 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterBiasing: Boost Unseen Word Recognition through Biasing Intermediate Predictions
Jun 21, 2024Despite recent advances in end-to-end speech recognition methods, their output is biased to the training data's vocabulary, resulting in inaccurate recognition of unknown terms or proper nouns. To improve the recognition accuracy for a given set of such terms, we propose an adaptation parameter-free approach based on Self-conditioned CTC. Our method improves the recognition accuracy of misrecognized target keywords by substituting their intermediate CTC predictions with corrected labels, which are then passed on to the subsequent layers. First, we create pairs of correct labels and recognition error instances for a keyword list using Text-to-Speech and a recognition model. We use these pairs to replace intermediate prediction errors by the labels. Conditioning the subsequent layers of the encoder on the labels, it is possible to acoustically evaluate the target keywords. Experiments conducted in Japanese demonstrated that our method successfully improved the F1 score for unknown words.
Keep Decoding Parallel with Effective Knowledge Distillation from Language Models to End-to-end Speech Recognisers
Jan 22, 2024



This study presents a novel approach for knowledge distillation (KD) from a BERT teacher model to an automatic speech recognition (ASR) model using intermediate layers. To distil the teacher's knowledge, we use an attention decoder that learns from BERT's token probabilities. Our method shows that language model (LM) information can be more effectively distilled into an ASR model using both the intermediate layers and the final layer. By using the intermediate layers as distillation target, we can more effectively distil LM knowledge into the lower network layers. Using our method, we achieve better recognition accuracy than with shallow fusion of an external LM, allowing us to maintain fast parallel decoding. Experiments on the LibriSpeech dataset demonstrate the effectiveness of our approach in enhancing greedy decoding with connectionist temporal classification (CTC).
Joint Speech Recognition and Audio Captioning
Feb 03, 2022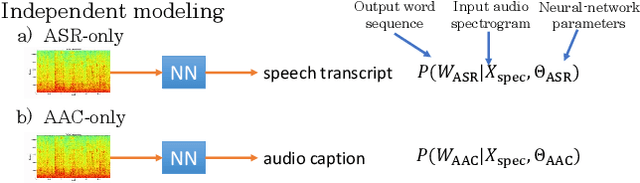
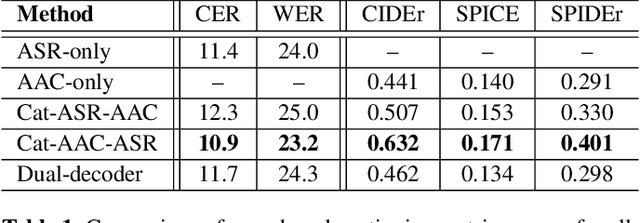
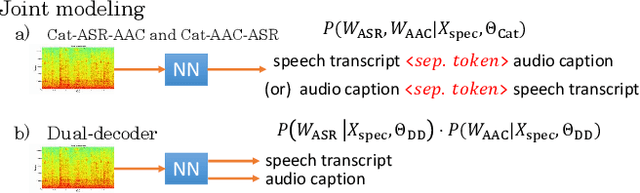
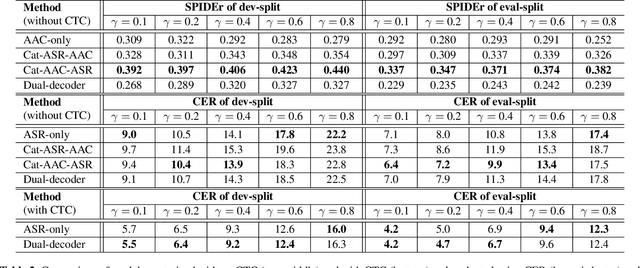
Speech samples recorded in both indoor and outdoor environments are often contaminated with secondary audio sources. Most end-to-end monaural speech recognition systems either remove these background sounds using speech enhancement or train noise-robust models. For better model interpretability and holistic understanding, we aim to bring together the growing field of automated audio captioning (AAC) and the thoroughly studied automatic speech recognition (ASR). The goal of AAC is to generate natural language descriptions of contents in audio samples. We propose several approaches for end-to-end joint modeling of ASR and AAC tasks and demonstrate their advantages over traditional approaches, which model these tasks independently. A major hurdle in evaluating our proposed approach is the lack of labeled audio datasets with both speech transcriptions and audio captions. Therefore we also create a multi-task dataset by mixing the clean speech Wall Street Journal corpus with multiple levels of background noises chosen from the AudioCaps dataset. We also perform extensive experimental evaluation and show improvements of our proposed methods as compared to existing state-of-the-art ASR and AAC methods.
Run-and-back stitch search: novel block synchronous decoding for streaming encoder-decoder ASR
Jan 25, 2022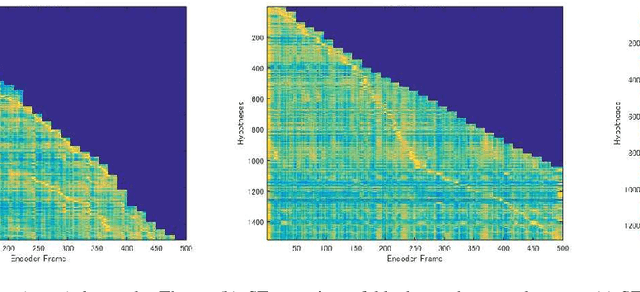
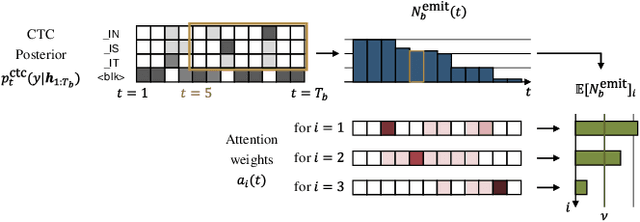
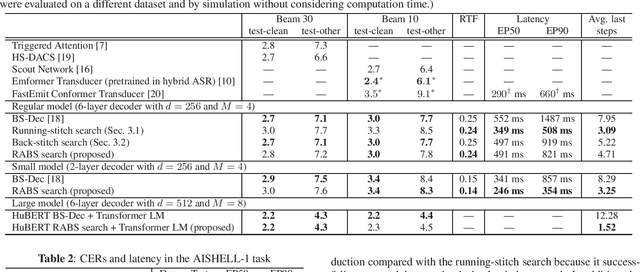
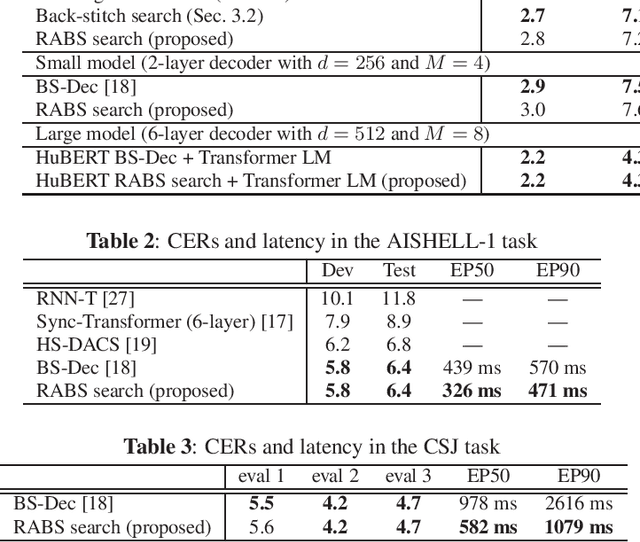
A streaming style inference of encoder-decoder automatic speech recognition (ASR) system is important for reducing latency, which is essential for interactive use cases. To this end, we propose a novel blockwise synchronous decoding algorithm with a hybrid approach that combines endpoint prediction and endpoint post-determination. In the endpoint prediction, we compute the expectation of the number of tokens that are yet to be emitted in the encoder features of the current blocks using the CTC posterior. Based on the expectation value, the decoder predicts the endpoint to realize continuous block synchronization, as a running stitch. Meanwhile, endpoint post-determination probabilistically detects backward jump of the source-target attention, which is caused by the misprediction of endpoints. Then it resumes decoding by discarding those hypotheses, as back stitch. We combine these methods into a hybrid approach, namely run-and-back stitch search, which reduces the computational cost and latency. Evaluations of various ASR tasks show the efficiency of our proposed decoding algorithm, which achieves a latency reduction, for instance in the Librispeech test set from 1487 ms to 821 ms at the 90th percentile, while maintaining a high recognition accuracy.