 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Keep Decoding Parallel with Effective Knowledge Distillation from Language Models to End-to-end Speech Recognisers
Jan 22, 2024
This study presents a novel approach for knowledge distillation (KD) from a BERT teacher model to an automatic speech recognition (ASR) model using intermediate layers. To distil the teacher's knowledge, we use an attention decoder that learns from BERT's token probabilities. Our method shows that language model (LM) information can be more effectively distilled into an ASR model using both the intermediate layers and the final layer. By using the intermediate layers as distillation target, we can more effectively distil LM knowledge into the lower network layers. Using our method, we achieve better recognition accuracy than with shallow fusion of an external LM, allowing us to maintain fast parallel decoding. Experiments on the LibriSpeech dataset demonstrate the effectiveness of our approach in enhancing greedy decoding with connectionist temporal classification (CTC).
DrBenchmark: A Large Language Understanding Evaluation Benchmark for French Biomedical Domain
Feb 20, 2024The biomedical domain has sparked a significant interest in the field of Natural Language Processing (NLP), which has seen substantial advancements with pre-trained language models (PLMs). However, comparing these models has proven challenging due to variations in evaluation protocols across different models. A fair solution is to aggregate diverse downstream tasks into a benchmark, allowing for the assessment of intrinsic PLMs qualities from various perspectives. Although still limited to few languages, this initiative has been undertaken in the biomedical field, notably English and Chinese. This limitation hampers the evaluation of the latest French biomedical models, as they are either assessed on a minimal number of tasks with non-standardized protocols or evaluated using general downstream tasks. To bridge this research gap and account for the unique sensitivities of French, we present the first-ever publicly available French biomedical language understanding benchmark called DrBenchmark. It encompasses 20 diversified tasks, including named-entity recognition, part-of-speech tagging, question-answering, semantic textual similarity, and classification. We evaluate 8 state-of-the-art pre-trained masked language models (MLMs) on general and biomedical-specific data, as well as English specific MLMs to assess their cross-lingual capabilities. Our experiments reveal that no single model excels across all tasks, while generalist models are sometimes still competitive.
IR-UWB Radar-Based Contactless Silent Speech Recognition of Vowels, Consonants, Words, and Phrases
Dec 15, 2023Several sensing techniques have been proposed for silent speech recognition (SSR); however, many of these methods require invasive processes or sensor attachment to the skin using adhesive tape or glue, rendering them unsuitable for frequent use in daily life. By contrast, impulse radio ultra-wideband (IR-UWB) radar can operate without physical contact with users' articulators and related body parts, offering several advantages for SSR. These advantages include high range resolution, high penetrability, low power consumption, robustness to external light or sound interference, and the ability to be embedded in space-constrained handheld devices. This study demonstrated IR-UWB radar-based contactless SSR using four types of speech stimuli (vowels, consonants, words, and phrases). To achieve this, a novel speech feature extraction algorithm specifically designed for IR-UWB radar-based SSR is proposed. Each speech stimulus is recognized by applying a classification algorithm to the extracted speech features. Two different algorithms, multidimensional dynamic time warping (MD-DTW) and deep neural network-hidden Markov model (DNN-HMM), were compared for the classification task. Additionally, a favorable radar antenna position, either in front of the user's lips or below the user's chin, was determined to achieve higher recognition accuracy. Experimental results demonstrated the efficacy of the proposed speech feature extraction algorithm combined with DNN-HMM for classifying vowels, consonants, words, and phrases. Notably, this study represents the first demonstration of phoneme-level SSR using contactless radar.
SpeechDPR: End-to-End Spoken Passage Retrieval for Open-Domain Spoken Question Answering
Jan 24, 2024Spoken Question Answering (SQA) is essential for machines to reply to user's question by finding the answer span within a given spoken passage. SQA has been previously achieved without ASR to avoid recognition errors and Out-of-Vocabulary (OOV) problems. However, the real-world problem of Open-domain SQA (openSQA), in which the machine needs to first retrieve passages that possibly contain the answer from a spoken archive in addition, was never considered. This paper proposes the first known end-to-end framework, Speech Dense Passage Retriever (SpeechDPR), for the retrieval component of the openSQA problem. SpeechDPR learns a sentence-level semantic representation by distilling knowledge from the cascading model of unsupervised ASR (UASR) and text dense retriever (TDR). No manually transcribed speech data is needed. Initial experiments showed performance comparable to the cascading model of UASR and TDR, and significantly better when UASR was poor, verifying this approach is more robust to speech recognition errors.
Automatic channel selection and spatial feature integration for multi-channel speech recognition across various array topologies
Dec 15, 2023Automatic Speech Recognition (ASR) has shown remarkable progress, yet it still faces challenges in real-world distant scenarios across various array topologies each with multiple recording devices. The focal point of the CHiME-7 Distant ASR task is to devise a unified system capable of generalizing various array topologies that have multiple recording devices and offering reliable recognition performance in real-world environments. Addressing this task, we introduce an ASR system that demonstrates exceptional performance across various array topologies. First of all, we propose two attention-based automatic channel selection modules to select the most advantageous subset of multi-channel signals from multiple recording devices for each utterance. Furthermore, we introduce inter-channel spatial features to augment the effectiveness of multi-frame cross-channel attention, aiding it in improving the capability of spatial information awareness. Finally, we propose a multi-layer convolution fusion module drawing inspiration from the U-Net architecture to integrate the multi-channel output into a single-channel output. Experimental results on the CHiME-7 corpus with oracle segmentation demonstrate that the improvements introduced in our proposed ASR system lead to a relative reduction of 40.1% in the Macro Diarization Attributed Word Error Rates (DA-WER) when compared to the baseline ASR system on the Eval sets.
AV-CPL: Continuous Pseudo-Labeling for Audio-Visual Speech Recognition
Sep 29, 2023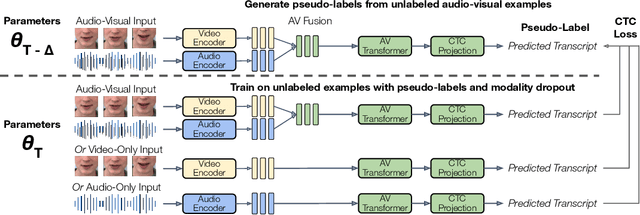
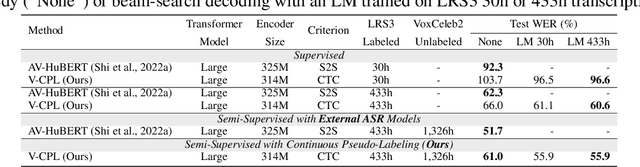
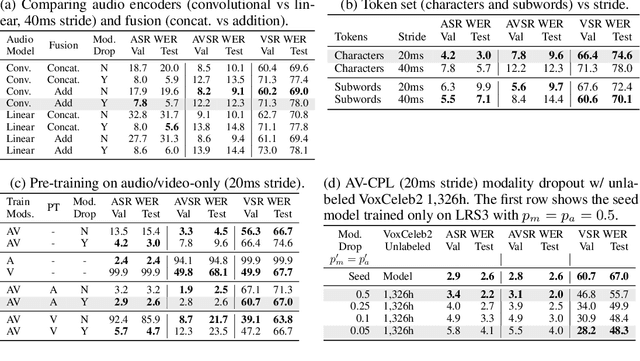
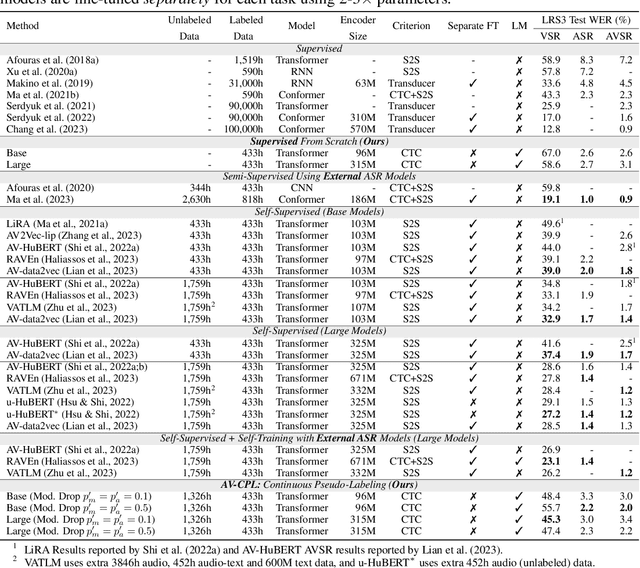
Audio-visual speech contains synchronized audio and visual information that provides cross-modal supervision to learn representations for both automatic speech recognition (ASR) and visual speech recognition (VSR). We introduce continuous pseudo-labeling for audio-visual speech recognition (AV-CPL), a semi-supervised method to train an audio-visual speech recognition (AVSR) model on a combination of labeled and unlabeled videos with continuously regenerated pseudo-labels. Our models are trained for speech recognition from audio-visual inputs and can perform speech recognition using both audio and visual modalities, or only one modality. Our method uses the same audio-visual model for both supervised training and pseudo-label generation, mitigating the need for external speech recognition models to generate pseudo-labels. AV-CPL obtains significant improvements in VSR performance on the LRS3 dataset while maintaining practical ASR and AVSR performance. Finally, using visual-only speech data, our method is able to leverage unlabeled visual speech to improve VSR.
Automated speech audiometry: Can it work using open-source pre-trained Kaldi-NL automatic speech recognition?
Dec 19, 2023A practical speech audiometry tool is the digits-in-noise (DIN) test for hearing screening of populations of varying ages and hearing status. The test is usually conducted by a human supervisor (e.g., clinician), who scores the responses spoken by the listener, or online, where a software scores the responses entered by the listener. The test has 24 digit-triplets presented in an adaptive staircase procedure, resulting in a speech reception threshold (SRT). We propose an alternative automated DIN test setup that can evaluate spoken responses whilst conducted without a human supervisor, using the open-source automatic speech recognition toolkit, Kaldi-NL. Thirty self-reported normal-hearing Dutch adults (19-64 years) completed one DIN+Kaldi-NL test. Their spoken responses were recorded, and used for evaluating the transcript of decoded responses by Kaldi-NL. Study 1 evaluated the Kaldi-NL performance through its word error rate (WER), percentage of summed decoding errors regarding only digits found in the transcript compared to the total number of digits present in the spoken responses. Average WER across participants was 5.0% (range 0 - 48%, SD = 8.8%), with average decoding errors in three triplets per participant. Study 2 analysed the effect that triplets with decoding errors from Kaldi-NL had on the DIN test output (SRT), using bootstrapping simulations. Previous research indicated 0.70 dB as the typical within-subject SRT variability for normal-hearing adults. Study 2 showed that up to four triplets with decoding errors produce SRT variations within this range, suggesting that our proposed setup could be feasible for clinical applications.
Personalized Large Language Models
Feb 14, 2024Large language models (LLMs) have significantly advanced Natural Language Processing (NLP) tasks in recent years. However, their universal nature poses limitations in scenarios requiring personalized responses, such as recommendation systems and chatbots. This paper investigates methods to personalize LLMs, comparing fine-tuning and zero-shot reasoning approaches on subjective tasks. Results demonstrate that personalized fine-tuning improves model reasoning compared to non-personalized models. Experiments on datasets for emotion recognition and hate speech detection show consistent performance gains with personalized methods across different LLM architectures. These findings underscore the importance of personalization for enhancing LLM capabilities in subjective text perception tasks.
An Integration of Pre-Trained Speech and Language Models for End-to-End Speech Recognition
Dec 06, 2023Advances in machine learning have made it possible to perform various text and speech processing tasks, including automatic speech recognition (ASR), in an end-to-end (E2E) manner. Since typical E2E approaches require large amounts of training data and resources, leveraging pre-trained foundation models instead of training from scratch is gaining attention. Although there have been attempts to use pre-trained speech and language models in ASR, most of them are limited to using either. This paper explores the potential of integrating a pre-trained speech representation model with a large language model (LLM) for E2E ASR. The proposed model enables E2E ASR by generating text tokens in an autoregressive manner via speech representations as speech prompts, taking advantage of the vast knowledge provided by the LLM. Furthermore, the proposed model can incorporate remarkable developments for LLM utilization, such as inference optimization and parameter-efficient domain adaptation. Experimental results show that the proposed model achieves performance comparable to modern E2E ASR models.
Communication-Efficient Personalized Federated Learning for Speech-to-Text Tasks
Jan 18, 2024To protect privacy and meet legal regulations, federated learning (FL) has gained significant attention for training speech-to-text (S2T) systems, including automatic speech recognition (ASR) and speech translation (ST). However, the commonly used FL approach (i.e., \textsc{FedAvg}) in S2T tasks typically suffers from extensive communication overhead due to multi-round interactions based on the whole model and performance degradation caused by data heterogeneity among clients.To address these issues, we propose a personalized federated S2T framework that introduces \textsc{FedLoRA}, a lightweight LoRA module for client-side tuning and interaction with the server to minimize communication overhead, and \textsc{FedMem}, a global model equipped with a $k$-nearest-neighbor ($k$NN) classifier that captures client-specific distributional shifts to achieve personalization and overcome data heterogeneity. Extensive experiments based on Conformer and Whisper backbone models on CoVoST and GigaSpeech benchmarks show that our approach significantly reduces the communication overhead on all S2T tasks and effectively personalizes the global model to overcome data heterogeneity.