 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Feedback to Checklists: Grounded Evaluation of AI-Generated Clinical Notes
Jul 23, 2025



AI-generated clinical notes are increasingly used in healthcare, but evaluating their quality remains a challenge due to high subjectivity and limited scalability of expert review. Existing automated metrics often fail to align with real-world physician preferences. To address this, we propose a pipeline that systematically distills real user feedback into structured checklists for note evaluation. These checklists are designed to be interpretable, grounded in human feedback, and enforceable by LLM-based evaluators. Using deidentified data from over 21,000 clinical encounters, prepared in accordance with the HIPAA safe harbor standard, from a deployed AI medical scribe system, we show that our feedback-derived checklist outperforms baseline approaches in our offline evaluations in coverage, diversity, and predictive power for human ratings. Extensive experiments confirm the checklist's robustness to quality-degrading perturbations, significant alignment with clinician preferences, and practical value as an evaluation methodology. In offline research settings, the checklist can help identify notes likely to fall below our chosen quality thresholds.
The Curious Language Model: Strategic Test-Time Information Acquisition
Jun 10, 2025
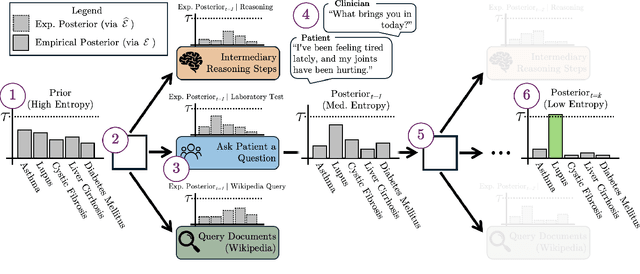


Decision-makers often possess insufficient information to render a confident decision. In these cases, the decision-maker can often undertake actions to acquire the necessary information about the problem at hand, e.g., by consulting knowledgeable authorities or by conducting experiments. Importantly, different levers of information acquisition come with different costs, posing the challenge of selecting the actions that are both informative and cost-effective. In this work, we propose CuriosiTree, a heuristic-based, test-time policy for zero-shot information acquisition in large language models (LLMs). CuriosiTree employs a greedy tree search to estimate the expected information gain of each action and strategically chooses actions based on a balance of anticipated information gain and associated cost. Empirical validation in a clinical diagnosis simulation shows that CuriosiTree enables cost-effective integration of heterogenous sources of information, and outperforms baseline action selection strategies in selecting action sequences that enable accurate diagnosis.
RoAST: Robustifying Language Models via Adversarial Perturbation with Selective Training
Dec 07, 2023



Fine-tuning pre-trained language models (LMs) has become the de facto standard in many NLP tasks. Nevertheless, fine-tuned LMs are still prone to robustness issues, such as adversarial robustness and model calibration. Several perspectives of robustness for LMs have been studied independently, but lacking a unified consideration in multiple perspectives. In this paper, we propose Robustifying LMs via Adversarial perturbation with Selective Training (RoAST), a simple yet effective fine-tuning technique to enhance the multi-perspective robustness of LMs in a unified way. RoAST effectively incorporates two important sources for the model robustness, robustness on the perturbed inputs and generalizable knowledge in pre-trained LMs. To be specific, RoAST introduces adversarial perturbation during fine-tuning while the model parameters are selectively updated upon their relative importance to minimize unnecessary deviation. Under a unified evaluation of fine-tuned LMs by incorporating four representative perspectives of model robustness, we demonstrate the effectiveness of RoAST compared to state-of-the-art fine-tuning methods on six different types of LMs, which indicates its usefulness in practice.
Co-training and Co-distillation for Quality Improvement and Compression of Language Models
Nov 07, 2023



Knowledge Distillation (KD) compresses computationally expensive pre-trained language models (PLMs) by transferring their knowledge to smaller models, allowing their use in resource-constrained or real-time settings. However, most smaller models fail to surpass the performance of the original larger model, resulting in sacrificing performance to improve inference speed. To address this issue, we propose Co-Training and Co-Distillation (CTCD), a novel framework that improves performance and inference speed together by co-training two models while mutually distilling knowledge. The CTCD framework successfully achieves this based on two significant findings: 1) Distilling knowledge from the smaller model to the larger model during co-training improves the performance of the larger model. 2) The enhanced performance of the larger model further boosts the performance of the smaller model. The CTCD framework shows promise as it can be combined with existing techniques like architecture design or data augmentation, replacing one-way KD methods, to achieve further performance improvement. Extensive ablation studies demonstrate the effectiveness of CTCD, and the small model distilled by CTCD outperforms the original larger model by a significant margin of 1.66 on the GLUE benchmark.
The Belebele Benchmark: a Parallel Reading Comprehension Dataset in 122 Language Variants
Aug 31, 2023



We present Belebele, a multiple-choice machine reading comprehension (MRC) dataset spanning 122 language variants. Significantly expanding the language coverage of natural language understanding (NLU) benchmarks, this dataset enables the evaluation of text models in high-, medium-, and low-resource languages. Each question is based on a short passage from the Flores-200 dataset and has four multiple-choice answers. The questions were carefully curated to discriminate between models with different levels of general language comprehension. The English dataset on its own proves difficult enough to challenge state-of-the-art language models. Being fully parallel, this dataset enables direct comparison of model performance across all languages. We use this dataset to evaluate the capabilities of multilingual masked language models (MLMs) and large language models (LLMs). We present extensive results and find that despite significant cross-lingual transfer in English-centric LLMs, much smaller MLMs pretrained on balanced multilingual data still understand far more languages. We also observe that larger vocabulary size and conscious vocabulary construction correlate with better performance on low-resource languages. Overall, Belebele opens up new avenues for evaluating and analyzing the multilingual capabilities of NLP systems.
A Study on Knowledge Distillation from Weak Teacher for Scaling Up Pre-trained Language Models
May 26, 2023Distillation from Weak Teacher (DWT) is a method of transferring knowledge from a smaller, weaker teacher model to a larger student model to improve its performance. Previous studies have shown that DWT can be effective in the vision domain and natural language processing (NLP) pre-training stage. Specifically, DWT shows promise in practical scenarios, such as enhancing new generation or larger models using pre-trained yet older or smaller models and lacking a resource budget. However, the optimal conditions for using DWT have yet to be fully investigated in NLP pre-training. Therefore, this study examines three key factors to optimize DWT, distinct from those used in the vision domain or traditional knowledge distillation. These factors are: (i) the impact of teacher model quality on DWT effectiveness, (ii) guidelines for adjusting the weighting value for DWT loss, and (iii) the impact of parameter remapping as a student model initialization technique for DWT.
XLM-V: Overcoming the Vocabulary Bottleneck in Multilingual Masked Language Models
Jan 25, 2023



Large multilingual language models typically rely on a single vocabulary shared across 100+ languages. As these models have increased in parameter count and depth, vocabulary size has remained largely unchanged. This vocabulary bottleneck limits the representational capabilities of multilingual models like XLM-R. In this paper, we introduce a new approach for scaling to very large multilingual vocabularies by de-emphasizing token sharing between languages with little lexical overlap and assigning vocabulary capacity to achieve sufficient coverage for each individual language. Tokenizations using our vocabulary are typically more semantically meaningful and shorter compared to XLM-R. Leveraging this improved vocabulary, we train XLM-V, a multilingual language model with a one million token vocabulary. XLM-V outperforms XLM-R on every task we tested on ranging from natural language inference (XNLI), question answering (MLQA, XQuAD, TyDiQA), and named entity recognition (WikiAnn) to low-resource tasks (Americas NLI, MasakhaNER).
Adaptable Claim Rewriting with Offline Reinforcement Learning for Effective Misinformation Discovery
Oct 14, 2022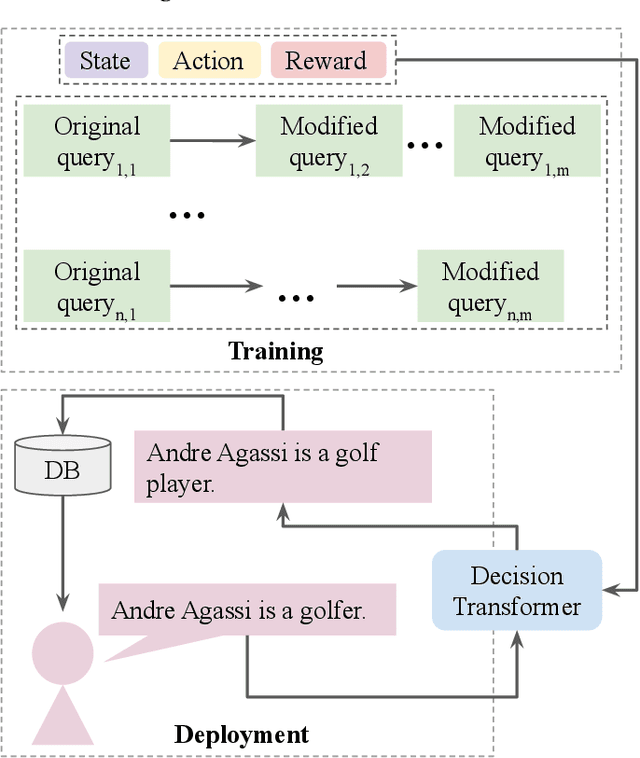
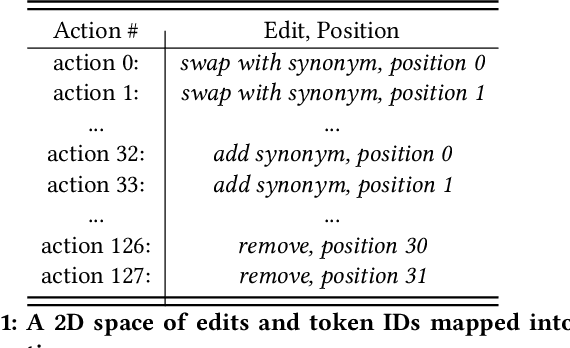
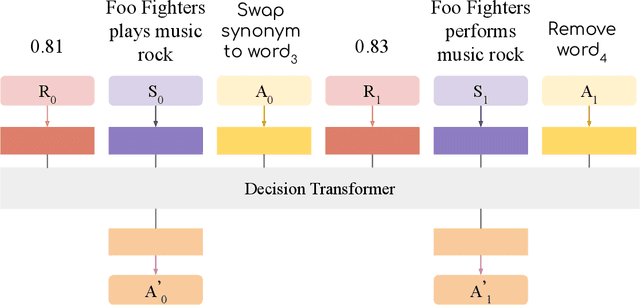

We propose a novel system to help fact-checkers formulate search queries for known misinformation claims and effectively search across multiple social media platforms. We introduce an adaptable rewriting strategy, where editing actions (e.g., swap a word with its synonym; change verb tense into present simple) for queries containing claims are automatically learned through offline reinforcement learning. Specifically, we use a decision transformer to learn a sequence of editing actions that maximize query retrieval metrics such as mean average precision. Through several experiments, we show that our approach can increase the effectiveness of the queries by up to 42\% relatively, while producing editing action sequences that are human readable, thus making the system easy to use and explain.
Attention-guided Generative Models for Extractive Question Answering
Oct 12, 2021
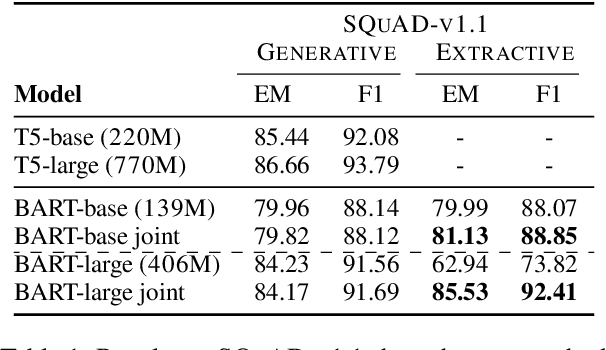
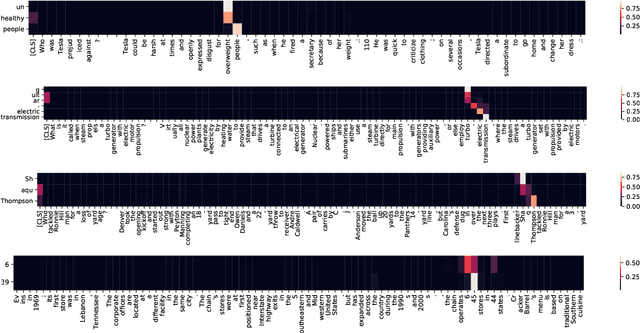
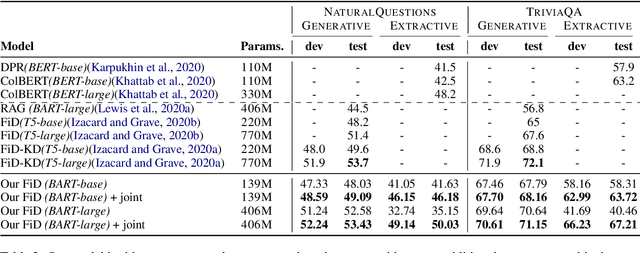
We propose a novel method for applying Transformer models to extractive question answering (QA) tasks. Recently, pretrained generative sequence-to-sequence (seq2seq) models have achieved great success in question answering. Contributing to the success of these models are internal attention mechanisms such as cross-attention. We propose a simple strategy to obtain an extractive answer span from the generative model by leveraging the decoder cross-attention patterns. Viewing cross-attention as an architectural prior, we apply joint training to further improve QA performance. Empirical results show that on open-domain question answering datasets like NaturalQuestions and TriviaQA, our method approaches state-of-the-art performance on both generative and extractive inference, all while using much fewer parameters. Furthermore, this strategy allows us to perform hallucination-free inference while conferring significant improvements to the model's ability to rerank relevant passages.
Multiplicative Position-aware Transformer Models for Language Understanding
Sep 27, 2021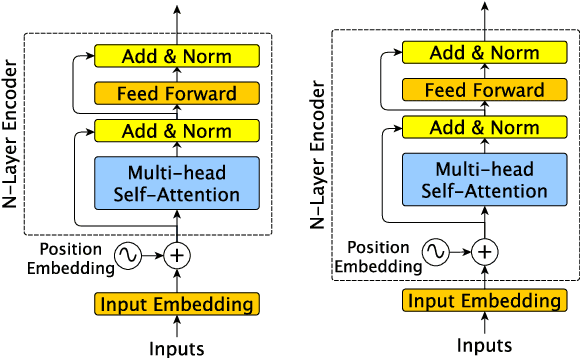

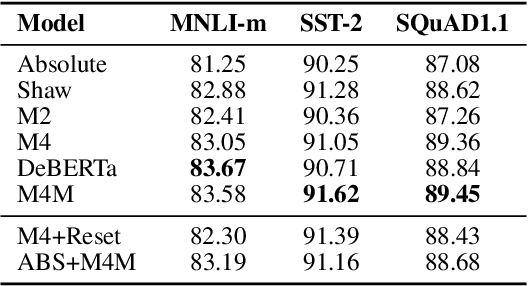
Transformer models, which leverage architectural improvements like self-attention, perform remarkably well on Natural Language Processing (NLP) tasks. The self-attention mechanism is position agnostic. In order to capture positional ordering information, various flavors of absolute and relative position embeddings have been proposed. However, there is no systematic analysis on their contributions and a comprehensive comparison of these methods is missing in the literature. In this paper, we review major existing position embedding methods and compare their accuracy on downstream NLP tasks, using our own implementations. We also propose a novel multiplicative embedding method which leads to superior accuracy when compared to existing methods. Finally, we show that our proposed embedding method, served as a drop-in replacement of the default absolute position embedding, can improve the RoBERTa-base and RoBERTa-large models on SQuAD1.1 and SQuAD2.0 datasets.