 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Explicit Intensity Control for Accented Text-to-speech
Oct 27, 2022
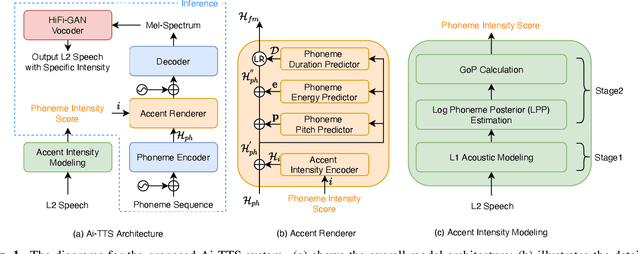
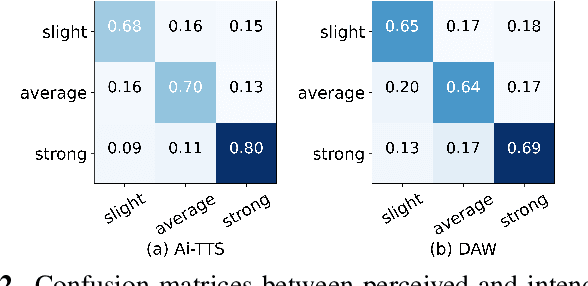
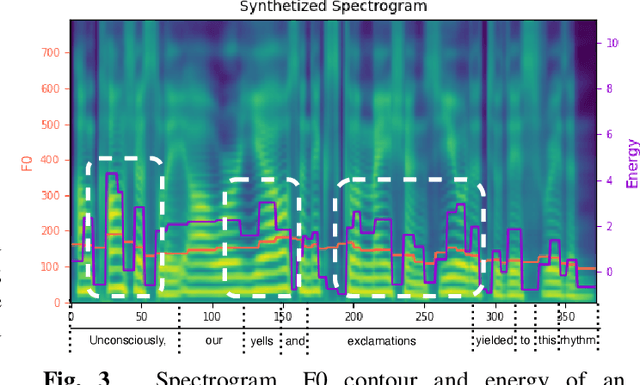
Accented text-to-speech (TTS) synthesis seeks to generate speech with an accent (L2) as a variant of the standard version (L1). How to control the intensity of accent in the process of TTS is a very interesting research direction, and has attracted more and more attention. Recent work design a speaker-adversarial loss to disentangle the speaker and accent information, and then adjust the loss weight to control the accent intensity. However, such a control method lacks interpretability, and there is no direct correlation between the controlling factor and natural accent intensity. To this end, this paper propose a new intuitive and explicit accent intensity control scheme for accented TTS. Specifically, we first extract the posterior probability, called as ``goodness of pronunciation (GoP)'' from the L1 speech recognition model to quantify the phoneme accent intensity for accented speech, then design a FastSpeech2 based TTS model, named Ai-TTS, to take the accent intensity expression into account during speech generation. Experiments show that the our method outperforms the baseline model in terms of accent rendering and intensity control.
Deep Learning for Environmentally Robust Speech Recognition: An Overview of Recent Developments
Sep 21, 2018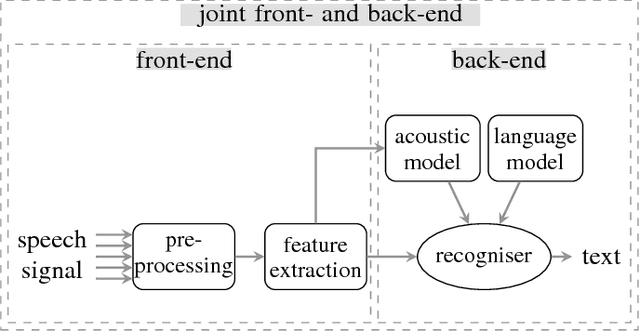

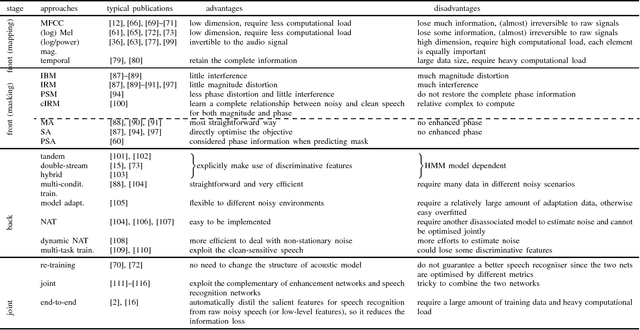

Eliminating the negative effect of non-stationary environmental noise is a long-standing research topic for automatic speech recognition that stills remains an important challenge. Data-driven supervised approaches, including ones based on deep neural networks, have recently emerged as potential alternatives to traditional unsupervised approaches and with sufficient training, can alleviate the shortcomings of the unsupervised methods in various real-life acoustic environments. In this light, we review recently developed, representative deep learning approaches for tackling non-stationary additive and convolutional degradation of speech with the aim of providing guidelines for those involved in the development of environmentally robust speech recognition systems. We separately discuss single- and multi-channel techniques developed for the front-end and back-end of speech recognition systems, as well as joint front-end and back-end training frameworks.
Streaming Models for Joint Speech Recognition and Translation
Jan 22, 2021
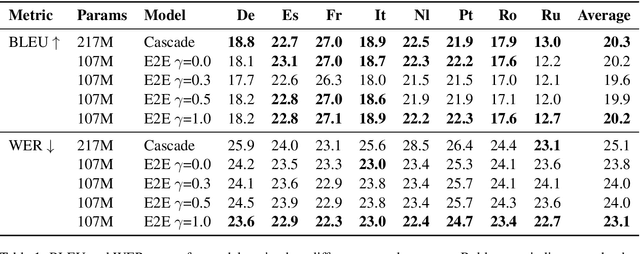
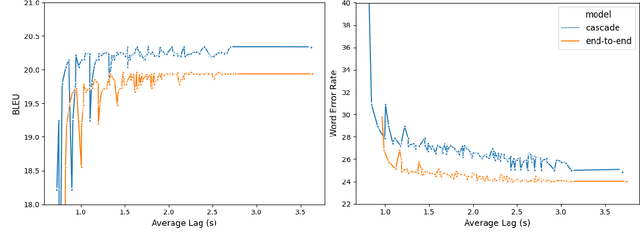
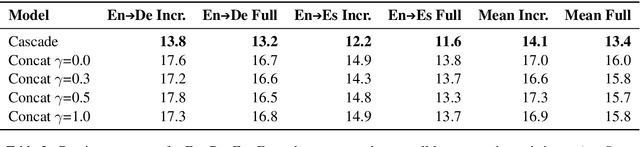
Using end-to-end models for speech translation (ST) has increasingly been the focus of the ST community. These models condense the previously cascaded systems by directly converting sound waves into translated text. However, cascaded models have the advantage of including automatic speech recognition output, useful for a variety of practical ST systems that often display transcripts to the user alongside the translations. To bridge this gap, recent work has shown initial progress into the feasibility for end-to-end models to produce both of these outputs. However, all previous work has only looked at this problem from the consecutive perspective, leaving uncertainty on whether these approaches are effective in the more challenging streaming setting. We develop an end-to-end streaming ST model based on a re-translation approach and compare against standard cascading approaches. We also introduce a novel inference method for the joint case, interleaving both transcript and translation in generation and removing the need to use separate decoders. Our evaluation across a range of metrics capturing accuracy, latency, and consistency shows that our end-to-end models are statistically similar to cascading models, while having half the number of parameters. We also find that both systems provide strong translation quality at low latency, keeping 99% of consecutive quality at a lag of just under a second.
Whose Emotion Matters? Speaker Detection without Prior Knowledge
Nov 23, 2022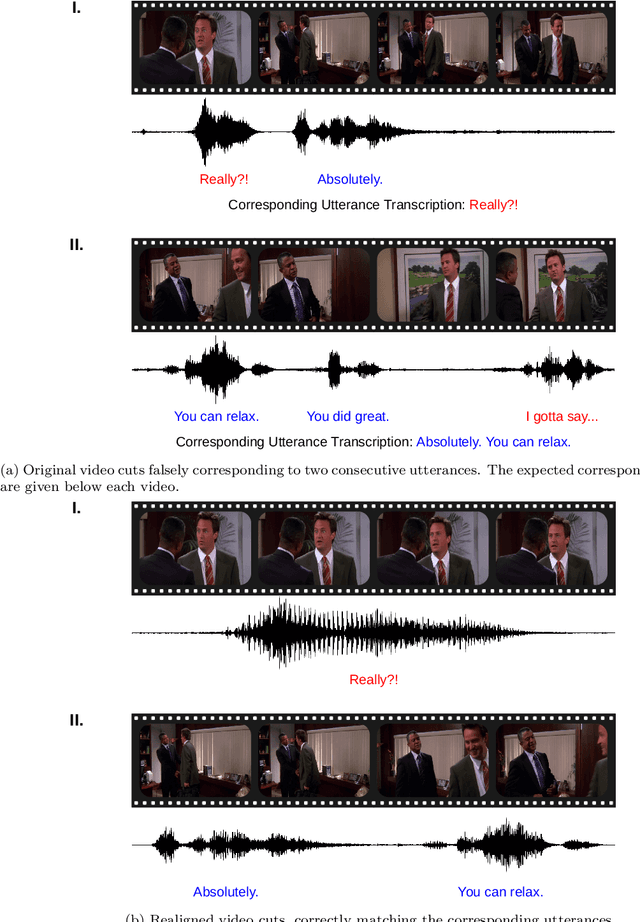

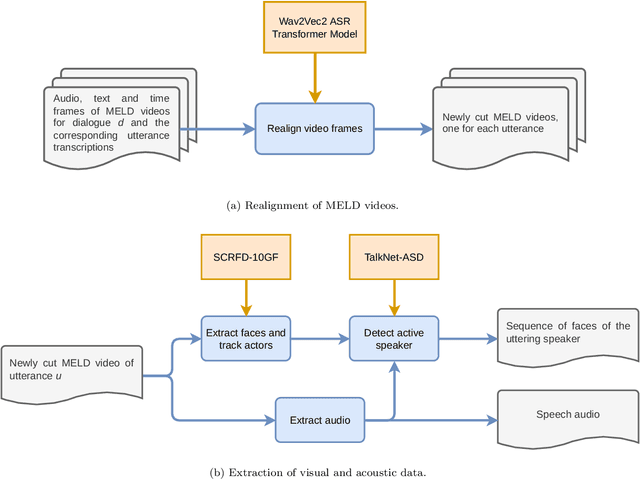
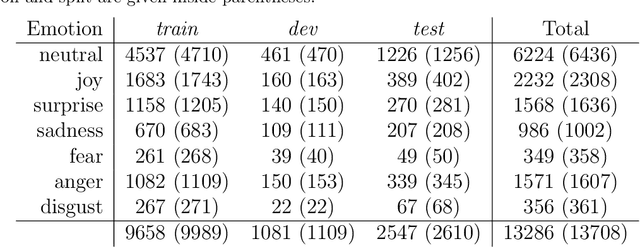
The task of emotion recognition in conversations (ERC) benefits from the availability of multiple modalities, as offered, for example, in the video-based MELD dataset. However, only a few research approaches use both acoustic and visual information from the MELD videos. There are two reasons for this: First, label-to-video alignments in MELD are noisy, making those videos an unreliable source of emotional speech data. Second, conversations can involve several people in the same scene, which requires the detection of the person speaking the utterance. In this paper we demonstrate that by using recent automatic speech recognition and active speaker detection models, we are able to realign the videos of MELD, and capture the facial expressions from uttering speakers in 96.92% of the utterances provided in MELD. Experiments with a self-supervised voice recognition model indicate that the realigned MELD videos more closely match the corresponding utterances offered in the dataset. Finally, we devise a model for emotion recognition in conversations trained on the face and audio information of the MELD realigned videos, which outperforms state-of-the-art models for ERC based on vision alone. This indicates that active speaker detection is indeed effective for extracting facial expressions from the uttering speakers, and that faces provide more informative visual cues than the visual features state-of-the-art models have been using so far.
TSNAT: Two-Step Non-Autoregressvie Transformer Models for Speech Recognition
Apr 04, 2021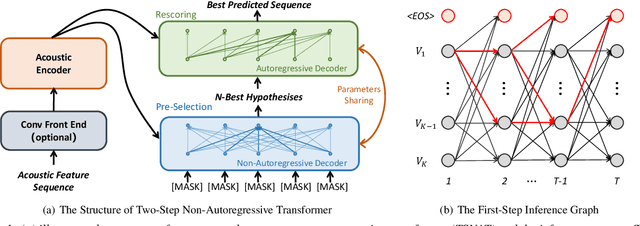
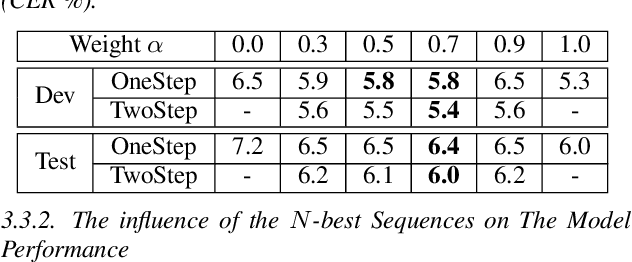
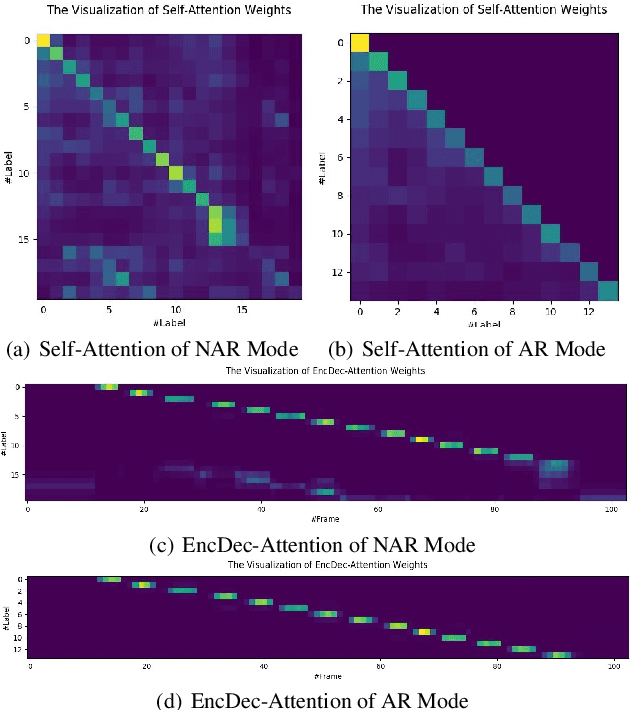
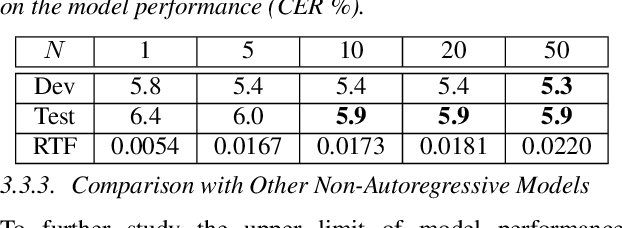
The autoregressive (AR) models, such as attention-based encoder-decoder models and RNN-Transducer, have achieved great success in speech recognition. They predict the output sequence conditioned on the previous tokens and acoustic encoded states, which is inefficient on GPUs. The non-autoregressive (NAR) models can get rid of the temporal dependency between the output tokens and predict the entire output tokens in at least one step. However, the NAR model still faces two major problems. On the one hand, there is still a great gap in performance between the NAR models and the advanced AR models. On the other hand, it's difficult for most of the NAR models to train and converge. To address these two problems, we propose a new model named the two-step non-autoregressive transformer(TSNAT), which improves the performance and accelerating the convergence of the NAR model by learning prior knowledge from a parameters-sharing AR model. Furthermore, we introduce the two-stage method into the inference process, which improves the model performance greatly. All the experiments are conducted on a public Chinese mandarin dataset ASIEHLL-1. The results show that the TSNAT can achieve a competitive performance with the AR model and outperform many complicated NAR models.
Provable Robustness for Streaming Models with a Sliding Window
Mar 28, 2023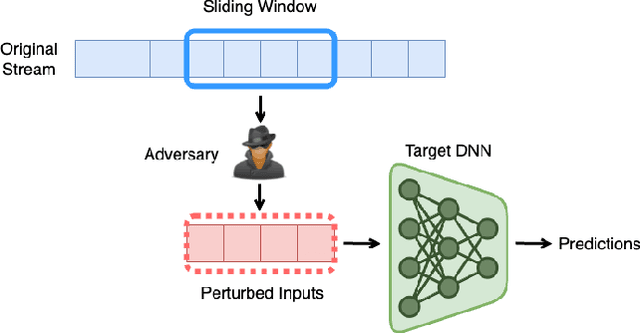
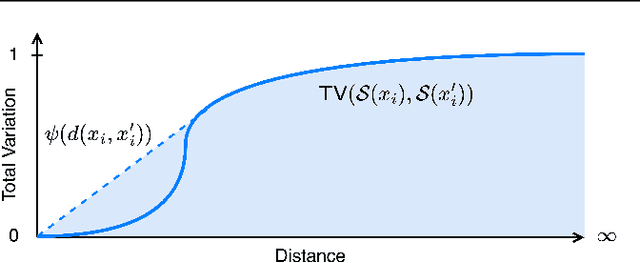

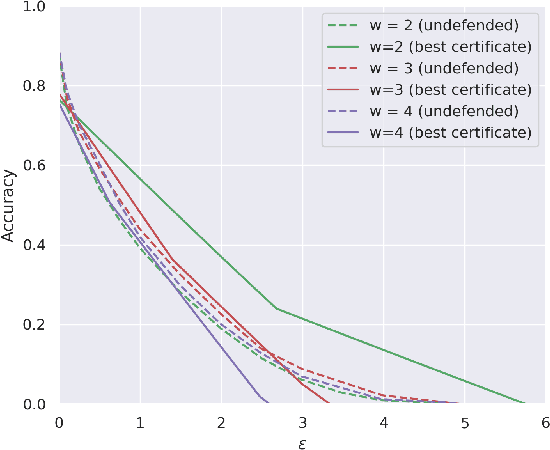
The literature on provable robustness in machine learning has primarily focused on static prediction problems, such as image classification, in which input samples are assumed to be independent and model performance is measured as an expectation over the input distribution. Robustness certificates are derived for individual input instances with the assumption that the model is evaluated on each instance separately. However, in many deep learning applications such as online content recommendation and stock market analysis, models use historical data to make predictions. Robustness certificates based on the assumption of independent input samples are not directly applicable in such scenarios. In this work, we focus on the provable robustness of machine learning models in the context of data streams, where inputs are presented as a sequence of potentially correlated items. We derive robustness certificates for models that use a fixed-size sliding window over the input stream. Our guarantees hold for the average model performance across the entire stream and are independent of stream size, making them suitable for large data streams. We perform experiments on speech detection and human activity recognition tasks and show that our certificates can produce meaningful performance guarantees against adversarial perturbations.
Towards A Unified Conformer Structure: from ASR to ASV Task
Nov 14, 2022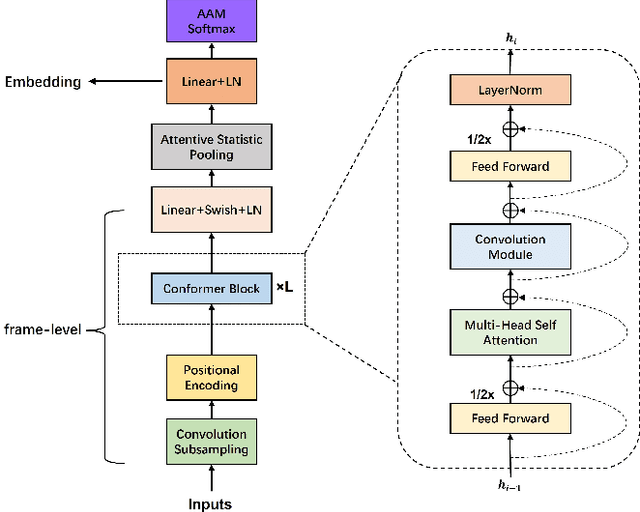
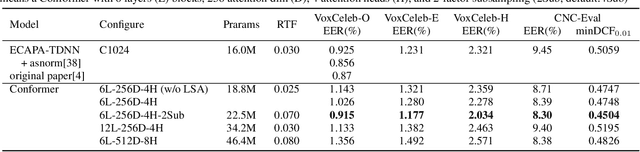
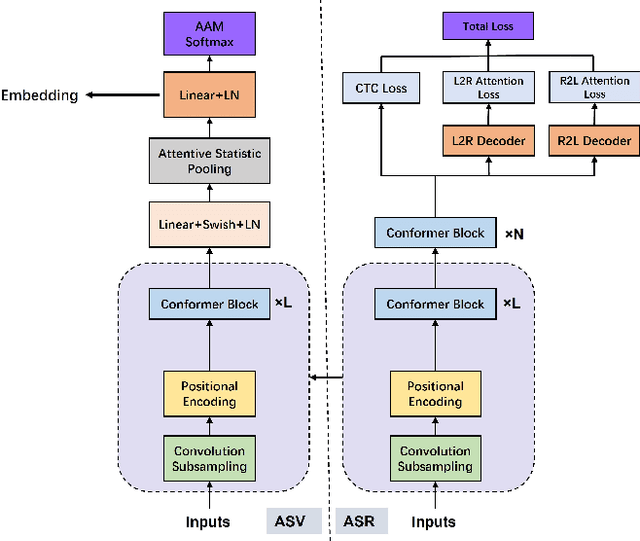
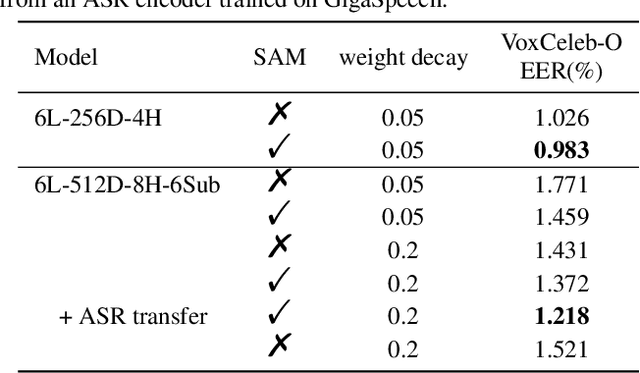
Transformer has achieved extraordinary performance in Natural Language Processing and Computer Vision tasks thanks to its powerful self-attention mechanism, and its variant Conformer has become a state-of-the-art architecture in the field of Automatic Speech Recognition (ASR). However, the main-stream architecture for Automatic Speaker Verification (ASV) is convolutional Neural Networks, and there is still much room for research on the Conformer based ASV. In this paper, firstly, we modify the Conformer architecture from ASR to ASV with very minor changes. Length-Scaled Attention (LSA) method and Sharpness-Aware Minimizationis (SAM) are adopted to improve model generalization. Experiments conducted on VoxCeleb and CN-Celeb show that our Conformer based ASV achieves competitive performance compared with the popular ECAPA-TDNN. Secondly, inspired by the transfer learning strategy, ASV Conformer is natural to be initialized from the pretrained ASR model. Via parameter transferring, self-attention mechanism could better focus on the relationship between sequence features, brings about 11% relative improvement in EER on test set of VoxCeleb and CN-Celeb, which reveals the potential of Conformer to unify ASV and ASR task. Finally, we provide a runtime in ASV-Subtools to evaluate its inference speed in production scenario. Our code is released at https://github.com/Snowdar/asv-subtools/tree/master/doc/papers/conformer.md.
Wav2Seq: Pre-training Speech-to-Text Encoder-Decoder Models Using Pseudo Languages
May 02, 2022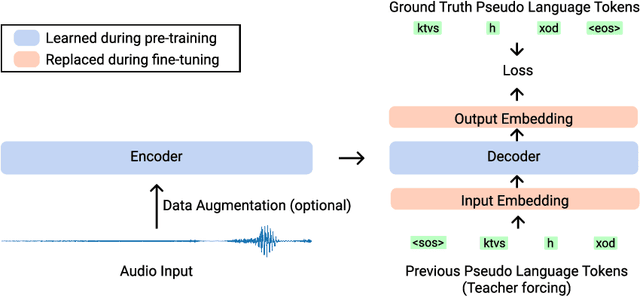

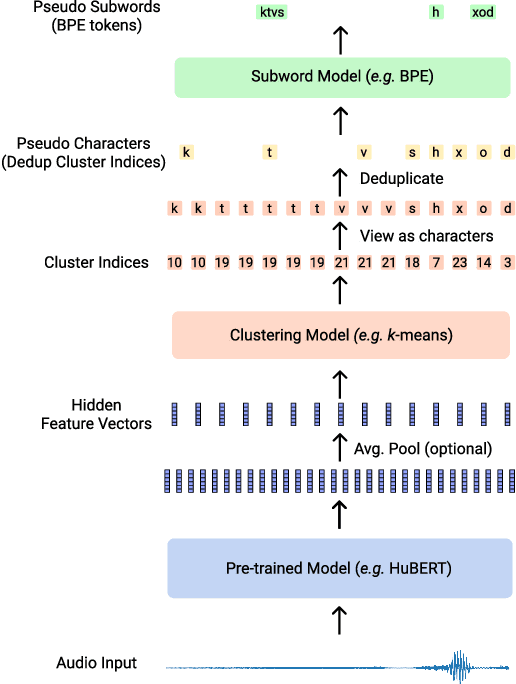
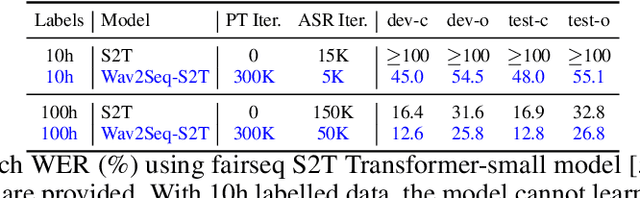
We introduce Wav2Seq, the first self-supervised approach to pre-train both parts of encoder-decoder models for speech data. We induce a pseudo language as a compact discrete representation, and formulate a self-supervised pseudo speech recognition task -- transcribing audio inputs into pseudo subword sequences. This process stands on its own, or can be applied as low-cost second-stage pre-training. We experiment with automatic speech recognition (ASR), spoken named entity recognition, and speech-to-text translation. We set new state-of-the-art results for end-to-end spoken named entity recognition, and show consistent improvements on 20 language pairs for speech-to-text translation, even when competing methods use additional text data for training. Finally, on ASR, our approach enables encoder-decoder methods to benefit from pre-training for all parts of the network, and shows comparable performance to highly optimized recent methods.
SpeechEQ: Speech Emotion Recognition based on Multi-scale Unified Datasets and Multitask Learning
Jun 27, 2022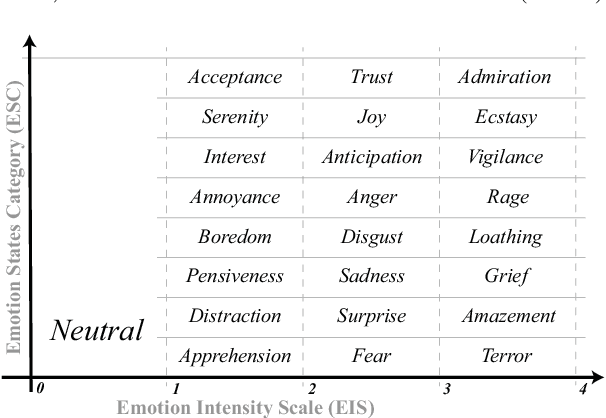

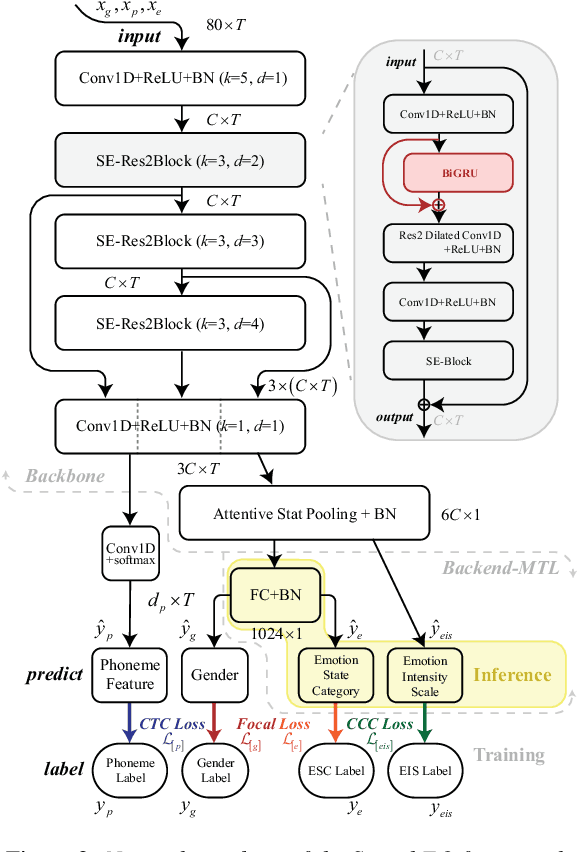
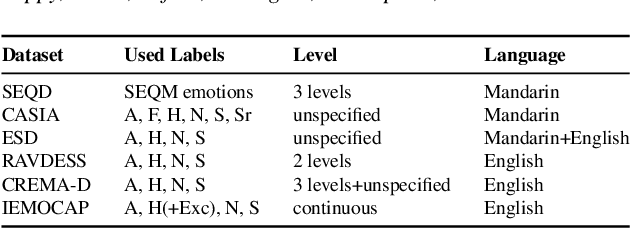
Speech emotion recognition (SER) has many challenges, but one of the main challenges is that each framework does not have a unified standard. In this paper, we propose SpeechEQ, a framework for unifying SER tasks based on a multi-scale unified metric. This metric can be trained by Multitask Learning (MTL), which includes two emotion recognition tasks of Emotion States Category (EIS) and Emotion Intensity Scale (EIS), and two auxiliary tasks of phoneme recognition and gender recognition. For this framework, we build a Mandarin SER dataset - SpeechEQ Dataset (SEQD). We conducted experiments on the public CASIA and ESD datasets in Mandarin, which exhibit that our method outperforms baseline methods by a relatively large margin, yielding 8.0\% and 6.5\% improvement in accuracy respectively. Additional experiments on IEMOCAP with four emotion categories (i.e., angry, happy, sad, and neutral) also show the proposed method achieves a state-of-the-art of both weighted accuracy (WA) of 78.16% and unweighted accuracy (UA) of 77.47%.
Transformer-based Online CTC/attention End-to-End Speech Recognition Architecture
Feb 11, 2020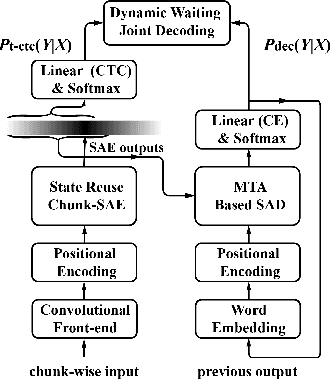

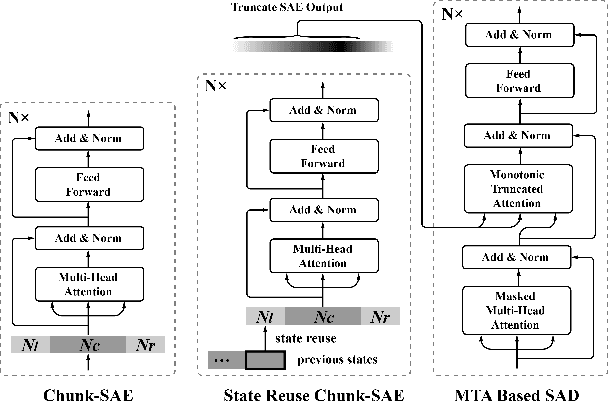
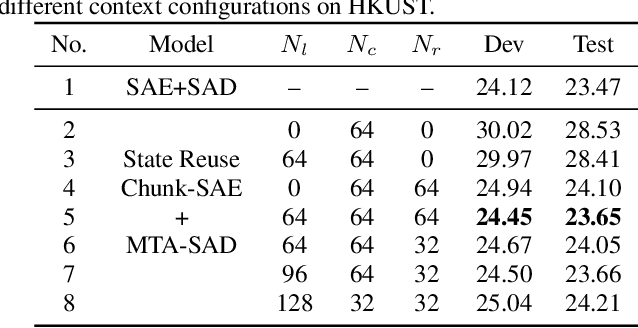
Recently, Transformer has gained success in automatic speech recognition (ASR) field. However, it is challenging to deploy a Transformer-based end-to-end (E2E) model for online speech recognition. In this paper, we propose the Transformer-based online CTC/attention E2E ASR architecture, which contains the chunk self-attention encoder (chunk-SAE) and the monotonic truncated attention (MTA) based self-attention decoder (SAD). Firstly, the chunk-SAE splits the speech into isolated chunks. To reduce the computational cost and improve the performance, we propose the state reuse chunk-SAE. Sencondly, the MTA based SAD truncates the speech features monotonically and performs attention on the truncated features. To support the online recognition, we integrate the state reuse chunk-SAE and the MTA based SAD into online CTC/attention architecture. We evaluate the proposed online models on the HKUST Mandarin ASR benchmark and achieve a 23.66% character error rate (CER) with a 320 ms latency. Our online model yields as little as 0.19% absolute CER degradation compared with the offline baseline, and achieves significant improvement over our prior work on Long Short-Term Memory (LSTM) based online E2E models.