 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Paraphrasing: A Universal Attack for Humanizing AI-Generated Text
Jun 08, 2025



The increasing capabilities of Large Language Models (LLMs) have raised concerns about their misuse in AI-generated plagiarism and social engineering. While various AI-generated text detectors have been proposed to mitigate these risks, many remain vulnerable to simple evasion techniques such as paraphrasing. However, recent detectors have shown greater robustness against such basic attacks. In this work, we introduce Adversarial Paraphrasing, a training-free attack framework that universally humanizes any AI-generated text to evade detection more effectively. Our approach leverages an off-the-shelf instruction-following LLM to paraphrase AI-generated content under the guidance of an AI text detector, producing adversarial examples that are specifically optimized to bypass detection. Extensive experiments show that our attack is both broadly effective and highly transferable across several detection systems. For instance, compared to simple paraphrasing attack--which, ironically, increases the true positive at 1% false positive (T@1%F) by 8.57% on RADAR and 15.03% on Fast-DetectGPT--adversarial paraphrasing, guided by OpenAI-RoBERTa-Large, reduces T@1%F by 64.49% on RADAR and a striking 98.96% on Fast-DetectGPT. Across a diverse set of detectors--including neural network-based, watermark-based, and zero-shot approaches--our attack achieves an average T@1%F reduction of 87.88% under the guidance of OpenAI-RoBERTa-Large. We also analyze the tradeoff between text quality and attack success to find that our method can significantly reduce detection rates, with mostly a slight degradation in text quality. Our adversarial setup highlights the need for more robust and resilient detection strategies in the light of increasingly sophisticated evasion techniques.
DREW : Towards Robust Data Provenance by Leveraging Error-Controlled Watermarking
Jun 05, 2024



Identifying the origin of data is crucial for data provenance, with applications including data ownership protection, media forensics, and detecting AI-generated content. A standard approach involves embedding-based retrieval techniques that match query data with entries in a reference dataset. However, this method is not robust against benign and malicious edits. To address this, we propose Data Retrieval with Error-corrected codes and Watermarking (DREW). DREW randomly clusters the reference dataset, injects unique error-controlled watermark keys into each cluster, and uses these keys at query time to identify the appropriate cluster for a given sample. After locating the relevant cluster, embedding vector similarity retrieval is performed within the cluster to find the most accurate matches. The integration of error control codes (ECC) ensures reliable cluster assignments, enabling the method to perform retrieval on the entire dataset in case the ECC algorithm cannot detect the correct cluster with high confidence. This makes DREW maintain baseline performance, while also providing opportunities for performance improvements due to the increased likelihood of correctly matching queries to their origin when performing retrieval on a smaller subset of the dataset. Depending on the watermark technique used, DREW can provide substantial improvements in retrieval accuracy (up to 40\% for some datasets and modification types) across multiple datasets and state-of-the-art embedding models (e.g., DinoV2, CLIP), making our method a promising solution for secure and reliable source identification. The code is available at https://github.com/mehrdadsaberi/DREW
Fast Adversarial Attacks on Language Models In One GPU Minute
Feb 23, 2024



In this paper, we introduce a novel class of fast, beam search-based adversarial attack (BEAST) for Language Models (LMs). BEAST employs interpretable parameters, enabling attackers to balance between attack speed, success rate, and the readability of adversarial prompts. The computational efficiency of BEAST facilitates us to investigate its applications on LMs for jailbreaking, eliciting hallucinations, and privacy attacks. Our gradient-free targeted attack can jailbreak aligned LMs with high attack success rates within one minute. For instance, BEAST can jailbreak Vicuna-7B-v1.5 under one minute with a success rate of 89% when compared to a gradient-based baseline that takes over an hour to achieve 70% success rate using a single Nvidia RTX A6000 48GB GPU. Additionally, we discover a unique outcome wherein our untargeted attack induces hallucinations in LM chatbots. Through human evaluations, we find that our untargeted attack causes Vicuna-7B-v1.5 to produce ~15% more incorrect outputs when compared to LM outputs in the absence of our attack. We also learn that 22% of the time, BEAST causes Vicuna to generate outputs that are not relevant to the original prompt. Further, we use BEAST to generate adversarial prompts in a few seconds that can boost the performance of existing membership inference attacks for LMs. We believe that our fast attack, BEAST, has the potential to accelerate research in LM security and privacy. Our codebase is publicly available at https://github.com/vinusankars/BEAST.
Exploring Geometry of Blind Spots in Vision Models
Oct 30, 2023



Despite the remarkable success of deep neural networks in a myriad of settings, several works have demonstrated their overwhelming sensitivity to near-imperceptible perturbations, known as adversarial attacks. On the other hand, prior works have also observed that deep networks can be under-sensitive, wherein large-magnitude perturbations in input space do not induce appreciable changes to network activations. In this work, we study in detail the phenomenon of under-sensitivity in vision models such as CNNs and Transformers, and present techniques to study the geometry and extent of "equi-confidence" level sets of such networks. We propose a Level Set Traversal algorithm that iteratively explores regions of high confidence with respect to the input space using orthogonal components of the local gradients. Given a source image, we use this algorithm to identify inputs that lie in the same equi-confidence level set as the source image despite being perceptually similar to arbitrary images from other classes. We further observe that the source image is linearly connected by a high-confidence path to these inputs, uncovering a star-like structure for level sets of deep networks. Furthermore, we attempt to identify and estimate the extent of these connected higher-dimensional regions over which the model maintains a high degree of confidence. The code for this project is publicly available at https://github.com/SriramB-98/blindspots-neurips-sub
Robustness of AI-Image Detectors: Fundamental Limits and Practical Attacks
Sep 29, 2023In light of recent advancements in generative AI models, it has become essential to distinguish genuine content from AI-generated one to prevent the malicious usage of fake materials as authentic ones and vice versa. Various techniques have been introduced for identifying AI-generated images, with watermarking emerging as a promising approach. In this paper, we analyze the robustness of various AI-image detectors including watermarking and classifier-based deepfake detectors. For watermarking methods that introduce subtle image perturbations (i.e., low perturbation budget methods), we reveal a fundamental trade-off between the evasion error rate (i.e., the fraction of watermarked images detected as non-watermarked ones) and the spoofing error rate (i.e., the fraction of non-watermarked images detected as watermarked ones) upon an application of a diffusion purification attack. In this regime, we also empirically show that diffusion purification effectively removes watermarks with minimal changes to images. For high perturbation watermarking methods where notable changes are applied to images, the diffusion purification attack is not effective. In this case, we develop a model substitution adversarial attack that can successfully remove watermarks. Moreover, we show that watermarking methods are vulnerable to spoofing attacks where the attacker aims to have real images (potentially obscene) identified as watermarked ones, damaging the reputation of the developers. In particular, by just having black-box access to the watermarking method, we show that one can generate a watermarked noise image which can be added to the real images to have them falsely flagged as watermarked ones. Finally, we extend our theory to characterize a fundamental trade-off between the robustness and reliability of classifier-based deep fake detectors and demonstrate it through experiments.
Provable Robustness for Streaming Models with a Sliding Window
Mar 28, 2023



The literature on provable robustness in machine learning has primarily focused on static prediction problems, such as image classification, in which input samples are assumed to be independent and model performance is measured as an expectation over the input distribution. Robustness certificates are derived for individual input instances with the assumption that the model is evaluated on each instance separately. However, in many deep learning applications such as online content recommendation and stock market analysis, models use historical data to make predictions. Robustness certificates based on the assumption of independent input samples are not directly applicable in such scenarios. In this work, we focus on the provable robustness of machine learning models in the context of data streams, where inputs are presented as a sequence of potentially correlated items. We derive robustness certificates for models that use a fixed-size sliding window over the input stream. Our guarantees hold for the average model performance across the entire stream and are independent of stream size, making them suitable for large data streams. We perform experiments on speech detection and human activity recognition tasks and show that our certificates can produce meaningful performance guarantees against adversarial perturbations.
Can AI-Generated Text be Reliably Detected?
Mar 17, 2023



The rapid progress of Large Language Models (LLMs) has made them capable of performing astonishingly well on various tasks including document completion and question answering. The unregulated use of these models, however, can potentially lead to malicious consequences such as plagiarism, generating fake news, spamming, etc. Therefore, reliable detection of AI-generated text can be critical to ensure the responsible use of LLMs. Recent works attempt to tackle this problem either using certain model signatures present in the generated text outputs or by applying watermarking techniques that imprint specific patterns onto them. In this paper, both empirically and theoretically, we show that these detectors are not reliable in practical scenarios. Empirically, we show that paraphrasing attacks, where a light paraphraser is applied on top of the generative text model, can break a whole range of detectors, including the ones using the watermarking schemes as well as neural network-based detectors and zero-shot classifiers. We then provide a theoretical impossibility result indicating that for a sufficiently good language model, even the best-possible detector can only perform marginally better than a random classifier. Finally, we show that even LLMs protected by watermarking schemes can be vulnerable against spoofing attacks where adversarial humans can infer hidden watermarking signatures and add them to their generated text to be detected as text generated by the LLMs, potentially causing reputational damages to their developers. We believe these results can open an honest conversation in the community regarding the ethical and reliable use of AI-generated text.
CUDA: Convolution-based Unlearnable Datasets
Mar 07, 2023
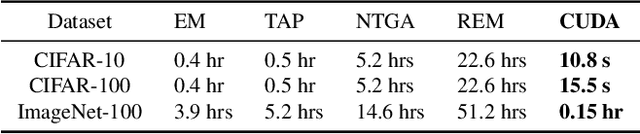
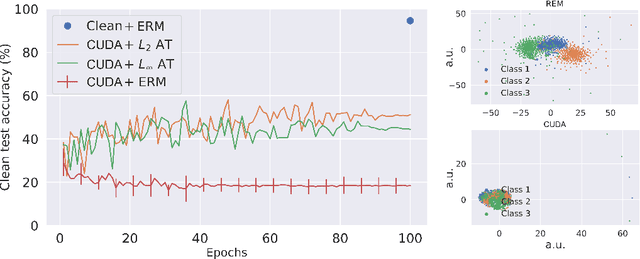
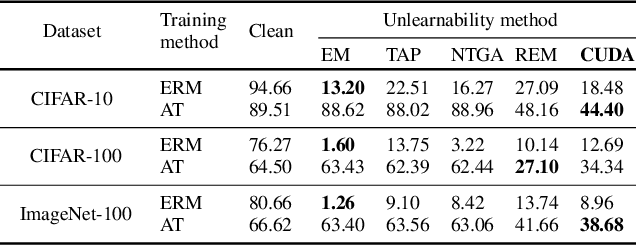
Large-scale training of modern deep learning models heavily relies on publicly available data on the web. This potentially unauthorized usage of online data leads to concerns regarding data privacy. Recent works aim to make unlearnable data for deep learning models by adding small, specially designed noises to tackle this issue. However, these methods are vulnerable to adversarial training (AT) and/or are computationally heavy. In this work, we propose a novel, model-free, Convolution-based Unlearnable DAtaset (CUDA) generation technique. CUDA is generated using controlled class-wise convolutions with filters that are randomly generated via a private key. CUDA encourages the network to learn the relation between filters and labels rather than informative features for classifying the clean data. We develop some theoretical analysis demonstrating that CUDA can successfully poison Gaussian mixture data by reducing the clean data performance of the optimal Bayes classifier. We also empirically demonstrate the effectiveness of CUDA with various datasets (CIFAR-10, CIFAR-100, ImageNet-100, and Tiny-ImageNet), and architectures (ResNet-18, VGG-16, Wide ResNet-34-10, DenseNet-121, DeIT, EfficientNetV2-S, and MobileNetV2). Our experiments show that CUDA is robust to various data augmentations and training approaches such as smoothing, AT with different budgets, transfer learning, and fine-tuning. For instance, training a ResNet-18 on ImageNet-100 CUDA achieves only 8.96$\%$, 40.08$\%$, and 20.58$\%$ clean test accuracies with empirical risk minimization (ERM), $L_{\infty}$ AT, and $L_{2}$ AT, respectively. Here, ERM on the clean training data achieves a clean test accuracy of 80.66$\%$. CUDA exhibits unlearnability effect with ERM even when only a fraction of the training dataset is perturbed. Furthermore, we also show that CUDA is robust to adaptive defenses designed specifically to break it.
Statistical Measures For Defining Curriculum Scoring Function
Feb 27, 2021
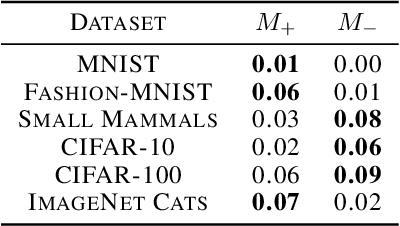

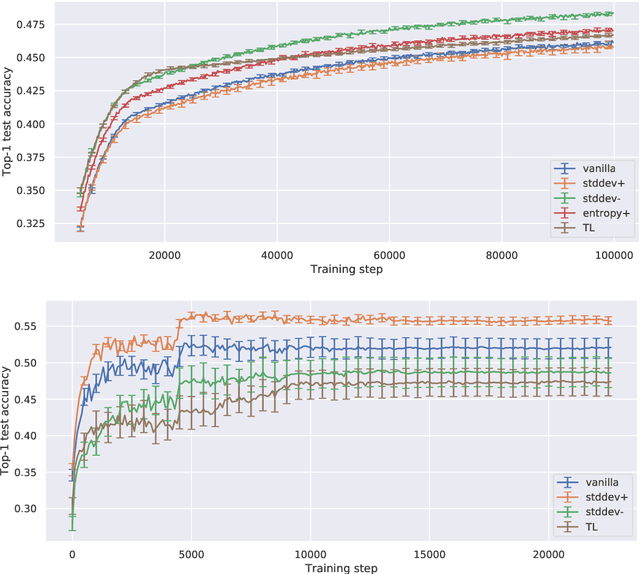
Curriculum learning is a training strategy that sorts the training examples by some measure of their difficulty and gradually exposes them to the learner to improve the network performance. In this work, we propose two novel curriculum learning algorithms, and empirically show their improvements in performance with convolutional and fully-connected neural networks on multiple real image datasets. Motivated by our insights from implicit curriculum ordering, we introduce a simple curriculum learning strategy that uses statistical measures such as standard deviation and entropy values to score the difficulty of data points for real image classification tasks. We also propose and study the performance of a dynamic curriculum learning algorithm. Our dynamic curriculum algorithm tries to reduce the distance between the network weight and an optimal weight at any training step by greedily sampling examples with gradients that are directed towards the optimal weight. Further, we also use our algorithms to discuss why curriculum learning is helpful.