 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASR-GLUE: A New Multi-task Benchmark for ASR-Robust Natural Language Understanding
Paper and Code

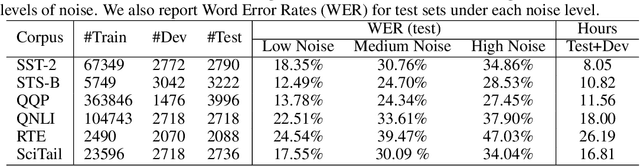
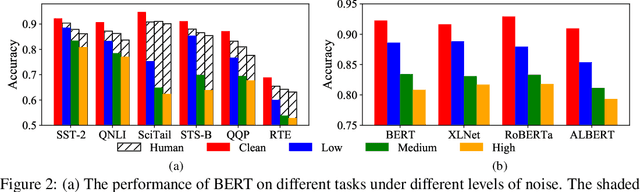

Language understanding in speech-based systems have attracted much attention in recent years with the growing demand for voice interface applications. However, the robustness of natural language understanding (NLU) systems to errors introduced by automatic speech recognition (ASR) is under-examined. %To facilitate the research on ASR-robust general language understanding, In this paper, we propose ASR-GLUE benchmark, a new collection of 6 different NLU tasks for evaluating the performance of models under ASR error across 3 different levels of background noise and 6 speakers with various voice characteristics. Based on the proposed benchmark, we systematically investigate the effect of ASR error on NLU tasks in terms of noise intensity, error type and speaker variants. We further purpose two ways, correction-based method and data augmentation-based method to improve robustness of the NLU systems. Extensive experimental results and analysises show that the proposed methods are effective to some extent, but still far from human performance, demonstrating that NLU under ASR error is still very challenging and requires further research.