 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Based Data Generation and Clinical Skills Evaluation for Low-Resource French OSCEs
Apr 09, 2026Objective Structured Clinical Examinations (OSCEs) are the standard method for assessing medical students' clinical and communication skills through structured patient interviews. In France, however, the organization of training sessions is limited by human and logistical constraints, restricting students' access to repeated practice and structured feedback. Recent advances in Natural Language Processing (NLP) and Large Language Models (LLMs) now offer the opportunity to automatically evaluate such medical interviews, thereby alleviating the need for human examiners during training. Yet, real French OSCE annotated transcripts remain extremely scarce, limiting reproducible research and reliable benchmarking. To address these challenges, we investigate the use of LLMs for both generating and evaluating French OSCE dialogues in a low-resource context. We introduce a controlled pipeline that produces synthetic doctor-patient interview transcripts guided by scenario-specific evaluation criteria, combining ideal and perturbed performances to simulate varying student skill levels. The resulting dialogues are automatically silver-labeled through an LLM-assisted framework supporting adjustable evaluation strictness. Benchmarking multiple open-source and proprietary LLMs shows that mid-size models ($\le$32B parameters) achieve accuracies comparable to GPT-4o ($\sim$90\%) on synthetic data, highlighting the feasibility of locally deployable, privacy-preserving evaluation systems for medical education.
Cross-lingual Matryoshka Representation Learning across Speech and Text
Feb 23, 2026Speakers of under-represented languages face both a language barrier, as most online knowledge is in a few dominant languages, and a modality barrier, since information is largely text-based while many languages are primarily oral. We address this for French-Wolof by training the first bilingual speech-text Matryoshka embedding model, enabling efficient retrieval of French text from Wolof speech queries without relying on a costly ASR-translation pipelines. We introduce large-scale data curation pipelines and new benchmarks, compare modeling strategies, and show that modality fusion within a frozen text Matryoshka model performs best. Although trained only for retrieval, the model generalizes well to other tasks, such as speech intent detection, indicating the learning of general semantic representations. Finally, we analyze cost-accuracy trade-offs across Matryoshka dimensions and ranks, showing that information is concentrated only in a few components, suggesting potential for efficiency improvements.
Speech Language Models for Under-Represented Languages: Insights from Wolof
Sep 18, 2025We present our journey in training a speech language model for Wolof, an underrepresented language spoken in West Africa, and share key insights. We first emphasize the importance of collecting large-scale, spontaneous, high-quality speech data, and show that continued pretraining HuBERT on this dataset outperforms both the base model and African-centric models on ASR. We then integrate this speech encoder into a Wolof LLM to train the first Speech LLM for this language, extending its capabilities to tasks such as speech translation. Furthermore, we explore training the Speech LLM to perform multi-step Chain-of-Thought before transcribing or translating. Our results show that the Speech LLM not only improves speech recognition but also performs well in speech translation. The models and the code will be openly shared.
Mixture of LoRA Experts for Low-Resourced Multi-Accent Automatic Speech Recognition
May 26, 2025



We aim to improve the robustness of Automatic Speech Recognition (ASR) systems against non-native speech, particularly in low-resourced multi-accent settings. We introduce Mixture of Accent-Specific LoRAs (MAS-LoRA), a fine-tuning method that leverages a mixture of Low-Rank Adaptation (LoRA) experts, each specialized in a specific accent. This method can be used when the accent is known or unknown at inference time, without the need to fine-tune the model again. Our experiments, conducted using Whisper on the L2-ARCTIC corpus, demonstrate significant improvements in Word Error Rate compared to regular LoRA and full fine-tuning when the accent is unknown. When the accent is known, the results further improve. Furthermore, MAS-LoRA shows less catastrophic forgetting than the other fine-tuning methods. To the best of our knowledge, this is the first use of a mixture of LoRA experts for non-native multi-accent ASR.
Lillama: Large Language Models Compression via Low-Rank Feature Distillation
Dec 28, 2024



Current LLM structured pruning methods typically involve two steps: (1) compression with calibration data and (2) costly continued pretraining on billions of tokens to recover lost performance. This second step is necessary as the first significantly impacts model accuracy. Prior research suggests pretrained Transformer weights aren't inherently low-rank, unlike their activations, which may explain this drop. Based on this observation, we propose Lillama, a compression method that locally distills activations with low-rank weights. Using SVD for initialization and a joint loss combining teacher and student activations, we accelerate convergence and reduce memory use with local gradient updates. Lillama compresses Mixtral-8x7B within minutes on a single A100 GPU, removing 10 billion parameters while retaining over 95% of its original performance. Phi-2 3B can be compressed by 40% with just 13 million calibration tokens, resulting in a small model that competes with recent models of similar size. The method generalizes well to non-transformer architectures, compressing Mamba-3B by 20% while maintaining 99% performance.
Large Language Models Compression via Low-Rank Feature Distillation
Dec 21, 2024Current LLM structured pruning methods involve two steps: (1) compressing with calibration data and (2) continued pretraining on billions of tokens to recover the lost performance. This costly second step is needed as the first step significantly impacts performance. Previous studies have found that pretrained Transformer weights aren't inherently low-rank, unlike their activations, which may explain this performance drop. Based on this observation, we introduce a one-shot compression method that locally distills low-rank weights. We accelerate convergence by initializing the low-rank weights with SVD and using a joint loss that combines teacher and student activations. We reduce memory requirements by applying local gradient updates only. Our approach can compress Mixtral-8x7B within minutes on a single A100 GPU, removing 10 billion parameters while maintaining over 95% of the original performance. Phi-2 3B can be compressed by 40% using only 13 million calibration tokens into a small model that competes with recent models of similar size. We show our method generalizes well to non-transformer architectures: Mamba-3B can be compressed by 20% while maintaining 99% of its performance.
SAMbA: Speech enhancement with Asynchronous ad-hoc Microphone Arrays
Jul 31, 2023Speech enhancement in ad-hoc microphone arrays is often hindered by the asynchronization of the devices composing the microphone array. Asynchronization comes from sampling time offset and sampling rate offset which inevitably occur when the microphones are embedded in different hardware components. In this paper, we propose a deep neural network (DNN)-based speech enhancement solution that is suited for applications in ad-hoc microphone arrays because it is distributed and copes with asynchronization. We show that asynchronization has a limited impact on the spatial filtering and mostly affects the performance of the DNNs. Instead of resynchronising the signals, which requires costly processing steps, we use an attention mechanism which makes the DNNs, thus our whole pipeline, robust to asynchronization. We also show that the attention mechanism leads to the asynchronization parameters in an unsupervised manner.
Transferring Knowledge via Neighborhood-Aware Optimal Transport for Low-Resource Hate Speech Detection
Oct 17, 2022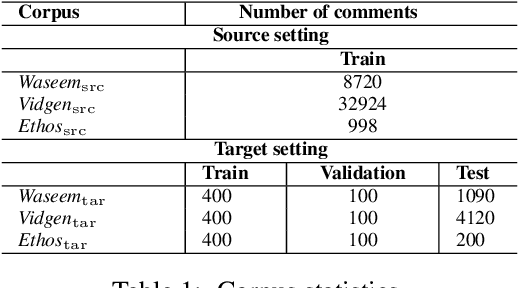
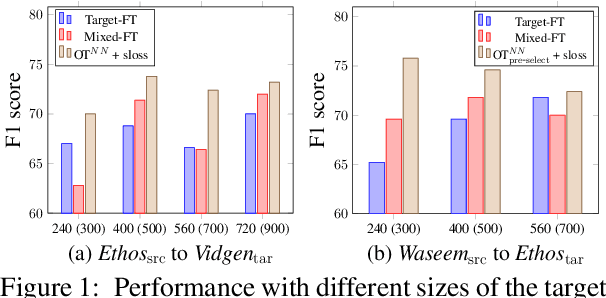

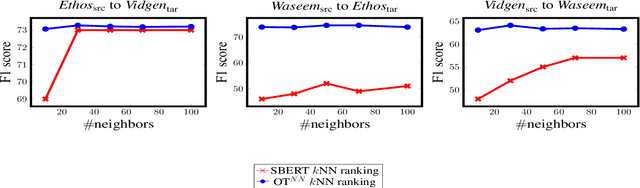
The concerning rise of hateful content on online platforms has increased the attention towards automatic hate speech detection, commonly formulated as a supervised classification task. State-of-the-art deep learning-based approaches usually require a substantial amount of labeled resources for training. However, annotating hate speech resources is expensive, time-consuming, and often harmful to the annotators. This creates a pressing need to transfer knowledge from the existing labeled resources to low-resource hate speech corpora with the goal of improving system performance. For this, neighborhood-based frameworks have been shown to be effective. However, they have limited flexibility. In our paper, we propose a novel training strategy that allows flexible modeling of the relative proximity of neighbors retrieved from a resource-rich corpus to learn the amount of transfer. In particular, we incorporate neighborhood information with Optimal Transport, which permits exploiting the geometry of the data embedding space. By aligning the joint embedding and label distributions of neighbors, we demonstrate substantial improvements over strong baselines, in low-resource scenarios, on different publicly available hate speech corpora.
Domain Classification-based Source-specific Term Penalization for Domain Adaptation in Hate-speech Detection
Sep 18, 2022
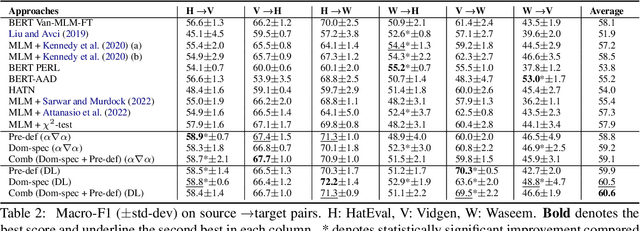


State-of-the-art approaches for hate-speech detection usually exhibit poor performance in out-of-domain settings. This occurs, typically, due to classifiers overemphasizing source-specific information that negatively impacts its domain invariance. Prior work has attempted to penalize terms related to hate-speech from manually curated lists using feature attribution methods, which quantify the importance assigned to input terms by the classifier when making a prediction. We, instead, propose a domain adaptation approach that automatically extracts and penalizes source-specific terms using a domain classifier, which learns to differentiate between domains, and feature-attribution scores for hate-speech classes, yielding consistent improvements in cross-domain evaluation.
Placing M-Phasis on the Plurality of Hate: A Feature-Based Corpus of Hate Online
Apr 28, 2022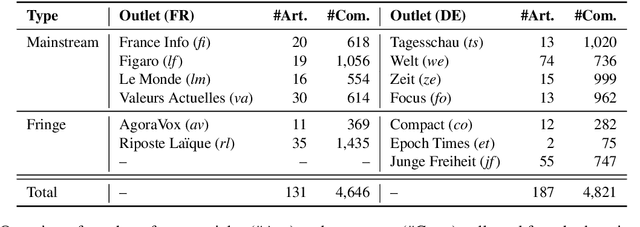

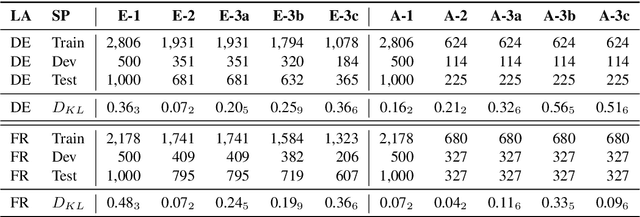
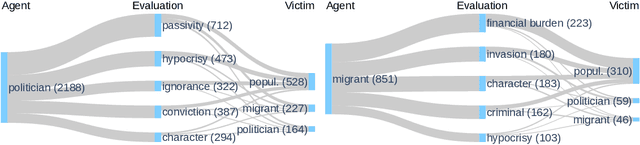
Even though hate speech (HS) online has been an important object of research in the last decade, most HS-related corpora over-simplify the phenomenon of hate by attempting to label user comments as "hate" or "neutral". This ignores the complex and subjective nature of HS, which limits the real-life applicability of classifiers trained on these corpora. In this study, we present the M-Phasis corpus, a corpus of ~9k German and French user comments collected from migration-related news articles. It goes beyond the "hate"-"neutral" dichotomy and is instead annotated with 23 features, which in combination become descriptors of various types of speech, ranging from critical comments to implicit and explicit expressions of hate. The annotations are performed by 4 native speakers per language and achieve high (0.77 <= k <= 1) inter-annotator agreements. Besides describing the corpus creation and presenting insights from a content, error and domain analysis, we explore its data characteristics by training several classification baselines.