 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
CopyNE: Better Contextual ASR by Copying Named Entities
May 22, 2023
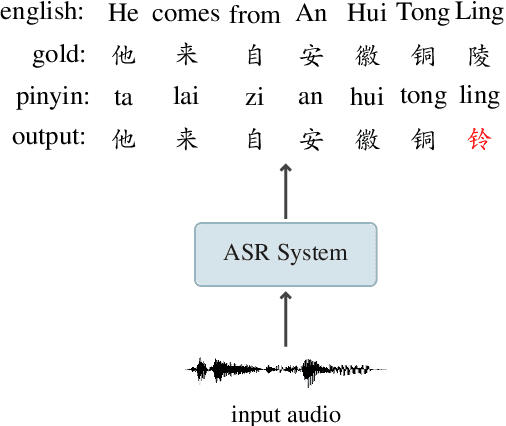
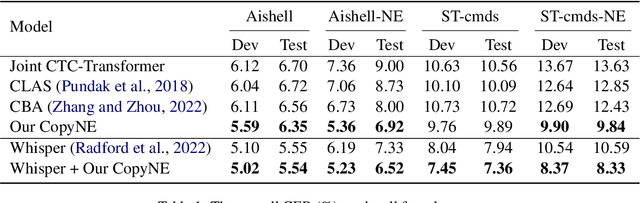
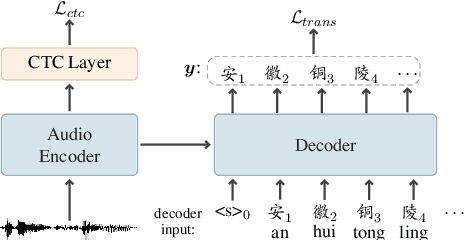
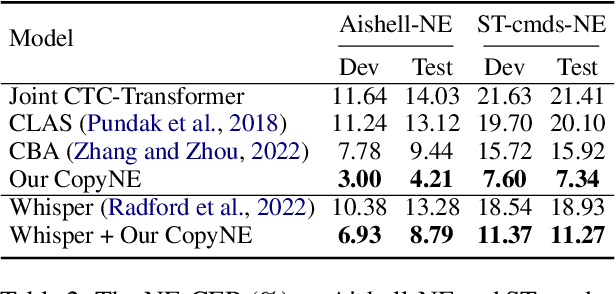
Recent years have seen remarkable progress in automatic speech recognition (ASR). However, traditional token-level ASR models have struggled with accurately transcribing entities due to the problem of homophonic and near-homophonic tokens. This paper introduces a novel approach called CopyNE, which uses a span-level copying mechanism to improve ASR in transcribing entities. CopyNE can copy all tokens of an entity at once, effectively avoiding errors caused by homophonic or near-homophonic tokens that occur when predicting multiple tokens separately. Experiments on Aishell and ST-cmds datasets demonstrate that CopyNE achieves significant reductions in character error rate (CER) and named entity CER (NE-CER), especially in entity-rich scenarios. Furthermore, even when compared to the strong Whisper baseline, CopyNE still achieves notable reductions in CER and NE-CER. Qualitative comparisons with previous approaches demonstrate that CopyNE can better handle entities, effectively improving the accuracy of ASR.
Modular Domain Adaptation for Conformer-Based Streaming ASR
May 22, 2023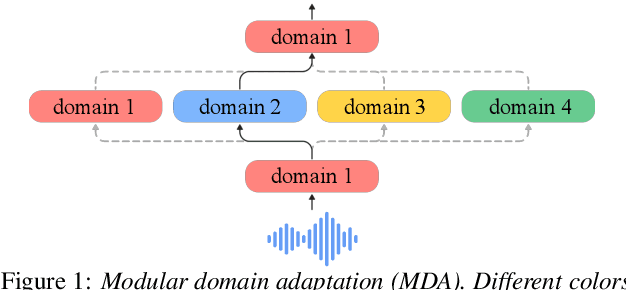
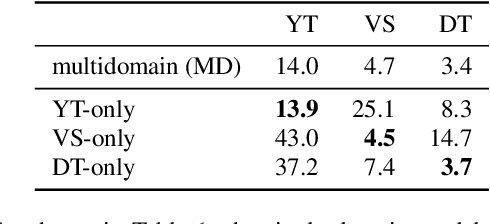
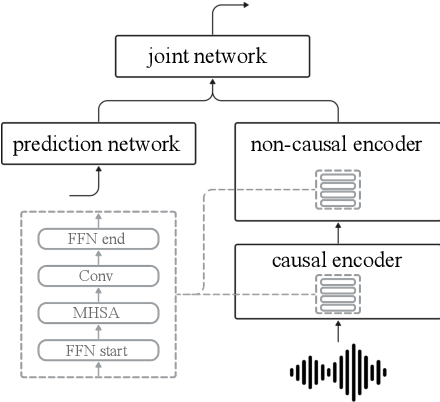
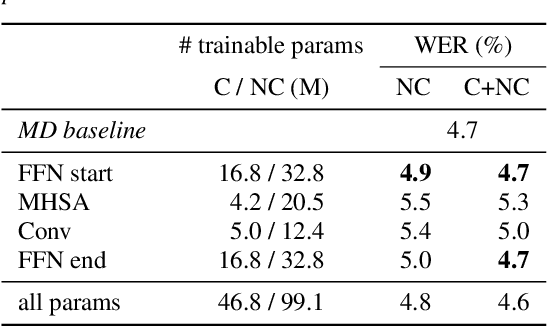
Speech data from different domains has distinct acoustic and linguistic characteristics. It is common to train a single multidomain model such as a Conformer transducer for speech recognition on a mixture of data from all domains. However, changing data in one domain or adding a new domain would require the multidomain model to be retrained. To this end, we propose a framework called modular domain adaptation (MDA) that enables a single model to process multidomain data while keeping all parameters domain-specific, i.e., each parameter is only trained by data from one domain. On a streaming Conformer transducer trained only on video caption data, experimental results show that an MDA-based model can reach similar performance as the multidomain model on other domains such as voice search and dictation by adding per-domain adapters and per-domain feed-forward networks in the Conformer encoder.
Multimodal Audio-textual Architecture for Robust Spoken Language Understanding
Jun 13, 2023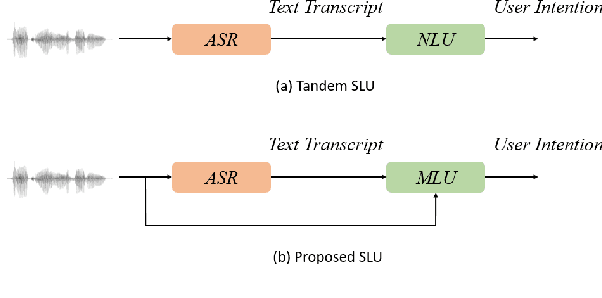
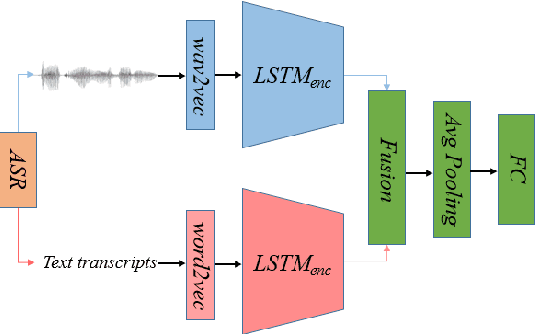
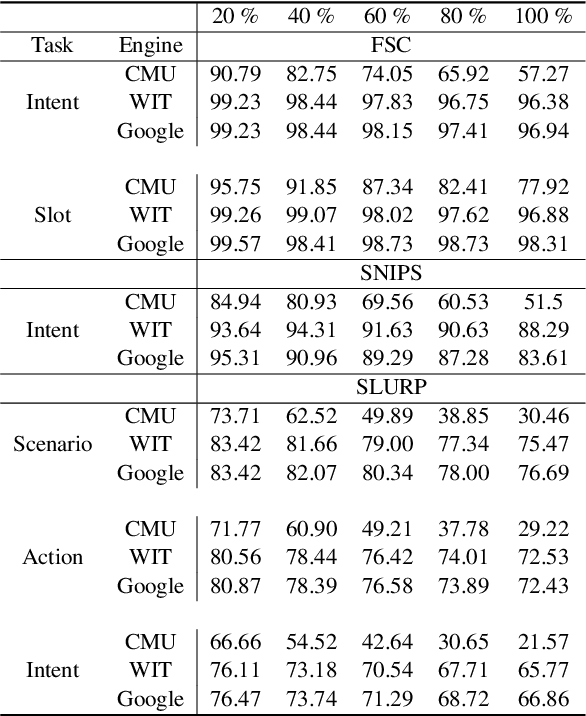
Recent voice assistants are usually based on the cascade spoken language understanding (SLU) solution, which consists of an automatic speech recognition (ASR) engine and a natural language understanding (NLU) system. Because such approach relies on the ASR output, it often suffers from the so-called ASR error propagation. In this work, we investigate impacts of this ASR error propagation on state-of-the-art NLU systems based on pre-trained language models (PLM), such as BERT and RoBERTa. Moreover, a multimodal language understanding (MLU) module is proposed to mitigate SLU performance degradation caused by errors present in the ASR transcript. The MLU benefits from self-supervised features learned from both audio and text modalities, specifically Wav2Vec for speech and Bert/RoBERTa for language. Our MLU combines an encoder network to embed the audio signal and a text encoder to process text transcripts followed by a late fusion layer to fuse audio and text logits. We found that the proposed MLU showed to be robust towards poor quality ASR transcripts, while the performance of BERT and RoBERTa are severely compromised. Our model is evaluated on five tasks from three SLU datasets and robustness is tested using ASR transcripts from three ASR engines. Results show that the proposed approach effectively mitigates the ASR error propagation problem, surpassing the PLM models' performance across all datasets for the academic ASR engine.
Sub-8-bit quantization for on-device speech recognition: a regularization-free approach
Oct 17, 2022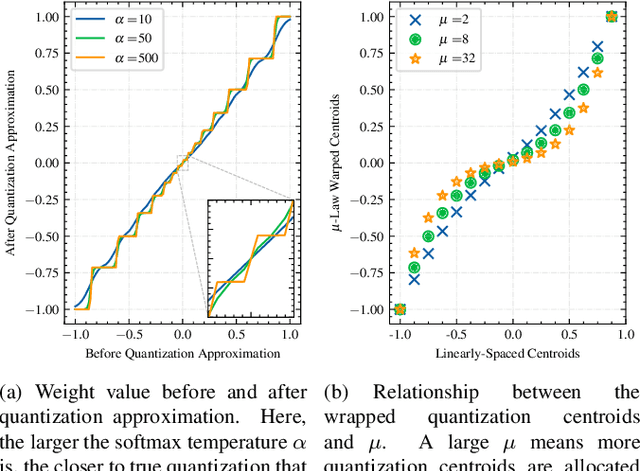
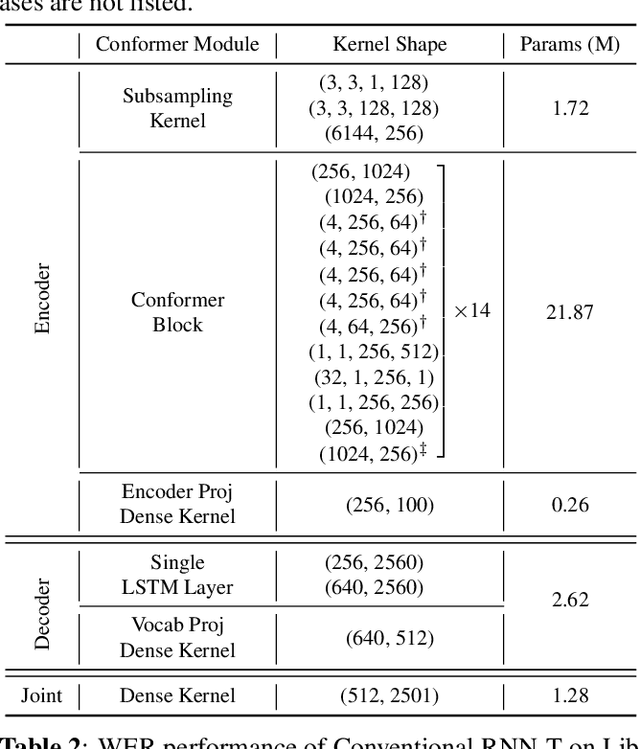

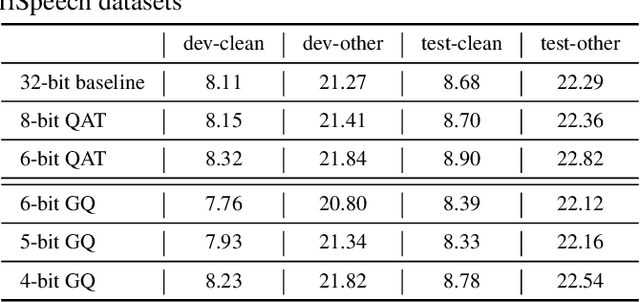
For on-device automatic speech recognition (ASR), quantization aware training (QAT) is ubiquitous to achieve the trade-off between model predictive performance and efficiency. Among existing QAT methods, one major drawback is that the quantization centroids have to be predetermined and fixed. To overcome this limitation, we introduce a regularization-free, "soft-to-hard" compression mechanism with self-adjustable centroids in a mu-Law constrained space, resulting in a simpler yet more versatile quantization scheme, called General Quantizer (GQ). We apply GQ to ASR tasks using Recurrent Neural Network Transducer (RNN-T) and Conformer architectures on both LibriSpeech and de-identified far-field datasets. Without accuracy degradation, GQ can compress both RNN-T and Conformer into sub-8-bit, and for some RNN-T layers, to 1-bit for fast and accurate inference. We observe a 30.73% memory footprint saving and 31.75% user-perceived latency reduction compared to 8-bit QAT via physical device benchmarking.
Deep Speech Based End-to-End Automated Speech Recognition (ASR) for Indian-English Accents
Apr 03, 2022Automated Speech Recognition (ASR) is an interdisciplinary application of computer science and linguistics that enable us to derive the transcription from the uttered speech waveform. It finds several applications in Military like High-performance fighter aircraft, helicopters, air-traffic controller. Other than military speech recognition is used in healthcare, persons with disabilities and many more. ASR has been an active research area. Several models and algorithms for speech to text (STT) have been proposed. One of the most recent is Mozilla Deep Speech, it is based on the Deep Speech research paper by Baidu. Deep Speech is a state-of-art speech recognition system is developed using end-to-end deep learning, it is trained using well-optimized Recurrent Neural Network (RNN) training system utilizing multiple Graphical Processing Units (GPUs). This training is mostly done using American-English accent datasets, which results in poor generalizability to other English accents. India is a land of vast diversity. This can even be seen in the speech, there are several English accents which vary from state to state. In this work, we have used transfer learning approach using most recent Deep Speech model i.e., deepspeech-0.9.3 to develop an end-to-end speech recognition system for Indian-English accents. This work utilizes fine-tuning and data argumentation to further optimize and improve the Deep Speech ASR system. Indic TTS data of Indian-English accents is used for transfer learning and fine-tuning the pre-trained Deep Speech model. A general comparison is made among the untrained model, our trained model and other available speech recognition services for Indian-English Accents.
ILASR: Privacy-Preserving Incremental Learning for Automatic Speech Recognition at Production Scale
Jul 22, 2022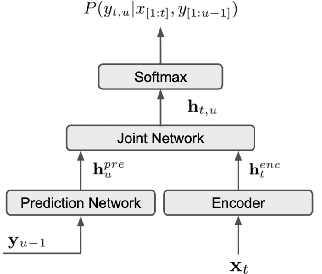
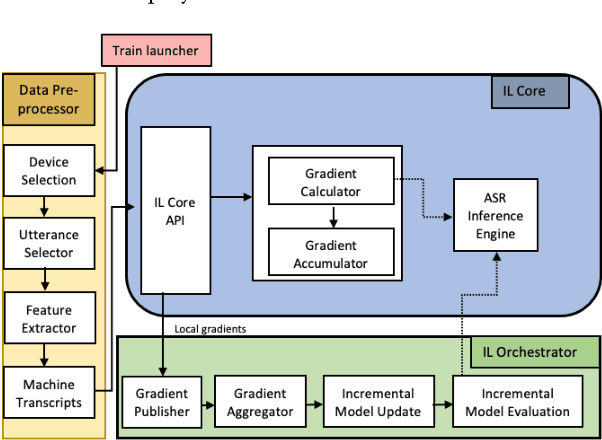
Incremental learning is one paradigm to enable model building and updating at scale with streaming data. For end-to-end automatic speech recognition (ASR) tasks, the absence of human annotated labels along with the need for privacy preserving policies for model building makes it a daunting challenge. Motivated by these challenges, in this paper we use a cloud based framework for production systems to demonstrate insights from privacy preserving incremental learning for automatic speech recognition (ILASR). By privacy preserving, we mean, usage of ephemeral data which are not human annotated. This system is a step forward for production levelASR models for incremental/continual learning that offers near real-time test-bed for experimentation in the cloud for end-to-end ASR, while adhering to privacy-preserving policies. We show that the proposed system can improve the production models significantly(3%) over a new time period of six months even in the absence of human annotated labels with varying levels of weak supervision and large batch sizes in incremental learning. This improvement is 20% over test sets with new words and phrases in the new time period. We demonstrate the effectiveness of model building in a privacy-preserving incremental fashion for ASR while further exploring the utility of having an effective teacher model and use of large batch sizes.
ML-SUPERB: Multilingual Speech Universal PERformance Benchmark
May 18, 2023
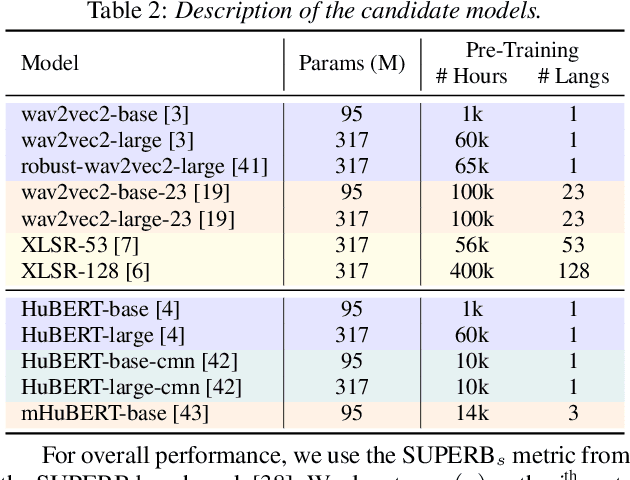
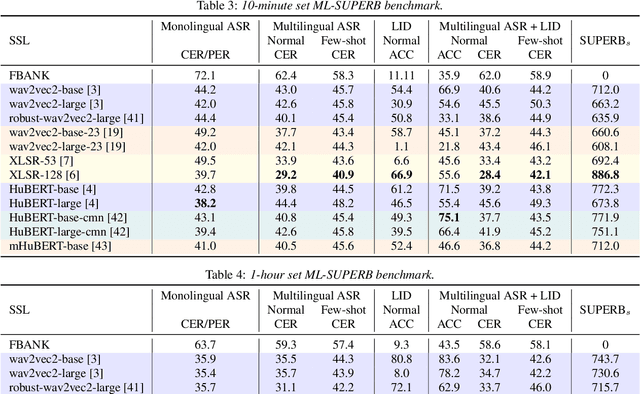
Speech processing Universal PERformance Benchmark (SUPERB) is a leaderboard to benchmark the performance of Self-Supervised Learning (SSL) models on various speech processing tasks. However, SUPERB largely considers English speech in its evaluation. This paper presents multilingual SUPERB (ML-SUPERB), covering 143 languages (ranging from high-resource to endangered), and considering both automatic speech recognition and language identification. Following the concept of SUPERB, ML-SUPERB utilizes frozen SSL features and employs a simple framework for multilingual tasks by learning a shallow downstream model. Similar to the SUPERB benchmark, we find speech SSL models can significantly improve performance compared to FBANK features. Furthermore, we find that multilingual models do not always perform better than their monolingual counterparts. We will release ML-SUPERB as a challenge with organized datasets and reproducible training scripts for future multilingual representation research.
Semantic VAD: Low-Latency Voice Activity Detection for Speech Interaction
May 21, 2023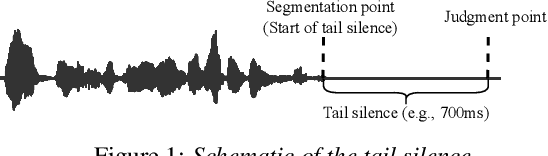
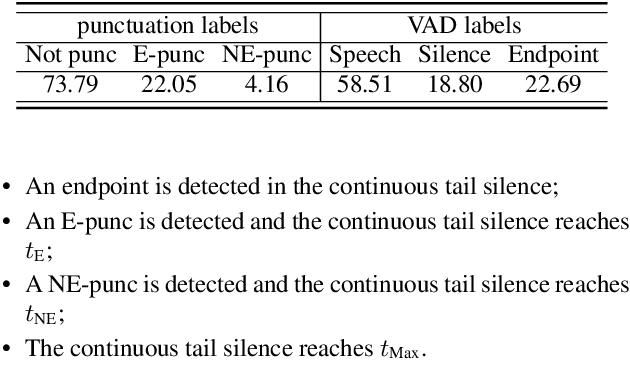
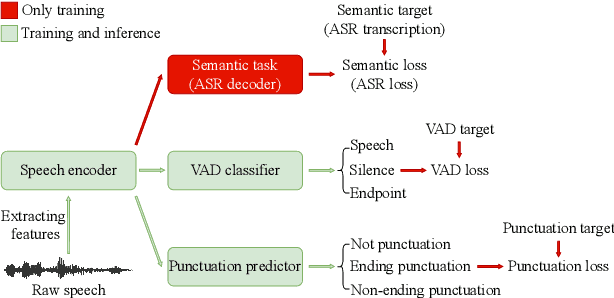
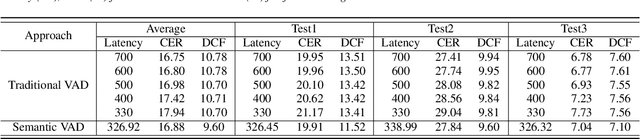
For speech interaction, voice activity detection (VAD) is often used as a front-end. However, traditional VAD algorithms usually need to wait for a continuous tail silence to reach a preset maximum duration before segmentation, resulting in a large latency that affects user experience. In this paper, we propose a novel semantic VAD for low-latency segmentation. Different from existing methods, a frame-level punctuation prediction task is added to the semantic VAD, and the artificial endpoint is included in the classification category in addition to the often-used speech presence and absence. To enhance the semantic information of the model, we also incorporate an automatic speech recognition (ASR) related semantic loss. Evaluations on an internal dataset show that the proposed method can reduce the average latency by 53.3% without significant deterioration of character error rate in the back-end ASR compared to the traditional VAD approach.
Hybrid-SD ($\text{H}_{\text{SD}}$) : A new hybrid evaluation metric for automatic speech recognition tasks
Nov 03, 2022

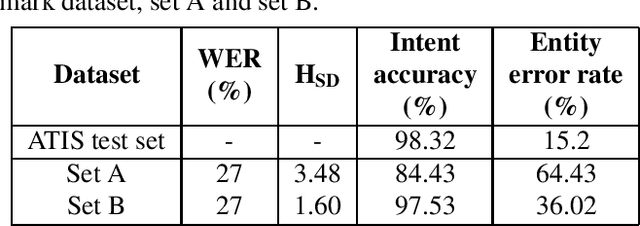

Many studies have examined the shortcomings of word error rate (WER) as an evaluation metric for automatic speech recognition (ASR) systems, particularly when used for spoken language understanding tasks such as intent recognition and dialogue systems. In this paper, we propose Hybrid-SD ($\text{H}_{\text{SD}}$), a new hybrid evaluation metric for ASR systems that takes into account both semantic correctness and error rate. To generate sentence dissimilarity scores (SD), we built a fast and lightweight SNanoBERT model using distillation techniques. Our experiments show that the SNanoBERT model is 25.9x smaller and 38.8x faster than SRoBERTa while achieving comparable results on well-known benchmarks. Hence, making it suitable for deploying with ASR models on edge devices. We also show that $\text{H}_{\text{SD}}$ correlates more strongly with downstream tasks such as intent recognition and named-entity recognition (NER).
Learning Contextually Fused Audio-visual Representations for Audio-visual Speech Recognition
Feb 15, 2022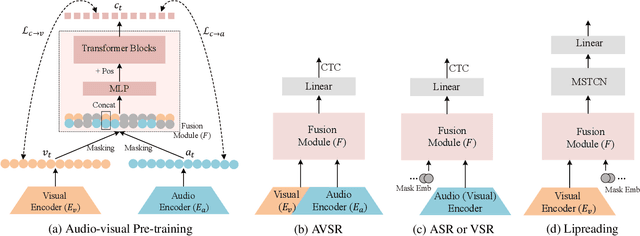
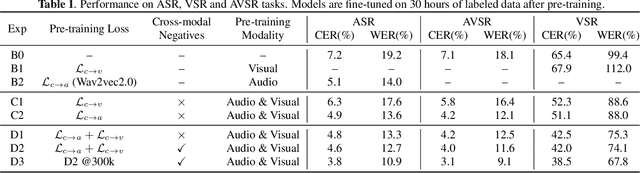
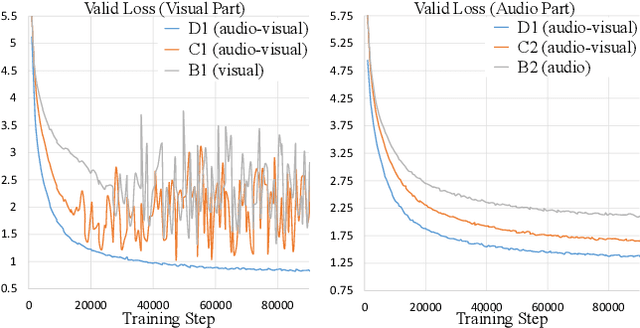
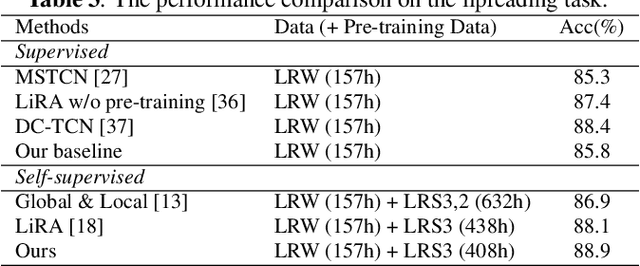
With the advance in self-supervised learning for audio and visual modalities, it has become possible to learn a robust audio-visual speech representation. This would be beneficial for improving the audio-visual speech recognition (AVSR) performance, as the multi-modal inputs contain more fruitful information in principle. In this paper, based on existing self-supervised representation learning methods for audio modality, we therefore propose an audio-visual representation learning approach. The proposed approach explores both the complementarity of audio-visual modalities and long-term context dependency using a transformer-based fusion module and a flexible masking strategy. After pre-training, the model is able to extract fused representations required by AVSR. Without loss of generality, it can be applied to single-modal tasks, e.g. audio/visual speech recognition by simply masking out one modality in the fusion module. The proposed pre-trained model is evaluated on speech recognition and lipreading tasks using one or two modalities, where the superiority is revealed.