 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
ASR-GLUE: A New Multi-task Benchmark for ASR-Robust Natural Language Understanding
Aug 30, 2021

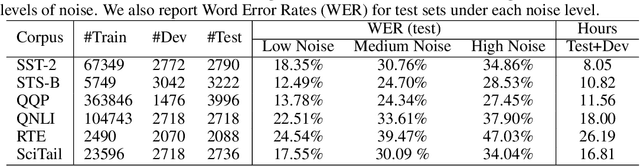
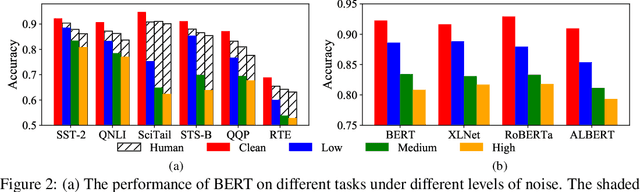

Language understanding in speech-based systems have attracted much attention in recent years with the growing demand for voice interface applications. However, the robustness of natural language understanding (NLU) systems to errors introduced by automatic speech recognition (ASR) is under-examined. %To facilitate the research on ASR-robust general language understanding, In this paper, we propose ASR-GLUE benchmark, a new collection of 6 different NLU tasks for evaluating the performance of models under ASR error across 3 different levels of background noise and 6 speakers with various voice characteristics. Based on the proposed benchmark, we systematically investigate the effect of ASR error on NLU tasks in terms of noise intensity, error type and speaker variants. We further purpose two ways, correction-based method and data augmentation-based method to improve robustness of the NLU systems. Extensive experimental results and analysises show that the proposed methods are effective to some extent, but still far from human performance, demonstrating that NLU under ASR error is still very challenging and requires further research.
A Multimodal Framework for Video Ads Understanding
Aug 29, 2021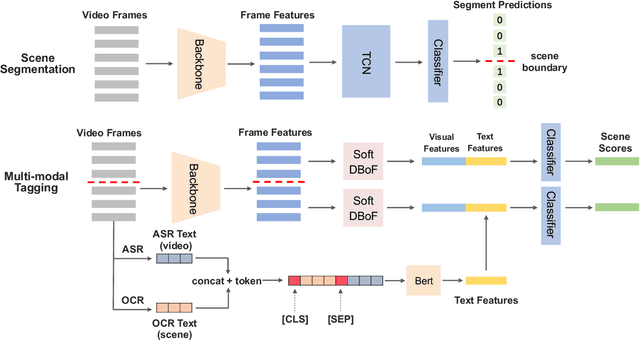


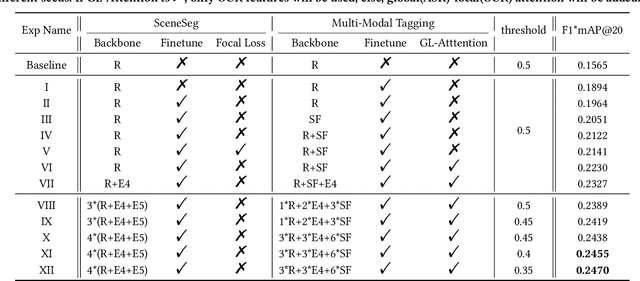
There is a growing trend in placing video advertisements on social platforms for online marketing, which demands automatic approaches to understand the contents of advertisements effectively. Taking the 2021 TAAC competition as an opportunity, we developed a multimodal system to improve the ability of structured analysis of advertising video content. In our framework, we break down the video structuring analysis problem into two tasks, i.e., scene segmentation and multi-modal tagging. In scene segmentation, we build upon a temporal convolution module for temporal modeling to predict whether adjacent frames belong to the same scene. In multi-modal tagging, we first compute clip-level visual features by aggregating frame-level features with NeXt-SoftDBoF. The visual features are further complemented with textual features that are derived using a global-local attention mechanism to extract useful information from OCR (Optical Character Recognition) and ASR (Audio Speech Recognition) outputs. Our solution achieved a score of 0.2470 measured in consideration of localization and prediction accuracy, ranking fourth in the 2021 TAAC final leaderboard.
A three-dimensional approach to Visual Speech Recognition using Discrete Cosine Transforms
Sep 07, 2016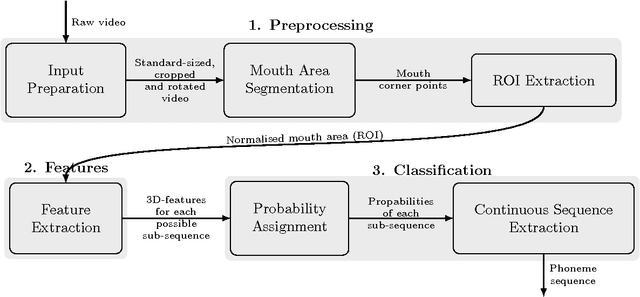


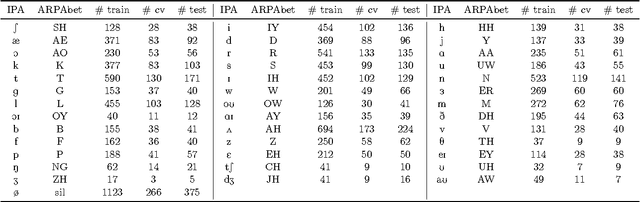
Visual speech recognition aims to identify the sequence of phonemes from continuous speech. Unlike the traditional approach of using 2D image feature extraction methods to derive features of each video frame separately, this paper proposes a new approach using a 3D (spatio-temporal) Discrete Cosine Transform to extract features of each feasible sub-sequence of an input video which are subsequently classified individually using Support Vector Machines and combined to find the most likely phoneme sequence using a tailor-made Hidden Markov Model. The algorithm is trained and tested on the VidTimit database to recognise sequences of phonemes as well as visemes (visual speech units). Furthermore, the system is extended with the training on phoneme or viseme pairs (biphones) to counteract the human speech ambiguity of co-articulation. The test set accuracy for the recognition of phoneme sequences is 20%, and the accuracy of viseme sequences is 39%. Both results improve the best values reported in other papers by approximately 2%. The contribution of the result is three-fold: Firstly, this paper is the first to show that 3D feature extraction methods can be applied to continuous sequence recognition tasks despite the unknown start positions and durations of each phoneme. Secondly, the result confirms that 3D feature extraction methods improve the accuracy compared to 2D features extraction methods. Thirdly, the paper is the first to specifically compare an otherwise identical method with and without using biphones, verifying that the usage of biphones has a positive impact on the result.
A Comparison of Methods for OOV-word Recognition on a New Public Dataset
Jul 16, 2021
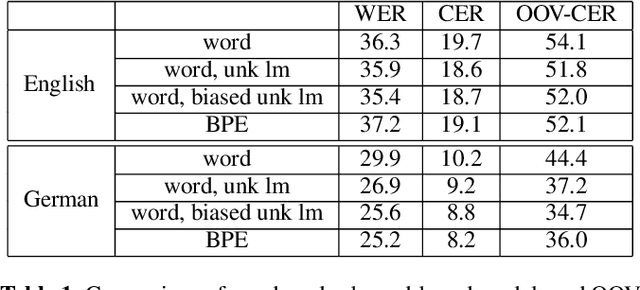
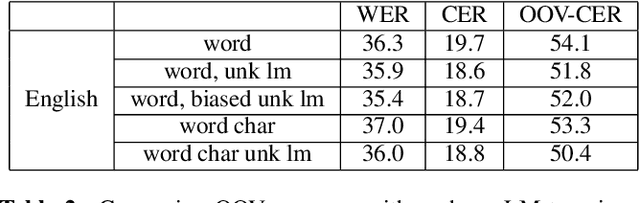
A common problem for automatic speech recognition systems is how to recognize words that they did not see during training. Currently there is no established method of evaluating different techniques for tackling this problem. We propose using the CommonVoice dataset to create test sets for multiple languages which have a high out-of-vocabulary (OOV) ratio relative to a training set and release a new tool for calculating relevant performance metrics. We then evaluate, within the context of a hybrid ASR system, how much better subword models are at recognizing OOVs, and how much benefit one can get from incorporating OOV-word information into an existing system by modifying WFSTs. Additionally, we propose a new method for modifying a subword-based language model so as to better recognize OOV-words. We showcase very large improvements in OOV-word recognition and make both the data and code available.
Animal inspired Application of a Variant of Mel Spectrogram for Seismic Data Processing
Sep 22, 2021

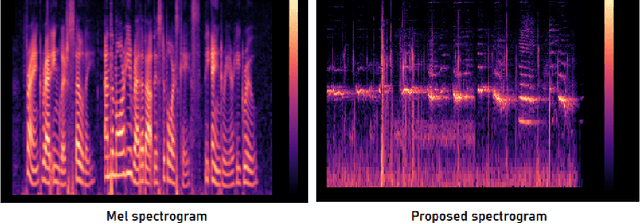
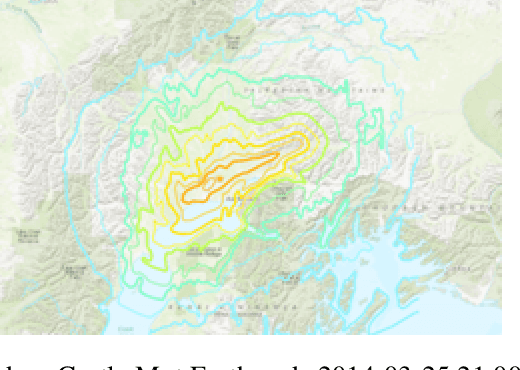
Predicting disaster events from seismic data is of paramount importance and can save thousands of lives, especially in earthquake-prone areas and habitations around volcanic craters. The drastic rise in the number of seismic monitoring stations in recent years has allowed the collection of a huge quantity of data, outpacing the capacity of seismologists. Due to the complex nature of the seismological data, it is often difficult for seismologists to detect subtle patterns with major implications. Machine learning algorithms have been demonstrated to be effective in classification and prediction tasks for seismic data. It has been widely known that some animals can sense disasters like earthquakes from seismic signals well before the disaster strikes. Mel spectrogram has been widely used for speech recognition as it scales the actual frequencies according to human hearing. In this paper, we propose a variant of the Mel spectrogram to scale the raw frequencies of seismic data to the hearing of such animals that can sense disasters from seismic signals. We are using a Computer vision algorithm along with clustering that allows for the classification of unlabelled seismic data.
Stepwise-Refining Speech Separation Network via Fine-Grained Encoding in High-order Latent Domain
Oct 10, 2021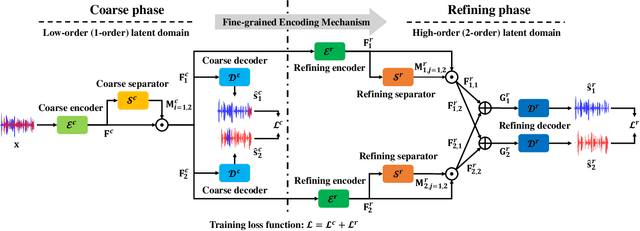
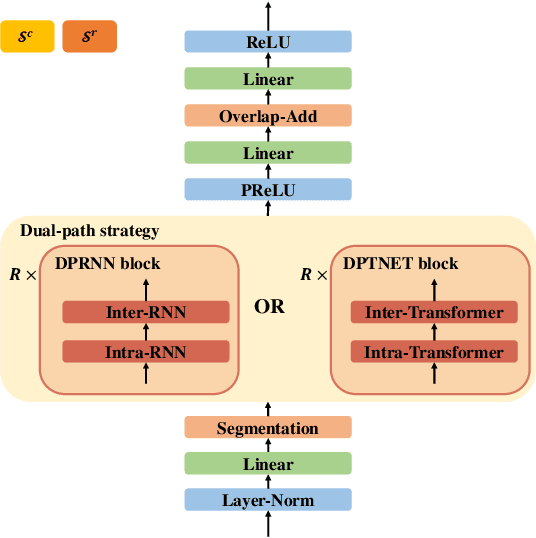
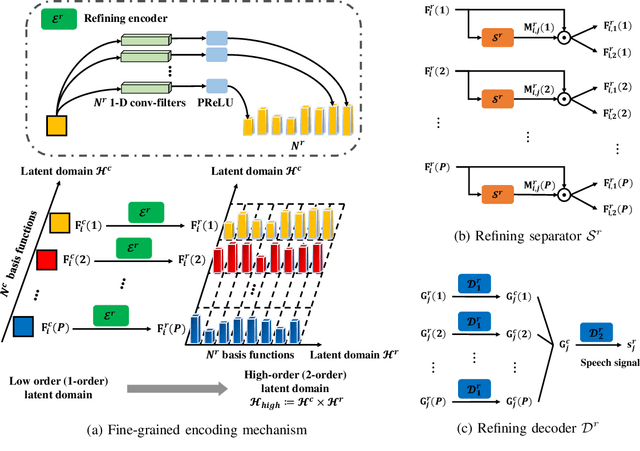
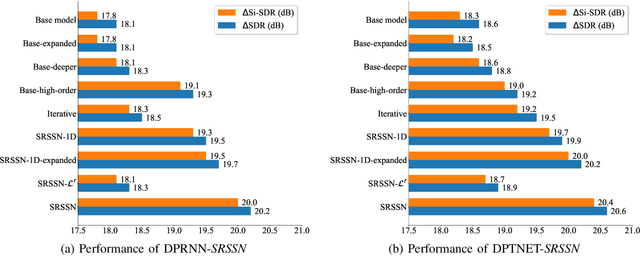
The crux of single-channel speech separation is how to encode the mixture of signals into such a latent embedding space that the signals from different speakers can be precisely separated. Existing methods for speech separation either transform the speech signals into frequency domain to perform separation or seek to learn a separable embedding space by constructing a latent domain based on convolutional filters. While the latter type of methods learning an embedding space achieves substantial improvement for speech separation, we argue that the embedding space defined by only one latent domain does not suffice to provide a thoroughly separable encoding space for speech separation. In this paper, we propose the Stepwise-Refining Speech Separation Network (SRSSN), which follows a coarse-to-fine separation framework. It first learns a 1-order latent domain to define an encoding space and thereby performs a rough separation in the coarse phase. Then the proposed SRSSN learns a new latent domain along each basis function of the existing latent domain to obtain a high-order latent domain in the refining phase, which enables our model to perform a refining separation to achieve a more precise speech separation. We demonstrate the effectiveness of our SRSSN by conducting extensive experiments, including speech separation in a clean (noise-free) setting on WSJ0-2/3mix datasets as well as in noisy/reverberant settings on WHAM!/WHAMR! datasets. Furthermore, we also perform experiments of speech recognition on separated speech signals by our model to evaluate the performance of speech separation indirectly.
Kaizen: Continuously improving teacher using Exponential Moving Average for semi-supervised speech recognition
Jun 14, 2021
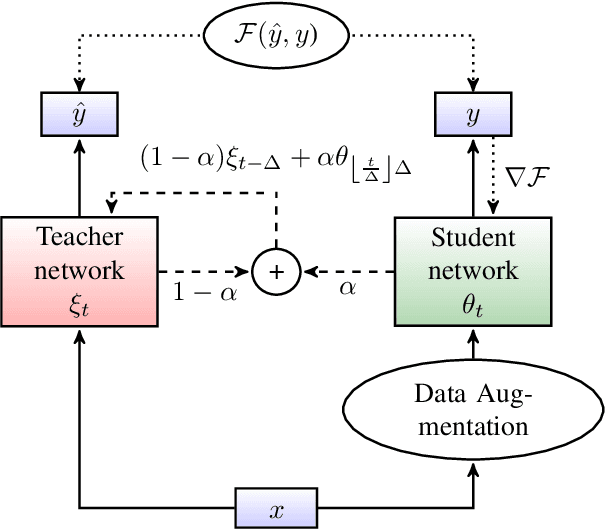
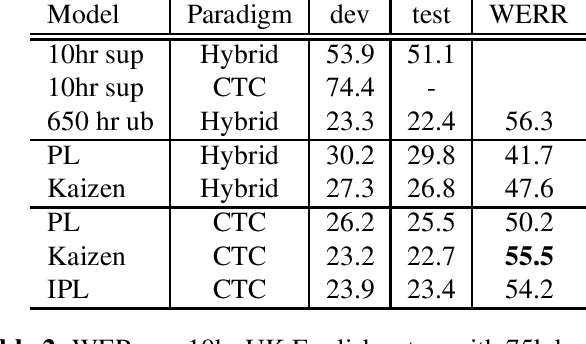
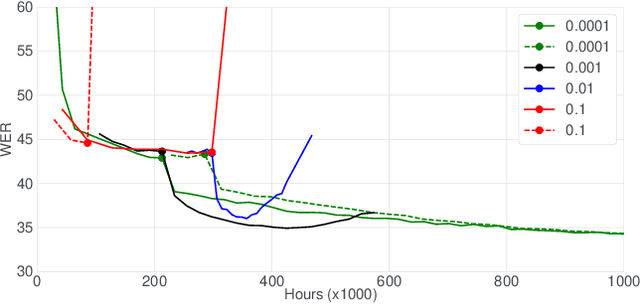
In this paper, we introduce the Kaizen framework that uses a continuously improving teacher to generate pseudo-labels for semi-supervised training. The proposed approach uses a teacher model which is updated as the exponential moving average of the student model parameters. This can be seen as a continuous version of the iterative pseudo-labeling approach for semi-supervised training. It is applicable for different training criteria, and in this paper we demonstrate it for frame-level hybrid hidden Markov model - deep neural network (HMM-DNN) models and sequence-level connectionist temporal classification (CTC) based models. The proposed approach shows more than 10% word error rate (WER) reduction over standard teacher-student training and more than 50\% relative WER reduction over 10 hour supervised baseline when using large scale realistic unsupervised public videos in UK English and Italian languages.
Combined Acoustic and Pronunciation Modelling for Non-Native Speech Recognition
Nov 06, 2007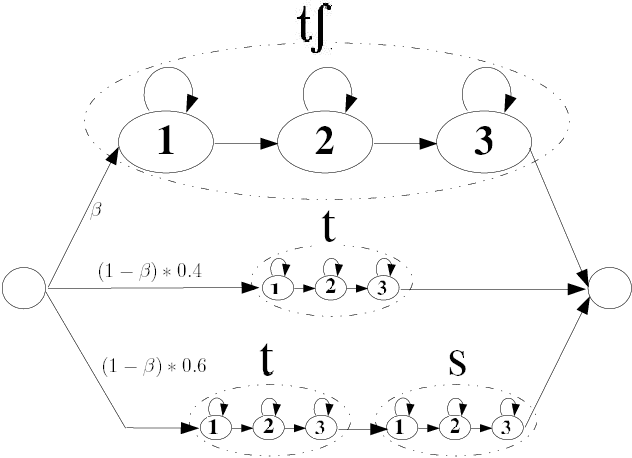
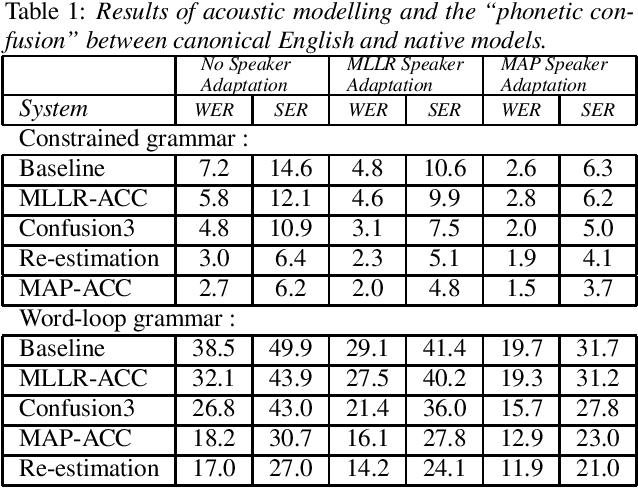

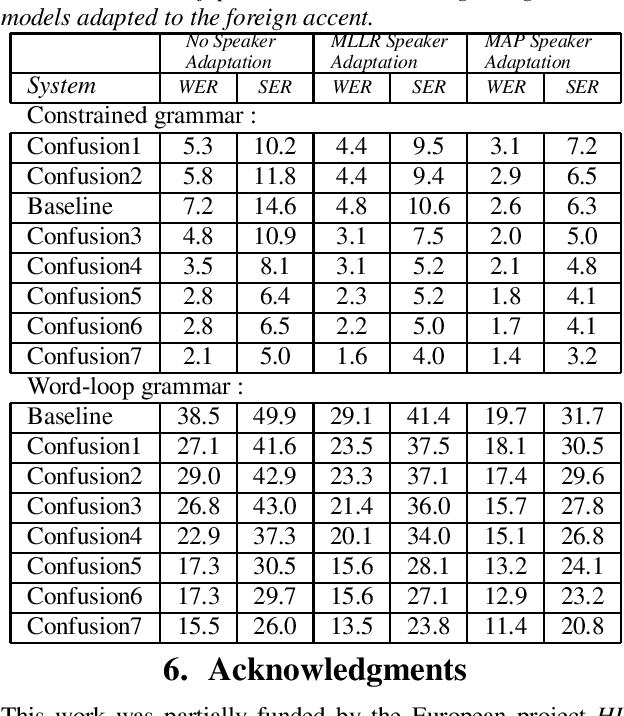
In this paper, we present several adaptation methods for non-native speech recognition. We have tested pronunciation modelling, MLLR and MAP non-native pronunciation adaptation and HMM models retraining on the HIWIRE foreign accented English speech database. The ``phonetic confusion'' scheme we have developed consists in associating to each spoken phone several sequences of confused phones. In our experiments, we have used different combinations of acoustic models representing the canonical and the foreign pronunciations: spoken and native models, models adapted to the non-native accent with MAP and MLLR. The joint use of pronunciation modelling and acoustic adaptation led to further improvements in recognition accuracy. The best combination of the above mentioned techniques resulted in a relative word error reduction ranging from 46% to 71%.
BSTC: A Large-Scale Chinese-English Speech Translation Dataset
Apr 09, 2021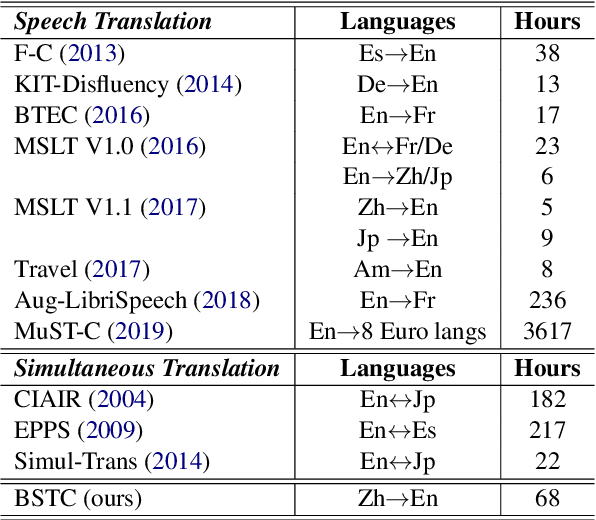
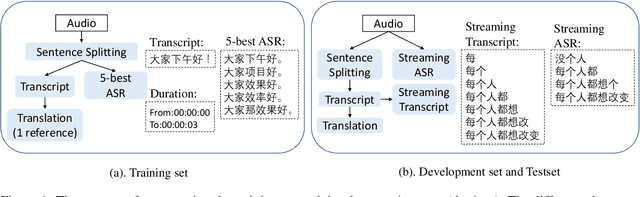

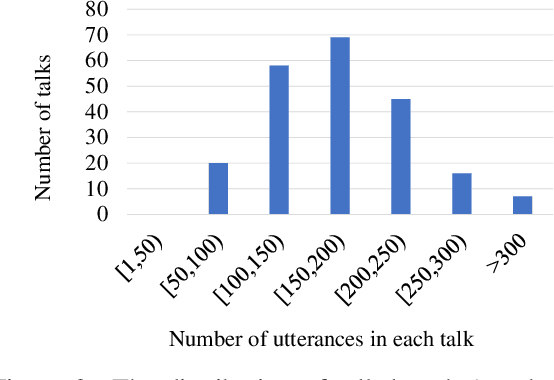
This paper presents BSTC (Baidu Speech Translation Corpus), a large-scale Chinese-English speech translation dataset. This dataset is constructed based on a collection of licensed videos of talks or lectures, including about 68 hours of Mandarin data, their manual transcripts and translations into English, as well as automated transcripts by an automatic speech recognition (ASR) model. We have further asked three experienced interpreters to simultaneously interpret the testing talks in a mock conference setting. This corpus is expected to promote the research of automatic simultaneous translation as well as the development of practical systems. We have organized simultaneous translation tasks and used this corpus to evaluate automatic simultaneous translation systems.
End-to-End Automatic Speech Recognition with Deep Mutual Learning
Feb 16, 2021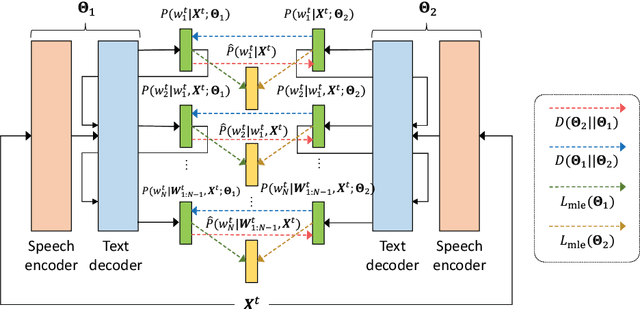
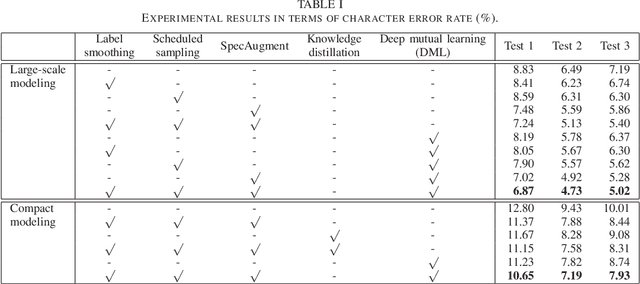
This paper is the first study to apply deep mutual learning (DML) to end-to-end ASR models. In DML, multiple models are trained simultaneously and collaboratively by mimicking each other throughout the training process, which helps to attain the global optimum and prevent models from making over-confident predictions. While previous studies applied DML to simple multi-class classification problems, there are no studies that have used it on more complex sequence-to-sequence mapping problems. For this reason, this paper presents a method to apply DML to state-of-the-art Transformer-based end-to-end ASR models. In particular, we propose to combine DML with recent representative training techniques. i.e., label smoothing, scheduled sampling, and SpecAugment, each of which are essential for powerful end-to-end ASR models. We expect that these training techniques work well with DML because DML has complementary characteristics. We experimented with two setups for Japanese ASR tasks: large-scale modeling and compact modeling. We demonstrate that DML improves the ASR performance of both modeling setups compared with conventional learning methods including knowledge distillation. We also show that combining DML with the existing training techniques effectively improves ASR performance.