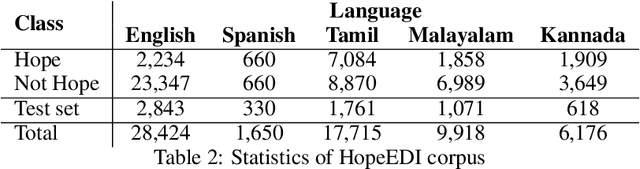
Hope is characterized as openness of spirit toward the future, a desire, expectation, and wish for something to happen or to be true that remarkably affects human's state of mind, emotions, behaviors, and decisions. Hope is usually associated with concepts of desired expectations and possibility/probability concerning the future. Despite its importance, hope has rarely been studied as a social media analysis task. This paper presents a hope speech dataset that classifies each tweet first into "Hope" and "Not Hope", then into three fine-grained hope categories: "Generalized Hope", "Realistic Hope", and "Unrealistic Hope" (along with "Not Hope"). English tweets in the first half of 2022 were collected to build this dataset. Furthermore, we describe our annotation process and guidelines in detail and discuss the challenges of classifying hope and the limitations of the existing hope speech detection corpora. In addition, we reported several baselines based on different learning approaches, such as traditional machine learning, deep learning, and transformers, to benchmark our dataset. We evaluated our baselines using weighted-averaged and macro-averaged F1-scores. Observations show that a strict process for annotator selection and detailed annotation guidelines enhanced the dataset's quality. This strict annotation process resulted in promising performance for simple machine learning classifiers with only bi-grams; however, binary and multiclass hope speech detection results reveal that contextual embedding models have higher performance in this dataset.
Training Autoregressive Speech Recognition Models with Limited in-domain Supervision
Oct 27, 2022
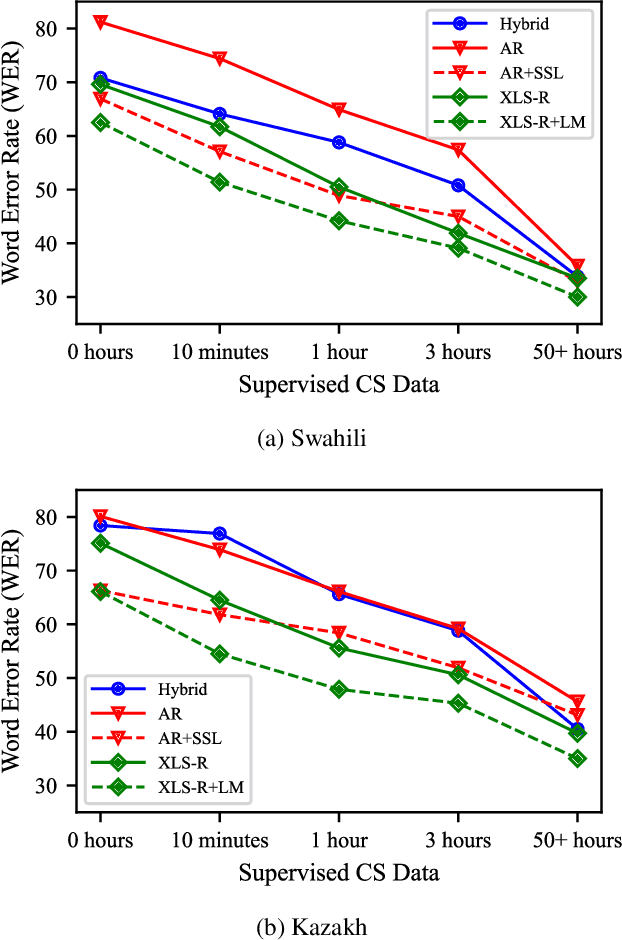

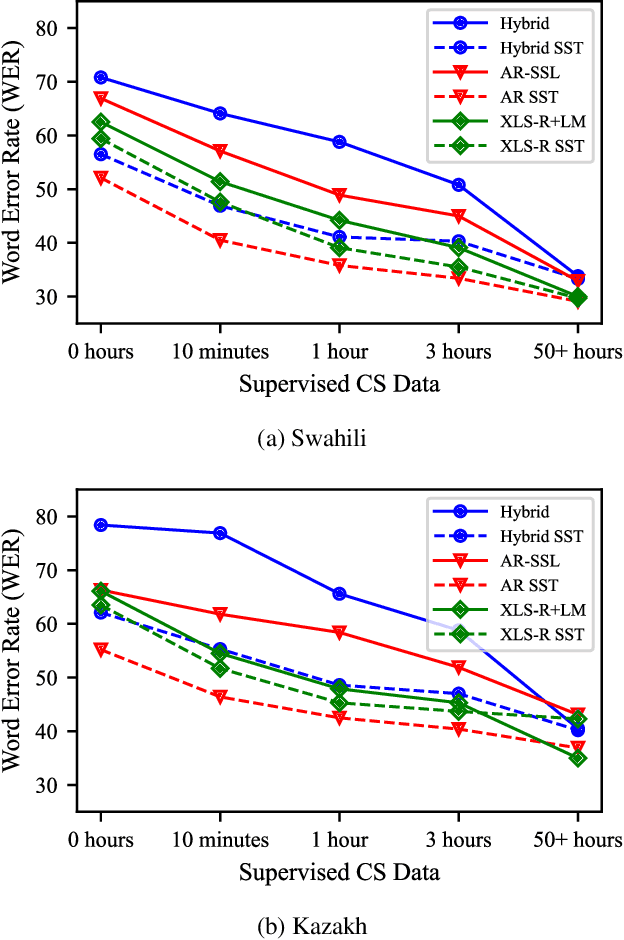
Advances in self-supervised learning have significantly reduced the amount of transcribed audio required for training. However, the majority of work in this area is focused on read speech. We explore limited supervision in the domain of conversational speech. While we assume the amount of in-domain data is limited, we augment the model with open source read speech data. The XLS-R model has been shown to perform well with limited adaptation data and serves as a strong baseline. We use untranscribed data for self-supervised learning and semi-supervised training in an autoregressive encoder-decoder model. We demonstrate that by using the XLS-R model for pseudotranscription, a much smaller autoregressive model can outperform a finetuned XLS-R model when transcribed in-domain data is limited, reducing WER by as much as 8% absolute.
Speech Enhancement with Fullband-Subband Cross-Attention Network
Nov 10, 2022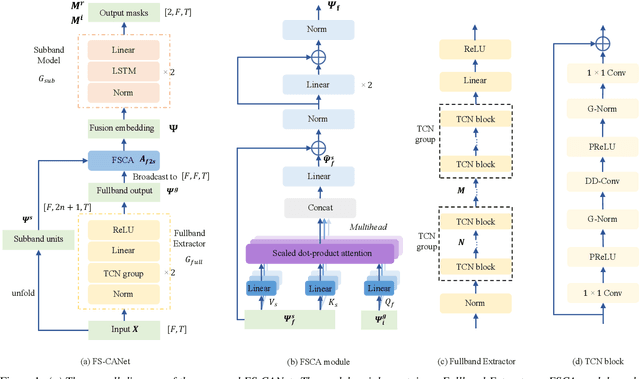
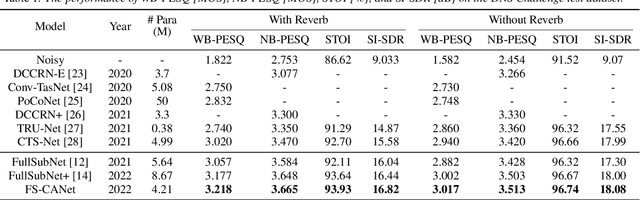
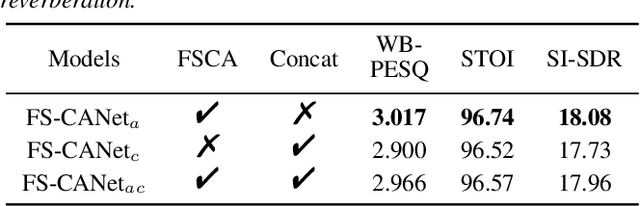
FullSubNet has shown its promising performance on speech enhancement by utilizing both fullband and subband information. However, the relationship between fullband and subband in FullSubNet is achieved by simply concatenating the output of fullband model and subband units. It only supplements the subband units with a small quantity of global information and has not considered the interaction between fullband and subband. This paper proposes a fullband-subband cross-attention (FSCA) module to interactively fuse the global and local information and applies it to FullSubNet. This new framework is called as FS-CANet. Moreover, different from FullSubNet, the proposed FS-CANet optimize the fullband extractor by temporal convolutional network (TCN) blocks to further reduce the model size. Experimental results on DNS Challenge - Interspeech 2021 dataset show that the proposed FS-CANet outperforms other state-of-the-art speech enhancement approaches, and demonstrate the effectiveness of fullband-subband cross-attention.
CB-Conformer: Contextual biasing Conformer for biased word recognition
Apr 19, 2023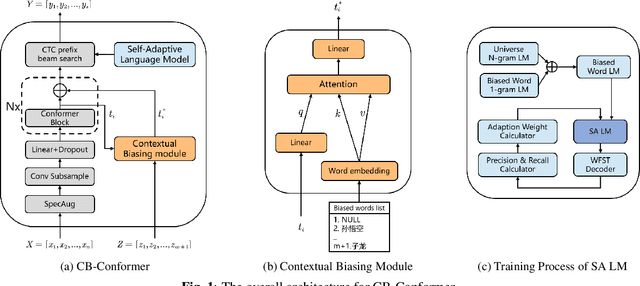
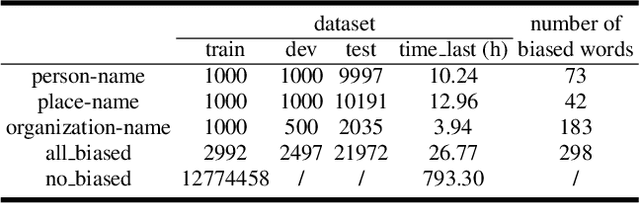
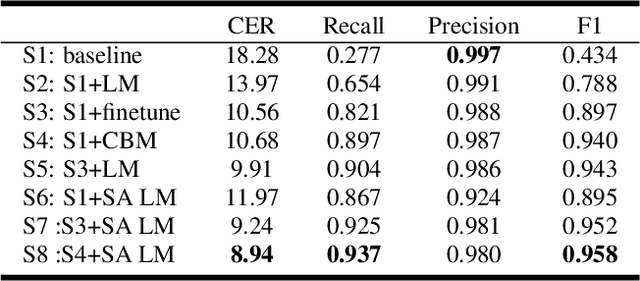
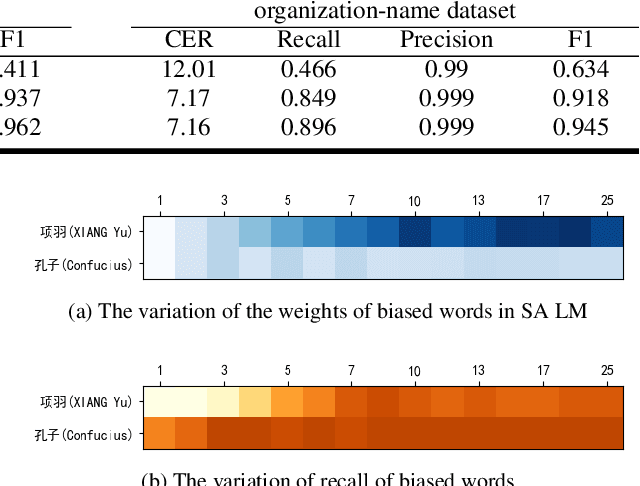
Due to the mismatch between the source and target domains, how to better utilize the biased word information to improve the performance of the automatic speech recognition model in the target domain becomes a hot research topic. Previous approaches either decode with a fixed external language model or introduce a sizeable biasing module, which leads to poor adaptability and slow inference. In this work, we propose CB-Conformer to improve biased word recognition by introducing the Contextual Biasing Module and the Self-Adaptive Language Model to vanilla Conformer. The Contextual Biasing Module combines audio fragments and contextual information, with only 0.2% model parameters of the original Conformer. The Self-Adaptive Language Model modifies the internal weights of biased words based on their recall and precision, resulting in a greater focus on biased words and more successful integration with the automatic speech recognition model than the standard fixed language model. In addition, we construct and release an open-source Mandarin biased-word dataset based on WenetSpeech. Experiments indicate that our proposed method brings a 15.34% character error rate reduction, a 14.13% biased word recall increase, and a 6.80% biased word F1-score increase compared with the base Conformer.
JEIT: Joint End-to-End Model and Internal Language Model Training for Speech Recognition
Feb 16, 2023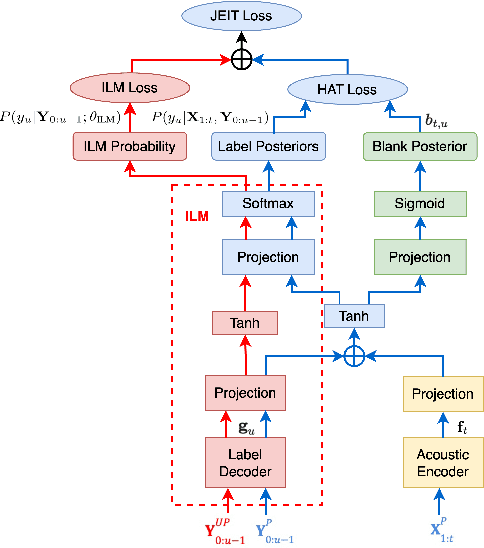

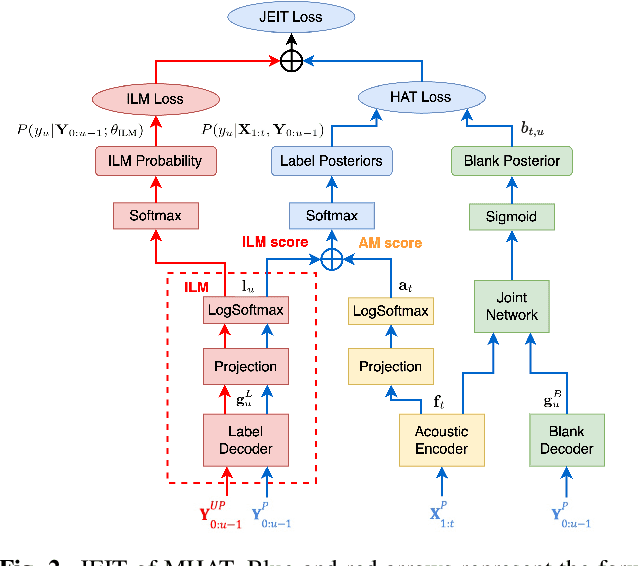
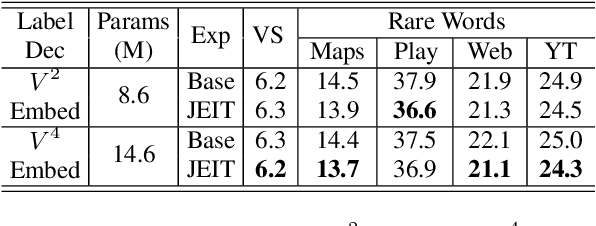
We propose JEIT, a joint end-to-end (E2E) model and internal language model (ILM) training method to inject large-scale unpaired text into ILM during E2E training which improves rare-word speech recognition. With JEIT, the E2E model computes an E2E loss on audio-transcript pairs while its ILM estimates a cross-entropy loss on unpaired text. The E2E model is trained to minimize a weighted sum of E2E and ILM losses. During JEIT, ILM absorbs knowledge from unpaired text while the E2E training serves as regularization. Unlike ILM adaptation methods, JEIT does not require a separate adaptation step and avoids the need for Kullback-Leibler divergence regularization of ILM. We also show that modular hybrid autoregressive transducer (MHAT) performs better than HAT in the JEIT framework, and is much more robust than HAT during ILM adaptation. To push the limit of unpaired text injection, we further propose a combined JEIT and JOIST training (CJJT) that benefits from modality matching, encoder text injection and ILM training. Both JEIT and CJJT can foster a more effective LM fusion. With 100B unpaired sentences, JEIT/CJJT improves rare-word recognition accuracy by up to 16.4% over a model trained without unpaired text.
* 5 pages, 3 figures, in ICASSP 2023
Towards Disentangled Speech Representations
Aug 28, 2022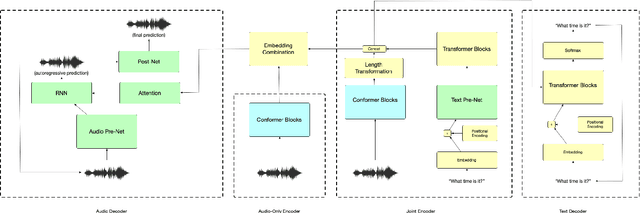
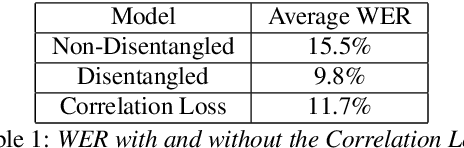

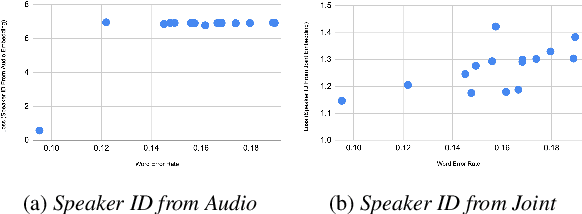
The careful construction of audio representations has become a dominant feature in the design of approaches to many speech tasks. Increasingly, such approaches have emphasized "disentanglement", where a representation contains only parts of the speech signal relevant to transcription while discarding irrelevant information. In this paper, we construct a representation learning task based on joint modeling of ASR and TTS, and seek to learn a representation of audio that disentangles that part of the speech signal that is relevant to transcription from that part which is not. We present empirical evidence that successfully finding such a representation is tied to the randomness inherent in training. We then make the observation that these desired, disentangled solutions to the optimization problem possess unique statistical properties. Finally, we show that enforcing these properties during training improves WER by 24.5% relative on average for our joint modeling task. These observations motivate a novel approach to learning effective audio representations.
Model-based estimation of in-car-communication feedback applied to speech zone detection
Oct 07, 2022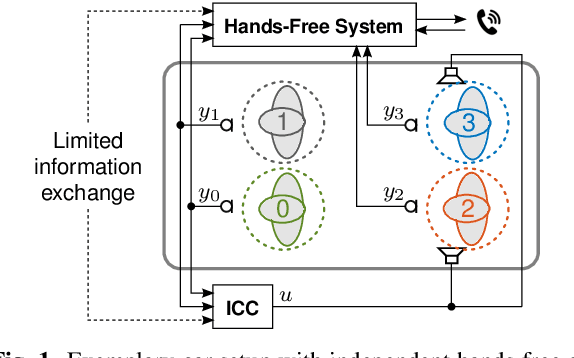
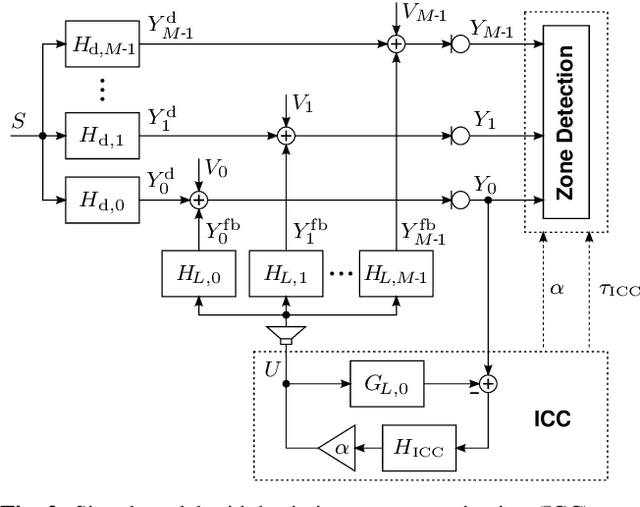

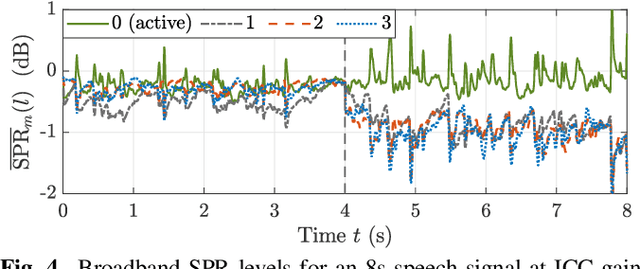
Modern cars provide versatile tools to enhance speech communication. While an in-car communication (ICC) system aims at enhancing communication between the passengers by playing back desired speech via loudspeakers in the car, these loudspeaker signals may disturb a speech enhancement system required for hands-free telephony and automatic speech recognition. In this paper, we focus on speech zone detection, i.e. detecting which passenger in the car is speaking, which is a crucial component of the speech enhancement system. We propose a model-based feedback estimation method to improve robustness of speech zone detection against ICC feedback. Specifically, since the zone detection system typically does not have access to the ICC loudspeaker signals, the proposed method estimates the feedback signal from the observed microphone signals based on a free-field propagation model between the loudspeakers and the microphones as well as the ICC gain. We propose an efficient recursive implementation in the short-time Fourier transform domain using convolutive transfer functions. A realistic simulation study indicates that the proposed method allows to increase the ICC gain by about 6dB while still achieving robust speech zone detection results.
Filler Word Detection with Hard Category Mining and Inter-Category Focal Loss
Apr 12, 2023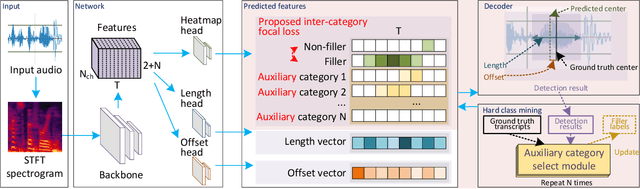
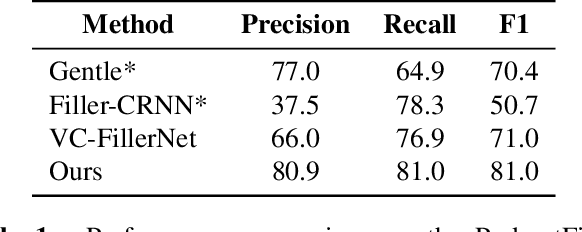
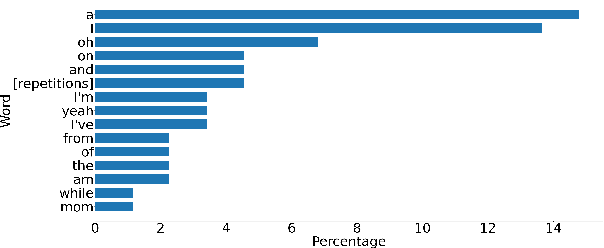
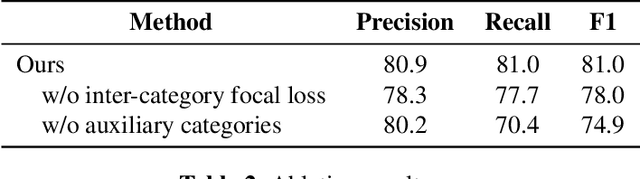
Filler words like ``um" or ``uh" are common in spontaneous speech. It is desirable to automatically detect and remove them in recordings, as they affect the fluency, confidence, and professionalism of speech. Previous studies and our preliminary experiments reveal that the biggest challenge in filler word detection is that fillers can be easily confused with other hard categories like ``a" or ``I". In this paper, we propose a novel filler word detection method that effectively addresses this challenge by adding auxiliary categories dynamically and applying an additional inter-category focal loss. The auxiliary categories force the model to explicitly model the confusing words by mining hard categories. In addition, inter-category focal loss adaptively adjusts the penalty weight between ``filler" and ``non-filler" categories to deal with other confusing words left in the ``non-filler" category. Our system achieves the best results, with a huge improvement compared to other methods on the PodcastFillers dataset.
RWEN-TTS: Relation-aware Word Encoding Network for Natural Text-to-Speech Synthesis
Dec 15, 2022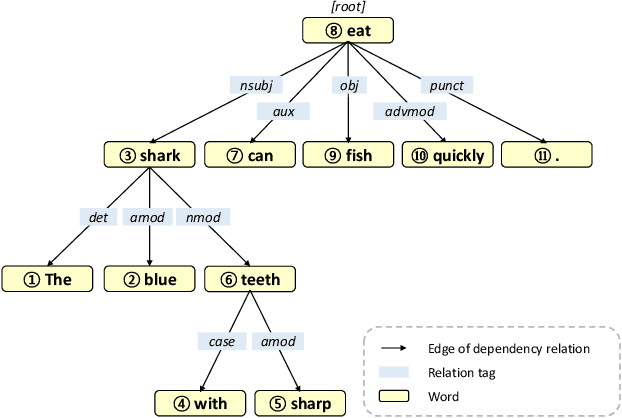

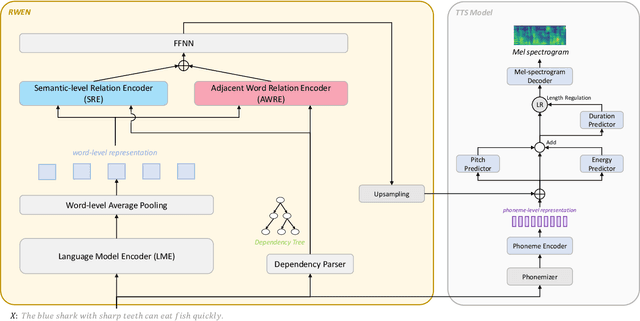

With the advent of deep learning, a huge number of text-to-speech (TTS) models which produce human-like speech have emerged. Recently, by introducing syntactic and semantic information w.r.t the input text, various approaches have been proposed to enrich the naturalness and expressiveness of TTS models. Although these strategies showed impressive results, they still have some limitations in utilizing language information. First, most approaches only use graph networks to utilize syntactic and semantic information without considering linguistic features. Second, most previous works do not explicitly consider adjacent words when encoding syntactic and semantic information, even though it is obvious that adjacent words are usually meaningful when encoding the current word. To address these issues, we propose Relation-aware Word Encoding Network (RWEN), which effectively allows syntactic and semantic information based on two modules (i.e., Semantic-level Relation Encoding and Adjacent Word Relation Encoding). Experimental results show substantial improvements compared to previous works.
Assessing the impact of contextual information in hate speech detection
Oct 05, 2022
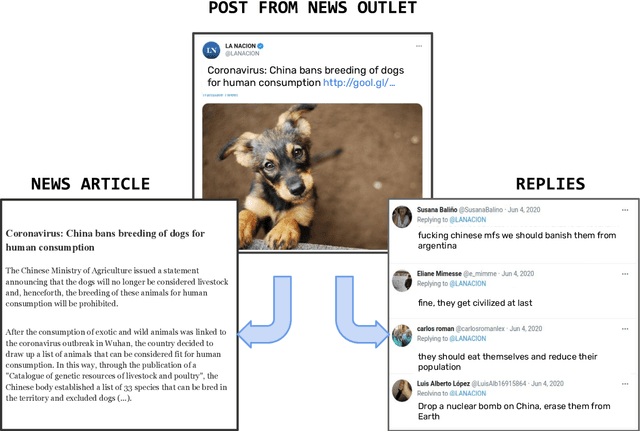
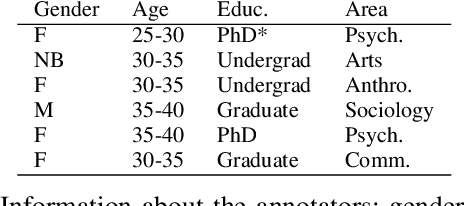
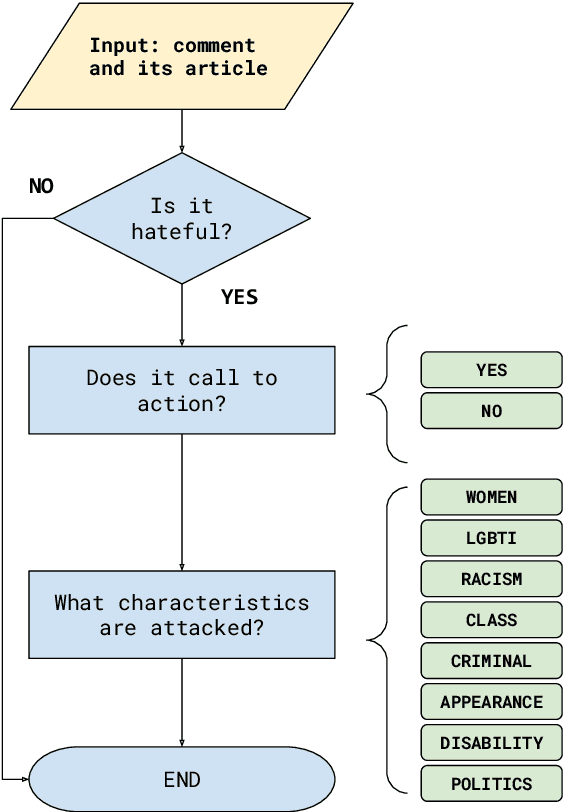
In recent years, hate speech has gained great relevance in social networks and other virtual media because of its intensity and its relationship with violent acts against members of protected groups. Due to the great amount of content generated by users, great effort has been made in the research and development of automatic tools to aid the analysis and moderation of this speech, at least in its most threatening forms. One of the limitations of current approaches to automatic hate speech detection is the lack of context. Most studies and resources are performed on data without context; that is, isolated messages without any type of conversational context or the topic being discussed. This restricts the available information to define if a post on a social network is hateful or not. In this work, we provide a novel corpus for contextualized hate speech detection based on user responses to news posts from media outlets on Twitter. This corpus was collected in the Rioplatense dialectal variety of Spanish and focuses on hate speech associated with the COVID-19 pandemic. Classification experiments using state-of-the-art techniques show evidence that adding contextual information improves hate speech detection performance for two proposed tasks (binary and multi-label prediction). We make our code, models, and corpus available for further research.