 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
From Senones to Chenones: Tied Context-Dependent Graphemes for Hybrid Speech Recognition
Oct 11, 2019
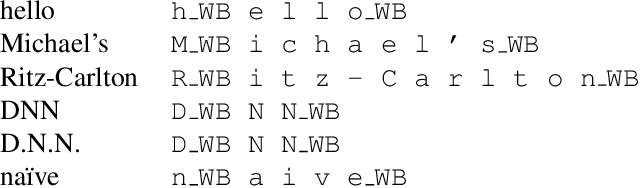
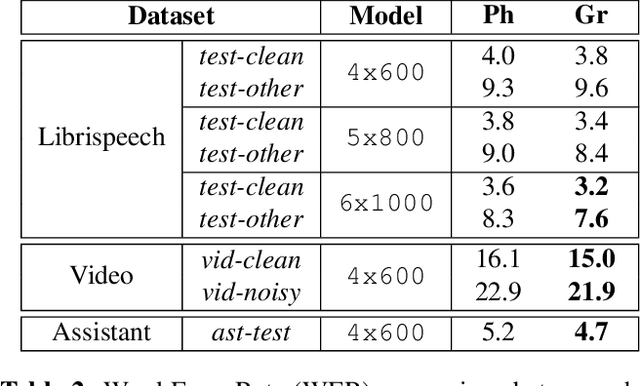
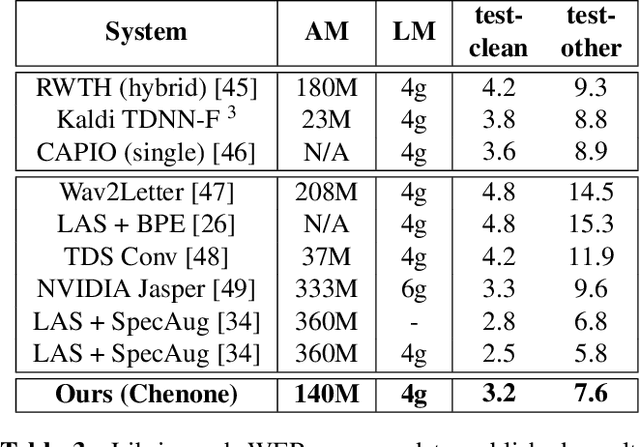
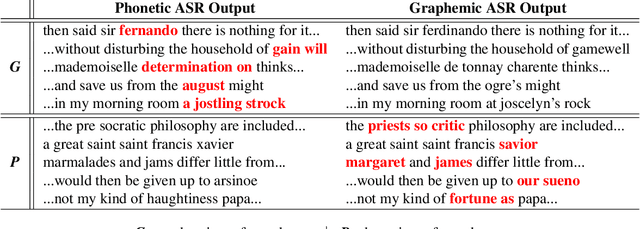
There is an implicit assumption that traditional hybrid approaches for automatic speech recognition (ASR) cannot directly model graphemes and need to rely on phonetic lexicons to get competitive performance, especially on English which has poor grapheme-phoneme correspondence. In this work, we show for the first time that, on English, hybrid ASR systems can in fact model graphemes effectively by leveraging tied context-dependent graphemes, i.e., chenones. Our chenone-based systems significantly outperform equivalent senone baselines by 4.5% to 11.1% relative on three different English datasets. Our results on Librispeech are state-of-the-art compared to other hybrid approaches and competitive with previously published end-to-end numbers. Further analysis shows that chenones can better utilize powerful acoustic models and large training data, and require context- and position-dependent modeling to work well. Chenone-based systems also outperform senone baselines on proper noun and rare word recognition, an area where the latter is traditionally thought to have an advantage. Our work provides an alternative for end-to-end ASR and establishes that hybrid systems can be improved by dropping the reliance on phonetic knowledge.
Joint Encoder-Decoder Self-Supervised Pre-training for ASR
Jun 09, 2022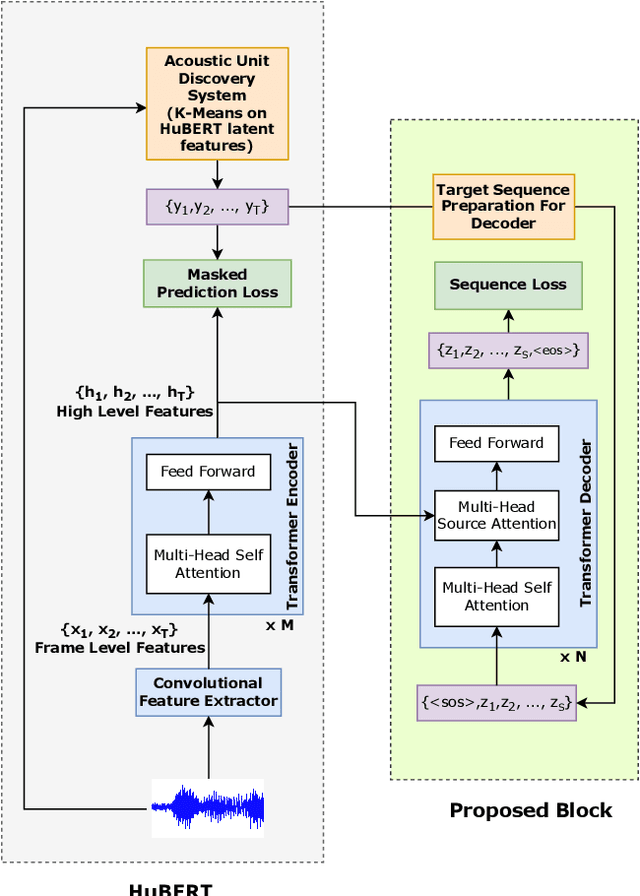
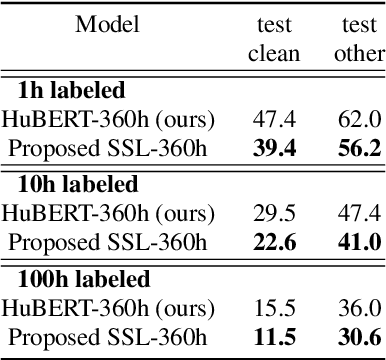
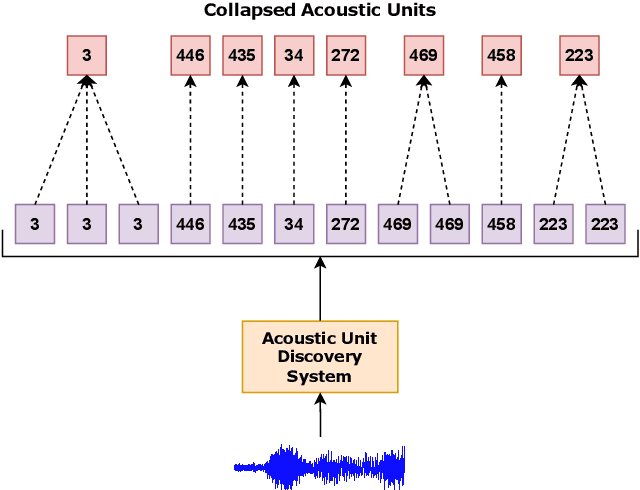
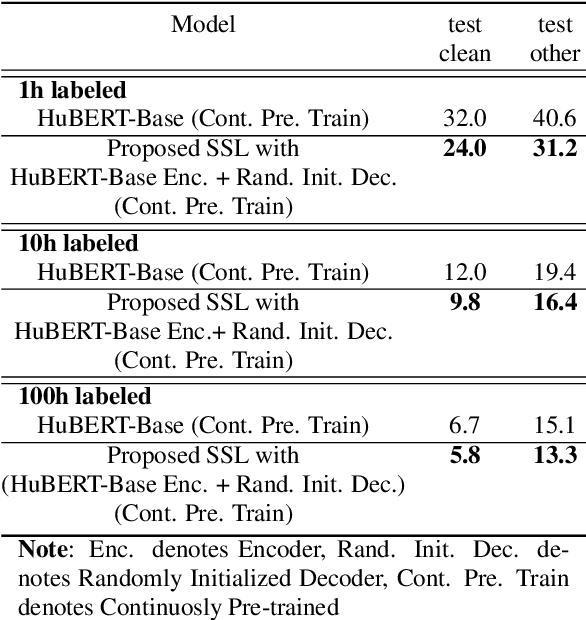
Self-supervised learning (SSL) has shown tremendous success in various speech-related downstream tasks, including Automatic Speech Recognition (ASR). The output embeddings of the SSL model are treated as powerful short-time representations of the speech signal. However, in the ASR task, the main objective is to get the correct sequence of acoustic units, characters, or byte-pair encodings (BPEs). Usually, encoder-decoder architecture works exceptionally well for a sequence-to-sequence task like ASR. Therefore, in this paper, we propose a new paradigm that exploits the power of a decoder during self-supervised learning. We use Hidden Unit BERT (HuBERT) SSL framework to compute the conventional masked prediction loss for the encoder. In addition, we have introduced a decoder in the SSL framework and proposed a target preparation strategy for the decoder. Finally, we use a multitask SSL setup wherein we jointly optimize both the encoder and decoder losses. We hypothesize that the presence of a decoder in the SSL model helps it learn an acoustic unit-based language model, which might improve the performance of an ASR downstream task. We compare our proposed SSL model with HuBERT and show up to 25% relative improvement in performance on ASR by finetuning on various LibriSpeech subsets.
Almost Unsupervised Text to Speech and Automatic Speech Recognition
May 13, 2019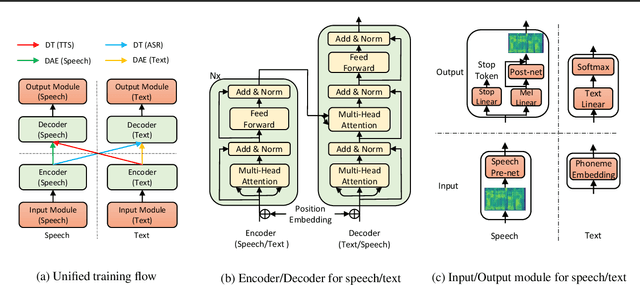
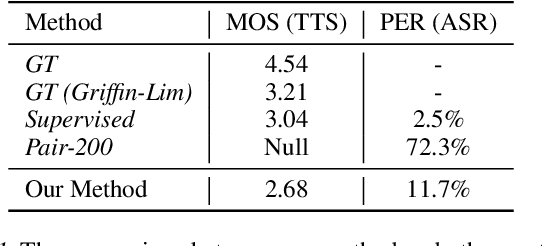
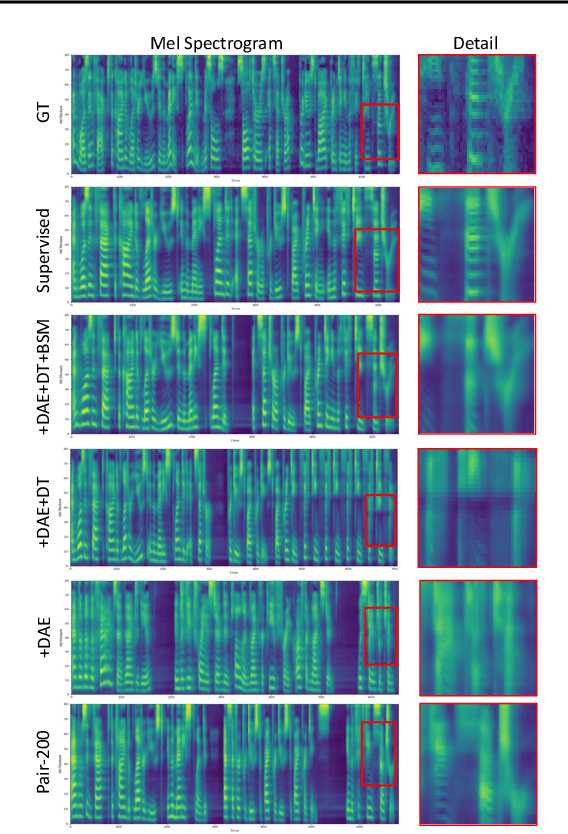

Text to speech (TTS) and automatic speech recognition (ASR) are two dual tasks in speech processing and both achieve impressive performance thanks to the recent advance in deep learning and large amount of aligned speech and text data. However, the lack of aligned data poses a major practical problem for TTS and ASR on low-resource languages. In this paper, by leveraging the dual nature of the two tasks, we propose an almost unsupervised learning method that only leverages few hundreds of paired data and extra unpaired data for TTS and ASR. Our method consists of the following components: (1) a denoising auto-encoder, which reconstructs speech and text sequences respectively to develop the capability of language modeling both in speech and text domain; (2) dual transformation, where the TTS model transforms the text $y$ into speech $\hat{x}$, and the ASR model leverages the transformed pair $(\hat{x},y)$ for training, and vice versa, to boost the accuracy of the two tasks; (3) bidirectional sequence modeling, which addresses error propagation especially in the long speech and text sequence when training with few paired data; (4) a unified model structure, which combines all the above components for TTS and ASR based on Transformer model. Our method achieves 99.84% in terms of word level intelligible rate and 2.68 MOS for TTS, and 11.7% PER for ASR on LJSpeech dataset, by leveraging only 200 paired speech and text data (about 20 minutes audio), together with extra unpaired speech and text data.
Wav2Letter: an End-to-End ConvNet-based Speech Recognition System
Sep 13, 2016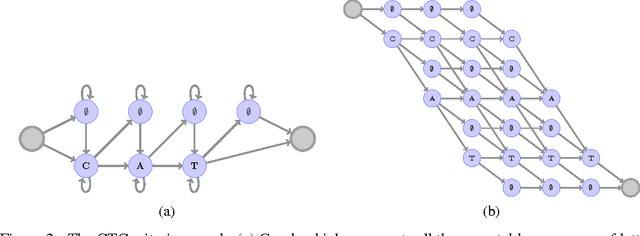
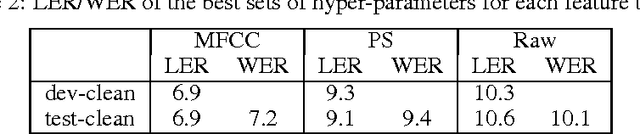
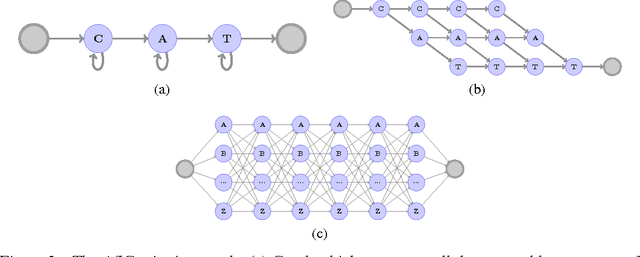
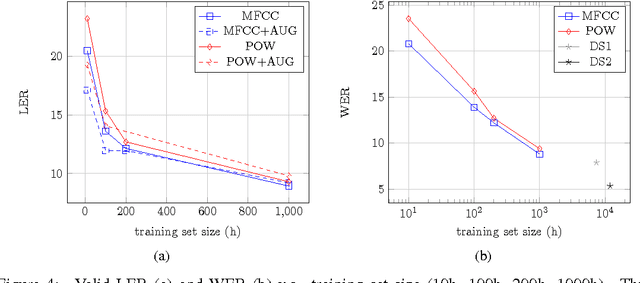
This paper presents a simple end-to-end model for speech recognition, combining a convolutional network based acoustic model and a graph decoding. It is trained to output letters, with transcribed speech, without the need for force alignment of phonemes. We introduce an automatic segmentation criterion for training from sequence annotation without alignment that is on par with CTC while being simpler. We show competitive results in word error rate on the Librispeech corpus with MFCC features, and promising results from raw waveform.
SUPERB @ SLT 2022: Challenge on Generalization and Efficiency of Self-Supervised Speech Representation Learning
Oct 16, 2022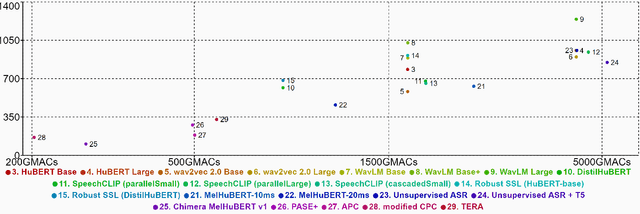
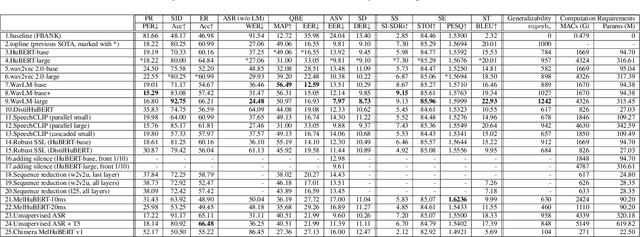
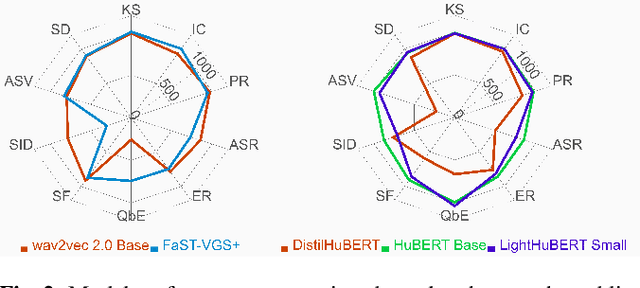
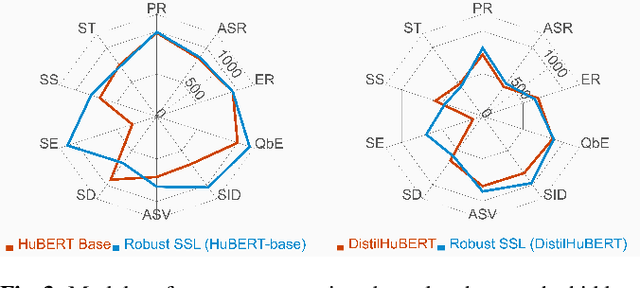
We present the SUPERB challenge at SLT 2022, which aims at learning self-supervised speech representation for better performance, generalization, and efficiency. The challenge builds upon the SUPERB benchmark and implements metrics to measure the computation requirements of self-supervised learning (SSL) representation and to evaluate its generalizability and performance across the diverse SUPERB tasks. The SUPERB benchmark provides comprehensive coverage of popular speech processing tasks, from speech and speaker recognition to audio generation and semantic understanding. As SSL has gained interest in the speech community and showed promising outcomes, we envision the challenge to uplevel the impact of SSL techniques by motivating more practical designs of techniques beyond task performance. We summarize the results of 14 submitted models in this paper. We also discuss the main findings from those submissions and the future directions of SSL research.
Very Deep Self-Attention Networks for End-to-End Speech Recognition
May 03, 2019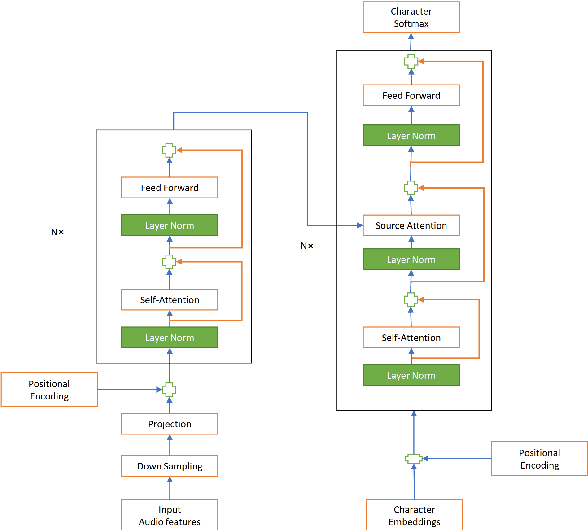
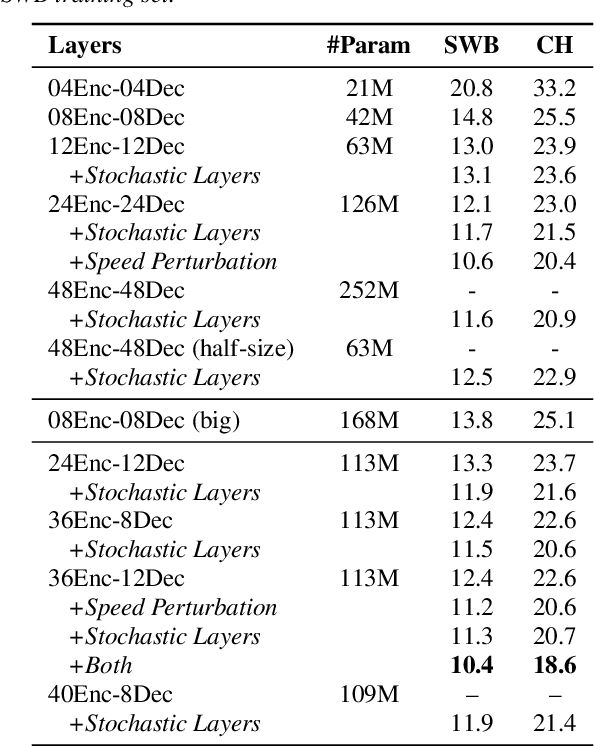
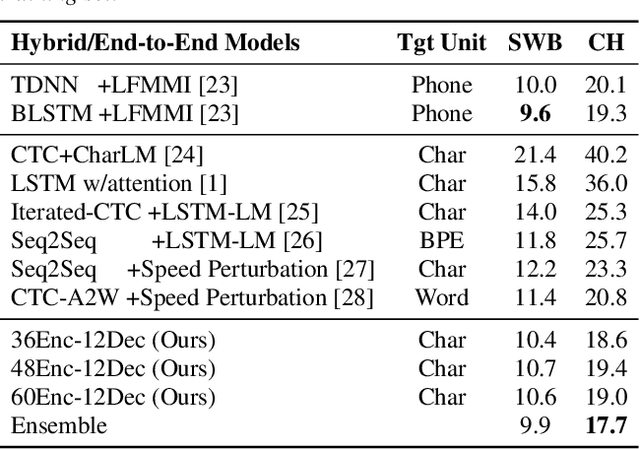

Recently, end-to-end sequence-to-sequence models for speech recognition have gained significant interest in the research community. While previous architecture choices revolve around time-delay neural networks (TDNN) and long short-term memory (LSTM) recurrent neural networks, we propose to use self-attention via the Transformer architecture as an alternative. Our analysis shows that deep Transformer networks with high learning capacity are able to exceed performance from previous end-to-end approaches and even match the conventional hybrid systems. Moreover, we trained very deep models with up to 48 Transformer layers for both encoder and decoders combined with stochastic residual connections, which greatly improve generalizability and training efficiency. The resulting models outperform all previous end-to-end ASR approaches on the Switchboard benchmark. An ensemble of these models achieve 9.9% and 17.7% WER on Switchboard and CallHome test sets respectively. This finding brings our end-to-end models to competitive levels with previous hybrid systems. Further, with model ensembling the Transformers can outperform certain hybrid systems, which are more complicated in terms of both structure and training procedure.
FLUTE: A Scalable, Extensible Framework for High-Performance Federated Learning Simulations
Mar 25, 2022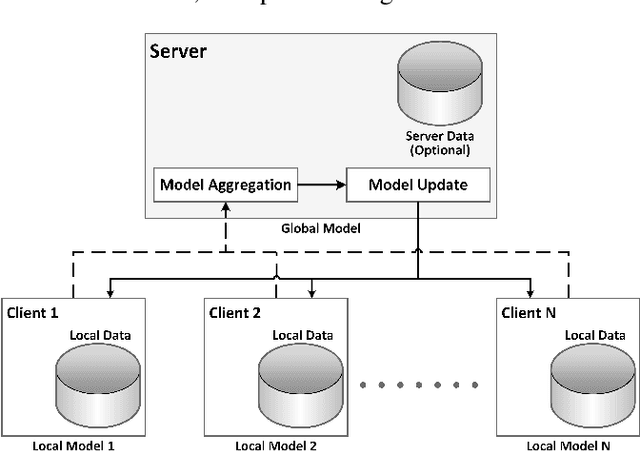
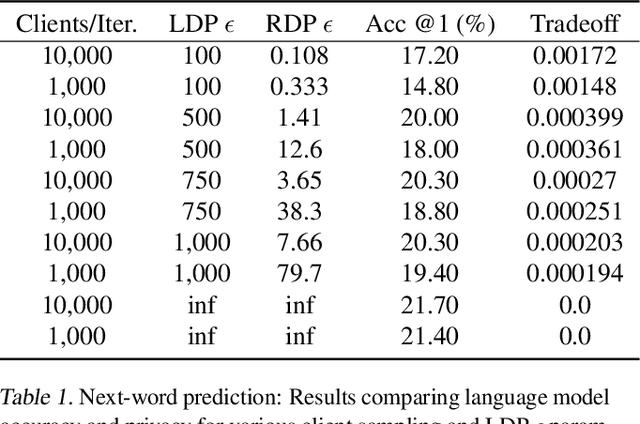
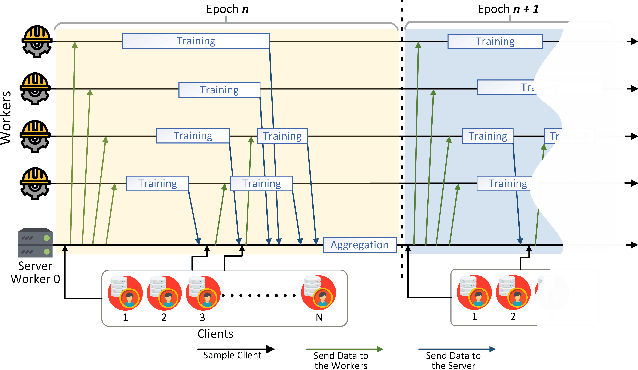
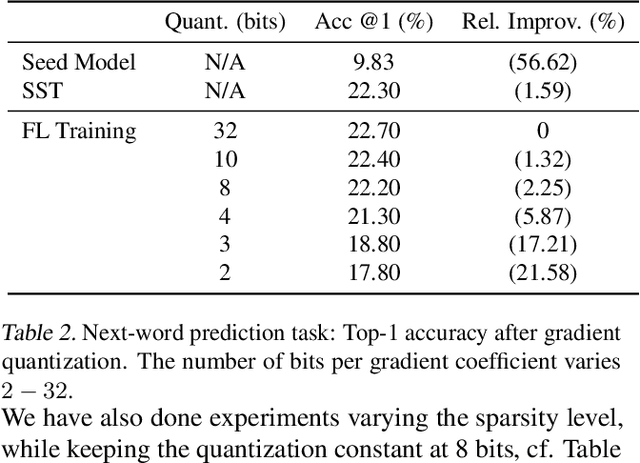
In this paper we introduce "Federated Learning Utilities and Tools for Experimentation" (FLUTE), a high-performance open source platform for federated learning research and offline simulations. The goal of FLUTE is to enable rapid prototyping and simulation of new federated learning algorithms at scale, including novel optimization, privacy, and communications strategies. We describe the architecture of FLUTE, enabling arbitrary federated modeling schemes to be realized, we compare the platform with other state-of-the-art platforms, and we describe available features of FLUTE for experimentation in core areas of active research, such as optimization, privacy and scalability. We demonstrate the effectiveness of the platform with a series of experiments for text prediction and speech recognition, including the addition of differential privacy, quantization, scaling and a variety of optimization and federation approaches.
Learning Noise-Invariant Representations for Robust Speech Recognition
Jul 17, 2018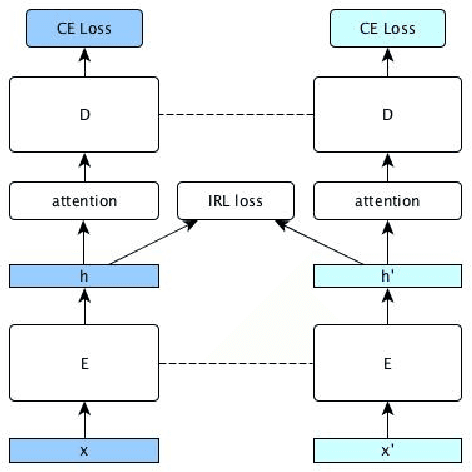
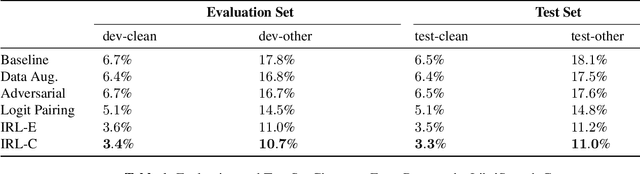
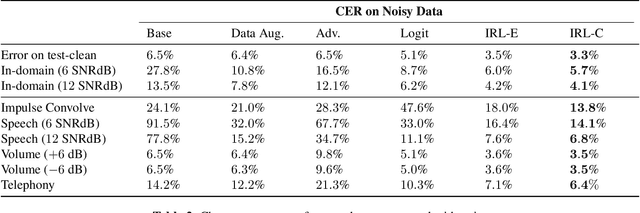
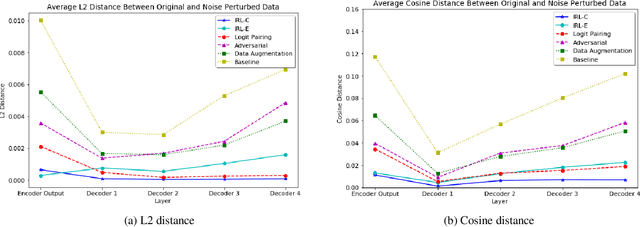
Despite rapid advances in speech recognition, current models remain brittle to superficial perturbations to their inputs. Small amounts of noise can destroy the performance of an otherwise state-of-the-art model. To harden models against background noise, practitioners often perform data augmentation, adding artificially-noised examples to the training set, carrying over the original label. In this paper, we hypothesize that a clean example and its superficially perturbed counterparts shouldn't merely map to the same class --- they should map to the same representation. We propose invariant-representation-learning (IRL): At each training iteration, for each training example,we sample a noisy counterpart. We then apply a penalty term to coerce matched representations at each layer (above some chosen layer). Our key results, demonstrated on the Librispeech dataset are the following: (i) IRL significantly reduces character error rates (CER) on both 'clean' (3.3% vs 6.5%) and 'other' (11.0% vs 18.1%) test sets; (ii) on several out-of-domain noise settings (different from those seen during training), IRL's benefits are even more pronounced. Careful ablations confirm that our results are not simply due to shrinking activations at the chosen layers.
Investigating Lexical Replacements for Arabic-English Code-Switched Data Augmentation
May 25, 2022
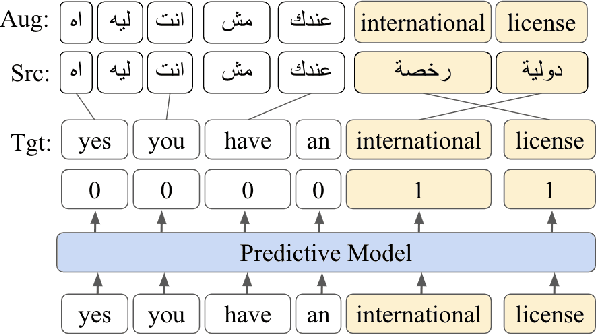

Code-switching (CS) poses several challenges to NLP tasks, where data sparsity is a main problem hindering the development of CS NLP systems. In this paper, we investigate data augmentation techniques for synthesizing Dialectal Arabic-English CS text. We perform lexical replacements using parallel corpora and alignments where CS points are either randomly chosen or learnt using a sequence-to-sequence model. We evaluate the effectiveness of data augmentation on language modeling (LM), machine translation (MT), and automatic speech recognition (ASR) tasks. Results show that in the case of using 1-1 alignments, using trained predictive models produces more natural CS sentences, as reflected in perplexity. By relying on grow-diag-final alignments, we then identify aligning segments and perform replacements accordingly. By replacing segments instead of words, the quality of synthesized data is greatly improved. With this improvement, random-based approach outperforms using trained predictive models on all extrinsic tasks. Our best models achieve 33.6% improvement in perplexity, +3.2-5.6 BLEU points on MT task, and 7% relative improvement on WER for ASR task. We also contribute in filling the gap in resources by collecting and publishing the first Arabic English CS-English parallel corpus.