 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving fairness for spoken language understanding in atypical speech with Text-to-Speech
Nov 16, 2023



Spoken language understanding (SLU) systems often exhibit suboptimal performance in processing atypical speech, typically caused by neurological conditions and motor impairments. Recent advancements in Text-to-Speech (TTS) synthesis-based augmentation for more fair SLU have struggled to accurately capture the unique vocal characteristics of atypical speakers, largely due to insufficient data. To address this issue, we present a novel data augmentation method for atypical speakers by finetuning a TTS model, called Aty-TTS. Aty-TTS models speaker and atypical characteristics via knowledge transferring from a voice conversion model. Then, we use the augmented data to train SLU models adapted to atypical speech. To train these data augmentation models and evaluate the resulting SLU systems, we have collected a new atypical speech dataset containing intent annotation. Both objective and subjective assessments validate that Aty-TTS is capable of generating high-quality atypical speech. Furthermore, it serves as an effective data augmentation strategy, contributing to more fair SLU systems that can better accommodate individuals with atypical speech patterns.
Federated Representation Learning for Automatic Speech Recognition
Aug 07, 2023



Federated Learning (FL) is a privacy-preserving paradigm, allowing edge devices to learn collaboratively without sharing data. Edge devices like Alexa and Siri are prospective sources of unlabeled audio data that can be tapped to learn robust audio representations. In this work, we bring Self-supervised Learning (SSL) and FL together to learn representations for Automatic Speech Recognition respecting data privacy constraints. We use the speaker and chapter information in the unlabeled speech dataset, Libri-Light, to simulate non-IID speaker-siloed data distributions and pre-train an LSTM encoder with the Contrastive Predictive Coding framework with FedSGD. We show that the pre-trained ASR encoder in FL performs as well as a centrally pre-trained model and produces an improvement of 12-15% (WER) compared to no pre-training. We further adapt the federated pre-trained models to a new language, French, and show a 20% (WER) improvement over no pre-training.
Learning When to Trust Which Teacher for Weakly Supervised ASR
Jun 21, 2023



Automatic speech recognition (ASR) training can utilize multiple experts as teacher models, each trained on a specific domain or accent. Teacher models may be opaque in nature since their architecture may be not be known or their training cadence is different from that of the student ASR model. Still, the student models are updated incrementally using the pseudo-labels generated independently by the expert teachers. In this paper, we exploit supervision from multiple domain experts in training student ASR models. This training strategy is especially useful in scenarios where few or no human transcriptions are available. To that end, we propose a Smart-Weighter mechanism that selects an appropriate expert based on the input audio, and then trains the student model in an unsupervised setting. We show the efficacy of our approach using LibriSpeech and LibriLight benchmarks and find an improvement of 4 to 25\% over baselines that uniformly weight all the experts, use a single expert model, or combine experts using ROVER.
Federated Self-Learning with Weak Supervision for Speech Recognition
Jun 21, 2023



Automatic speech recognition (ASR) models with low-footprint are increasingly being deployed on edge devices for conversational agents, which enhances privacy. We study the problem of federated continual incremental learning for recurrent neural network-transducer (RNN-T) ASR models in the privacy-enhancing scheme of learning on-device, without access to ground truth human transcripts or machine transcriptions from a stronger ASR model. In particular, we study the performance of a self-learning based scheme, with a paired teacher model updated through an exponential moving average of ASR models. Further, we propose using possibly noisy weak-supervision signals such as feedback scores and natural language understanding semantics determined from user behavior across multiple turns in a session of interactions with the conversational agent. These signals are leveraged in a multi-task policy-gradient training approach to improve the performance of self-learning for ASR. Finally, we show how catastrophic forgetting can be mitigated by combining on-device learning with a memory-replay approach using selected historical datasets. These innovations allow for 10% relative improvement in WER on new use cases with minimal degradation on other test sets in the absence of strong-supervision signals such as ground-truth transcriptions.
ILASR: Privacy-Preserving Incremental Learning for Automatic Speech Recognition at Production Scale
Jul 22, 2022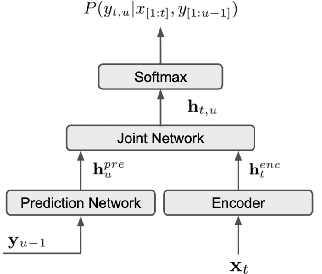
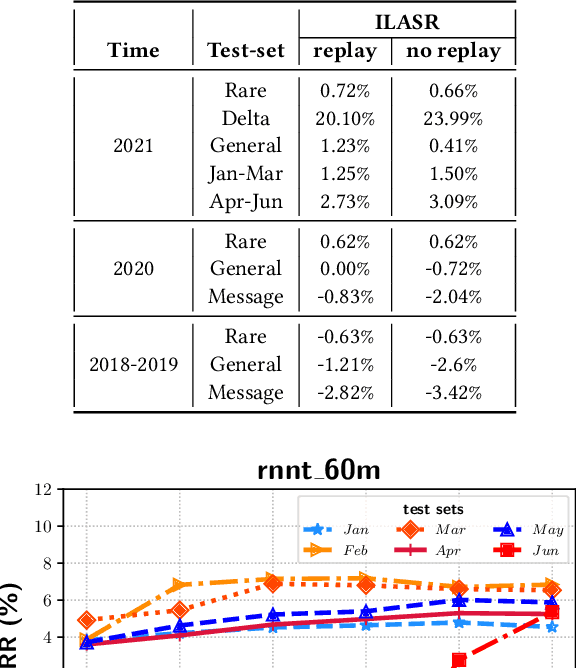
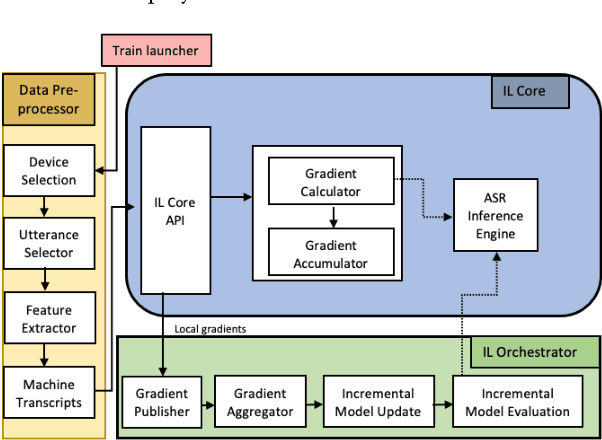
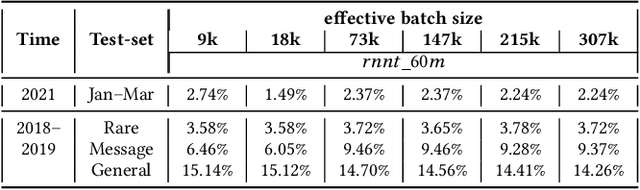
Incremental learning is one paradigm to enable model building and updating at scale with streaming data. For end-to-end automatic speech recognition (ASR) tasks, the absence of human annotated labels along with the need for privacy preserving policies for model building makes it a daunting challenge. Motivated by these challenges, in this paper we use a cloud based framework for production systems to demonstrate insights from privacy preserving incremental learning for automatic speech recognition (ILASR). By privacy preserving, we mean, usage of ephemeral data which are not human annotated. This system is a step forward for production levelASR models for incremental/continual learning that offers near real-time test-bed for experimentation in the cloud for end-to-end ASR, while adhering to privacy-preserving policies. We show that the proposed system can improve the production models significantly(3%) over a new time period of six months even in the absence of human annotated labels with varying levels of weak supervision and large batch sizes in incremental learning. This improvement is 20% over test sets with new words and phrases in the new time period. We demonstrate the effectiveness of model building in a privacy-preserving incremental fashion for ASR while further exploring the utility of having an effective teacher model and use of large batch sizes.
End-to-End Spoken Language Understanding using RNN-Transducer ASR
Jul 08, 2021
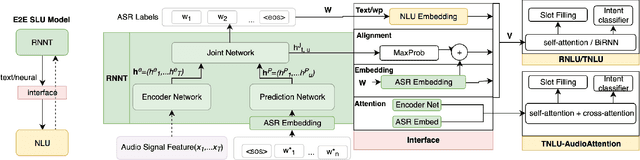

We propose an end-to-end trained spoken language understanding (SLU) system that extracts transcripts, intents and slots from an input speech utterance. It consists of a streaming recurrent neural network transducer (RNNT) based automatic speech recognition (ASR) model connected to a neural natural language understanding (NLU) model through a neural interface. This interface allows for end-to-end training using multi-task RNNT and NLU losses. Additionally, we introduce semantic sequence loss training for the joint RNNT-NLU system that allows direct optimization of non-differentiable SLU metrics. This end-to-end SLU model paradigm can leverage state-of-the-art advancements and pretrained models in both ASR and NLU research communities, outperforming recently proposed direct speech-to-semantics models, and conventional pipelined ASR and NLU systems. We show that this method improves both ASR and NLU metrics on both public SLU datasets and large proprietary datasets.
Listen with Intent: Improving Speech Recognition with Audio-to-Intent Front-End
May 14, 2021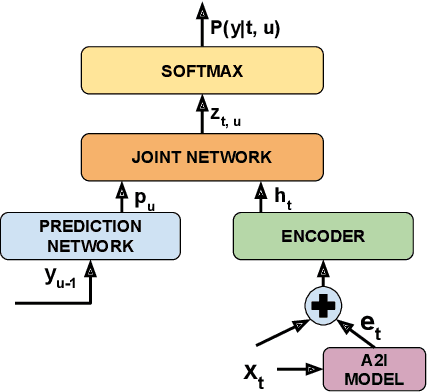
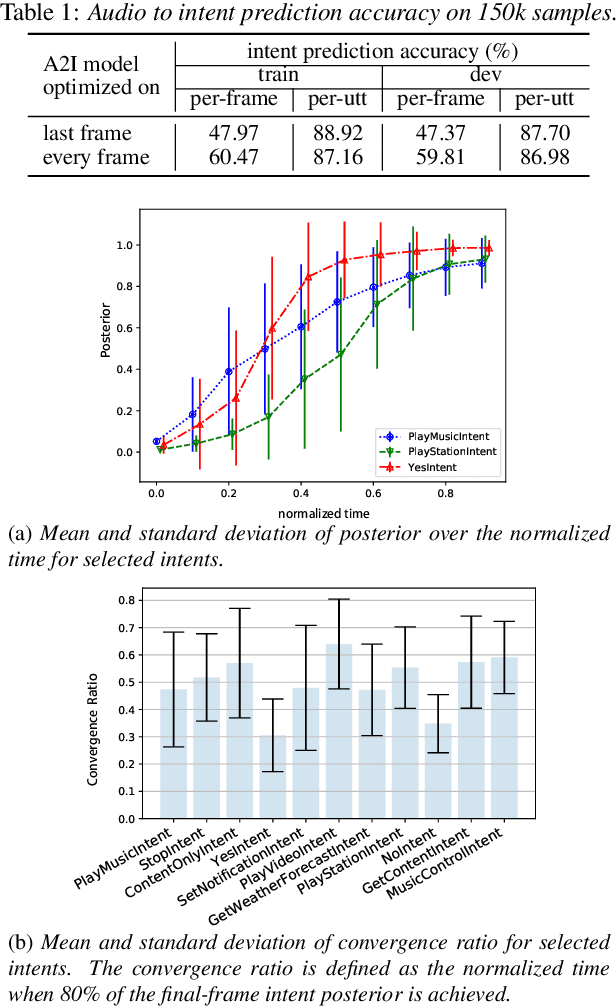
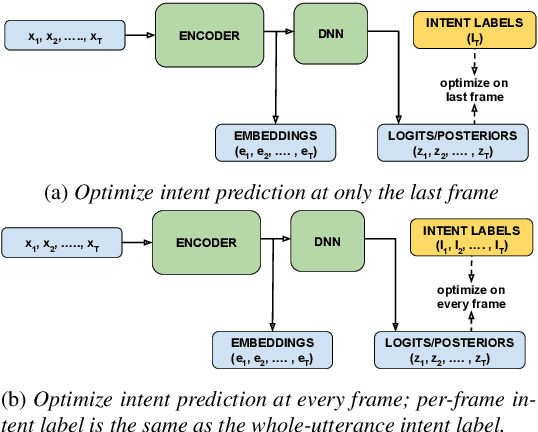
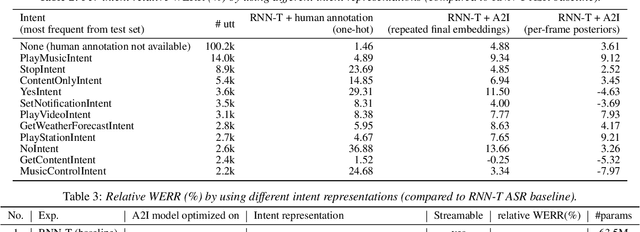
Comprehending the overall intent of an utterance helps a listener recognize the individual words spoken. Inspired by this fact, we perform a novel study of the impact of explicitly incorporating intent representations as additional information to improve a recurrent neural network-transducer (RNN-T) based automatic speech recognition (ASR) system. An audio-to-intent (A2I) model encodes the intent of the utterance in the form of embeddings or posteriors, and these are used as auxiliary inputs for RNN-T training and inference. Experimenting with a 50k-hour far-field English speech corpus, this study shows that when running the system in non-streaming mode, where intent representation is extracted from the entire utterance and then used to bias streaming RNN-T search from the start, it provides a 5.56% relative word error rate reduction (WERR). On the other hand, a streaming system using per-frame intent posteriors as extra inputs for the RNN-T ASR system yields a 3.33% relative WERR. A further detailed analysis of the streaming system indicates that our proposed method brings especially good gain on media-playing related intents (e.g. 9.12% relative WERR on PlayMusicIntent).
Do as I mean, not as I say: Sequence Loss Training for Spoken Language Understanding
Feb 12, 2021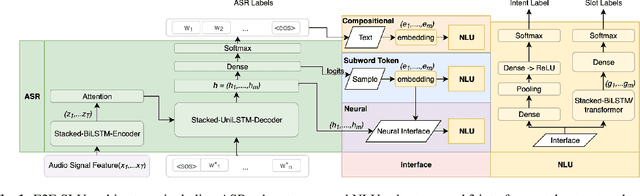
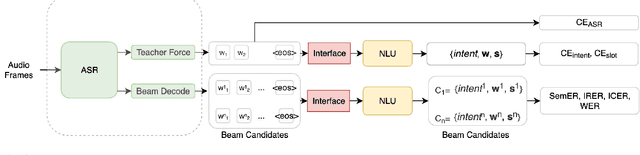
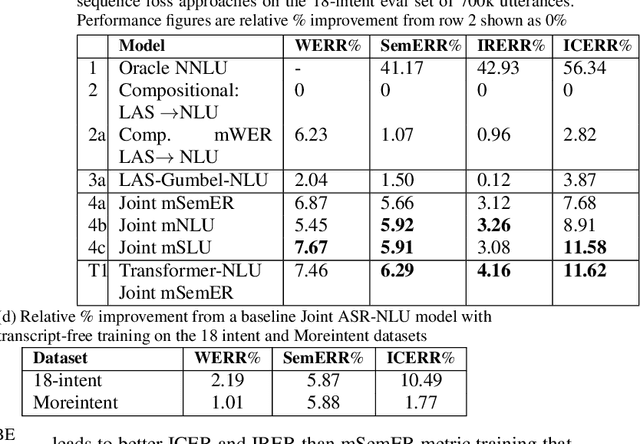
Spoken language understanding (SLU) systems extract transcriptions, as well as semantics of intent or named entities from speech, and are essential components of voice activated systems. SLU models, which either directly extract semantics from audio or are composed of pipelined automatic speech recognition (ASR) and natural language understanding (NLU) models, are typically trained via differentiable cross-entropy losses, even when the relevant performance metrics of interest are word or semantic error rates. In this work, we propose non-differentiable sequence losses based on SLU metrics as a proxy for semantic error and use the REINFORCE trick to train ASR and SLU models with this loss. We show that custom sequence loss training is the state-of-the-art on open SLU datasets and leads to 6% relative improvement in both ASR and NLU performance metrics on large proprietary datasets. We also demonstrate how the semantic sequence loss training paradigm can be used to update ASR and SLU models without transcripts, using semantic feedback alone.
Speech To Semantics: Improve ASR and NLU Jointly via All-Neural Interfaces
Aug 14, 2020
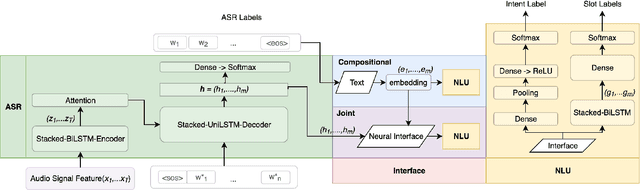
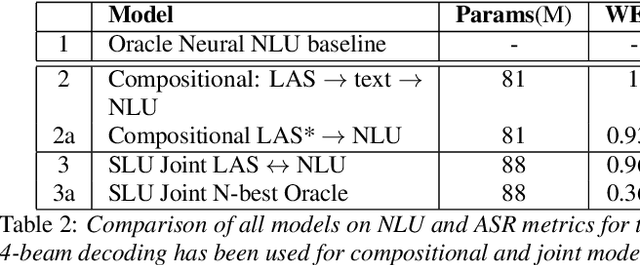
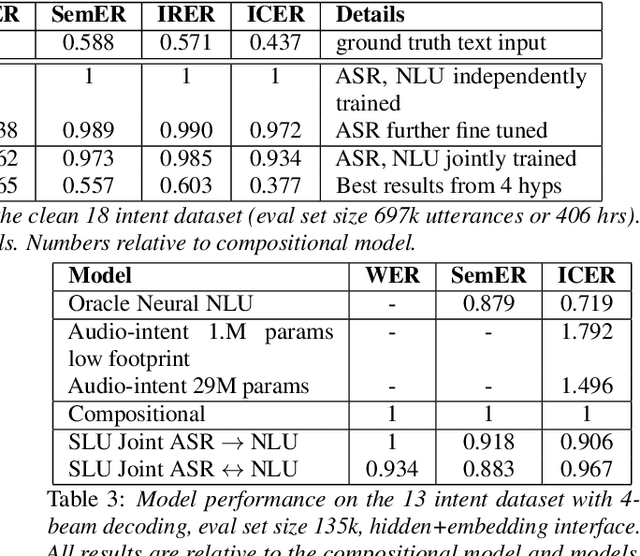
We consider the problem of spoken language understanding (SLU) of extracting natural language intents and associated slot arguments or named entities from speech that is primarily directed at voice assistants. Such a system subsumes both automatic speech recognition (ASR) as well as natural language understanding (NLU). An end-to-end joint SLU model can be built to a required specification opening up the opportunity to deploy on hardware constrained scenarios like devices enabling voice assistants to work offline, in a privacy preserving manner, whilst also reducing server costs. We first present models that extract utterance intent directly from speech without intermediate text output. We then present a compositional model, which generates the transcript using the Listen Attend Spell ASR system and then extracts interpretation using a neural NLU model. Finally, we contrast these methods to a jointly trained end-to-end joint SLU model, consisting of ASR and NLU subsystems which are connected by a neural network based interface instead of text, that produces transcripts as well as NLU interpretation. We show that the jointly trained model shows improvements to ASR incorporating semantic information from NLU and also improves NLU by exposing it to ASR confusion encoded in the hidden layer.
Distributed Convex Optimization With Limited Communications
Oct 29, 2018
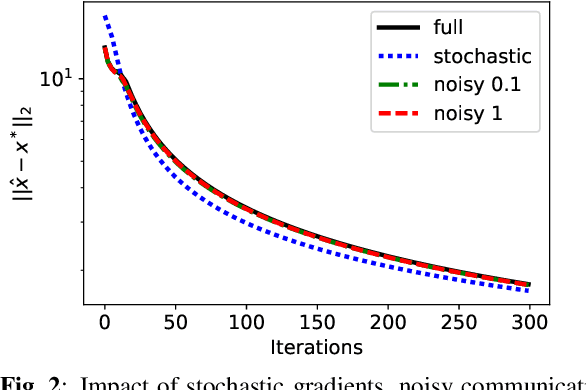

In this paper, a distributed convex optimization algorithm, termed \emph{distributed coordinate dual averaging} (DCDA) algorithm, is proposed. The DCDA algorithm addresses the scenario of a large distributed optimization problem with limited communication among nodes in the network. Currently known distributed subgradient methods, such as the distributed dual averaging or the distributed alternating direction method of multipliers algorithms, assume that nodes can exchange messages of large cardinality. Such network communication capabilities are not valid in many scenarios of practical relevance. In the DCDA algorithm, on the other hand, communication of each coordinate of the optimization variable is restricted over time. For the proposed algorithm, we bound the rate of convergence under different communication protocols and network architectures. We also consider the extensions to the case of imperfect gradient knowledge and the case in which transmitted messages are corrupted by additive noise or are quantized. Relevant numerical simulations are also provided.